
1. 什么是NGram模型 NGram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。 每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。 该模型基于这样一种假设,第N个词的出现只与前面N1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常用的是二元的BiGram和三元的TriGram。 说完了ngram模型的概念之后,下面讲解ngram的一般应用。 2. NGram模型用于评估语句是否合理 如果...
NLP
2025-01-02

取代RNN——Transformer 在介绍Transformer前我们来回顾一下RNN的结构 对RNN有一定了解的话,一定会知道,RNN有两个很明显的问题 效率问题:需要逐个词进行处理,后一个词要等到前一个词的隐状态输出以后才能开始处理 如果传递距离过长还会有梯度消失、梯度爆炸和遗忘问题 为了缓解传递间的梯度和遗忘问题,设计了各种各样的RNN cell,最著名的两个就是LSTM和GRU了 LSTM (Long Short Term Memory) GRU (Gated Recurrent Unit) 但是,引用网上一个博主的比喻,这么做就像是在给马车换车轮,为什么不直接换成汽车呢? 于是就有了Transformer。Transformer 是Google Brain 2017的提出的一篇工...
NLP
2024-12-31
SelfSupervised Learning,又称为自监督学习,我们知道一般机器学习分为有监督学习,无监督学习和强化学习。 而 SelfSupervised Learning 是无监督学习里面的一种,主要是希望能够学习到一种通用的特征表达用于下游任务 (Downstream Tasks)。 其主要的方式就是通过自己监督自己。作为代表作的 kaiming 的 MoCo 引发一波热议, Yann Lecun也在 AAAI 上讲 SelfSupervised Learning 是未来的大势所趋。所以在这个系列中,我会系统地解读 SelfSupervised Learning 的经典工作。 本文主要介绍 SelfSupervised Learning 在 NLP领域的经典工作:BERT模型的原理及...
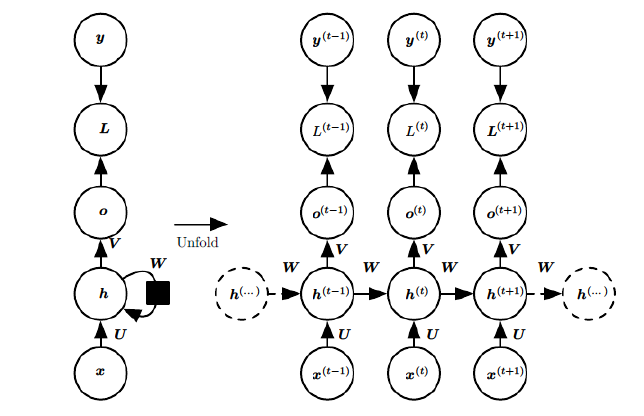
RNN 概述 在前面讲到的DNN和CNN中,训练样本的输入和输出是比较的确定的。但是有一类问题DNN和CNN不好解决,就是训练样本输入是连续的序列,且序列的长短不一,比如基于时间的序列:一段段连续的语音,一段段连续的手写文字。这些序列比较长,且长度不一,比较难直接的拆分成一个个独立的样本来通过DNN/CNN进行训练。 而对于这类问题,RNN则比较的擅长。那么RNN是怎么做到的呢?RNN假设我们的样本是基于序列的。比如是从序列索引1到序列索引 τ 。对于这其中的任意序列索引号 t ,它对应的输入是对应的样本序列中的 x(t) 。而模型在序列索引号 t 位置的隐藏状态 h(t) ,则由 x(t) 和在 t−1 位置的隐藏状态 h(t−1) 共同决定。在任意序列索引号 t ,我们也有对应的模型预测...
NLP
2024-12-31
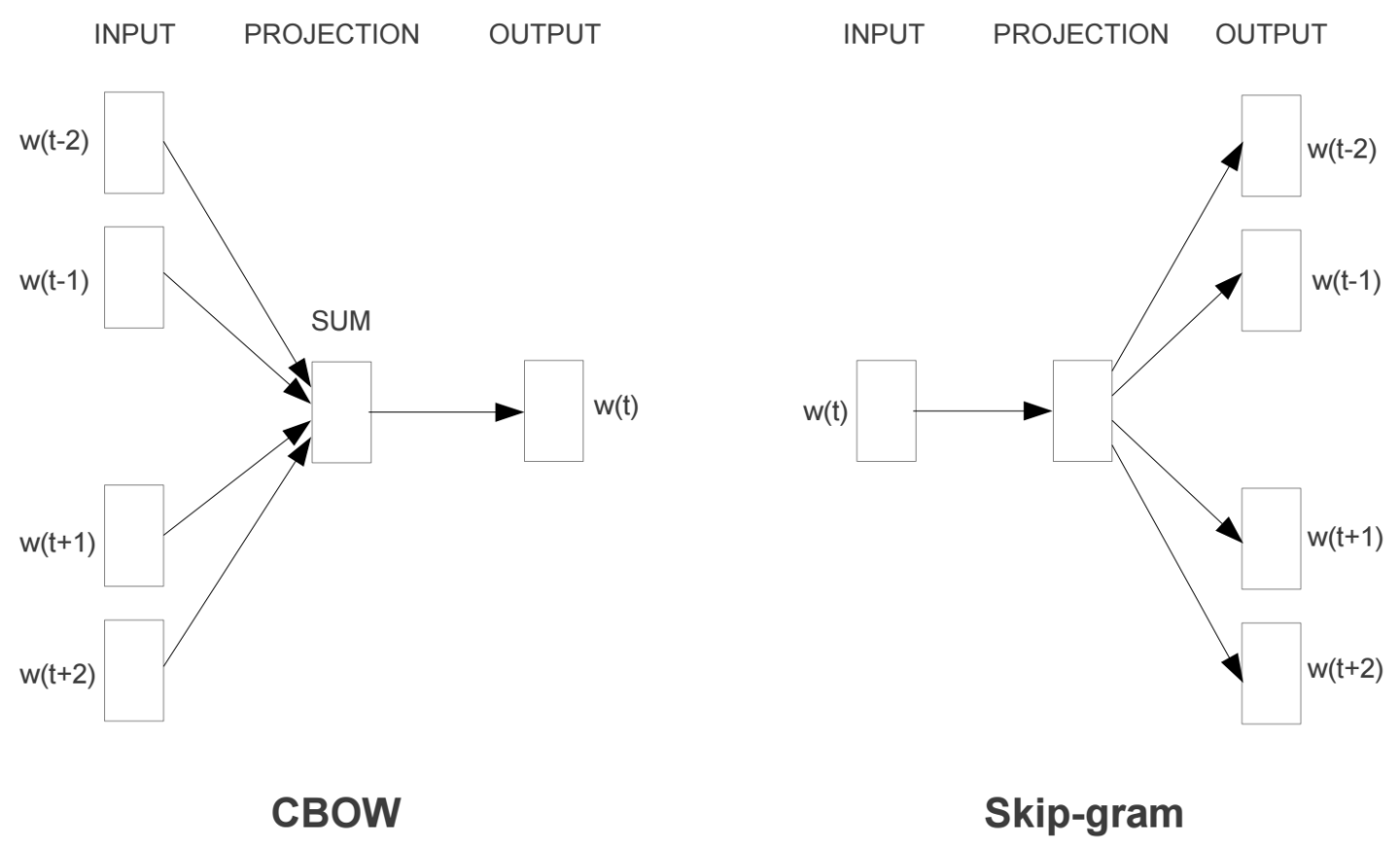
什么是Word2Vec和Embeddings? Word2Vec是从大量文本语料中以无监督的方式学习语义知识的一种模型,它被大量地用在自然语言处理(NLP)中。那么它是如何帮助我们做自然语言处理呢?Word2Vec其实就是通过学习文本来用词向量的方式表征词的语义信息,即通过一个嵌入空间使得语义上相似的单词在该空间内距离很近。Embedding其实就是一个映射,将单词从原先所属的空间映射到新的多维空间中,也就是把原先词所在空间嵌入到一个新的空间中去。 我们从直观角度上来理解一下,cat这个单词和kitten属于语义上很相近的词,而dog和kitten则不是那么相近,iphone这个单词和kitten的语义就差的更远了。通过对词汇表中单词进行这种数值表示方式的学习(也就是将单词转换为词向量),能...
NLP
2024-12-31

Tokenizer 诸如GPT3/4以及LlaMA/LlaMA2大语言模型都采用了token的作为模型的输入输出,其输入是文本,然后将文本转为token(正整数),然后从一串token(对应于文本)预测下一个token。 进入OpenAI官网提供的tokenizer可以看到GPT3tokenizer采用的方法。这里以Hello World为例说明。 总共30个token,英文单词一般会用单独的token表示,大小写也会区分不同的token,如Hello和hello,另外有一些由空格前导的单词也会单独编码,这会使得编码整个句子效率更高(这将省去每个空格的编码),对于中文token化,会使用两到三个ID(正整数表示),比如上面的中英文的!。 在英语等空白隔开的语言中,文本被预标记化,通常使用不跨...