Deep Learning
2024-12-29
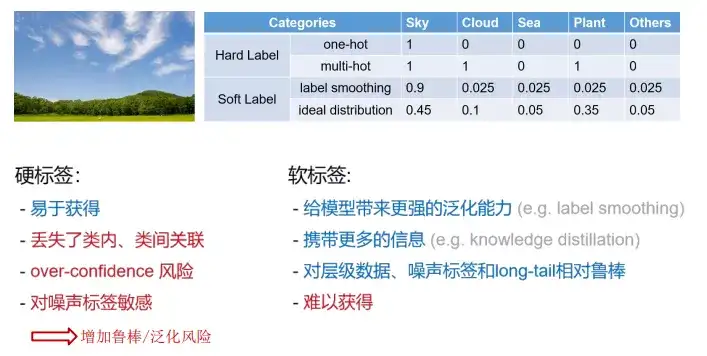
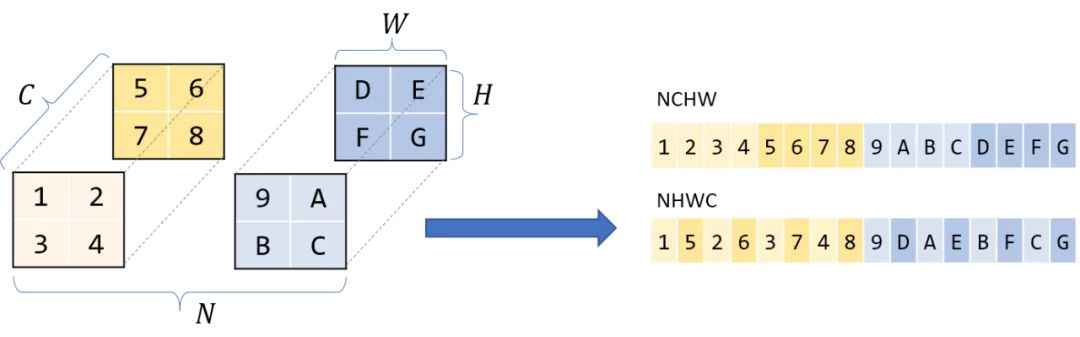
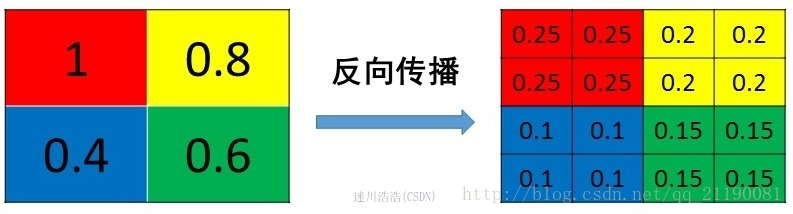
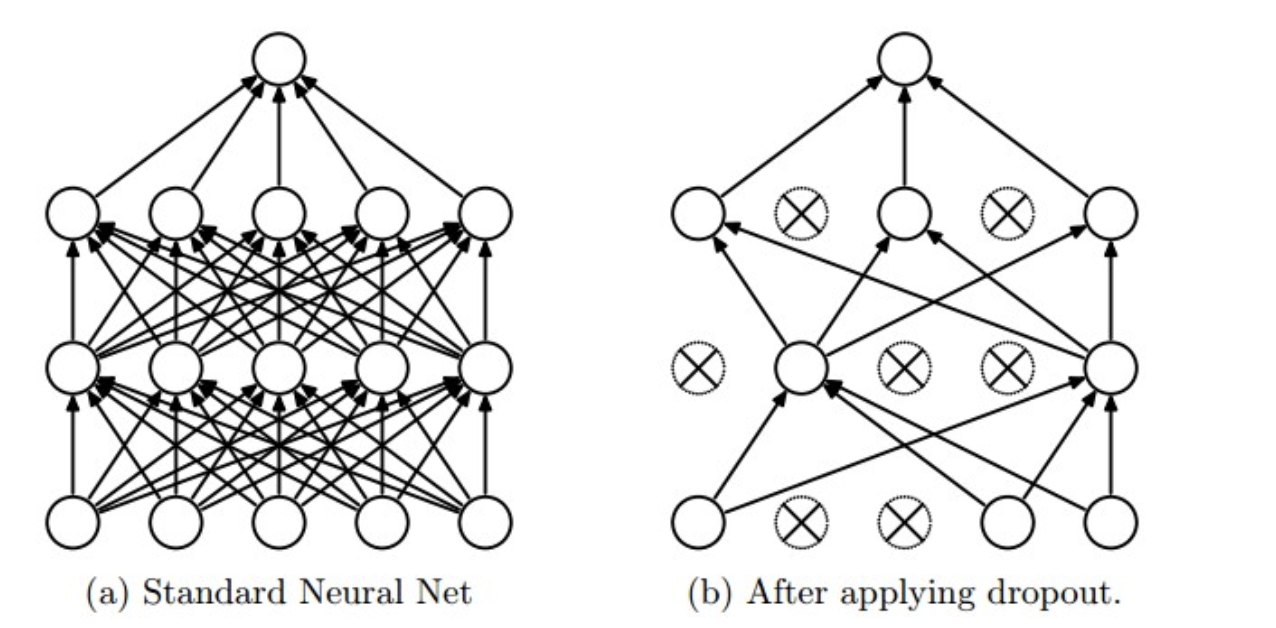
机器学习 Hinge Loss Hinge的叫法来源于其损失函数的图形,为一个折线,通用函数方式为: [公式] Hinge可以解 间距最大化 问题,带有代表性的就是svm,最初的svm优化函数如下: [公式] 将约束项进行变形则为: [公式] 则可以将损失函数进一步写为: [公式] 因此svm的损失函数可以看成L2Norm和Hinge损失误差之和. 交叉熵 从熵来看交叉熵损失 信息量 信息量来衡量一个事件的不确定性,一个事件发生的概率越大,不确定性越小,则其携带的信息量就越小。 设𝑋是一个离散型随机变量,其取值为集合 X=x_0,x_1,…,x_n ,则其概率分布函数为 p(x)=Pr(X=x),x∈X ,则定义事件 𝑋=𝑥_0 的信息量为 [公式] 当 𝑝(𝑥_0)=1 时,该事件必定发生...