- Flow Matching 其实是将 flow 的离散形式转换为连续形式(连续标准化流CNF),进而可以看成是一个ODE方程,实际求解的是这个ODE
- 求解的核心思路是:构建速度场通过数值积分求解位移,也就是通过预测速度场,从而转为ode求解
- 从概率路径的角度上来说,解是无穷多的,不同的方法本质上讲是在于构造尽可能简单、直接、易解的概率路径
- 通过不同的条件概率路径,可以构造出VP(score matching)、 VE(diffusion)、OT(1-rectified flow)等形式
- 实际的边缘概率分布路径并不是一条直线,我们是通过拟合条件速度场来逼近边缘速度场,即使我们证明了对于参数 \(\theta\) 来说优化目标是等价的,但终究还是有一些gap
Flow-based Models
Normalizing Flow
Normalizing Flow 是一种基于变换对概率分布进行建模的模型,其通过一系列离散且可逆的变换实现任意分布与先验分布(例如标准高斯分布)之间的相互转换。在 Normalizing Flow 训练完成后,就可以直接从高斯分布中进行采样,并通过逆变换得到原始分布中的样本,实现生成的过程。(有关 Normalizing Flow 的详细理论)
从这个角度看,Normalizing Flow 和 Diffusion Model 是有一些相通的,其做法的对比如下表所示。从表中可以看到,两者大致的过程是非常类似的,尽管依然有些地方不一样,但这两者应该可以通过一定的方法得到一个比较统一的表示。
模型 | 前向过程 | 反向过程 |
|---|---|---|
Normalizing Flow | 通过显式的可学习变换将样本分布变换为标准高斯分布 | 从标准高斯分布采样,并通过上述变换的逆变换得到生成的样本 |
Diffusion Model | 通过不可学习的 schedule 对样本进行加噪,多次加噪变换为标准高斯分布 | 从标准高斯分布采样,通过模型隐式地学习反向过程的噪声,去噪得到生成样本 |
Continuous Normalizing Flow
Continuous Normalizing Flow(CNF),也就是连续标准化流,可以看作 Normalizing Flow 的一般形式。在传统的Normalizing Flows中,变换通常是通过一系列可逆的离散函数来定义的,而在CNFs中,这种变换是连续的,这使得模型能够更加平滑地适应数据的分布,提高了模型的表达能力。
设有 d 维空间中的数据 \(x = (x^1, x^2, \dots, x^d) \in \mathbb{R}^d\)。CNF 有两个核心的研究对象:
概率密度路径
粒子在流动的过程中,其概率分布在不断地改变。定义概率密度路径 \(p:[0,1]\times \mathbb R^d\to\mathbb R_{>0}\),其中 \(p_t(\mathbf x)\) 表示 \(t\) 时刻 \(x\) 位置处的概率密度。称之为“路径”是因为 \(t\mapsto p_t\) 可以视作无限维概率分布空间中的流形上的一条路径。
显然,对任意时刻 \(t\in[0,1]\),概率密度 \(p_t(\mathbf x)\) 都应满足归一化条件:\(\int p_t(\mathbf x)\mathrm d\mathbf x=1\). 因此,区别于流体力学中一般的流(不要求密度是归一化的),我们称这种模型为归一化流;又由于时间是连续的,因此称为连续归一化流。
速度场与连续性方程
定义速度场为 \(\mathbf u:[0,1]\times\mathbb R^d\to\mathbb R^d\),其中 \(\mathbf u_t(\mathbf x)\) 表示 \(t\) 时刻 \(x\) 位置处粒子的运动速度。流体中的粒子沿着速度场 \(\mathbf u\) 运动,引起概率密度的变化,因此 \(\mathbf u_t(\mathbf x)\) 与 \(p_t(\mathbf x)\) 之间一定存在某种关系,这个关系式称为连续性方程:
直观上,连续性方程的第一项表示单位时间内 \(x\) 位置处粒子的增加/减少量,第二项表示单位时间内 \(x\) 位置处粒子的流出/流入量,显然粒子增加量就是流入量,因此连续性方程成立。熟悉随机微分方程的读者可能会发现,连续性方程其实就是 Fokker-Planck 方程在扩散项为零时的情形。
概率分布在向量场中进行变换这一过程可以用物理学中的传输行为来建模。这是因为不管概率分布如何变换,其在全体分布上的积分始终为 1,因此可以认为概率密度也是一个守恒的物理量,可以类比物理学中的质量、电荷等的传输行为进行建模。在物理学里,Continuity Equation是描述守恒量传输行为的偏微分方程。在适当条件下,质量、能量、动量、电荷等都是守恒量,因此很多传输行为都可以用连续性方程来描述,在高维情况中定义如下:
\(\operatorname{div}\left(p_{t}(x) \mathbf{u}_{t}(x)\right)\) 是向量场与概率密度的乘积的散度,表示概率流通过某个区域的净变化率。
值得注意的是,概率密度路径与速度场不是一一对应的关系,不同的速度场可以产生相同的概率密度路径。例如,给 \(\mathbf u_t(\mathbf x)\) 加上散度为零的场(无源场),就得到了一个新的速度场,并且连续性方程依旧成立,所以概率密度路径不变。
向量场 是一个函数,它在空间中的每一点都分配一个向量。
在二维或三维空间中的每个点\( (x, y, z)\) 上,向量场会给出一个向量,这个向量可以表示速度、电场、磁场等任何有大小和方向的量。
可以用箭头图来可视化向量场,每个箭头表示一个向量,箭头的方向表示向量的方向,箭头的长度表示向量的大小。
散度(Divergence)是一个运算符,用来衡量一个向量场在空间中某一点的“发散程度”或者“汇聚程度”。它是一个标量值。
如果我们有一个向量场 \(\mathbf{F}=(F_x,F_y,F_z)\)(在三维空间中),它的散度定义为:
\(\mathrm{div}(\mathbf{F}) = \nabla \cdot \mathbf{F} = \frac{\partial F_x}{\partial x} + \frac{\partial F_y}{\partial y} + \frac{\partial F_z}{\partial z}\)
简单来说,散度是将向量场的变化“压缩”成一个标量,描述了这个场在某点的“体积变化率”。
性质:Continuity Equation 是判断向量场 \(v_t(x)\) 产生对应的概率密度路径 \(p_t(x)\) 的 **充分必要条件。如果向量场 \(v_t(x)\) 和概率密度路径 \(p_t(x)\) 满足 Continuity Equation,则在CNFs 中该向量场 \(v_t(x)\) 就能产生对应的概率密度路径 \(p_t(x)\)。
为什么说向量场 \(v_t\) “生成” 了概率密度路径 \(p_t\) ?为什么要用常微分方程 ODE 来表达?\(v_t\) 是 \(\phi_t\) 的导数(微分)。导数或者说微分,就是一个量随着另一个量极小变化时的变化,其实写成离散形式也好理解了,微分就是变化量: \( \phi'_t=\phi_{t+\Delta t}-\phi_t\)。就是从上一个时间点x的位置,怎么到下一个时间点x的位置,再知道初值 \(\phi_0=x\) 之后,就能从第一个点 “流” 到最后一个点,得到一个路径 \(p_t\),所以说“向量场(\(\phi_t\) ODE 的解 \(\phi'_t=v_t\))生成了一条概率路径”。而 ODE \(d\phi_t/dt=v(z_t,t)\)定义了一个向量场 \(v\) 。

Probability path \(p_t = \mathcal{N}(\mu_t, 1)\) from \(p_0 = \mathcal{N}(0, 1)\) to \(p_1 = \mathcal{N}(\mu, 1)\)
流与变量替换
粒子沿着速度场运动,得到的轨迹称为流。具体而言,流 \(\boldsymbol\phi:[0,1]\times\mathbb R^d\to\mathbb R^d\)是下述常微分方程的解:
其中 \(\boldsymbol\phi_t(\mathbf x)\) 表示 0 时刻位于 \(\mathbf x\) 处的粒子在 \(t\) 时刻运动到的位置。换句话说,随着 \(t\) 从 0 到 1 变化,\(\boldsymbol\phi_t(\mathbf x)\) 形成了从 \(\mathbf x\) 位置出发的粒子运动的轨迹。为了看得更清楚,可以对上式左右两边同时从 \(0\) 到 \(t\) 积分:
左边表示从 \(\mathbf x\) 出发的粒子在 \(t\) 时间内的位移,右边是对速度的积分,自然也是位移。
💡 flow 的核心就是通过可逆变换在不同分布之间建立映射。\(ϕ_t\)就是这个变换函数,它告诉我们如何将一个分布中的点映射到另一个分布中的点,从而实现分布之间的转换。
根据流 \(\boldsymbol\phi\) 的定义,\(t\) 时刻位于 \(\mathbf x\) 位置处的粒子在 \(0\) 时刻的出发位置是 \(\boldsymbol\phi_t^{-1}(\mathbf x)\),因此根据随机变量的变量替换公式,可以知道 \(p_t(\mathbf x)\) 与 \(\boldsymbol\phi_t(\mathbf x)\) 之间有关系:
简记作 \(p_t=[\boldsymbol\phi_t]_\#(p_0)\),称作 push-forward 方程。
拓展(瞬时变量替换公式):Push-forward 方程给出了 \(0\) 时刻到 \(t\) 时刻概率密度的变化。进一步地,Neural ODE 的作者还给出了描述概率密度变化的微分方程,称作瞬时变量替换公式:
推导过程:计算 \(p_t(\boldsymbol\phi_t(\mathbf x))\) 对 \(t\) 的全导数:
其中第二行是代入了连续性方程,第三行是将散度展开,最后一行是根据流的定义有 \(\mathbf u_t(\boldsymbol\phi_t(\mathbf x))=\frac{\partial}{\partial t}\boldsymbol\phi_t(\mathbf x)\). 于是我们有:
这就得到了瞬时变量替换公式。
Neural ODE 提出使用一个参数为 \(\theta \in \mathbb{R}^p\) 的神经网络 \(v_t(x; \theta)\) 来建模向量场 \(v_t\),从而就能够计算出 flow \(\phi_t\),来实现 CNF。
如果知道了这个向量场 \(v_t\),那么通过求解这个ODE 就可以找到从初始概率分布到目标概率分布的连续路径,从而将简单分布转换成复杂分布。这个ODE可以采用欧拉方法来求解,从初始值\(x_0\) 开始,使用下面的迭代公式来计算\(z\)在后续时间点的近似值:
其中,\(\Delta t = 1/N\) 是步长,\(t=i/N\) 是采样时间点,\(N\) 是最大采样步数,\(x_t\) 是在时间 \(t\) 的近似解。
也就是说,一旦我们得知从标准高斯分布到目标分布的变换向量场,就可以从标准高斯分布采样,然后通过上述迭代过程得到目标分布中的一个近似解,完成生成的过程。这和离散的 Normalizing Flow 是一致的。
综上所述,概率密度路径、速度场和流之间的关系可表示为下图:
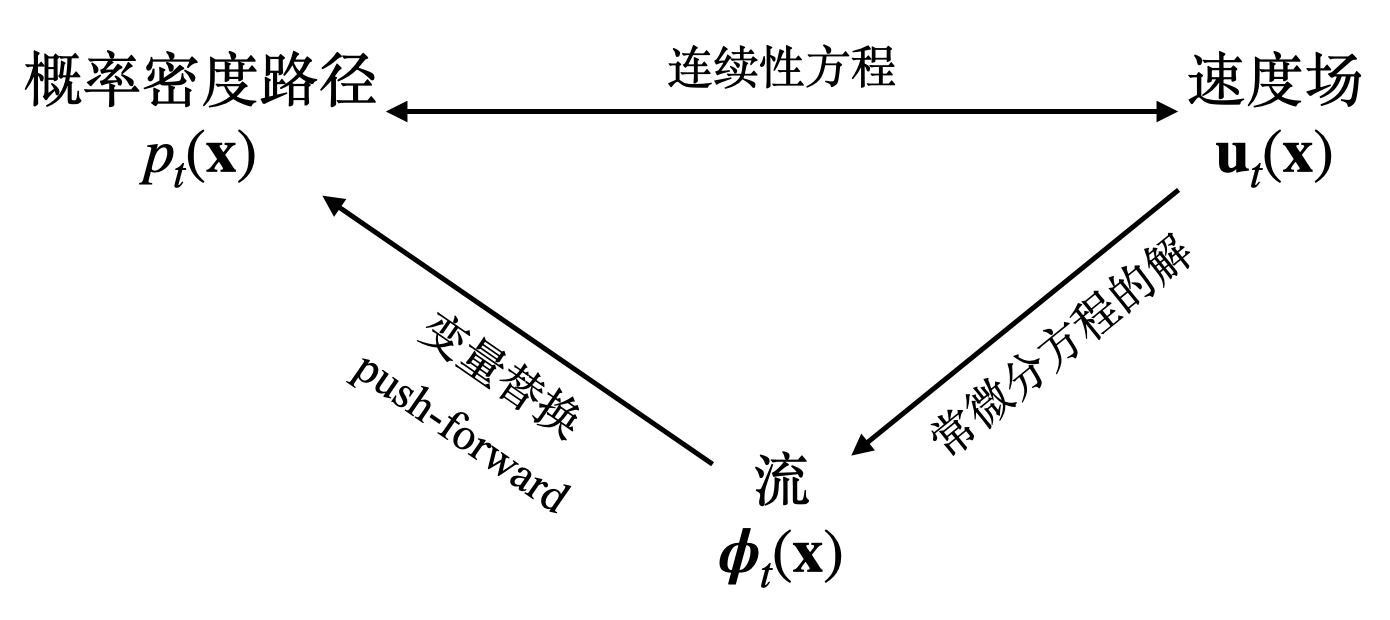
在 Score-based Model 中,我们用随机微分方程(SDE)统一了 SMLD(Score Matching with Langevin Dynamics)和 DDPM,并且将 SDE 转化为了 ODE 概率流。也就是说,扩散模型同样能够用一个 ODE 来表示,因此,扩散模型也应当能够利用 CNF 的训练方式进行训练,这个训练的方式就是 Flow Matching。
Flow Matching
概述
在构建生成模型时,我们假设有一个未知的数据分布\(q(x_1)\) (注意本文中的符号与扩散模型论文中常用的符号相反,本文 \(x_{1}\) 表示真实数据,\(x_0\) 表示随机噪声),我们能从其中采样出大量数据样本,但是不知道该分布的具体函数。
记 \(p_t\) 为概率路径,而 \(p_0=p\) 是一个简单的已知分布 (如标准高斯分布\(p(x)\sim\mathcal{N}(0,\mathbf{I})\)), 并令\(p_1\) 在分布上大致与 \(q\) 相等。Flow Matching 的目标就是去匹配这样一条目标概率路径,从而我们能够从\(p_0\) ”流动“到\(p_{1}\),实现生成。如何构造这样一条目标路径,稍后会介绍。
Flow Matching 的训练目标和 Score Matching 是比较类似的,学习的目标就是通过学习拟合一个向量场 \(u_t\),使得能够得到对分布进行变换的概率路径 \(p_t\),也就是下边这个公式:
其中 \(θ\) 是模型的可训练参数,\(t\) 在 0 到 1 之间均匀分布,\(x\sim p_t(x)\) 是概率路径,\(u_\theta(t, x)\) 是由模型表示的向量场。这个训练目标的含义为:利用模型 \(θ\) 来拟合一个向量场 \(u_\theta(t, x)\),使得最终通过学习到的 \(u_\theta(t, x)\) 可以得到概率路径 \(p_t(x)\),并且满足 \(p_1(x)\approx q(x)\)。
不过实际上这个公式并不实用,首先能够满足 \(p_1(x)\approx q(x)\) 的概率路径是很多的,其次我们也不知道 \(u(t,x)\) 究竟是什么东西,所以无法直接用来计算损失。
实际上概率路径有很多,如下图所示,在实际操作中,会选择一条具体的路径,也就是一个目标向量场\(u_t\)才具有实际意义。
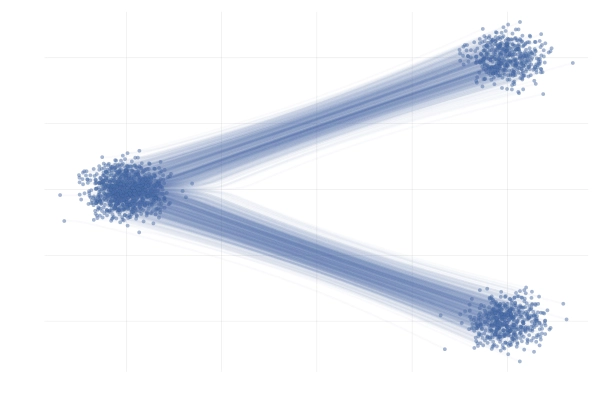
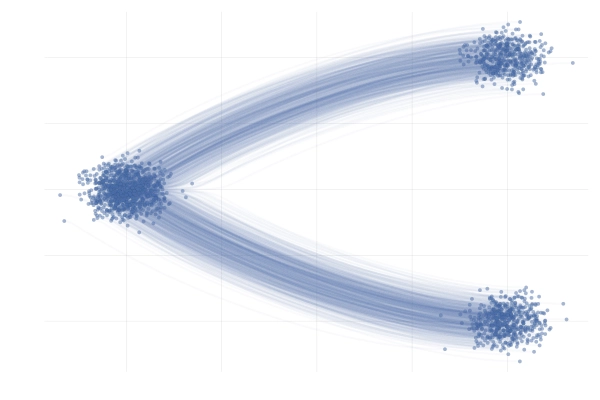
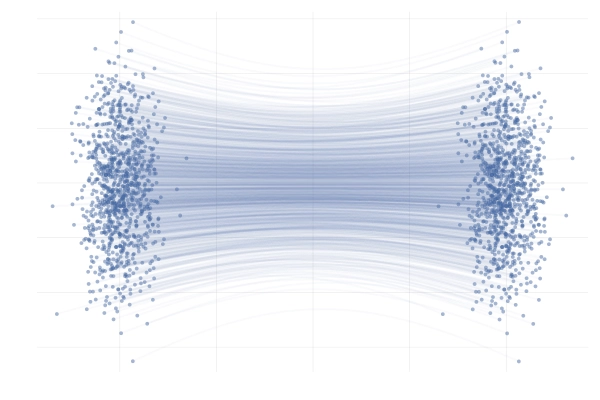
从条件概率路径和向量场构造
虽然我们不知道 \(p_t(x)\) 和 \(u_t(x)\) 的具体形式,但是我们可以通过添加条件将其转换为可以求得的形式(可以类比在 DDPM 推导时将 \(p(\mathbf{x}_{t-1}|\mathbf{x}_t)\) 转换为了 \(p(\mathbf{x}_{t-1}|\mathbf{x}_t, \mathbf{x}_0)\), score matching中也有类似的转换过程,\(\nabla\log p_t(\mathbf x)=\mathbb E_{p(\mathbf x_1\vert\mathbf x)}[\nabla\log p_t(\mathbf x\vert\mathbf x_1)]\))。也就是说,虽然 \(u_t(x)\) 不知道,但是可以通过学习条件向量场 \(u_t(x|x_1)\),使得最后通过这个向量场能够生成条件概率路径 \(p_t(x|x_1)\), \(x_1 \sim q_1\)。由于我们可以获得数据样本 ,所以将\(x_1\)作为条件听起来非常合理,从而得出以下边际概率路径,
在这种情况下,条件概率路径 \(p_{t\mid 1}\) 需要满足边界条件, 初始状态下条件分布等于先验分布;
终止状态下条件分布集中在\(x_1\)附近的一个很小的区域内;
第一个定理就是为了说明这个带条件的形式和不带条件的形式是等价的,也就是:
定理一: 给定向量场 \(u_t(x|x_1)\),其能够生成条件概率路径 \(p_t(x|x_1)\),那么对于任意分布 \(q(x_1)\),满足某一特定形式(后文会给出)的边缘向量场 \(u_t(x)\) 就能生成对应的边缘概率路径 \(p_t(x)\)。
证明: 首先,对于边缘概率路径 \(p_t(x)\),有以下等式:
其中 \(p_{t}\left( x | z\right) \)为条件分布,\(q(z)\) 为隐变量分布,\(p_{t}\left( x | z\right) \) 对应的速度场为 \(u_{t}\left( x | z\right) \)。现在我们要考虑\(u_{t}\left( x \right)\) 应该怎么被定义的问题。首先,我们考察一下连续性方程是否能被满足,这个是一切假设的前提。
考虑到条件分布下的连续性方程 \(\frac{\partial}{\partial t} p_{t}\left( x | z\right)=-\nabla\left( u_{t}\left( x | z\right) \cdot p_{t}\left( x | z\right) \right)\), 带到上式可得,
我们希望能得到(2),即
推导到这里, \(u_t(x) \)需要满足以下形式:
也就是说,只要 \(u_t(x)\) 满足上边等式中的形式,就可以用 \(u(x|x_1)\) 和 \(p(x|x_1)\) 取代 \(u(x)\) 和 \(p(x)\)。
这个边缘向量场的定义应该是为了这盘醋(论文中的定理1)包的这个饺子,针对这个公式具体点说也就是在数据点 \(x\) 处的向量场 \(u_t(x)\) 是通过对所有可能的初始条件 \(x_1\) 的条件向量场 \(u_{t}\left(x \mid x_{1}\right)\) 加权积分得到的,权重是由条件概率密度 \(p_t(x∣x_1)\) 和边缘概率密度 \(p_t(x)\) 的比值决定的。
Conditional Flow Matching
虽然基于上述过程已经推导出了 \(u_t(x)\) 的形式,但上述的积分依然不容易求解。因此作者给出了一种更容易求解的形式(如下所示),并且证明了下面这个损失函数与原本损失函数的等价性。
这样写的直觉是,如果(11)是一个好的代理目标,那么我们直接对(11)进行优化就行,因为很有可能在给定 \(z\) 的情况下,条件速度场是可采样或者可解的,类似分数匹配的条件概率一样。
作者证明了 \(\mathcal{L}_{CFM}\) 和 \(\mathcal{L}_{FM}\)的等价性,也就是说优化 \(\mathcal{L}_{CFM}\) 等价于优化 LFM:
定理二: 假定对于所有 \(x\in\mathbb{R}^d\) 且\(t\in[0,1]\)都有 \(p_t(x)>0\),那么 \(\mathcal{L}_{CFM}\) 和 \(\mathcal{L}_{FM}\) 相差一个与 \(θ\) 无关的常数,即有 \(\nabla_\theta\mathcal{L}_\mathrm{FM}(\theta)=\nabla_\theta\mathcal{L}_\mathrm{CFM}(\theta)\)。
证明: 因为优化目标是 \(θ\),我们考察 \(\nabla_{\theta}L_{CFM}\left( \theta \right)\),有
类似的,我们考察(6)对于 \(θ\) 的导数,有
对于两个式子的第一项有,
所以现在的关键在于,以上两个式子的右边第二项有什么联系?我们继续化简
如此即证明了上述的定理,即
这就意味着,优化(11)和优化(7)对于 \(θ\) 来说是一样的,或者说你为了得到(7)中的参数化速度场,你可以以(11)为目标,构造条件速度场,然后用网络拟合 \(u_{t}\left( x | z \right)\) 就行,至于拟合到的是什么没关系,实际推理的时候你可以直接把 \(u_{\theta}\left( t,x \right)\) 当作 \(u_t(x)\) 的近似来使用。
到这里,构造代理目标的目的就完成了。很有意思的是,我们在满足连续性方程的情况下构造的 \(u_t(x)\) ,直接可以让我们用条件分布作为代理目标,来拟合边缘分布。事实上,用类似的思路,也可以证明在扩散模型SDE框架里,条件分数匹配的目标跟得分匹配的目标对于优化网络参数而言是一致的,具体可以参考苏剑林的《生成扩散模型漫谈(十八):得分匹配 = 条件得分匹配》。
条件概率路径和向量场
上面我们已经证明了条件概率路径和条件向量场可以等价于边缘概率路径和边缘向量场,并且用 CFM 的方式进行训练和 Flow Matching 的效果是相同的。但现在 \(u_t(x|z)\) 的形式依然是不知道的,因此我们需要进一步定义具体的条件概率路径的形式。就像 DDPM,我们需要定义具体的前向过程,才能基于这个过程进行训练。
原始推论
Lipman的原始论文里作者给出的条件概率路径的形式为:
其中 \(μ\) 是和时间有关的高斯分布均值,\(σ\) 是和时间有关的高斯分布方差。并且为了使这个条件概率路径有比较良好的性质,作者设定在 \(t=0\) 时 \(p(x)\) 为标准高斯分布 \(\mathcal{N}(x|0,I)\),也就是 \(\mu_0(x_1)=0\),\(\sigma_0(x_1)=1\);同时希望条件概率路径最终能够生成目标样本,所以当 \(t=1\) 时高斯分布的均值和方差 \(\mu_1(x_1)=x_1\)、\(\sigma_1(x_1)=\sigma_{\min}\),其中 \(\sigma_{\min}\) 时一个足够小的数。
同时,作者将 flow 定义为以下形式:
其中 \(x\sim\mathcal{N}(0,I)\) 服从标准高斯分布,根据上文所述的 CNF 的 ODE 表示,有:
这样我们就可以将损失函数 \(\mathcal{L}_\mathrm{CFM}\) 的形式变为如下形式:
在上边的式子里,\(\psi_t\) 的形式是已知的,并且 \(x_0\sim\mathcal{N}(0,I)\),所以上边的式子是可以求解的,是实用、可以实现的损失函数。同时,也可以得到条件向量场的形式,即:
定理三: 令 \(p_t(x|x_1)\) 是上述的高斯概率路径,\(\psi_t\) 是上述的 flow map,那么 \(\psi_t(x)\) 对应于唯一的向量场 \(u_t(x|x_1)\),且形式为:
证明: 由于 \(\psi_t\) 可逆,令 \(x=\psi^{-1}(y)\),则可以写出:
同时对 \(ψ_t\) 求导得到:
根据 ODE,推导得到:
泛化推论
原文推导相对比较晦涩,这里尝试简化+泛化一下
假设边缘概率分布 \(p_{t}\left( x \right)=N\left( x \space | \space \mu_{t},\sigma_{t}^{2}\right)\),当 \(t=0\) 时刻,\(x_{0} \sim N\left( \mu_{0},\sigma_{0}^{2} \right)\) ,概率流里的其中一条可以表示为
上面公式是高斯分布重参数化的形式,因为假设 \(p_t(x)\) 遵循均值为 \(\mu_t\)、标准差为 \(\sigma_t\) 的高斯分布,因此 \(\psi_t\) 可以重参数化为 \(\psi_t = \mu_t + \sigma_t * \epsilon\) 的格式,\(\epsilon\) 是遵循标准正态分布的随机变量,因为 \(x_0\) 是以均值为\(\mu_0\)、标准差为 \(\sigma_0\) 的高斯分布,所以我们这里用 \(\epsilon = (x_0 - \mu_0)/\sigma_0\) 代替,于是得到了(13)。Lipman等人的论文里因为初始分布 \(x\) 是标准高斯分布,所以直接用 \(x\) 替换了\(\epsilon\),这里的写法是参考了Alex Tong的论文用一个更泛化的写法,\(x\) 是非标准正态分布。
注意:
- 概率流有无穷多条,这个只是其中一条比较简单的,相当于高斯分布的重参数化形式;
- 假设边缘分布是高斯分布,不是一个很合理的假设,因为两个分布之间的过渡分布,即便其中一个是高斯分布,过渡分布一般也不是高斯分布,但是如果我们将边缘分布转为条件概率分布,有可能会变得很合理,下文我们也将指出,我们可以构造出这样的分布;
- (13)中的 \(x_0\) 可以认为代表初始分布,这里也相当于假设了初始分布为高斯分布,但注意并没有限制它是不是标准正态分布,这个假设极为重要。
令 \(y=\psi_t\left(x_0\right)\),那么我们有\(x_0=\psi_t^{-1}\left(y\right)\), 即正向和逆向的flow map,根据(13) 有
根据 \(y=\psi_t\left(x_0\right)\) 和(14)式,有
将 \(y\) 改为 \(x\),于是有
注意,这里的推导方法跟Lipman等人的论文略有不同,主要参考的是Alex Tong等人的论文写法,不过基本思想是一样的,本质上就是找到flow map的表达式,然后将表达式里的 \(x\) 替换成 \(y\), 就得到了\(u\) 的通用表达式。这里的推导,不需要假设初始分布是标准正态分布,意味着初始分布的构造有很大的自由度。(15)我们如果将其变为条件分布,那么则有
其中 \(z\) 可以是任意的coupling,这个很关键。如果将 \(z\) 设为 \(x_{1}\) ,那么就是Lipman的原始论文里的式子。有了(15)或者(16)以后,我们实际上就可以直接带入(11)优化了,具体取决于随时间变化的均值和方差怎么定义。
条件分布例子
VE(Variance Exploding) diffusion
选择如下形式:
这对应着 \(\boldsymbol\mu_t=\mathbf x_1,\,\sigma_t=\sigma_{1-t}\) 的情形。代入条件速度场(15)或者(16)得:
相应的条件流为:
对应score matching 的方式,这种过程能够使模型生成数据时探索范围更广的空间,有助于生成多样的样本。
VE像一个自适应速度场
- 距离越远,移动越快
- 接近目标时会自动减速
- 保证平滑收敛
VP(Variance Preserving) diffusion
考虑如下形式
这对应着 \(\boldsymbol\mu_t(\mathbf x_1)=\alpha_{1-t}\mathbf x_1,\,\sigma_t(\mathbf x_1)=\sqrt{1-\alpha_{1-t}^2}\) 的情形。代入条件速度场(15)或者(16)得:
相应的条件流为:
这种过程在引入噪声的同时保持整体方差不变,这样能使数据的分布比较稳定。(可以看出 DDPM 就是这种过程)。VE diffusion 或 VP diffusion 的条件流对时间 \(t\) 不是线性关系,也就是说它们的轨迹会拐弯。
flow matching
如果我们选择如下形式:
那么相当于 \(\mu_t = t x_1, \sigma_t = 1 - (1 - \sigma)t\),即初始时刻为标准正态分布,\(t=1\) 时 \(x \sim \mathcal{N}(x_1, \sigma^2)\),那么代入(15)或者(16)我们可以得到:
这个就是 Lipman 等人论文里的条件速度场表达式。注意,这里虽然条件速度场的表达式和 Lipman 等人的论文里是一样的,但是跟论文中的拟合目标不太一样。笔者之前看很多文章或者帖子都是直接誊抄的原始论文公式而并没有说明清楚,因此这里简要说明一下。式子中的 \(x\) 并不是初始分布或者采样点 \(x_0\),而相当于是 \(\psi_t(x_0)\),根据定义我们有:\(x = \psi_t(x_0) = t x_1 + (1 - (1 - \sigma)t)x_0\), 代入(17)式可以得到:
这就是 Lipman 等人的论文里的(23)式。可以看到,在给定 \(x_0\) 后,速度是定值,flow map 为直线。
Optimal Transport Conditional(1-rectified flow)
如果我们选择让 flow map 的均值是 \(x_0\) 和 \(x_1\) 的线性插值(直线),即:
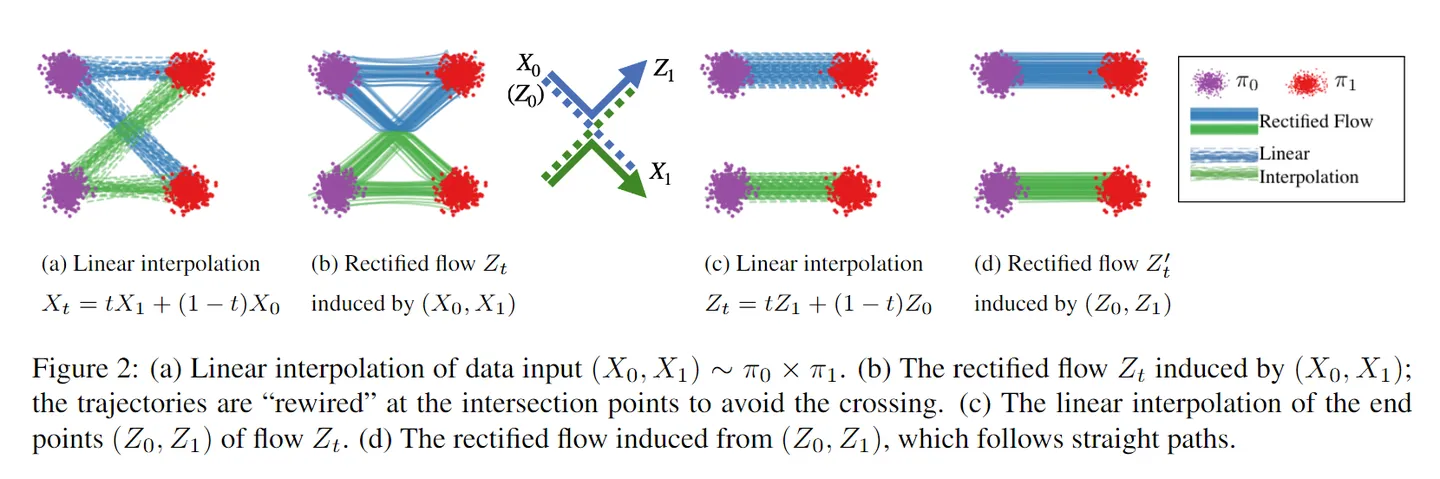
我们可以看到,(18)给出来的条件速度场,是一个固定值,即条件分布是由一个恒定的速度场推动,从初始分布或者初始采样数据点,由恒定的速度走直线到目标分布或者目标采样数据点,这个条件速度场对应的条件概率流也称为rectified flow(1-rectified flow),或者I-CFM(conditional flow matching with independent coupling),或者optimal transport。大家看到这里可能会很兴奋,因为这个拟合目标实在太过于简单且太过于优雅了,就是说给定时间 \(t\) 和 \(x\),实际上你要拟合的速度场就是你的采样对 \((x_0,x_1)\) 的差值,实现起来简单且计算起来也很简单。以下是几点takeaway:
- 虽然Lipman等人的论文里,用了初始时刻为标准高斯的假设,但(conditional) flow matching并不要求初始分布 \(q\left( x_{0} \right)\) 是一个高斯分布,实际上可以是任意形式,只要满足 \(p_{0}=q_{0}*N\left( x \space | \space 0, \sigma^{2}\right)\) ,就可以连续推导出以上式子;
- 所谓“走直线”,指的是条件概率分布,而不是我们想求的最原始的边缘分布,尽管拟合目标是所谓的直线,但实际边缘分布或者推动边缘分布的速度场,仍然是曲线,所以才有类似2-reflow或者OT-CFM等工作出来,尽可能将曲线拉直;
源代码解析
CFM (8gaussian-moons)
最核心的两段代码如下
def sample_conditional_pt(x0, x1, t, sigma):
"""
Draw a sample from the probability path N(t * x1 + (1 - t) * x0, sigma), see (Eq.14) [1].
Parameters
----------
x0 : Tensor, shape (bs, *dim)
represents the source minibatch
x1 : Tensor, shape (bs, *dim)
represents the target minibatch
t : FloatTensor, shape (bs)
Returns
-------
xt : Tensor, shape (bs, *dim)
"""
t = t.reshape(-1, *([1] * (x0.dim() - 1)))
mu_t = t * x1 + (1 - t) * x0
epsilon = torch.randn_like(x0)
return mu_t + sigma * epsilon
def compute_conditional_vector_field(x0, x1):
"""
Compute the conditional vector field ut(x1|x0) = x1 - x0, see Eq.(15) [1].
Parameters
----------
x0 : Tensor, shape (bs, *dim)
represents the source minibatch
x1 : Tensor, shape (bs, *dim)
represents the target minibatch
Returns
-------
ut : conditional vector field ut(x1|x0) = x1 - x0
"""
return x1 - x0以上代码注释已经非常清楚了,笔者这里不做过多解读。以下是训练主循环
sigma = 0.1
dim = 2
batch_size = 256
model = MLP(dim=dim, time_varying=True)
optimizer = torch.optim.Adam(model.parameters())
device = "cuda"
model.to(device)
start = time.time()
for k in range(20000):
optimizer.zero_grad()
x0 = sample_8gaussians(batch_size).to(device)
x1 = sample_moons(batch_size).to(device)
t = torch.rand(x0.shape[0]).type_as(x0).to(device)
xt = sample_conditional_pt(x0, x1, t, sigma=0.01)
ut = compute_conditional_vector_field(x0, x1)
vt = model(torch.cat([xt, t[:, None]], dim=-1))
loss = torch.mean((vt - ut) ** 2)
loss.backward()
optimizer.step()
if (k + 1) % 5000 == 0:
end = time.time()
print(f"{k+1}: loss {loss.item():0.3f} time {(end - start):0.2f}")
start = end
node = NeuralODE(
torch_wrapper(model), solver="dopri5", sensitivity="adjoint", atol=1e-4, rtol=1e-4
)
with torch.no_grad():
traj = node.trajectory(
sample_8gaussians(1024).to(device),
t_span=torch.linspace(0, 1, 100).to(device),
)
plot_trajectories(traj.cpu().numpy())主流程主要就是采样 \(x_t\) ,得到 \(u_{t}\left( x | x_{0},x_{1}\right) \),通过网络计算 \(u_{\theta}\left( t,x \right)\),算loss,backward。推理采样实际上就是调用了ODE的数值积分求解器,感兴趣的同学可以自己去看采样的源代码。执行结果作图如下:
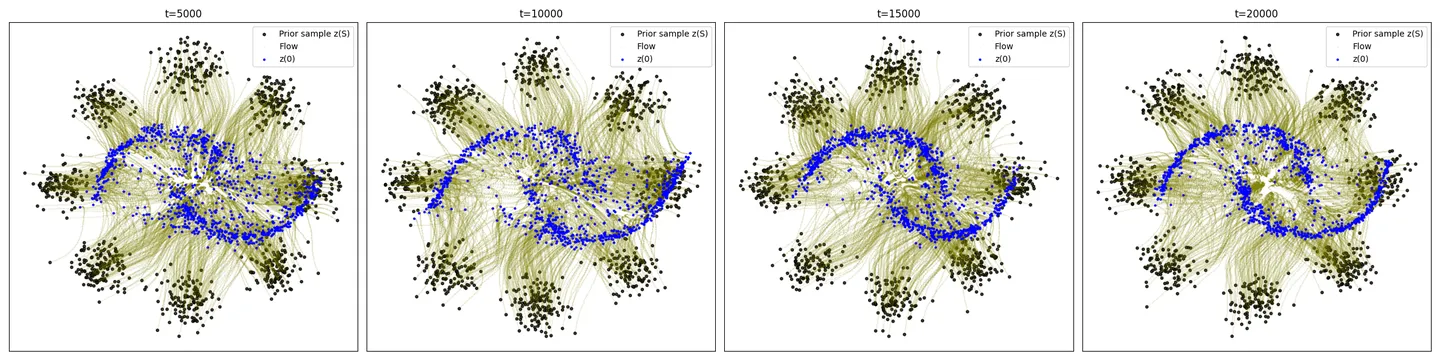
可以看到,CFM在2W步的时候基本已经比较好的能从8个高斯分布变化到月牙分布,但是细心的小伙伴应该能发现,采样的路径并不是直的,甚至存在很多Lipman等人论文里提到的overshoot的现象。也就是说,虽然看起来是走直线,但实际学到的边缘速度场,仍然是曲线。
CFM (Reflow例子)
这里给大家再跑一下Liu Xingchao等人用来解释reflow的例子,同步sample生成的代码
def sample_reflow_samples(sample_nums):
from torch.distributions import Normal, Categorical
from torch.distributions.multivariate_normal import MultivariateNormal
from torch.distributions.mixture_same_family import MixtureSameFamily
D = 10.
VAR = 0.3
COMP = 3
initial_mix = Categorical(torch.tensor([1/COMP for i in range(COMP)]))
initial_comp = MultivariateNormal(
torch.tensor(
[
[D * np.sqrt(3) / 2., D / 2.],
[-D * np.sqrt(3) / 2., D / 2.],
[0.0, - D * np.sqrt(3) / 2.]
]
).float(),
VAR * torch.stack([torch.eye(2) for i in range(COMP)])
)
initial_model = MixtureSameFamily(initial_mix, initial_comp)
samples_0 = initial_model.sample([sample_nums])
target_mix = Categorical(torch.tensor([1/COMP for i in range(COMP)]))
target_comp = MultivariateNormal(
torch.tensor(
[
[D * np.sqrt(3) / 2., - D / 2.],
[-D * np.sqrt(3) / 2., - D / 2.],
[0.0, D * np.sqrt(3) / 2.]
]
).float(),
VAR * torch.stack([torch.eye(2) for i in range(COMP)])
)
target_model = MixtureSameFamily(target_mix, target_comp)
samples_1 = target_model.sample([sample_nums])
return samples_0, samples_1然后将主循环里x0和x1的生成以及对应的采样改成
# x0 = sample_8gaussians(batch_size).to(device)
# x1 = sample_moons(batch_size).to(device)
x0, x1 = sample_reflow_samples(batch_size)
x0, x1 = x0.to(device), x1.to(device)
# sample_8gaussians(1024).to(device),
traj = node.trajectory(
sample_reflow_samples(1024)[0].to(device),
t_span=torch.linspace(0, 1, 100).to(device),
)执行以后结果如下
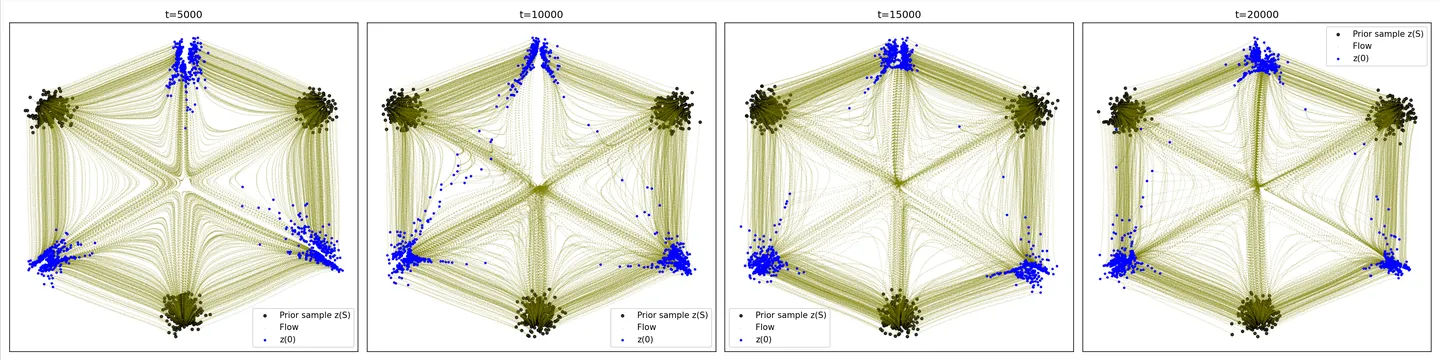
这个结果和colab里的轨迹分布式类似的。换成论文里的配图例子,即两个gaussian横向变化为另外两个gaussian如下图
改动主要就是把comp变为2,然后source center为[(-10, 10), (-10, -10)],target center为[(10, 10), (10, -10)],执行结果如下:
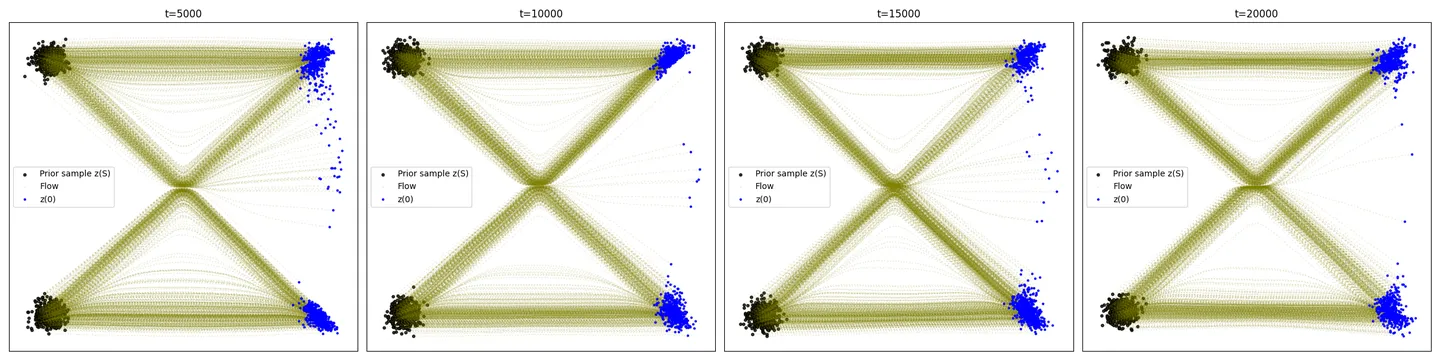
可以看到,在I-CFM,或者说1-reflow的模式下,实际的边缘速度场或者轨迹分布得到的是类似Liu等人论文里Fig.2(b)里的效果,突出体现为会有一部分轨迹流到中心后“拐弯”到目标分布,并且整体看起来是对称的。关于产生这种现象的原因,我们放到结论和探讨部分稍微展开聊一下,简单说是由于 (1) 样本配对的随机性; (2) ODE学习到的速度场是光滑的(用Liu Xingchao在知乎的文章里称之为“必须是因果”的);
OT-CFM
关于这块的理论在这里不做展开,这里主要是想给大家展示一下所谓“直线”的边缘分布是怎样的,实际上从概率流ODE和Flow Matching工作出来后,很多工作都致力于想办法尽可能“拉直”边缘分布的轨迹,而不仅仅是条件分布。从两个高斯到两个高斯的例子我们可以看出,如果以(-10, 10)为中心的高斯分布采样,对应的目标分布都在(10, 10)里,以及(-10, -10)为中心的高斯分布采样的目标分布都在(10, -10)里,那么我们手动去画轨迹,边缘分布的轨迹真的基本上都是直线,那么我们去逼近直线得到的几乎也都是直线。OT-CFM是Alex Tong等人提出的,在采样数据集合中,先对传输路径进行优化,即尽可能减少source到target点对的传输距离之和,那这样在样本相对均衡的情况下,就能做到(以2-gaussian到2-gaussian为例)我们期望的(-10, 10)对(10, 10)和(-10, -10)对(10, -10)。考虑到在对超大样本集下对全部的样本进行排序的代价过大,所以实操的时候是在mini-batch维度上进行距离优化。主要的代码改动如下
from torchcfm.optimal_transport import OTPlanSampler
ot_sampler = OTPlanSampler(method="exact")
# Draw samples from OT plan
x0, x1 = ot_sampler.sample_plan(x0, x1)即在得到x0和x1以后调用ot_sampler.sample_plan 尽可能减少传输距离,虽然是一种次优的方法,但实际效果还不错,以下会放一些例子。
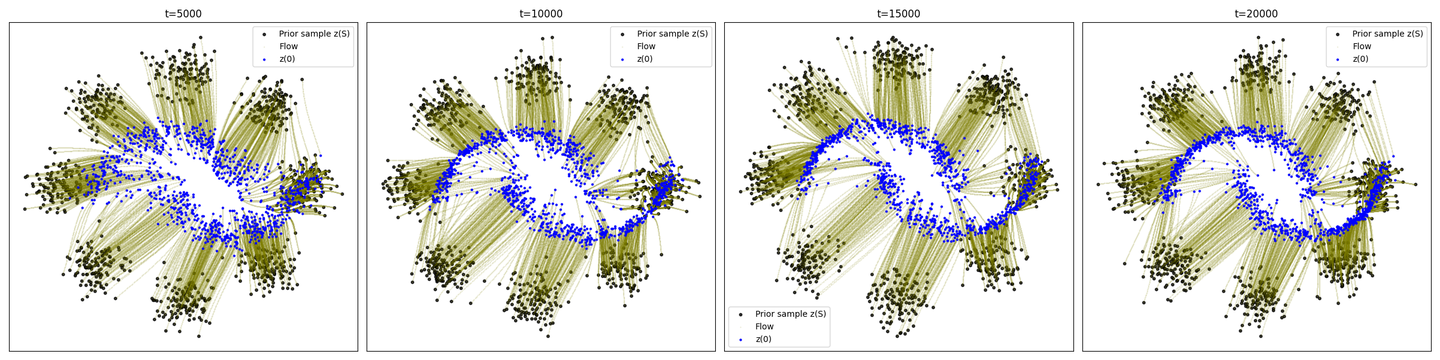
8gaussian-moons
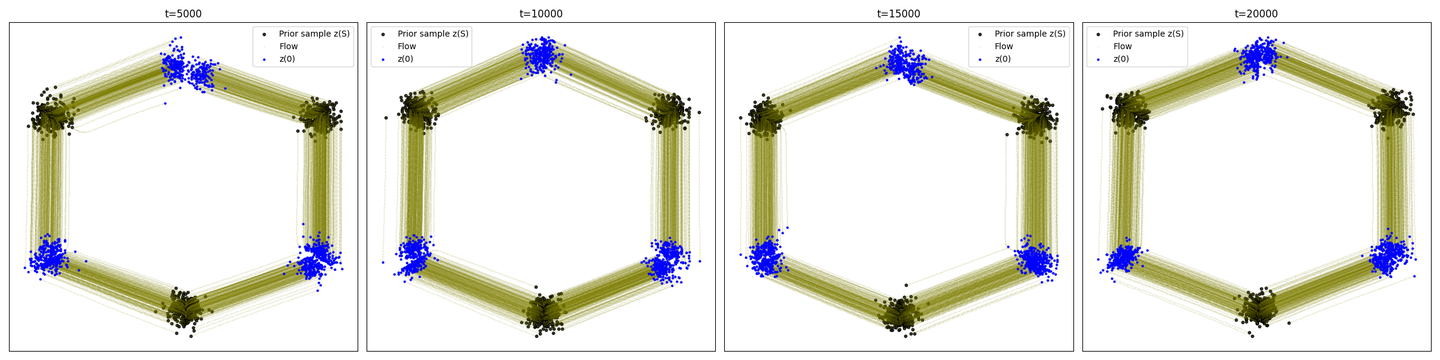
Reflow的3-gaussian-to-3-gaussian
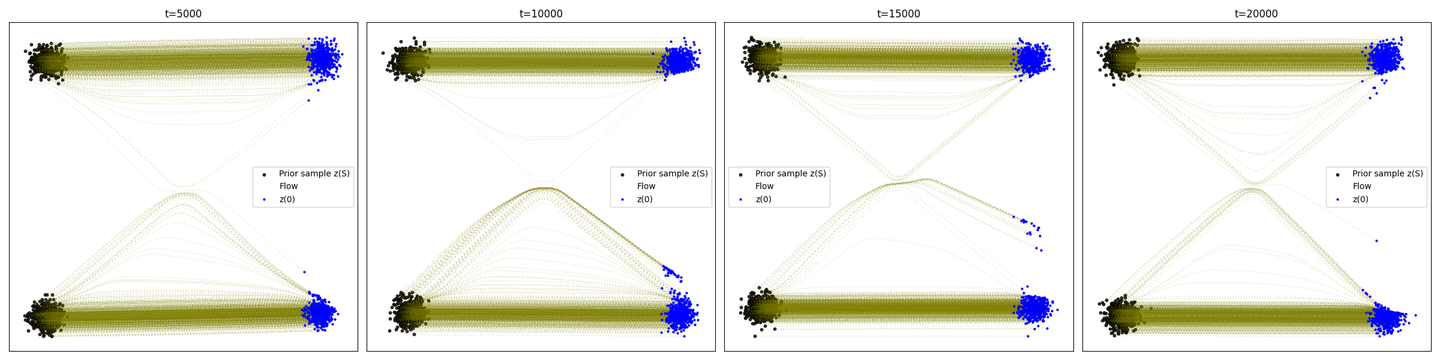
Reflow的2-gaussian-to-2-gaussian例子
总结和探讨
这一部分简单回顾一些要点,并讨论一些以上部分因为篇幅没有展开讨论的问题。
- 关键需要掌握的是流匹配的动机(构建速度场通过数值积分求解位移),以及通过代理目标的方式将流匹配转化为条件流匹配,核心目的是让我们的优化目标里的各项都是可解或者可获得的;
- 从概率路径的角度上来说,解是无穷多的,不同的方法本质上讲是在于构造尽可能简单、直接、易解的概率路径;
- 关于“走直线”,大家很容易理解的是,给定 \(x_0\) 和 \(x_1\) ,构造一条线性插值的flow map,可以让条件概率分布路径变为直线,条件速度场为恒定速度,但这里很重要的一点是实际的边缘概率分布路径并不是一条直线,我们是通过拟合条件速度场来逼近边缘速度场,即使我们证明了对于参数 \(\theta\) 来说优化目标是等价的,但终究还是有一些gap,至于这个gap来源的底层原理,目前暂时无法用更通俗易懂的语言讲清楚,待补充;
- 生成模型本质上还是将分布转化为分布的过程,从更高的观点来看,无论是SDE还是ODE系列方法,似乎都可以统一到stochastic interpolant的框架里;
- 关于源代码部分中的2-gaussian问题,呈现了对称的曲线直线混合分布,这里稍微多解释两句。首先直观的理解为什么边缘速度场给出的是曲线,我们考虑(source1, target1)和(source2, target2)为分布上的最优匹配,那么实际在采样过程中,你不可避免的会采样到(source1, target2)和(source2, target1)这种组合,那么你就会有很多“交叉”的路径,实际上神经网络学习到的往往是“平均”的结果,所以你实际在source1里采样一个点,它的目标既可能是target1也可能是target2,因此它的平均行为就是初始速度的方向是沿着target1和target2两个方向之间的某一方向,这个是比较好理解的。那么为什么概率路径或者实际的轨迹不会交叉?假设你要拟合的速度场是光滑的,那么对于处于中间的某一点来说,在这里对x的导数具有唯一值,那么因此镜像的一个平均结果就是上下对称,并且以正中心的那条线为“分水岭”的一系列曲线簇。笔者这里无法给出严格的证明,但从道理上看似乎是这么回事,并且理论上讲正中心那条线的y方向速度分量为0,这是一个推论;
- 既然很多情况下曲线是由于样本配对的随机性导致的,那么消解的方法其实也很直观,就是尽可能减少传输距离,使得某一些分布能固定传输到离它最近的分布里,从实操上看大体有两种方法:(1) 通过reflow论文里提到的方式,因为我们看到虽然路径是曲线,但训练好的模型能自动帮训练样本找到最有传输路径对应的分布,所以通过pretrain好的flow模型进行再次采样得到训练集,再训练一个flow模型,以此往复\(n\)次,那么理论上讲得到的路径会越来越直,但也会因为逐渐累积误差导致性能下降;(2) 对于训练样本,直接对传输距离进行优化,那么就能尽可能避免路径交叉的问题;无论是对于(1)还是对于(2),我们应当充分认识到,现实中的数据分布是相当复杂的,光靠简单的方法仍然是很难实现所谓的“走直线”的目标的;
Reference
An introduction to Flow Matching