Minieye
车舱VLM
💡 ****
任务
任务主要包含舱内感知和舱外感知两种任务,具体来说,舱内和舱外感知都会有很多子任务,比如说,舱内就包含人物的基础属性(性别,年龄,位置,动作,衣着等),遗落物体,宠物等等;舱外又包含天气,道路情况,停车后周围环境等。
数据
数据包含不同阶段的数据处理,pretrain,sft,rl
- pretrain数据:大部分为为Caption数据,用来训练模型的图文知识,也包含一些文本数据,为了防止模型的语言能力遗忘问题
- sft数据:这部分数据就包含了多种任务,包含caption、ocr、grounding、gqa、text、多轮对话等,也包含 了大量的内部数据,主要为舱内和舱外的感知对话数据
- RL数据:这部分为两种数据 一种是偏好数据集用于DPO训练,另外一种是prompt数据用于GRPO训练
模型和训练
模型主要的结构为 前期采用的是llava架构, 后期采用的是qwen2.5vl以及qwen3-vl, 大小主要采用0.8B,4B,8B
训练步骤同样也分为pretrain-sft-rl三部分, 前期会做pretrain, 后期考虑到迭代速度和资源等原因会抛弃掉pretrain只做后训练
- pretrain:包含align和知识灌入(caption):50M
- sft:实验数据比例:20M
- rl:借鉴internvl-3.5的成功经验,采用cascade强化训练的方案(用off-policy 预热,这样模型生成的 rollouts 质量更高,训练会更加稳定,接着用on-policy refine)
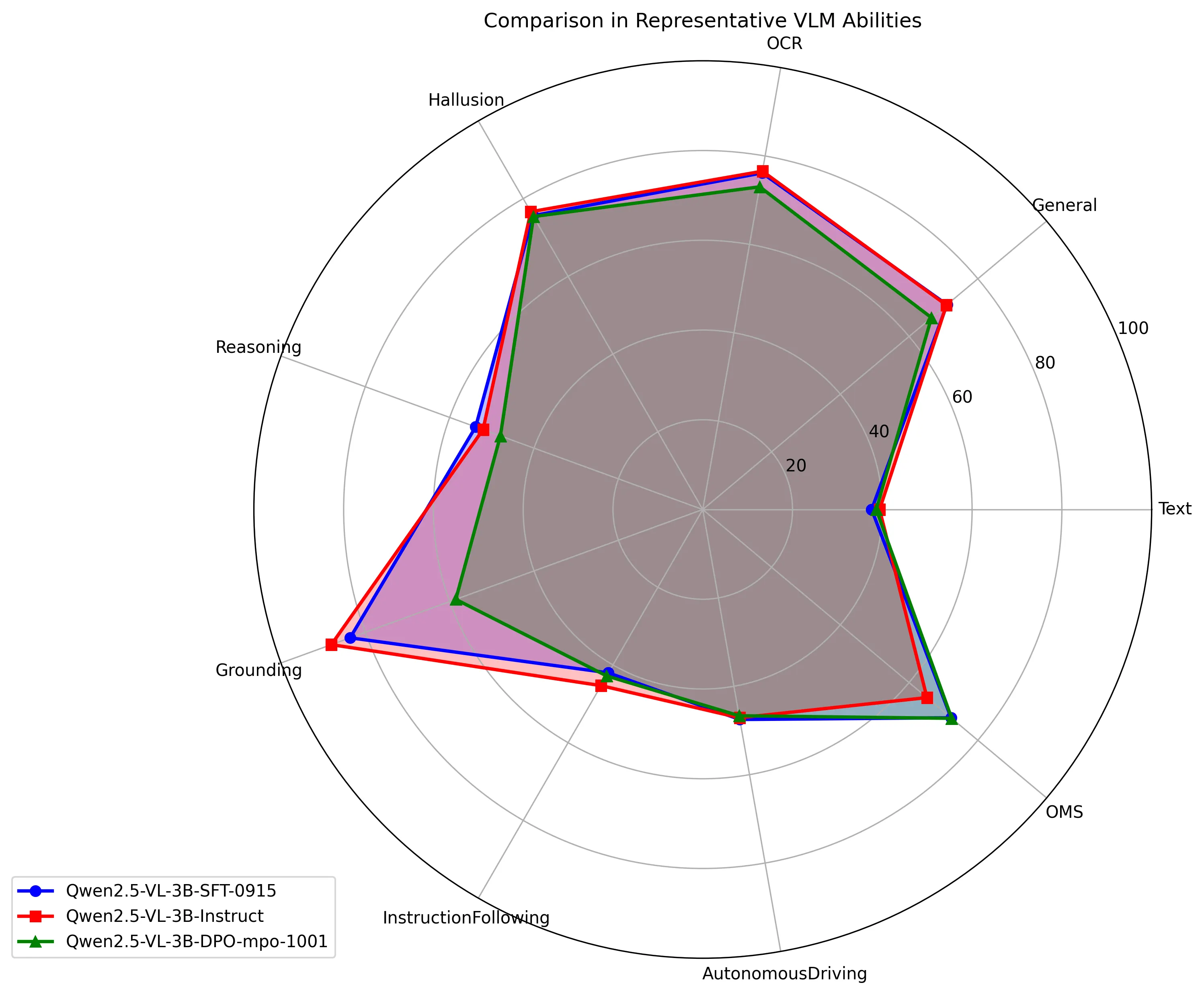
评测
利用vlmevalkit框架 调研主流的benchmark 并构建内部任务的benchmark, 分维度评测和量化性能指标
大的维度主要分为 多模,语言,项目任务,每个大维度里面又会细分细粒度的维度
Agent
这部分我只是参与了前期的框架调研和demo展示
目前整个项目的Agent框架流程主要包含 意图识别Agent、拒识Agent以及各自功能模块的Agent等
探索方案
- 数据收集和处理框架: 一直在完善数据的整体pipeline,包含数据比例以及数据质量评估的方案
- 压缩视觉token:在实际的使用中,视觉部分占用的token的占比还是比较大的,尤其是当传感器的分辨率较大时,所以我们探索了几种不同框架下压缩视觉token的方式,我们也自己实践并探索对比了一下 选出一个比较好的方案:
- 正反馈循环系统:为了得到一套正反馈系统,由之前小模型的项目经验,建立了一套:数据采集—数据处理—模型训练—模型评估—badcase tag标签,这里主要说明basecase的分析,首先评测的数据我们会有一套tag系统(借鉴数据标注时的管道系统,通过小模型和人工规则筛取)来对现有的badcase分为比较细粒度的tag标签来查看模型存在的问题,然后定时收集和扩充我们的训练集和测试集
- 提升推理输出速率:这部分我们也在调研和试验阶段,主要基于自投机采样方案来增大模型的推理速度
- GUI-Agent:这部分同样也在调研和试验阶段,主要的方案主要参考UI-TARS2的方案来构建车机端的在线UI沙盒系统
商汤
产线动作识别
💡 ****
- 工作整体流程:
对产险上的video做动作的识别, video帧有标注,分不同的工位 - 数据及GT(产险时序start,end帧的序号及对应动作类别(16+1)):
- 关于 video action recognize
- 以TDN为网络框架基础
- 工作细节:
利用之前框架可以提取每一个segmemt的embedding, 在通过TRN的方式结合未来帧的信息来预测当前帧的输出结果
车舱项目Gaze识别
💡 ****
- 整体工作流程:3d gaze-vec的回归,满足各个区域及分心的precision和recall精度指标要求
- 数据相关标定及采集:
- 泛化性能优化工作:
- 模型结构:backbone为mobilenet-V2搜索版本
loss
class CA_Loss_op(nn.Module):
def __init__(self):
super(CA_Loss_op, self).__init__()
def forward(self, gaze, label):
totals = torch.sum(gaze * label, dim=1, keepdim=True)
length1 = torch.sqrt(torch.sum(gaze * gaze, dim=1, keepdim=True))
length2 = torch.sqrt(torch.sum(label * label, dim=1, keepdim=True))
res = totals / (length1 * length2)
# angle = torch.mean(torch.acos(torch.min(res, torch.ones_like(res)*0.9999999))) * 180/math.pi
angle = torch.acos(torch.min(res, torch.ones_like(res) * 0.9999999)) * 180 / math.pi
angle = angle.reshape(-1)
thresh_old_angle = 5
angle_sorted, idx = torch.sort(angle, descending=True)
idx_threshold = -1
nums_min = 10
while idx_threshold < nums_min:
for i in range(len(angle_sorted)):
if angle_sorted[i] > thresh_old_angle:
idx_threshold += 1
else:
idx_threshold = i
if idx_threshold > nums_min:
break
thresh_old_angle = thresh_old_angle - 1
sorted_idx = idx[:idx_threshold]
ohem_loss = angle[sorted_idx]
angel_avg = ohem_loss.sum() / (idx_threshold + 1)
return angel_avg
单目深度估计
💡 基于深度估计的单目相机方案调研和落地
- 论文:manydepth
PDD
推词服务:
💡 ****
- 主要场景包含:搜索框底纹词推荐、猜你想搜、腰部推荐
- 模型:CTR、CVR模型
- 输入特征:用户历史搜索词、点击商品为trigger,围绕u2i2q、u2q2q、u2c2q(c为用户偏好类目)
猜你想搜(搜索中)&底纹
重排阶段LTR模型:
💡 重排阶段LTR模型,包括特征生成和模型的部署
- 主要工作:重排时针对item权重的学习双塔模型,item主要权重包含:price,精排分数,相关性打分,销量等
实验室
目标检测遮挡优化
💡 目标检测遮挡问题:
当两个不同类别物体产生遮挡时,分类会对定位造成混淆
- 模型思路:在做定位时,很多时候可能proposal会向非对应gt去回归。所以尝试在定位分支中加入物体分类的信息。