💡 ****
Flow-based Models
Normalizing Flow
Normalizing Flow 是一种基于变换对概率分布进行建模的模型,其通过一系列离散且可逆的变换实现任意分布与先验分布(例如标准高斯分布)之间的相互转换。在 Normalizing Flow 训练完成后,就可以直接从高斯分布中进行采样,并通过逆变换得到原始分布中的样本,实现生成的过程。(有关 Normalizing Flow 的详细理论)
从这个角度看,Normalizing Flow 和 Diffusion Model 是有一些相通的,其做法的对比如下表所示。从表中可以看到,两者大致的过程是非常类似的,尽管依然有些地方不一样,但这两者应该可以通过一定的方法得到一个比较统一的表示。
Continuous Normalizing Flow
Continuous Normalizing Flow(CNF),也就是连续标准化流,可以看作 Normalizing Flow 的一般形式。在传统的Normalizing Flows中,变换通常是通过一系列可逆的离散函数来定义的,而在CNFs中,这种变换是连续的,这使得模型能够更加平滑地适应数据的分布,提高了模型的表达能力。
设有 d 维空间中的数据 $x = (x^1, x^2, \dots, x^d) \in \mathbb{R}^d
$ 。CNF 有两个核心的研究对象:
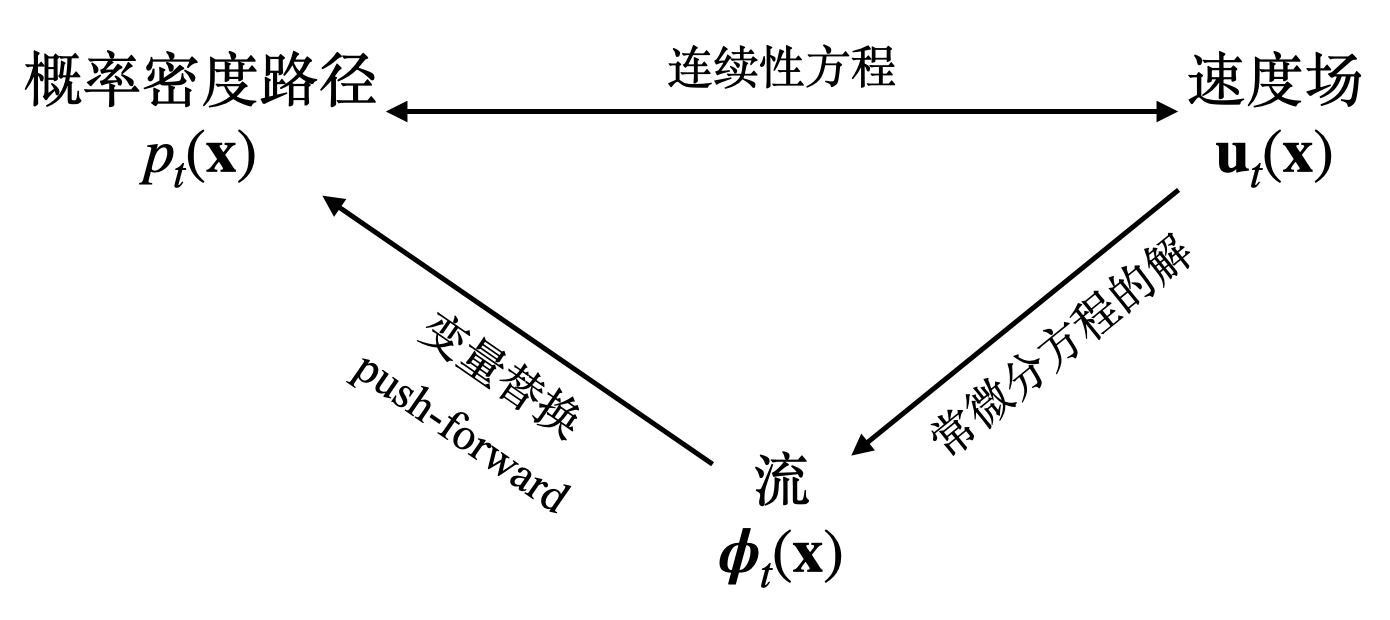
概率密度路径
粒子在流动的过程中,其概率分布在不断地改变。定义概率密度路径 ,其中 表示 时刻 位置处的概率密度。称之为“路径”是因为 可以视作无限维概率分布空间中的流形上的一条路径。
显然,对任意时刻 ,概率密度 都应满足归一化条件:. 因此,区别于流体力学中一般的流(不要求密度是归一化的),我们称这种模型为归一化流;又由于时间是连续的,因此称为连续归一化流。
速度场与连续性方程
定义速度场为 ,其中 表示 时刻 位置处粒子的运动速度。流体中的粒子沿着速度场 运动,引起概率密度的变化,因此 与 之间一定存在某种关系,这个关系式称为连续性方程:
直观上,连续性方程的第一项表示单位时间内 位置处粒子的增加/减少量,第二项表示单位时间内 位置处粒子的流出/流入量,显然粒子增加量就是流入量,因此连续性方程成立。熟悉随机微分方程的读者可能会发现,连续性方程其实就是 Fokker-Planck 方程在扩散项为零时的情形。
概率分布在向量场中进行变换这一过程可以用物理学中的传输行为来建模。这是因为不管概率分布如何变换,其在全体分布上的积分始终为 1,因此可以认为概率密度也是一个守恒的物理量,可以类比物理学中的质量、电荷等的传输行为进行建模。在物理学里,Continuity Equation是描述守恒量传输行为的偏微分方程。在适当条件下,质量、能量、动量、电荷等都是守恒量,因此很多传输行为都可以用连续性方程来描述,在高维情况中定义如下:
是向量场与概率密度的乘积的散度,表示概率流通过某个区域的净变化率。
值得注意的是,概率密度路径与速度场不是一一对应的关系,不同的速度场可以产生相同的概率密度路径。例如,给 加上散度为零的场(无源场),就得到了一个新的速度场,并且连续性方程依旧成立,所以概率密度路径不变。
向量场 是一个函数,它在空间中的每一点都分配一个向量。
在二维或三维空间中的每个点 上,向量场会给出一个向量,这个向量可以表示速度、电场、磁场等任何有大小和方向的量。
可以用箭头图来可视化向量场,每个箭头表示一个向量,箭头的方向表示向量的方向,箭头的长度表示向量的大小。
散度(Divergence)是一个运算符,用来衡量一个向量场在空间中某一点的“发散程度”或者“汇聚程度”。它是一个标量值。
如果我们有一个向量场 (在三维空间中),它的散度定义为:
$\mathrm{div}(\mathbf{F}) = \nabla \cdot \mathbf{F} = \frac{\partial F_x}{\partial x} + \frac{\partial F_y}{\partial y} + \frac{\partial F_z}{\partial z}
$
简单来说,散度是将向量场的变化“压缩”成一个标量,描述了这个场在某点的“体积变化率”。
性质:Continuity Equation **是判断向量场 产生对应的概率密度路径 的 **充分必要条件。如果向量场 和概率密度路径 满足 Continuity Equation **,则在CNFs **中该向量场 就能产生对应的概率密度路径 。
为什么说向量场 “生成” 了概率密度路径 ?为什么要用常微分方程 ODE 来表达? 是 的导数(微分)。导数或者说微分,就是一个量随着另一个量极小变化时的变化,其实写成离散形式也好理解了,微分就是变化量: 。就是从上一个时间点x的位置,怎么到下一个时间点x的位置,再知道初值 之后,就能从第一个点 “流” 到最后一个点,得到一个路径 ,所以说“向量场( ODE 的解 )生成了一条概率路径”。而 ODE 定义了一个向量场 。

Probability path from to
流与变量替换
粒子沿着速度场运动,得到的轨迹称为流。具体而言,流 是下述常微分方程的解:
其中 表示 0 时刻位于 处的粒子在 时刻运动到的位置。换句话说,随着 从 0 到 1 变化, 形成了从 位置出发的粒子运动的轨迹。为了看得更清楚,可以对上式左右两边同时从 到 积分:
左边表示从 出发的粒子在 时间内的位移,右边是对速度的积分,自然也是位移。
💡 flow 的核心就是通过可逆变换在不同分布之间建立映射。就是这个变换函数,它告诉我们如何将一个分布中的点映射到另一个分布中的点,从而实现分布之间的转换。
根据流 的定义, 时刻位于 位置处的粒子在 时刻的出发位置是 ,因此根据随机变量的变量替换公式,可以知道 与 之间有关系:
简记作 ,称作 push-forward 方程。
拓展(瞬时变量替换公式):Push-forward 方程给出了 时刻到 时刻概率密度的变化。进一步地,Neural ODE 的作者还给出了描述概率密度变化的微分方程,称作瞬时变量替换公式:
推导过程:计算 对 的全导数:
其中第二行是代入了连续性方程,第三行是将散度展开,最后一行是根据流的定义有 . 于是我们有:
这就得到了瞬时变量替换公式。
Neural ODE 提出使用一个参数为 的神经网络 来建模向量场 ,从而就能够计算出 flow ,来实现 CNF。
如果知道了这个向量场 ,那么通过求解这个ODE **就可以找到从初始概率分布到目标概率分布的连续路径,从而将简单分布转换成复杂分布。这个ODE可以采用欧拉方法来求解,从初始值 开始,使用下面的迭代公式**来计算在后续时间点的近似值:
其中, 是步长, 是采样时间点, 是最大采样步数, 是在时间 的近似解。
也就是说,一旦我们得知从标准高斯分布到目标分布的变换向量场,就可以从标准高斯分布采样,然后通过上述迭代过程得到目标分布中的一个近似解,完成生成的过程。这和离散的 Normalizing Flow 是一致的。
综上所述,概率密度路径、速度场和流之间的关系可表示为下图:
在 Score-based Model 中,我们用随机微分方程(SDE)统一了 SMLD(Score Matching with Langevin Dynamics)和 DDPM,并且将 SDE 转化为了 ODE 概率流。也就是说,扩散模型同样能够用一个 ODE 来表示,因此,扩散模型也应当能够利用 CNF 的训练方式进行训练,这个训练的方式就是 Flow Matching。
Flow Matching
概述
在构建生成模型时,我们假设有一个未知的数据分布 (注意本文中的符号与扩散模型论文中常用的符号相反,本文 表示真实数据, 表示随机噪声),我们能从其中采样出大量数据样本,但是不知道该分布的具体函数。
记 为概率路径,而 是一个简单的已知分布 (如标准高斯分布), 并令 在分布上大致与 相等。Flow Matching 的目标就是去匹配这样一条目标概率路径,从而我们能够从 ”流动“到,实现生成。如何构造这样一条目标路径,稍后会介绍。
Flow Matching 的训练目标和 Score Matching 是比较类似的,学习的目标就是通过学习拟合一个向量场 ,使得能够得到对分布进行变换的概率路径 ,也就是下边这个公式:
其中 是模型的可训练参数, 在 0 到 1 之间均匀分布, 是概率路径, 是由模型表示的向量场。这个训练目标的含义为:利用模型 来拟合一个向量场 ,使得最终通过学习到的 可以得到概率路径 ,并且满足 。
不过实际上这个公式并不实用,首先能够满足 的概率路径是很多的,其次我们也不知道 究竟是什么东西,所以无法直接用来计算损失。
实际上概率路径有很多,如下图所示,在实际操作中,会选择一条具体的路径,也就是一个目标向量场才具有实际意义。
从条件概率路径和向量场构造
虽然我们不知道 和 的具体形式,但是我们可以通过添加条件将其转换为可以求得的形式(可以类比在 DDPM 推导时将 转换为了 , score matching中也有类似的转换过程,)。也就是说,虽然 不知道,但是可以通过学习条件向量场 ,使得最后通过这个向量场能够生成条件概率路径 , 。由于我们可以获得数据样本 ,所以将作为条件听起来非常合理,从而得出以下边际概率路径,
在这种情况下,条件概率路径 需要满足边界条件, 初始状态下条件分布等于先验分布;
终止状态下条件分布集中在附近的一个很小的区域内;
第一个定理就是为了说明这个带条件的形式和不带条件的形式是等价的,也就是:
定理一: 给定向量场 ,其能够生成条件概率路径 ,那么对于任意分布 ,满足某一特定形式(后文会给出)的边缘向量场 就能生成对应的边缘概率路径 。
证明: 首先,对于边缘概率路径 ,有以下等式:
其中 为条件分布, 为隐变量分布, 对应的速度场为 。现在我们要考虑 应该怎么被定义的问题。首先,我们考察一下连续性方程是否能被满足,这个是一切假设的前提。
考虑到条件分布下的连续性方程 , 带到上式可得,
我们希望能得到(2)式,即
推导到这里, 需要满足以下形式:
也就是说,只要 满足上边等式中的形式,就可以用 和 取代 和 。
这个边缘向量场的定义应该是为了这盘醋(论文中的定理1)包的这个饺子,针对这个公式具体点说也就是在数据点 处的向量场 是通过对所有可能的初始条件 的条件向量场 加权积分得到的,权重是由条件概率密度 ** 和边缘概率密度 的比值决定的**。
Conditional Flow Matching
虽然基于上述过程已经推导出了 的形式,但上述的积分依然不容易求解。因此作者给出了一种更容易求解的形式(如下所示),并且证明了下面这个损失函数与原本损失函数的等价性。
这样写的直觉是,如果(11)式是一个好的代理目标,那么我们直接对(11)式进行优化就行,因为很有可能在给定 的情况下,条件速度场是可采样或者可解的,类似分数匹配的条件概率一样。
作者证明了 和 的等价性,也就是说优化 等价于优化 LFM:
定理二: 假定对于所有 且都有 ,那么 和 相差一个与 无关的常数,即有 。
证明: 因为优化目标是 ,我们考察 ,有
类似的,我们考察(6)式对于 的导数,有
对于两个式子的第一项有,
所以现在的关键在于,以上两个式子的右边第二项有什么联系?我们继续化简
如此即证明了上述的定理,即
这就意味着,优化(11)式和优化(7)式对于 来说是一样的,或者说你为了得到(7)式中的参数化速度场,你可以以(11)式为目标,构造条件速度场,然后用网络拟合 就行,至于拟合到的是什么没关系,实际推理的时候你可以直接把 当作 的近似来使用。
到这里,构造代理目标的目的就完成了。很有意思的是,我们在满足连续性方程的情况下构造的 ,直接可以让我们用条件分布作为代理目标,来拟合边缘分布。事实上,用类似的思路,也可以证明在扩散模型SDE框架里,条件分数匹配的目标跟得分匹配的目标对于优化网络参数而言是一致的,具体可以参考苏剑林的《生成扩散模型漫谈(十八):得分匹配 = 条件得分匹配》。
条件概率路径和向量场
上面我们已经证明了条件概率路径和条件向量场可以等价于边缘概率路径和边缘向量场,并且用 CFM 的方式进行训练和 Flow Matching 的效果是相同的。但现在 的形式依然是不知道的,因此我们需要进一步定义具体的条件概率路径的形式。就像 DDPM,我们需要定义具体的前向过程,才能基于这个过程进行训练。