概述
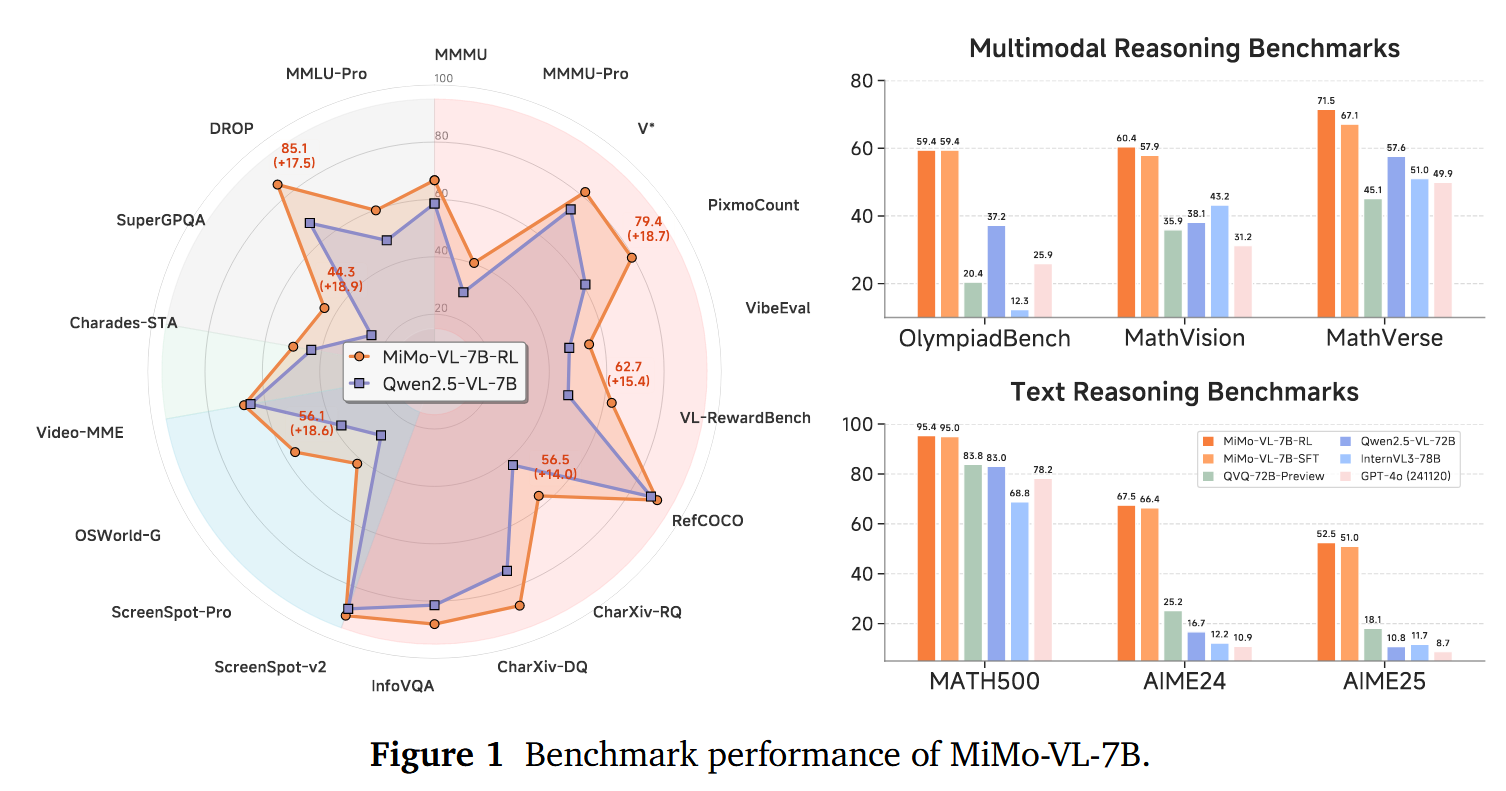
小米团队近日发布了MIMO-VL-7B-SFT和MIMO-VL-7B-RL,这是两个强大的视觉语言模型,MIMO-VL-7B-RL在40个评估任务中的35个上优于QWEN2.5-VL-7B,对于GUI Grounding任务,它在OSWorld-G上设置了一个新标准,甚至超过了UI-TARS等专业模型。模型通过四个阶段的预训练(2.4T Token)与Mixed On-policy 强化(MORL)整合了多样化的奖励信号。
在文章中,作者提到了两个重要的发现:
- 从Pre-Traing 训练阶段中加入高质量且覆盖广的推理数据对于强化模型性能至关重要。
- Mixed On-policy 强化学习进一步增强了模型的性能,同时实现了稳定的同时改进仍然在性能方面具有挑战性。
Pre-Training
模型结构
整个模型还是采用了VIT-MLP-LLM的结构,具体来说,视觉模型采用了Qwen2.5-VL中的视觉encoder,LLM采用了自家的语言模型MiMo-7B-Base。
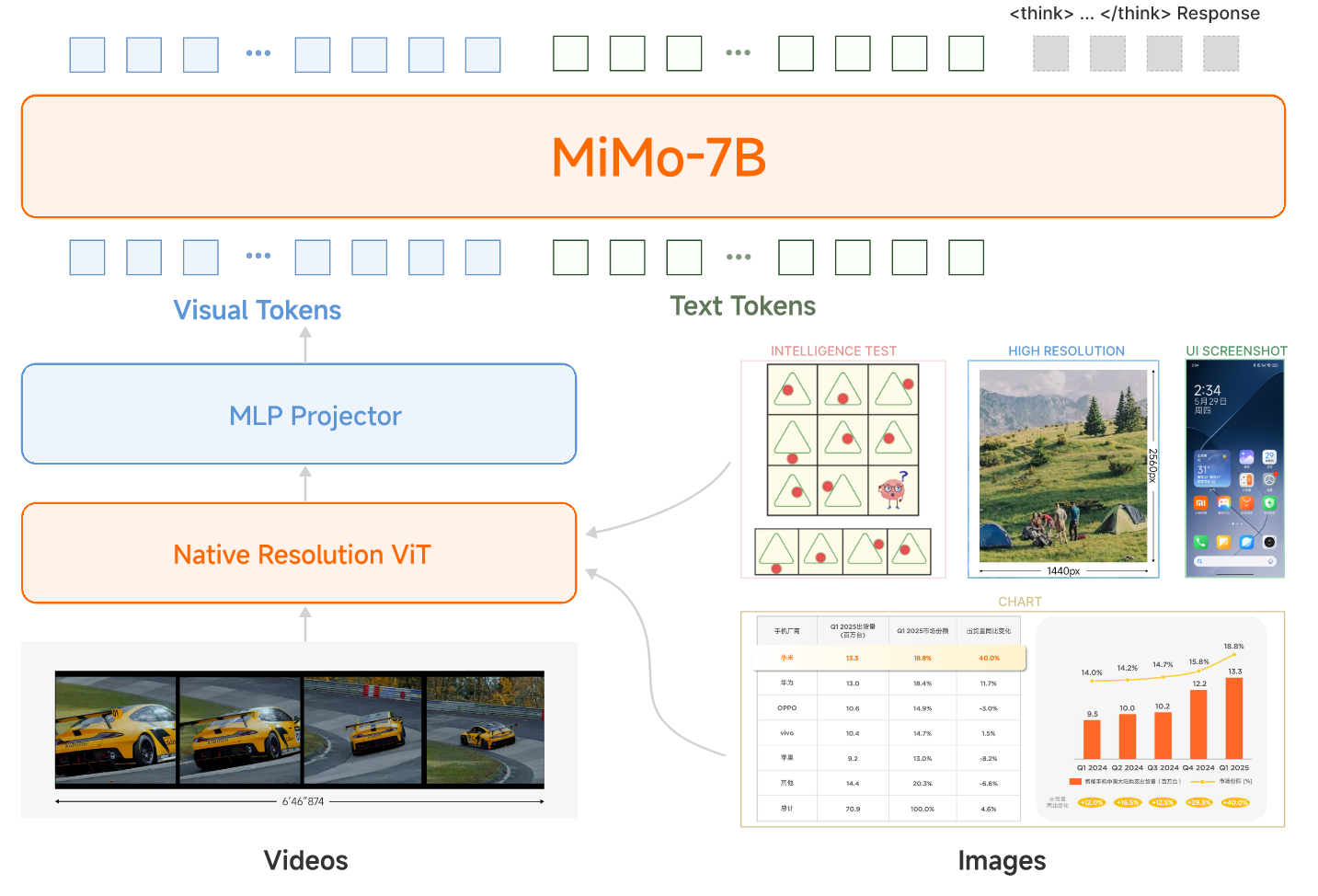
整个Pretraining采用了四个阶段的训练,每个阶段采用的数据,模型训练参数和模型参数如下面两表所示
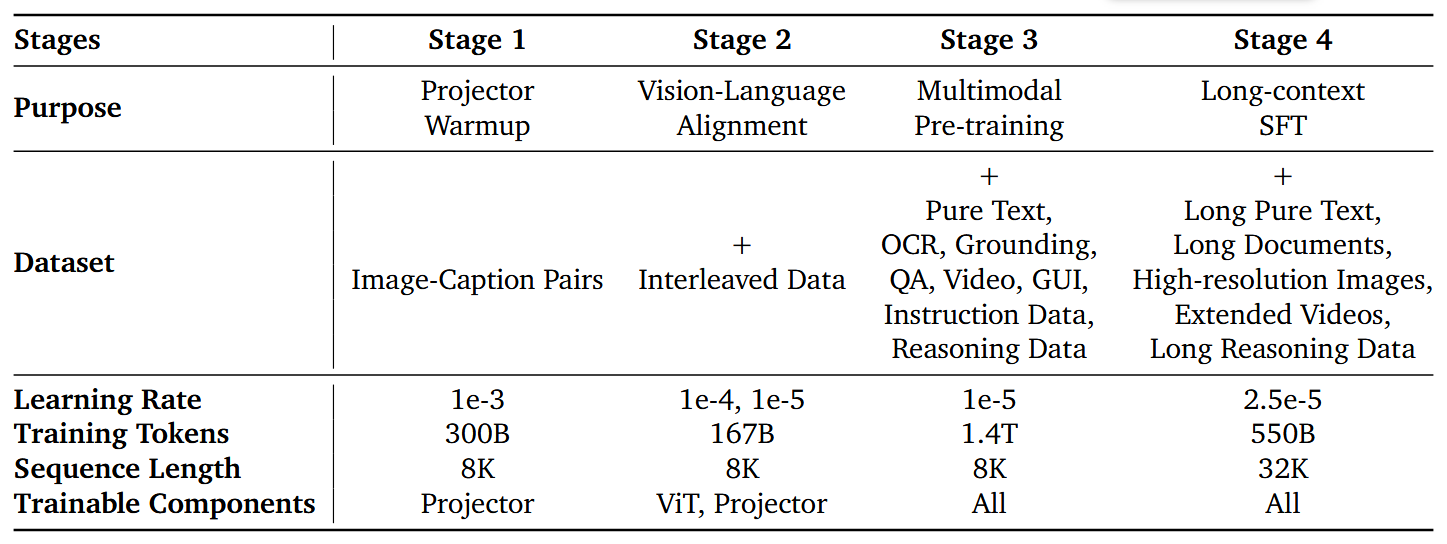
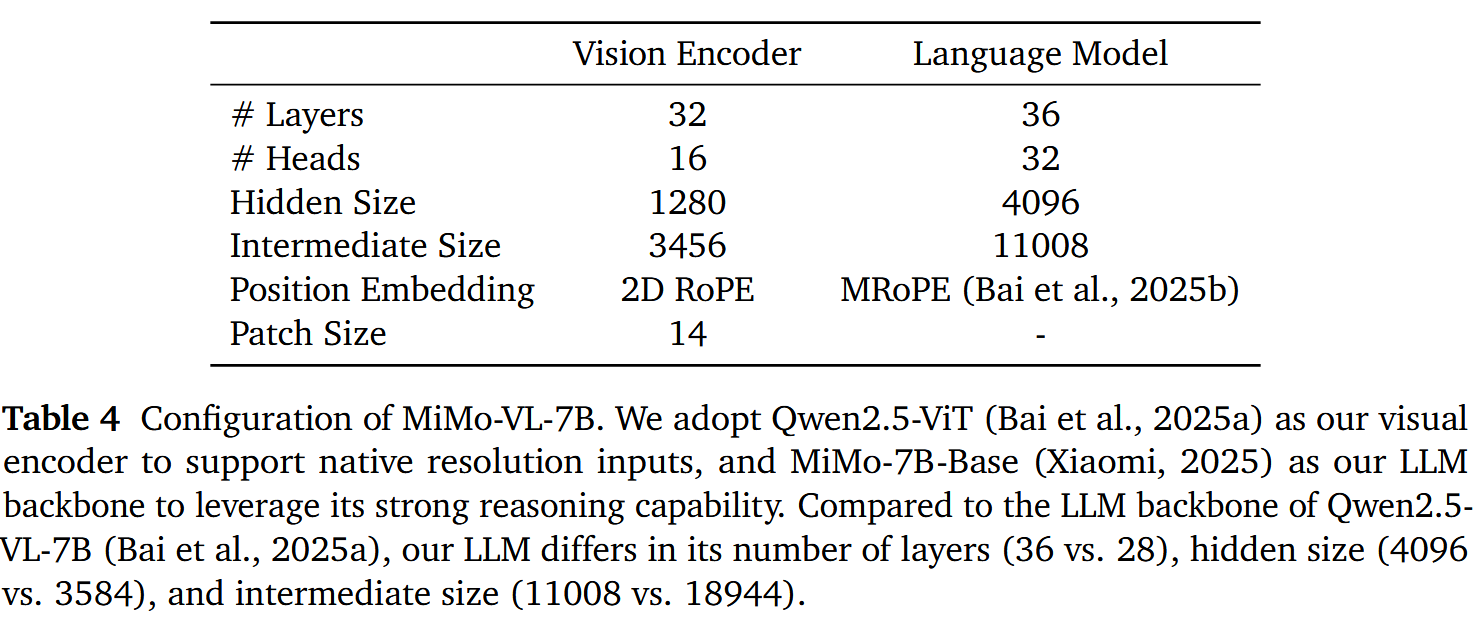
Pre-Training 数据
整个预训练用了2.4T的tokens数据量,包含一般图像Caption,交错数据,OCR,Grounding,Video,GUI交互,reasoning示例和仅文本序列。
针对每个类别的数据,作者设计了不同的管道来过滤数据得到高质量数据集,另外基于phash来去除重复的图像数据
Image Caption
- 从Web来源汇总了大量可公开可用的caption 数据。
- 此初始语料库经历了严格的重复数据删除阶段,并与文本过滤一起采用了PHASH,以产生一组精细且独特的原始Caption。
- 将图像及其原始文本描述作为先验,利用专门的模型来re-caption整个原始字幕数据集。
- 为了使得数据失衡,采用了MetaClip的方法,该方法涉及构建新型双语(中文和英语)元数据。这个步骤可用于完善数据分布,从而减轻高频条目的占比过高并减少数据集噪声。
通过这种细致过程的得到了一个平衡,高质量且多样化的caption数据集。另外,作者观察到这个丰富的数据集可显著增强模型输出的泛化性以及生成的质量,其优势在现有的benchmark中并不总能得到充分体现。
Interleaved
- 数据来源于包括网页,书籍和学术论文中的包含了大量的交织图像文本数据。
- 对于源自书籍和论文的内容,作者采用了高级PDF解析工具包进行内容提取和清洗。过滤过程优先考虑并保留富含世界知识的数据类型,例如教科书,百科全书,手册,指南,专利和传记。
- 对于视觉组件,实现了排除小尺寸,异常纵横比,不安全内容以及具有最小视觉信息的图像(例如,装饰性章节标题和插图)的过滤器。
- 最后,对图像文本pair在相关性,互补性和信息密度平衡上进行评分,从而确保了高质量数据的保留。
该数据集大大增加了模型的知识存储库,从而为其后续推理功能建立了强大的基础。
OCR and Grounding
为了增强模型在OCR和object grounding中的功能,广泛收集了开源数据集中的OCR和Grounding数据,以进行预训练。
- 对于OCR数据,这些图像涵盖了文档,表格,一般场景,产品包装和数学公式的各种文本内容。为了增加学习难度,除了标准印刷文本外,作者还专门合并了包含手写脚本的图像,印刷形式变形的文本以及模糊/遮挡的文本,从而提高了模型的识别性能和稳健性。并且对要OCR的图像中加入了边界框来使模型能够同时预测这些位置。
- 对于Grounding数据,包含了图像中具有单个对象和多个对象的方案。在涉及定位的所有情况下,我们都使用绝对坐标来表示。
Video
视频数据集主要来自公开可用的视频数据,这些视频涵盖了各种各样的域,流派和持续时间。
- 设计了一个视频 re-caption pipeline,产生密集的,细粒度的事件级的描述。
- 每个caption在时间上以精确的开始和结束时间戳为基础,使模型能够感知一般的视频的时间。
- 从caption数据集中,进一步收集了一个子集,该子集平衡了事件持续时间的分布,用于时间Grounding。
- 还策划了视频分析数据,该数据总结了视频的全局语义,例如叙事结构,风格元素和隐性意图。
- 合并了开源视频字幕和对话数据集,以进一步丰富我们的视频预处理数据。
GUI
为了增强模型在定位GUI方面的功能,作者收集了涵盖各种平台的开源预训练数据,例如移动端,Web和台式机。还设计了合成数据引擎,以补偿开源数据的局限性并加强模型特定方面的功能。例如,已经构建了大量的 中文的GUI数据,以使模型能够更好地处理中文GUI场景。
- 对于GUI Grounding,收集了 元素定位(element grounding) 和 指令定位(instruction grounding) 数据。
- element grounding 基于文本描述训练模型以精确找到对应的元素,从而确立对静态用户界面的强大感知。
- instruction grounding要求模型根据用户说明在屏幕截图上识别目标对象,从而增强对GUI交互逻辑的理解。对于这一部分,作者还引入了一项预训练任务,涉及根据前后屏幕截图预测中间操作。
- 对于GUI行动,我们收集了大规模的长GUI动作轨迹。为了确保各个平台之间的一致性,将移动,Web和桌面环境中的操作统一为标准化的动作空间。
Synthetic Reasoning
通过对开源问题的全面策划生成合成推理数据。这个多样化的集合涵盖了感知问题回答,文档问题回答,视频问题回答以及视觉推理任务,并补充了来自Web内容和文学作品的问答对。
- 在初步过滤这些源问题之后,利用大型推理模型来产生整合明确推理的答案。这个方法的基石是严格的多阶段质量控制。
- 除了验证答案的事实正确性之外,还将严格的过滤标准应用于推理过程本身,评估思想的清晰度,消除冗余并确保一致的格式。
Post-Training
作者在后训练中采用了一种 混合式on-policy 的强化学习(MORL)框架,该框架将强化学习与在RLHF中的可验证奖励强化模型 Reinforcement Learning with Verifiable Rewards(RLVR)无缝整合。
RLVR
RLVR仅依赖于基于规则的奖励,来实现了连续的模型自我迭代。在MIMO-VL-7B的训练后训练中,作者设计了多个可验证的推理和感知任务,可以使用预定义的规则准确验证最终解决方案。其中包含:Visual Reasoning,Text Reasoning,Visual Grounding,Visual Counting,Temporal Video Grounding
RLHF
Query Collection:
对于query的收集,包含纯文本和多模态两种模式。而对于每一个query,通过MIMO-VL-7B和其他多个表现较好的VLM来生成响应。这些响应随后由一个高级的VLM成对进行排名,以构建确定数据集来对奖励模型进行训练,值得注意的是,为了减轻奖励黑客,同样的查询集可用于奖励模型训练和RLHF流程。
奖励模型
同样针对于不同的输入方式,作者量身定制的两个专业奖励模型,并使用Bradley-Terry奖励建模目标训练。对于文本来说,从MIMO-7B初始化以利用其强大的语言理解能力;而多模式奖励模型则建立在MIMO-VL-7B上,以有效地处理包含视觉输入。这种双模型方法可确保在文本和多模式评估方案中的最佳性能。
MORL
作者将基于规则的奖励和基于模型的奖励统一集成进VERL框架内,这里称为Reward Service,并通过Seamless Rollout Engine来进行处理和增强。
下面这个图展示了整体的MORL框架
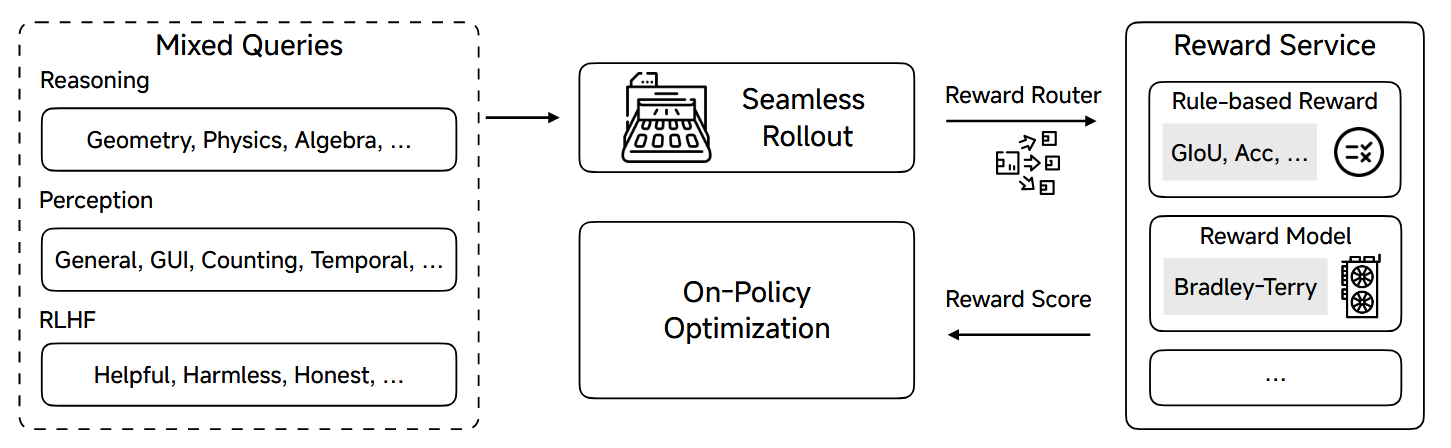
RL算法采用了GRPO的变体,与Vanilla GRPO相比,此on-policy变体在响应推出后执行单步policy更新,从而消除了对剪裁的替代训练目标的需求。整合了几个进步,包括删除KL损失,动态采样,简单的数据过滤器和重新采样策略,纳入了此RL训练配方。
因为不同的输入和任务,所用的奖励模型不同,为了提供统一的界面和接近零的延迟奖励计算,作者在这里引入了Reward-as-a-Service (RaaS)。奖励路由器根据查询的任务类型动态选择适当的奖励功能。为了最大程度地减少延迟,将奖励模型部署为独立服务,以确保可以通过HTTP访问可扩展的奖励计算。所有奖励均标准化为[0,1]的范围。这个的训练过程中没有额外的奖励,例如格式奖励。
实验
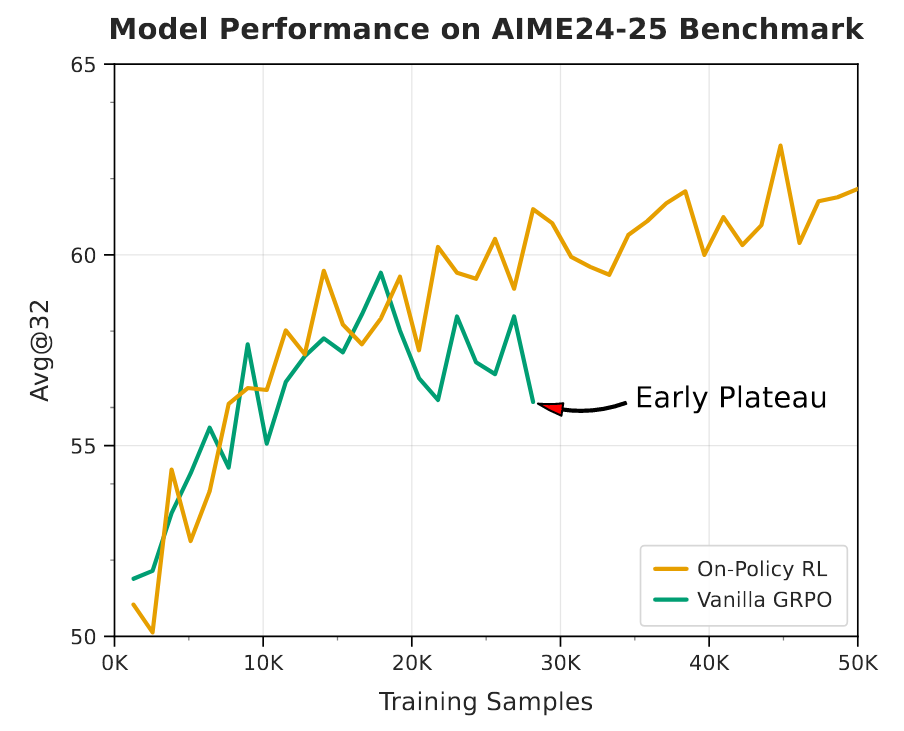
On-Policy RL v.s. Vanilla GRPO
作者在后面也探讨了policy RL V.S.原始的GRPO的好处。仅使用纯文本数据,如下图所示,on-policy算法显示训练数据量和性能得分之间存在一致的正相关。它的学习曲线在观察到的训练窗口中没有显示饱和的迹象,这表明使用其他计算资源和数据进一步增强。相反,Vanilla GRPO算法最初表现出较高的样品效率,在训练的早期就达到了稳健的性能。但是,这个优势是短暂的。该算法的性能通常会在约20,000个训练样本后达到饱和。