DropBlock
论文题目:DropBlock: A regularization method for convolutional networks
论文地址:https://arxiv.org/abs/1810.12890
由于dropBlock其实是dropout在卷积层上的推广,故很有必须先说明下dropout操作。
dropout,训练阶段在每个mini-batch中,依概率P随机屏蔽掉一部分神经元,只训练保留下来的神经元对应的参数,屏蔽掉的神经元梯度为0,参数不参数与更新。而测试阶段则又让所有神经元都参与计算。
dropout操作流程:参数是丢弃率p
1)在训练阶段,每个mini-batch中,按照伯努利概率分布(采样得到0或者1的向量,0表示丢弃)随机的丢弃一部分神经元(即神经元置零)。用一个mask向量与该层神经元对应元素相乘,mask向量维度与输入神经一致,元素为0或1。
2)然后对神经元rescale操作,即每个神经元除以保留概率\(1-P\),也即乘上\(1/(1-P)\)。
3)反向传播只对保留下来的神经元对应参数进行更新。
4)测试阶段,Dropout层不对神经元进行丢弃,保留所有神经元直接进行前向过程。
为啥要rescale呢?是为了保证训练和测试分布尽量一致,或者输出能量一致。可以试想,如果训练阶段随机丢弃,那么其实dropout输出的向量,有部分被屏蔽掉了,可以等下认为输出变了,如果dropout大量应用,那么其实可以等价为进行模拟遮挡的数据增强,如果增强过度,导致训练分布都改变了,那么测试时候肯定不好,引入rescale可以有效的缓解,保证训练和测试时候,经过dropout后数据分布能量相似。
#!encoding=utf-8
import numpy as np
def dropout(x, drop_out_ratio,type="train"):
if drop_out_ratio < 0. or drop_out_ratio>= 1: # drop_out_ratio是概率值,必须在0~1之间
raise Exception('Dropout level must be in interval [0, 1[.')
if type=="train":
scale = 1. / (1. - drop_out_ratio)
mask_vec = np.random.binomial(n=1, p=1. - drop_out_ratio,size=x.shape) # 即将生成一个0、1分布的向量,0表示这个神经元被屏蔽,不工作了,也就是dropout了
print mask_vec
x *= mask_vec # 0、1与x相乘,我们就可以屏蔽某些神经元,让它们的值变为0
x*=scale #再乘上scale系数
print(x)
return x
x=[100,29.5,1,2.0,3,4,23,12,34,45,667,76]
dratio=0.4
xnp=np.array(x)
print(x)
dropout(xnp,dratio,"train")
dropout方法多是作用在全连接层上,在卷积层应用dropout方法意义不大。文章认为是因为每个feature map的位置都有一个感受野范围,仅仅对单个像素位置进行dropout并不能降低feature map学习的特征范围,也就是说网络仍可以通过该位置的相邻位置元素去学习对应的语义信息,也就不会促使网络去学习更加鲁邦的特征。
既然单独的对每个位置进行dropout并不能提高网络的泛化能力,那么很自然的,如果我们按照一块一块的去dropout,就自然可以促使网络去学习更加鲁邦的特征。思路很简单,就是在feature map上去一块一块的找,进行归零操作,类似于dropout,叫做dropblock。

绿色阴影区域是语义特征,b图是模拟dropout的做法,随机丢弃一些位置的特征,但是作者指出这中做法没啥用,因为网络还是可以推断出来,(c)是本文做法。
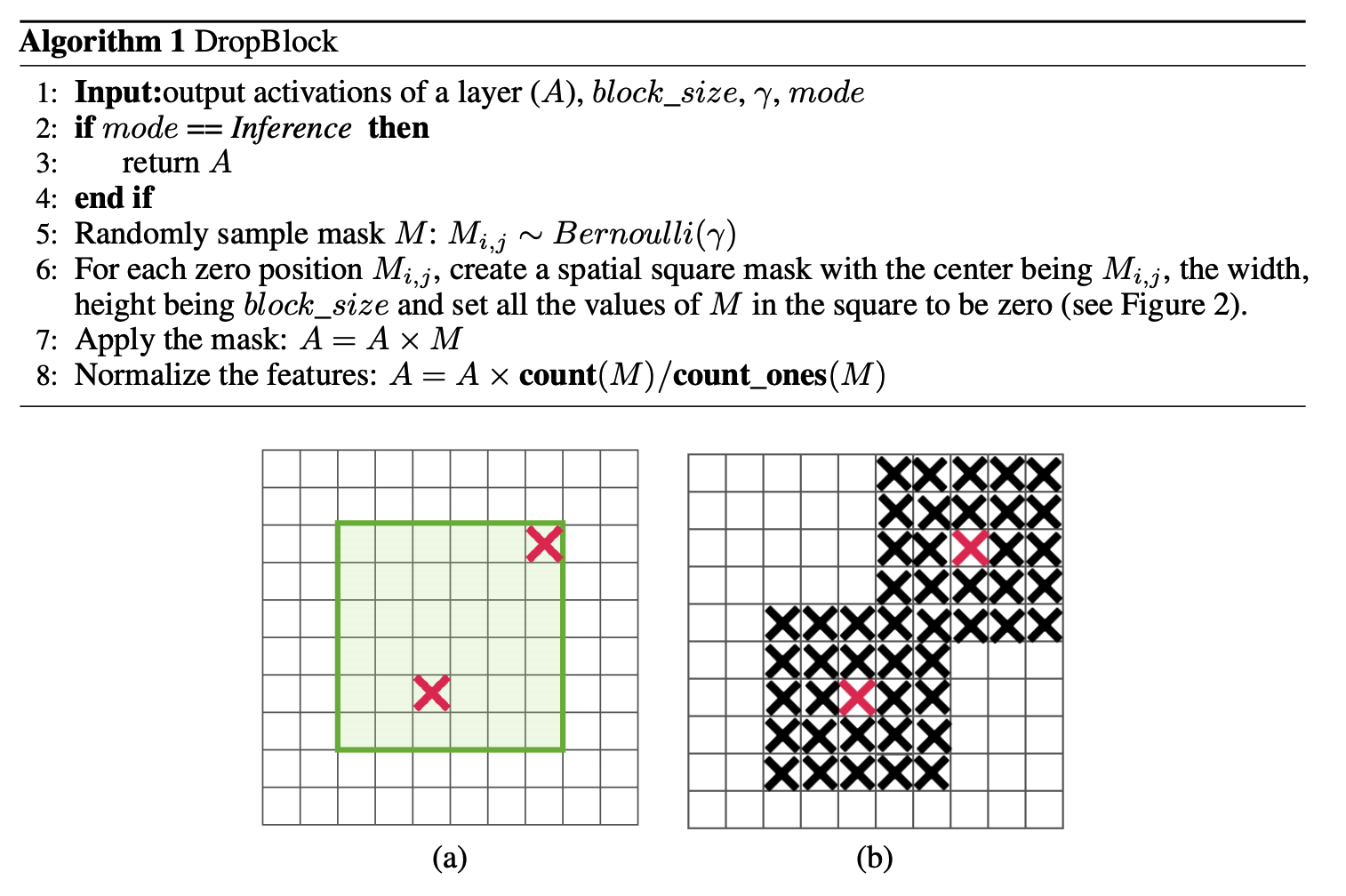
dropblock有三个比较重要的参数,一个是block_size,用来控制进行归零的block大小;一个是γ,用来控制每个卷积结果中,到底有多少个channel要进行dropblock;最后一个是keep_prob,作用和dropout里的参数一样。
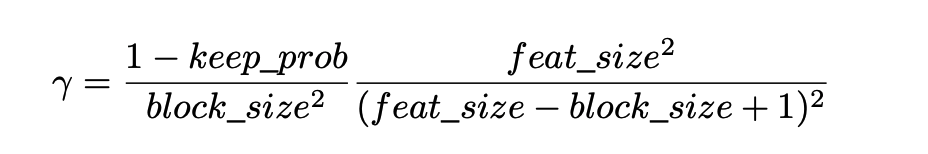
M大小和输出特征图大小一致,非0即1,为了保证训练和测试能量一致,需要和dropout一样,进行rescale。
上述是理论分析,在做实验时候发现,block_size控制为77效果最好,对于所有的feature map都一样,γ通过一个公式来控制,keep_prob则是一个线性衰减过程,从最初的1到设定的阈值(具体实现是dropout率从0增加到指定值为止),论文通过实验表明这种方法效果最好。如果固定prob效果好像不好*。
实践中,\(\alpha\)并没有显式的设置的值,而是根据keep_prob(具体实现是反的,是丢弃概率)来调整。
DropBlock in ResNet-50 DropBlock加在哪?最佳的DropBlock配置是block_size=7,在group3和group4上都用。将DropBlock用在skip connection比直接用在卷积层后要好,具体咋用,可以看代码。
class DropBlock2D(nn.Module):
r"""Randomly zeroes 2D spatial blocks of the input tensor.
As described in the paper
`DropBlock: A regularization method for convolutional networks`_ ,
dropping whole blocks of feature map allows to remove semantic
information as compared to regular dropout.
Args:
drop_prob (float): probability of an element to be dropped.
block_size (int): size of the block to drop
Shape:
- Input: `(N, C, H, W)`
- Output: `(N, C, H, W)`
.. _DropBlock: A regularization method for convolutional networks:
https://arxiv.org/abs/1810.12890
"""
def __init__(self, drop_prob, block_size):
super(DropBlock2D, self).__init__()
self.drop_prob = drop_prob
self.block_size = block_size
def forward(self, x):
# shape: (bsize, channels, height, width)
assert x.dim() == 4, \
"Expected input with 4 dimensions (bsize, channels, height, width)"
if not self.training or self.drop_prob == 0.:
return x
else:
# get gamma value
gamma = self._compute_gamma(x)
# sample mask
mask = (torch.rand(x.shape[0], *x.shape[2:]) < gamma).float()
# place mask on input device
mask = mask.to(x.device)
# compute block mask
block_mask = self._compute_block_mask(mask)
# apply block mask
out = x * block_mask[:, None, :, :]
# scale output
out = out * block_mask.numel() / block_mask.sum()
return out
def _compute_block_mask(self, mask):
# 比较巧妙的实现,用max pool来实现基于一点来得到全0区域
block_mask = F.max_pool2d(input=mask[:, None, :, :],
kernel_size=(self.block_size, self.block_size),
stride=(1, 1),
padding=self.block_size // 2)
if self.block_size % 2 == 0:
block_mask = block_mask[:, :, :-1, :-1]
block_mask = 1 - block_mask.squeeze(1)
return block_mask
def _compute_gamma(self, x):
return self.drop_prob / (self.block_size ** 2)