Temporal action detection可以分为两种setting, 一是offline的,在检测时视频是完整可得的,也就是可以利用完整的视频检测动作发生的时间区间(开始时间+结束时间)以及动作的类别; 二是 online的,即处理的是一个视频流,需要在线的检测(or 预测未来)发生的动作类别,但无法知道检测时间点之后的内容。online的问题设定更符合surveillance的需求,需要做实时的检测或者预警;offline的设定更符合视频搜索的需求,比如youtube可能用到的 highlight detection / preview generation。
问题演化
Early action detection -> Online action detection -> Online action anticipation:
在学术界关注online action detection之前,有一个相似的问题叫做 early event detection ,问题定义是 “detect the event as soon as possible, after it starts but before it ends”, 即 在某事件开始之后尽量快地检测到它。但是具体问题设定上,它假设目标事件已知,只是在每一帧上去检测有没有发生这个动作,这相当于把detection简化成了localization的问题,不需要关心分类,而只是检测起止时间。
在CVPR16时 Shugao Ma提出了early activity detection,问题强调的是观察了一段动作之后,给出这个动作的类别和开始的时间, 这篇文章算是比较早 (不确定是不是最早)的去做early action detection。

在ECCV 16, Geest et al 明确提出 online action detection,给出了一个比较全面的问题定义,测试方式和一个新数据集 (视频取材于美剧,长度在20分钟左右,我觉得这个数据集拿来做offline/online detection 都还是不错的)。问题定义是 “Given a streaming video as input, the system should output, ideally in realtime, whether the action is currently taking place (or not).”, 即,针对一个视频流,检测何种动作正在发生。以下图片来自

在这些文章的基础上,在BMVC17发表了一篇做online action anticipation的文章,问题相比online detection更进一步,考虑能否根据过去发生的动作预测未来将要发生的动作,并将online detection作为anticipation的一种特殊情况进行处理,即预测时间为0.
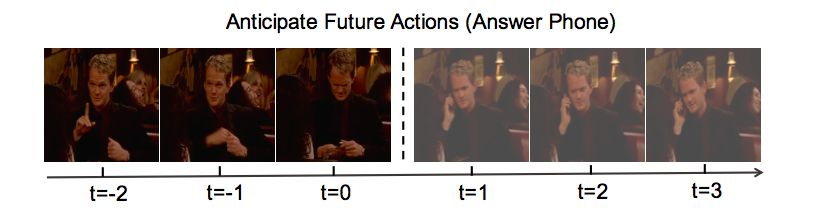
这四篇文章应该能简要的勾勒出这个问题的发展,从Early action detection 到 Online action detection 再到 Online action anticipation。
主要方法
TRN
文章标题:Temporal Recurrent Networks for Online Action Detection
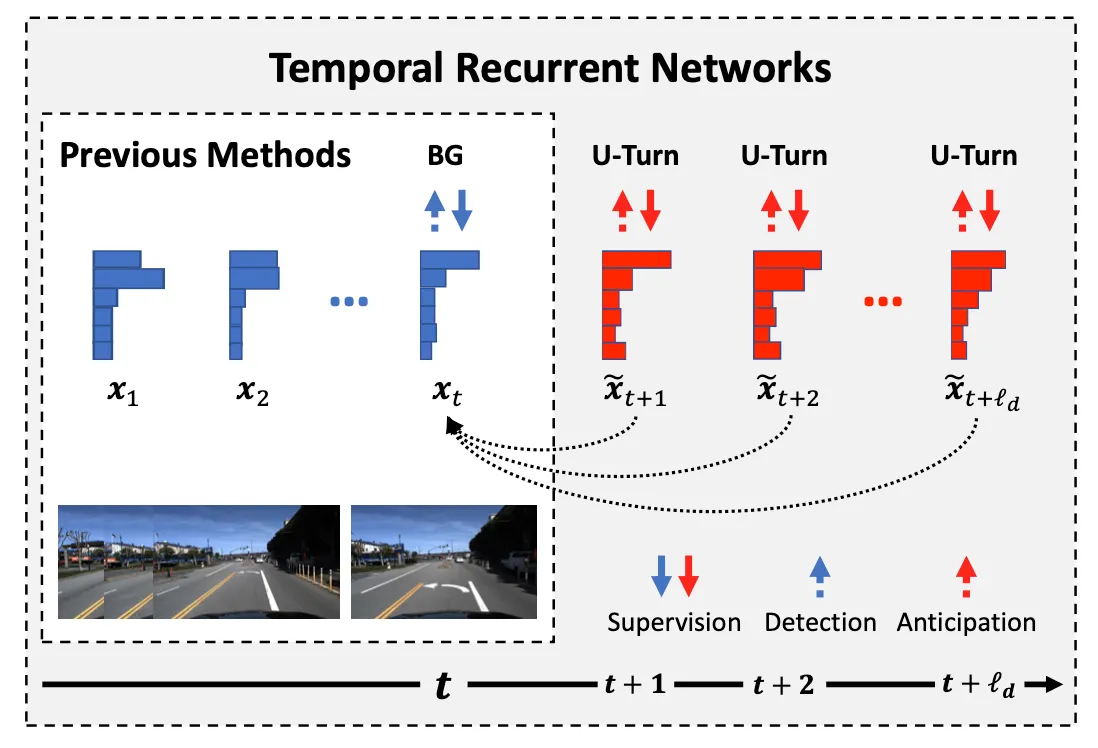
这篇文章的思路就是之前的工作都是在利用历史信息和当前时刻的信息,而这篇文章就是要预测未来的信息来结合历史信息做分类。整体框架采用的lstm。
方法
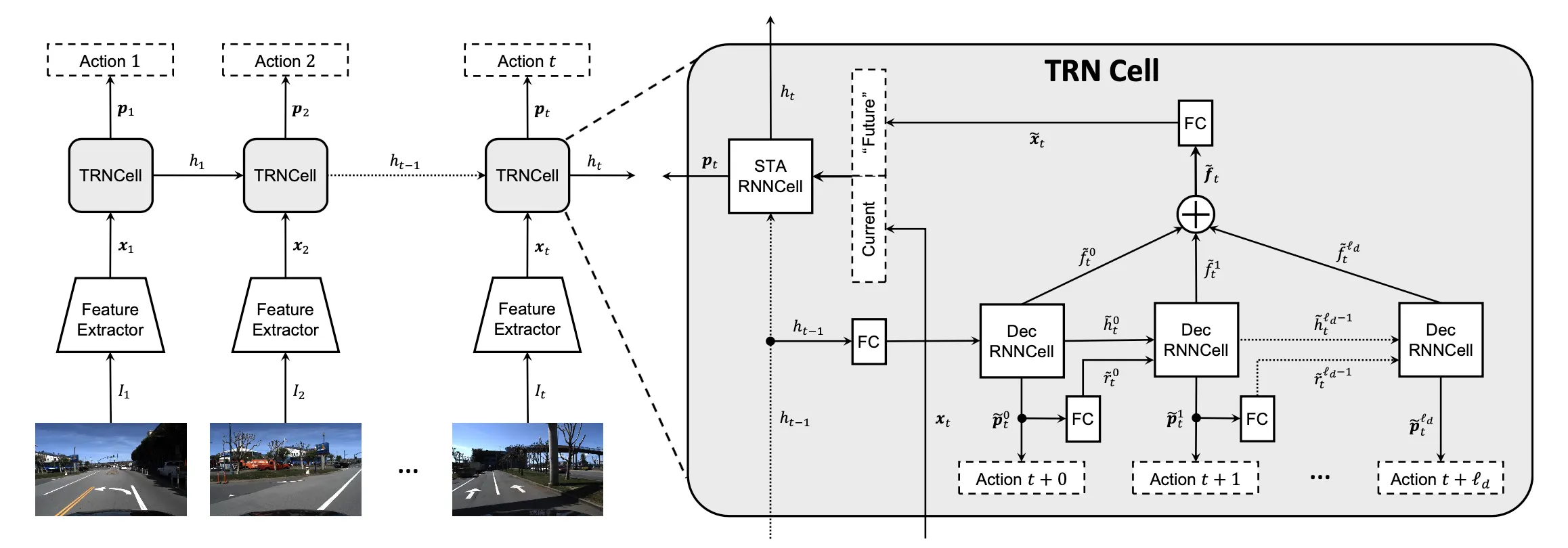
传统的RNN或者LSTM并不能接收未来的信息,所以作者设计了一个TRN Cell为一个循环单元,TRN Cell 的算法流程如下:

右侧的可以横过来看,输入是大lstm中的隐状态h(文中把大的lstm称作Encoder),以h为输入再经过小的lstm,将输出连接起来构成future信息。
再解释一下就是,endcoder中得到了时间t的信息,那以t的信息为输入,再经过序列lstm,每个输出就可以看作是对未来\(t+1...t+l_d\) 的预测,这些预测再经过一个FC层和 \(t\) 时刻的结合起来,作用于encoder的下一时序。
从Loss的角度来说,两部分loss,一部分是Encoder输出和真实类别的loss,另一部分是Decoder输出和真实类别的loss,也就是强制encoder学习到预测未来的信息。
IDU
文章标题:Learning to Discriminate Information for Online Action Detection
这篇文章主要的动机是,之前的RNN,LSTM,GRU这样的循环结构中,循环单元累计历史输入,但忽视了其与当前动作的联系,所以不能得到一个有效的判别性的表示。
所以, 这篇文章就是在探索是否可以学习一个判别性较强的表示区分相关和不相关的信息以检测当前要动作。
方法
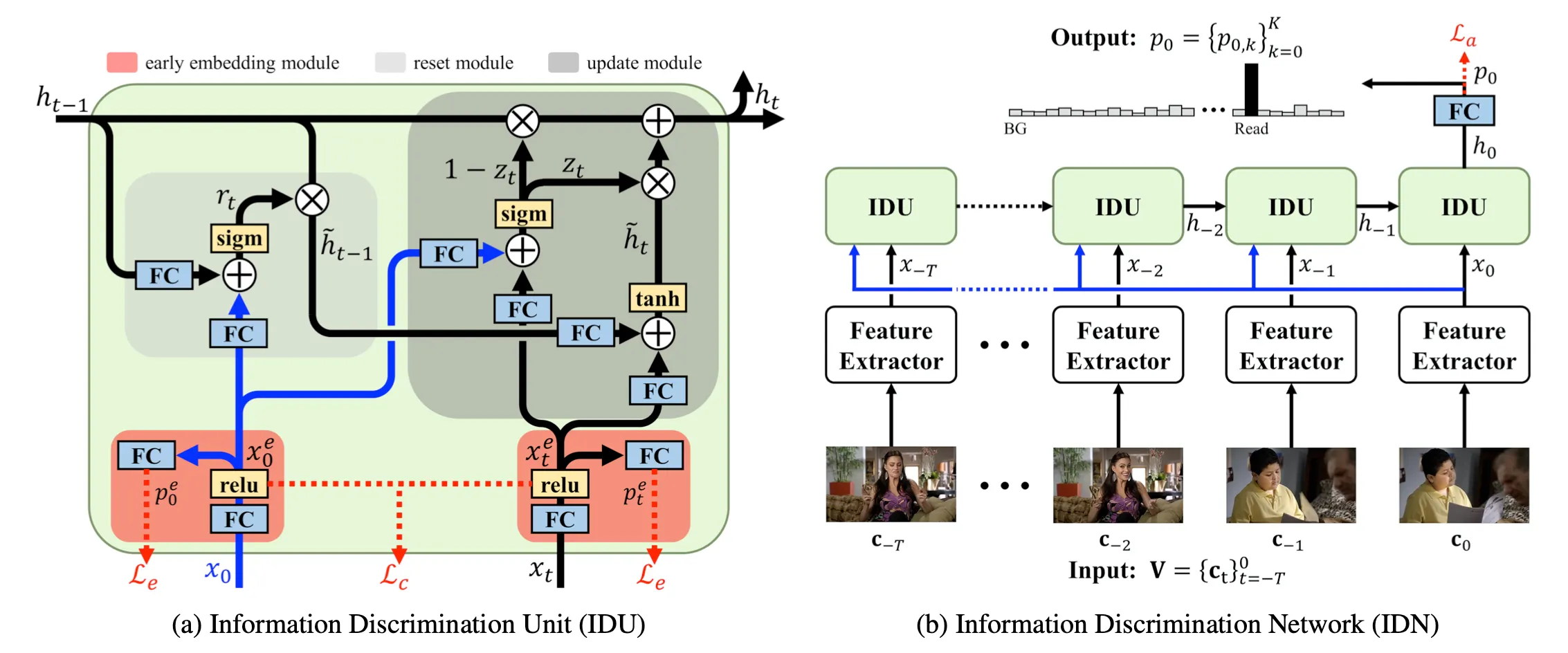
文章基于GRU提出了一个 Information Discrimination Unit (IDU)来实现上述的想法。
GRU
首先回顾一下GRU:
reset gate 决定之前的状态 \(h_{t-1}\) 是否忽略。
同样,update gate 决定 \(h_t\) 是否用一个新的状态函数 \(\tilde{h_t}\) 来更新。
IDU
IDU在GRU的基础上增加了一个模块:Early Embedding Module, 具体如下:
模块的输入为当前时刻特征 \(x_0\) 和所有时刻特征 \(x_t\) ,输出为特征embedding \(x_0^e\) 和 \(x_t^e\)
为了让特征embedding学习到相应action的表示,作者引入了两个loss去监督学习。
- 第一个为multi-class 进行分类
其中\(p_{t,k}^e\)为\(x_t^e\)经过softmax得到的概率。
- 第二个为为了让特征更具判别性,作者加入了contrastive loss\[\begin{aligned} \mathcal{L}_c &= \mathbf{1}\{y_t = y_0\} D^2(x_t^e, x_0^e) \\ &\quad + \mathbf{1}\{y_t \neq y_0\} \max(0, m - D^2(x_t^e, x_0^e)), \end{aligned} \]
而 reset gate 和 update gate 和GRU相似,只不过输入不同,和他们的motivation一样,reset gate是把当前时刻特征 \(x_0^e\) 和上一步的隐藏状态特征 \(h_{t-1}\)作为输入,具体如下:
update gate是把当前时刻特征 \(x_0^e\) 和之前时刻特征 \(x_{t}^e\)作为输入,具体如下:
IDN
- 网络输入:当前和之前 \(T\)个时刻的chunks ,\(V = \{c_t\}^0_{t=−T }\)。其中,每个chunk定义为 \(c = \{I_n\}^N_{n=1 }\) 为\(N\)个连续帧。
- 网络输出:当前时刻K个action的概率,\(p_0 = \{p_{0,k}\}^K_{k=0}\)
- 特征提取:TSN
- 网络训练:\(h_0\)接FC得到action的类别概率 \(p_0^e\), 分类loss 为ce
实验
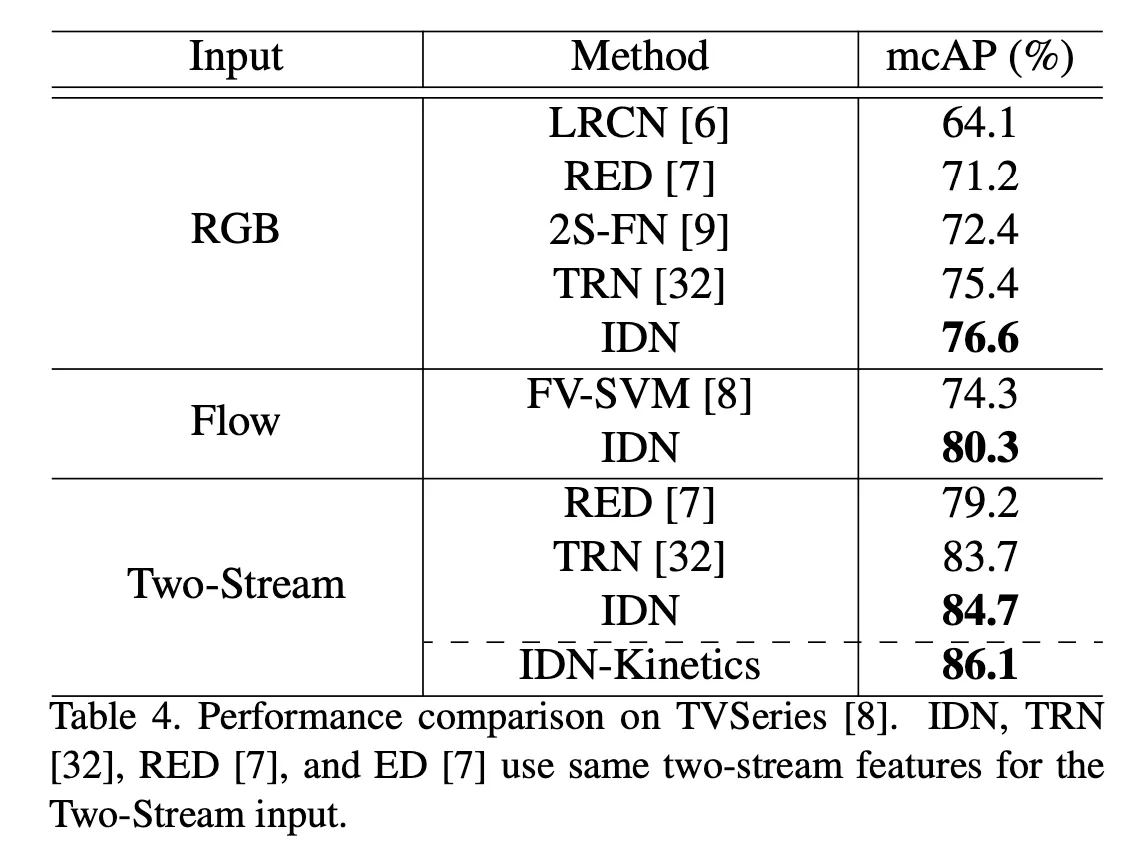

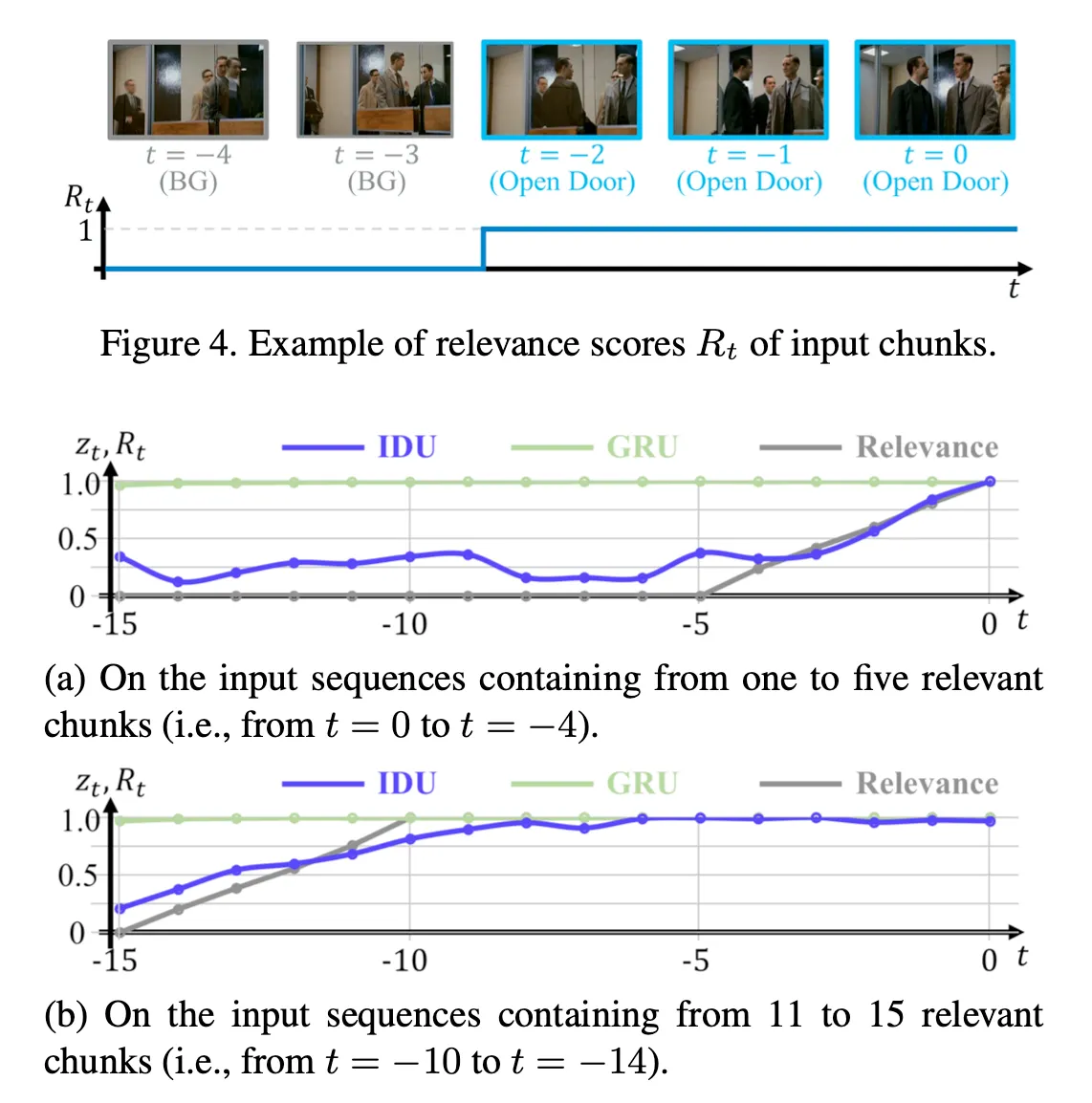
一个有意思的实验设置是,作者设定了一个\(R_t\) , 代表与当前时刻action一样的历史时刻为1,否则为0,来证明IDU有效的模拟了输入信息与正在进行的动作相关性。
OadTR
文章:Online Action Detection with Transformers
之前的很多方法都是用RNN的结构去构建时序上的依赖关系,但是RNN的结构的缺点是不能并行操作,且存在梯度消失的现象。所以本文就是将之前的RNN的结构改为Transfomer的形式。延续了之前TRN的整个网络的框架,也是结合了对未来帧的预测与历史帧的表示相结合来对当前的动作进行预测。
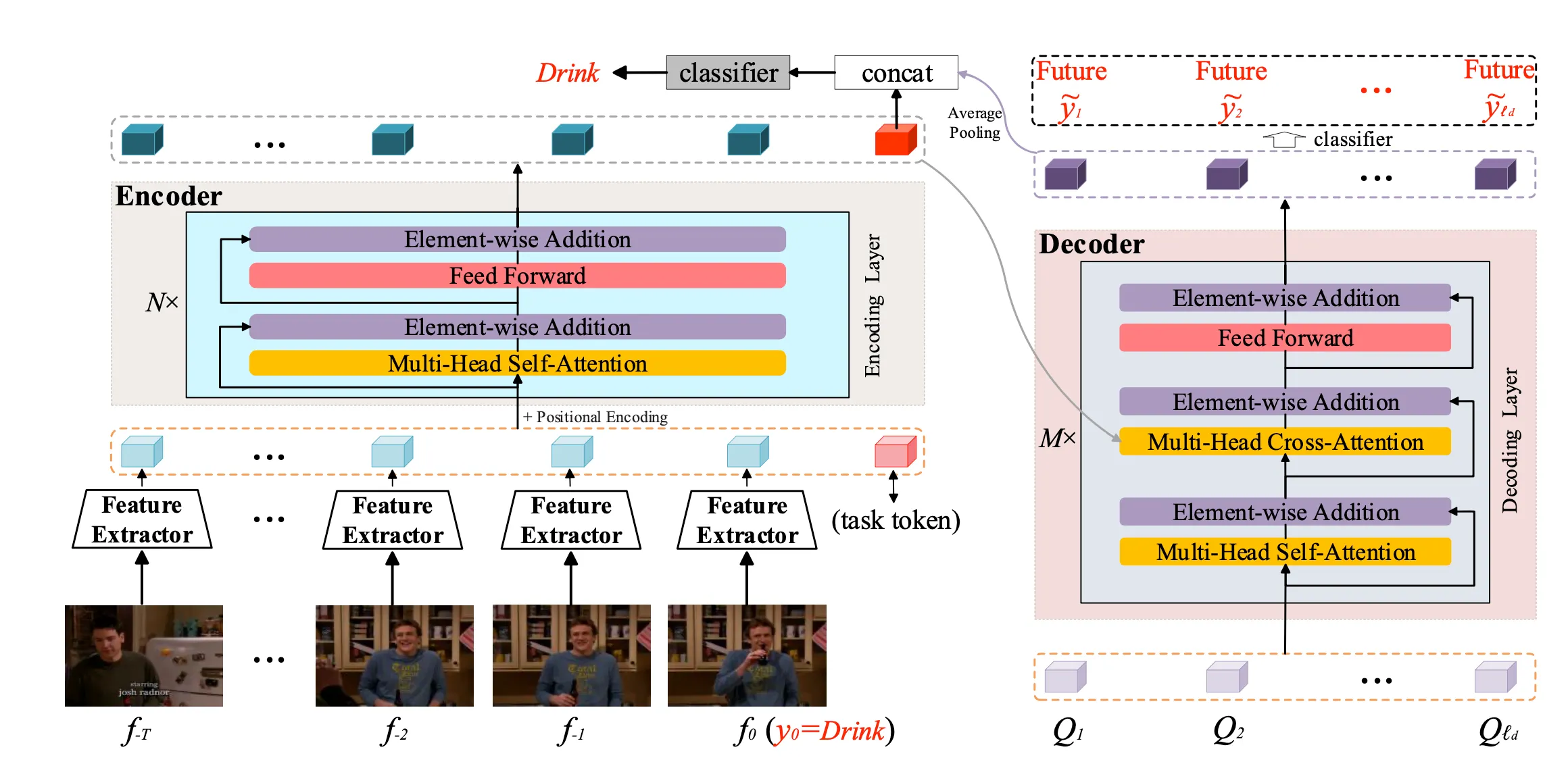
整个网络框架如上图所示,
Encoder就是利用transfomer对long-range的历史和目前帧进行特征表示,其中要说明的一个点就是,这里的特征空间包含T个历史特征,当前窗口的特征以及一个task token,这个task token的作用可以从下图看出来
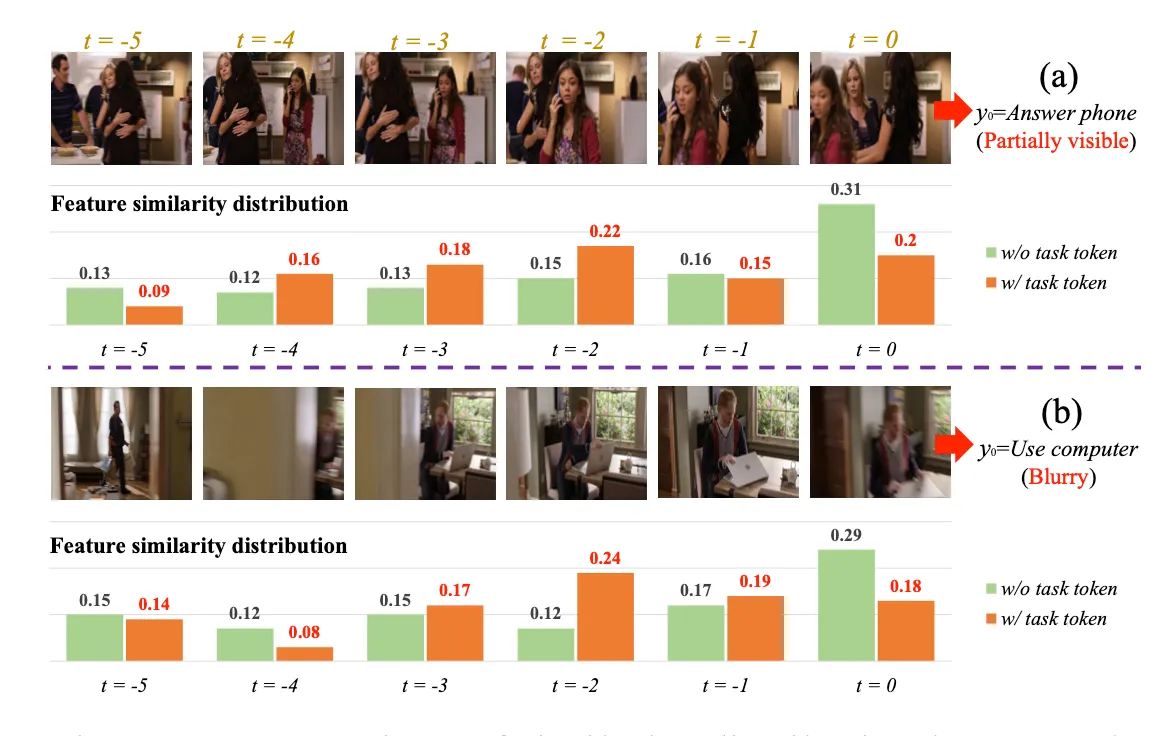
这幅图对比的是输入进classifier的特征与网络输入的特征的相似性,可以看出w/o task token 对应的是当前t=0时刻的特征,而w/ task token 对应的是历史帧中最具判别性的特征
直观上看,如果这里没有tokenclass,其他token得到的最终特征表示必然会整体偏向这个指定的token,从而不能用来表示当前动作的特征。 相比之下,tokenclass的语义embedding可以通过与encoder中的其他token自适应交互得到,更适合特征表示