最优策略(Optimal Policy ) 之前在 贝尔曼方程(Bellman Equation) 中说过, 状态值可以用来评估一个策略是好是坏 ,这里给出正式的概念: \[v_{\pi_1}(s) \geq v_{\pi_2}(s) \quad \text { for all } s \in \mathcal{S}\] 那么此时 \(\pi_1\) 比 \(\pi_2\) ”更好“ 最优状态值(Optimal State Value) : 对于任意状态 \(s\) ,最优状态值 \(v^*(s)\) 是所有可能策略中状态值的最大值: \[v^*(s) = \max_{\pi} v_{\pi}(s)\] 其中 \(v_{\pi}(s)\) 是策略 \(\pi\) 下的状态值。 最优策略(Optimal Policy) : 如果一个策略的状态值在所有状态中均大于或等于其他策略的状态值,则该策略为最优策略: \[\pi^* = \arg\max_{\pi} v_{\pi}(s), \forall s \in S\] 即最优策略总是选择使得状态值最大的动作。 性质 : 存在性...
Reinforcement Learning
2026-03-27
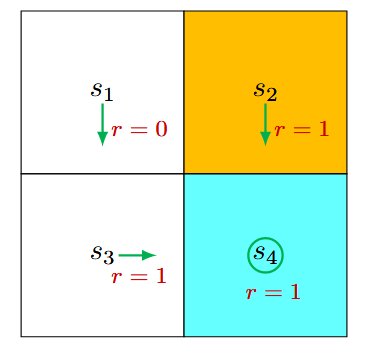
状态价值(State values) 定义 状态价值是强化学习中的核心概念,用于衡量Agent从某个状态出发、遵循特定策略后所能获得的期望回报。 数学表达为: \[
v_\pi(s) = \mathbb{E}[G_t | S_t = s]
\tag{1}\] 其中: \(v_\pi(s)\) :状态 \(s\) 的状态价值函数(state-value function) 或者简称为 状态价值(state value); \(\pi\) :智能体遵循的策略; \(G_t = R_{t+1} + \gamma R_{t+2} + \gamma^2 R_{t+3} + \dots\) :从当前时间步 \(t\) 开始的折扣回报; \(\gamma \in (0, 1)\) :折扣因子,用于平衡即时奖励和未来奖励。 状态价值的特点 依赖于状态 \(s\) :状态价值是条件期望,条件是智能体从状态 \(s\) 开始。 依赖于策略 \(\pi\) :不同策略会生成不同的轨迹,从而影响状态价值。 与时间步无关 :状态价值是一个固定值,与当前时间步 \(t\) 无关。 代表一个状态的价值。...
Reinforcement Learning
2026-03-27

引言 强化学习中,找到最优策略是核心目标。本文详细介绍三种能够找到最优策略的基础算法: 价值迭代、策略迭代和截断策略迭代 。这些算法属于动态规划范畴,需要系统模型,是后续无模型强化学习算法的重要基础。 在强化学习的发展路线中,这些算法处于"基础工具"到"算法/方法"的过渡阶段,是从"有模型"到"无模型"学习的重要桥梁。 价值迭代(Value iteration) 价值迭代算法 基于收缩映射定理求解贝尔曼最优方程 。其核心迭代公式为: \[\begin{equation}v_{k+1} = \max_{\pi \in \Pi} (r_\pi + \gamma P_\pi v_k), k = 0, 1, 2, ...\tag{1}\end{equation}\] 根据收缩映射定理,当 \(k \to \infty\) 时, \(v_k\) 和 \(\pi_k\) 分别收敛到最优状态值和最优策略。 每次迭代包含两个步骤: 策略更新步骤 (policy update step) :找到能解决以下优化问题的策略 \[\pi_{k+1} = \arg\max_\pi (r_\pi +...
Reinforcement Learning
2026-03-27

基础概念 Grid-Word Example 环境描述 :网格世界是一个直观的二维环境,包含: 白色格子 :可通行区域。 橙色格子 :禁止进入的区域(禁区)。 目标格子 :代理需要到达的目标位置。 任务目标 : 找到一条“好的”策略,使代理从任意初始位置到达目标格子。 策略应避免进入禁区、碰撞边界或走不必要的弯路。 什么是强化学习:依据策略执行动作-感知状态-得到奖励 所谓强化学习(Reinforcement Learning,简称RL),是指基于智能体在复杂、不确定的环境中最大化它能获得的奖励,从而达到自主决策的目的。 a computational approach to learning whereby an agent tries to maximize the total amount of reward it receives while interacting with a complex and uncertain environment 经典的强化学习模型可以总结为下图的形式(你可以理解为任何强化学习都包含这几个基本部分:智能体、行为、环境、状态、奖励):...

💡 GRPO相比PPO主要优势: 1. 训练更稳定 引入 KL 散度惩罚项,有效控制策略更新的幅度,避免策略崩溃,提高训练的稳定性 GRPO用组内相对优势替代value model,消除了value估计误差 通过组内归一化,自动消除reward scale和bias的影响 实验中发现GRPO的advantage方差比PPO小30%左右,训练崩溃率更低 2. 工程更简单 只需要1-2个模型(policy + reference),而PPO需要4个 显存占用减少50%以上,训练速度提升2-3倍 超参数更少,更容易调优 3. 相对奖励机制 通过对同一输入生成的多个输出进行比较,GRPO 能够更稳定地估计优势函数,减少了训练过程中的方差 背景 GRPO是 DeepSeek-Math model中提出的对PPO方法的改进策略: 强化学习(RL)在提升模型数学推理能力方面被证明是有效的 传统PPO算法需要较大训练资源 GRPO作为PPO的变体被提出,可以更高效地优化模型 PPO Vs GRPO PPO回顾 PPO的目标函数为: \[\begin{aligned}J_{PPO}(\theta) =...
杂七杂八
2026-03-27
生成器 什么是生成器? 通过列表生成式,我们可以直接创建一个列表,但是,受到内存限制,列表容量肯定是有限的,而且创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。 所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间,在Python中, 这种一边循环一边计算的机制,称为生成器:generator 生成器是一个特殊的程序,可以被用作控制循环的迭代行为,python中生成器是迭代器的一种,使用 yield 返回值函数,每次调用 yield 会暂停,而可以使用 next() 函数和 send() 函数恢复生成器。 生成器类似于返回值为数组的一个函数,这个函数可以接受参数,可以被调用,但是,不同于一般的函数会一次性返回包括了所有数值的数组,生成器一次只能产生一个值,这样消耗的内存数量将大大减小,而且允许调用函数可以很快的处理前几个返回值,因此生成器看起来像是一个函数,但是表现得却像是迭代器 python中的生成器...
杂七杂八
2026-03-27
概述 python采用的是 引用计数 机制为主, 标记-清除 和 分代收集 两种机制为辅的策略。 引用计数 Python语言默认采用的垃圾收集机制是『引用计数法 Reference Counting 』,该算法最早George E. Collins在1960的时候首次提出,50年后的今天,该算法依然被很多编程语言使用。 『引用计数法』的原理是:每个对象维护一个 ob_ref 字段,用来记录该对象当前被引用的次数,每当新的引用指向该对象时,它的引用计数 ob_ref 加 1 ,每当该对象的引用失效时计数 ob_ref 减 1 ,一旦对象的引用计数为 0 ,该对象立即被回收,对象占用的内存空间将被释放。 它的缺点是需要额外的空间维护引用计数,这个问题是其次的,不过最主要的问题是它不能解决对象的“循环引用”,因此,也有很多语言比如Java并没有采用该算法做来垃圾的收集机制。 引用计数案例 import sys
class A():
def __init__(self):
'''初始化对象'''
print('object born id:%s'...
杂七杂八
2026-03-27

Quick Start 一个最简单的DDP Pytorch例子! 环境准备 PyTorch(gpu)>=1.5,python>=3.6 推荐使用官方打好的PyTorch docker,避免乱七八糟的环境问题影响心情。 # Dockerfile# Start FROM Nvidia PyTorch image https://ngc.nvidia.com/catalog/containers/nvidia:pytorch
# FROM nvcr.io/nvidia/pytorch:20.03-py3 代码 单GPU代码 ## main.py文件
import torch
# 构造模型
model = nn.Linear(10, 10).to(local_rank)
# 前向传播
outputs = model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
loss_fn = nn.MSELoss()
loss_fn(outputs, labels).backward()
#...
杂七杂八
2026-03-27

列表和元组总结 列表和元组都是 一个可以放置任意数据类型的有序集合 ,他们有以下共同点 列表和元组中的元素可以任意,并且都可以嵌套。 列表和元组都支持索引,且都支持负数索引,-1表示最后一个元素,-2表示倒数第二个元素 列表和元组都支持切片操作 都支持in关键词 都可以使用 .index() 、 .count() 、 sorted() 和 enumerate() 等方法 两者之间的相互转换,list()和tuple() 但是他们也是有区别 列表是动态的,长度大小不固定,可以随意地增加、删减或者改变元素(mutable) 元组是静态的,长度大小不固定,无法增删改,想要对已有的元组做任何“改变”,就只能开辟一块内存,创建新的元组 列表和元组存储方式的差异 由于列表是动态的;元组是静态的,不可变的。这样的差异,势必会影响两者存储方式。我们可以来看下面的例子: >>> l = [1, 2, 3]
>>> l.__sizeof__()
64
>>> tup = (1, 2, 3)
>>> tup.__sizeof__()
48...
NLP
2026-03-26

这篇文章主要去“复盘”一下主流的长度外推结果,并试图从中发现免训练长度外推的关键之处。 问题定义 顾名思义,免训练长度外推,就是不需要用长序列数据进行额外的训练,只用短序列语料对模型进行训练,就可以得到一个能够处理和预测长序列的模型,即“Train Short, Test Long”。那么如何判断一个模型能否用于长序列呢?最基本的指标就是模型的长序列Loss或者PPL不会爆炸,更加符合实践的评测则是输入足够长的Context,让模型去预测答案,然后跟真实答案做对比,算BLEU、ROUGE等, LongBench 就是就属于这类榜单。 但要注意的是,长度外推应当不以牺牲远程依赖为代价——否则考虑长度外推就没有意义了,倒不如直接截断文本——这意味着通过显式地截断远程依赖的方案都需要谨慎选择,比如ALIBI,还有带显式Decay的 线性RNN ,这些方案当序列长度足够大时都表现为局部注意力,即便有可能实现长度外推,也会有远程依赖不足的风险,需要根据自己的场景斟酌使用。 如何判断在长度外推的同时有没有损失远程依赖呢?比较严谨的是像 ReRoPE...
NLP
2026-03-26

概述 众所周知,尽管基于Attention机制的Transformer类模型有着良好的并行性能,但它的空间和时间复杂度都是 \(\mathcal{O}(n^2)\) 级别的, \(n\) 是序列长度,所以当 \(n\) 比较大时Transformer模型的计算量难以承受。近来,也有不少工作致力于降低Transformer模型的计算量,比如模型剪枝、量化、蒸馏等精简技术,又或者修改Attention结构,使得其复杂度能降低到 \(\mathcal{O}(n\log n)\) 甚至 \(\mathcal{O}(n)\) 。 改变这一复杂度的思路主要有两种: 一是走稀疏化的思路,比如OpenAI的 Sparse Attention ,通过“只保留小区域内的数值、强制让大部分注意力为零”的方式,来减少Attention的计算量。经过特殊设计之后,Attention矩阵的大部分元素都是0,因此理论上它也能节省显存占用量和计算量。后续类似工作还有 《Explicit Sparse Transformer: Concentrated Attention Through Explicit...
NLP
2026-03-26

Attention 当前最流行的Attention机制当属 Scaled-Dot Attention,形式为 \[\begin{equation}Attention(\boldsymbol{Q},\boldsymbol{K},\boldsymbol{V}) = softmax\left(\boldsymbol{Q}\boldsymbol{K}^{\top}\right)\boldsymbol{V}\tag{1}\end{equation}\] 这里的 \(\boldsymbol{Q}\in\mathbb{R}^{n\times d_k}, \boldsymbol{K}\in\mathbb{R}^{m\times d_k}, \boldsymbol{V}\in\mathbb{R}^{m\times d_v}\) ,简单起见我们就没显式地写出Attention的缩放因子了。本文我们主要关心Self Attention场景,所以为了介绍上的方便统一设 \(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V}\in\mathbb{R}^{n\times...