总览
由于是“图文多模态”,还是要从“图”和“文”的表征方法讲起,然后讲清楚图文表征的融合方法。这里只讲两件事情:
- 视觉表征:分为两个部分问题,一是如何合理建模视觉输入特征,二是如何通过预训练手段进行充分学习表征,这两点是基于视觉完成具体算法任务的基础;
- 视觉与自然语言的对齐(Visul Language Alignment)或融合:目的是将视觉和自然语言建模到同一表征空间并进行融合,实现自然语言和视觉语义的互通,这点同样离不开预训练这一过程。模态对齐是处理多模态问题的基础,也是现在流行的多模态大模型技术前提。
对于视觉表征,从发展上可以分为卷积神经网络(CNN)和Vision Transformer(VIT)两大脉络,二者分别都有各自的表征、预训练以及多模态对齐的发展过程。而对于VIT线,另有多模态大模型如火如荼的发展,可谓日新月异。
CNN:视觉理解的一代先驱
点击展开
卷积视觉表征模型和预训练
对视觉信息的表征,简单来说是将图像信息转化成深度学习输入所需的特征向量或向量序列,如图2。深度学习时代,卷积神经网络(CNN)凭借其局部区域连接、权重共享以及位移不变性等特点,天然的符合了图像信息的建模归纳假设,成为早期最适合视觉表征的模型。具体的,卷积神经网络应用视觉表征的模型很多,我们简单从LeNet-5、AlexNet、VGG和ResNet等模型的演进一窥其在关键要素。
卷积视觉表征:从LeNet到ResNet
LeNet-5早期在数字识别中取得了成功的应用,网络结构是 [CONV-POOL-CONV-POOL-FC-FC]。卷积层使用 55的卷积核,步长为1;池化层使用 22 的区域,步长为2;后面是全连接层;AlexNet相比LeNet-5做了更多层数的堆叠,网络参数进行了相应的调整,并在ImageNet大赛2012夺得冠军;相应VGG网络使用更小的卷积核,同时相比AlexNet进一步提升了网络层数。
随着研究的深入,神经网络的层数也出现了爆发式地增长,由此也不可避免的带来梯度消失和梯度爆炸的问题,使得模型训练的困难度也随之提升。一种解决方法是将神经网络某些层跳过下一层神经元的连接,隔层相连,弱化每层之间的强联系。这种神经网络被称为Residual Network(ResNet)残差网络,网络结构的原理是将卷积层的堆叠,替换成跨层连接的模块,如下图所示。

有了合理的建模模型,可以使用具体任务的训练数据学习视觉表征,进而完成不同的任务(如分类、分割、目标检测等)。而更加有效的方式通常是先用“海量”的数据让模型学到通用的视觉表征,再进行下游具体任务数据的学习,也就是预训练+微调的范式。
卷积视觉预训练
在CNN视觉表征体系下,早期的视觉预训练有另一个叫法是迁移学习,在BERT的预训练+微调范式流行之前就已经被广泛应用。迁移学习中,传统CNN视觉模型在做具体任务训练之前,先在大量的图像任务数据集上进行预先训练(如ImageNet分类任务数据集等)。然后使用预训练的CNN权重初始化Backbone,并增加一些任务定制网络模块,完成在下游任务上的微调(如Backbone+全连接层做分类任务)。
卷积神经网络视觉表征和预训练的优化升级工作还有很多,介绍相关内容的资料也很多,篇幅原因我们对此不进行详细展开和概述,而是把更多的笔墨放在近几年更热门的研究方向上。
早期多模态融合与预训练
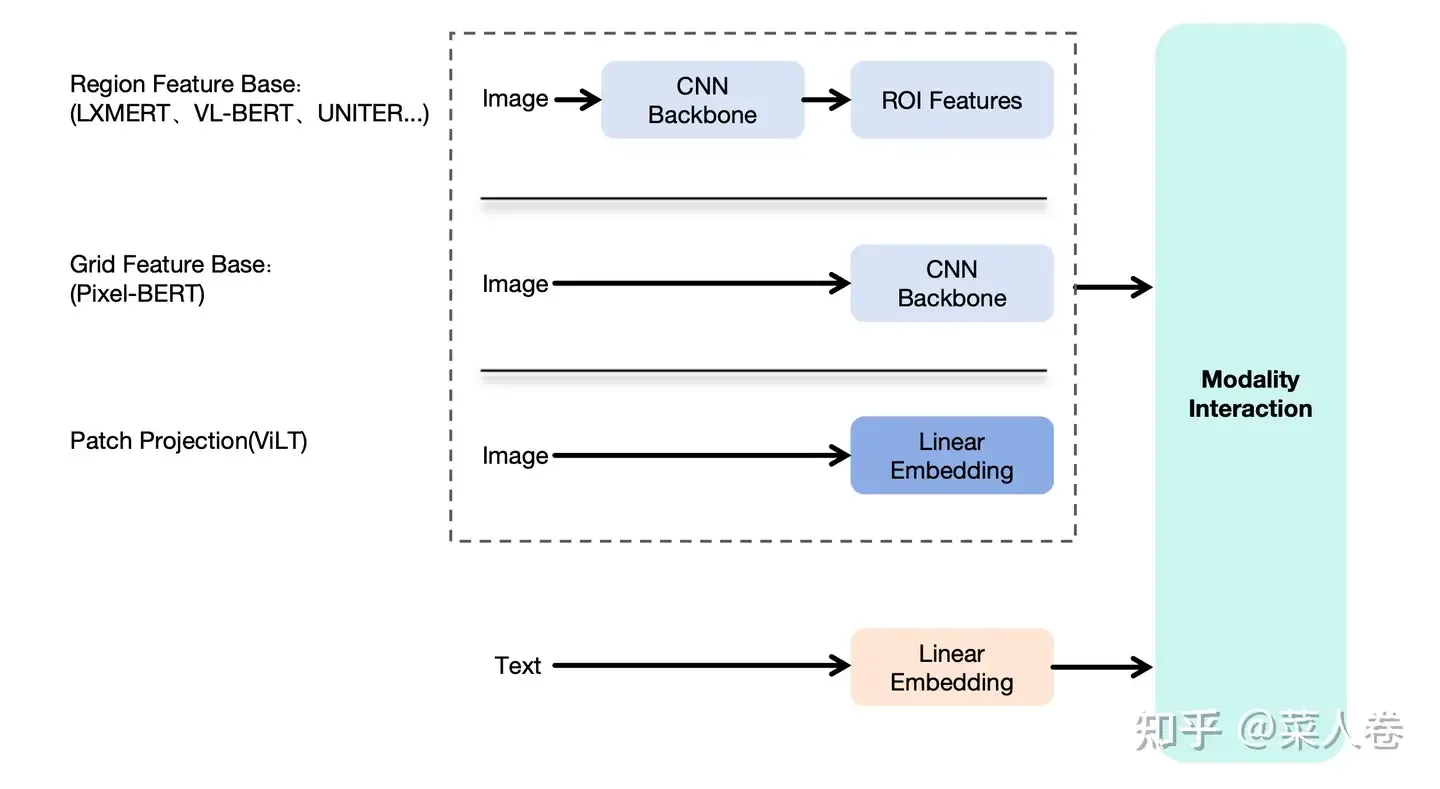
接着是CNN体系下的多模态融合和预训练,视觉和自然语言的跨模态对齐和融合有两种表现形式:一种是双塔结构,多模态分别表征,通过对比学习机制实现视觉和文本在同一空间中的距离度量;另一种是视觉表征和文本表征通过交互型网络结构融合成多模态表征,进而完成下游任务应用。由于前者可以看作后者的特例,我们用后一种表现形式为例,将二者统一,进而讲述以CNN为基础的早期多模态融合与预训练技术。
如下图,展示了上述的多模态融合框架,包括视觉特征提取模块、文本特征提取模块和模态融合模块。文本模块是常见的Token Embedding方式;视觉表征方面,由于CNN已经验证了有效性,因此大多数的工作在都考虑使用CNN做视觉特征抽取,得到高级语义特征,然后将高级语义表征作为输入,和文本Token Embedding序列一起输入到下游融合模块。不同工作的差异主要集中在视觉特征提取CNN Backbone以及Modality Interaction两个模块。
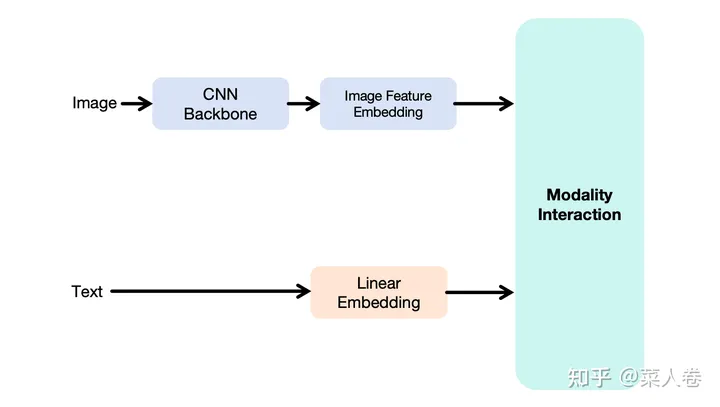
我们以2019年作为粗略分界点,在此之后BERT的训练范式开始流行,多模态方向上的研究热点则是借鉴BERT的成功,使用Transformer网络(特指Transformer Encoder)作为Modality Interaction模块把视觉和自然语言进行特征融合,并通过大规模预训练来学习得到多模态表征;而在此之前的方案通常是简单的多层全连接网络实现,我们不多赘述。
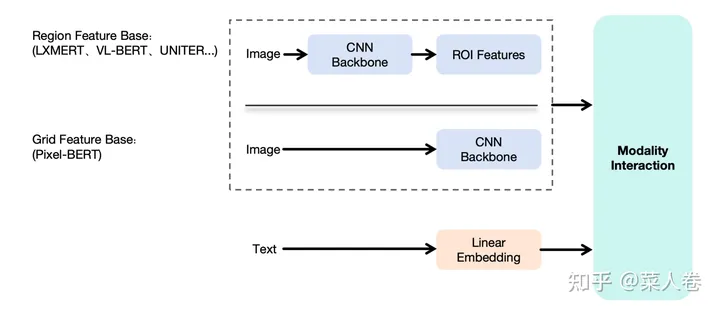
顺着这个思路,确定了使用Transformer作为模型融合模块这个大方向后,第二个问题是如何对视觉特征进行有效编码,得到和文本一样的Token Embedding序列作为模型输入?这一问题的解法在CNN为主的时期有两种主要方式,如图5:
- Region Feature Base:先通过基于CNN的目标检测模型(Fast R-CNN等),识别图像中的关键物体区域集合(ROI,Region Of Interest),并提取区域的表征向量,作为Transformer模型的视觉输入Embedding序列。这么做的动机是,每个ROI区域,都有明确的语义表达(人、建筑、物品等),方便后续和文本特征的对齐。比较有代表性的工作如LXMERT、VL-BERT和UNITER等;
- Grid Feature Base:区域特征方法虽然看上去合理,但是依赖前置的目标检测模型,整体链路较重。因此也有工作探索,不经过区域检测,直接使用CNN网络提取深层的像素特征作为交互模型输入,同样取得了一些成果。比较有代表性的工作如Pixel-Bert等。
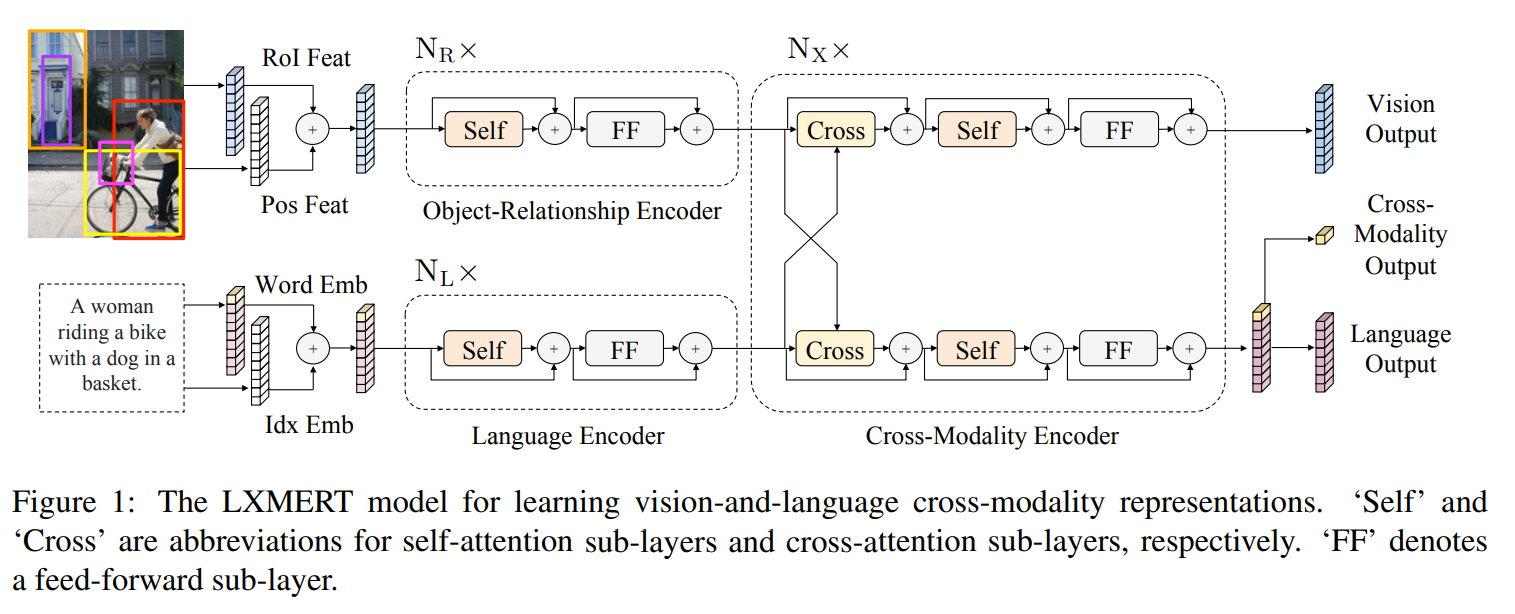
LXMERT
LXMERT是早期进行多模态特征融合的工作之一,如图,模型采用经典的两路深层表征输入结构。在视觉侧关注单图,图像经过目标检测模型得到区域块的特征序列,又经过Transformer做进一步编码区域块之间的关系(Object-Relationship Encoder);文本侧通过BERT结构得到文本的特征序列(Language Encoder),最后两者使用深层Transformer结构做交叉Attention,最后进行多任务的预训练。LXMERT的预训练任务相比BERT较多,包括Masked图像特征的预测、图像Label的预测(猫、狗等)、VQA、图文是否匹配以及纯文本侧的Masked语言模型(MLM)。
预训练模型经过特定任务微调后,LXMERT在两个视觉问答数据集(VQA和GQA)上达到了当时最先进的结果。作者还展示了LXMERT可以很好地泛化到一个具有挑战性的视觉推理任务(NLVR2),并将之前的最佳结果提高了22%(从54%到76%),是一个比较优秀的工作。
VL-BERT
另一个Region Feature Base的经典工作是VL-BERT。如图,与LXMERT不同的是,VL-BERT属于单路输入模式,视觉特征在经过目标检测模型进行Region特征提取后,直接和文本Embedding一起拼接输入到Transformer网络中进行多模态的交叉Attention。

VL-BERT设计了两个预训练任务:带视觉特征的掩码语言模型学习(Masked Language Modeling with Visual Clues)、带文本特征的视觉Region分类(Masked RoI Classification with Linguistic Clues)。经过预训练和微调流程,模型可以适用于多种视觉和语言任务,并在视觉问答、图像-文本检索、视觉常识推理等任务上都取得了非常不错的性能。VL-BERT印证了,多模态语义特征不需要各自的单独深度编码,直接做交互也可以取得有效结果。
UNITER
如图,UNITER使用和VL-BERT类似的架构,同样的单路架构,同样是目标检测模型做视觉的语义特征抽取,并进一步使用更多的训练数据、更多的预训练任务,希望得到一个更加通用的图文多模态表征模型。UNITER通过在四个图像和文本数据集(COCO, Visual Genome, Conceptual Captions, and SBU Captions)上进行大规模的预训练,可以支持多种视觉和语言任务的联合多模态表征。同时设计了四种预训练任务:遮蔽语言建模(MLM),遮蔽区域建模(MRM,有三种变体),图像-文本匹配(ITM),和词-区域对齐(WRA)。

相比于之前方案,UNITER提出了通过最优传输(OT,Optimal Transport)的方法来进行WRA,在预训练过程中显式地加强词和图像区域之间的细粒度对齐。相比其他工作仅使用图像-文本匹配(ITM)的全局对齐方式,WRA更加精准。经过大量的消融实验,UNITER还探索了预训练任务的最佳组合方式,并最终在视觉问答,图像-文本检索,指代表达理解,视觉常识推理,视觉蕴含,和NLVR2等任务上都达到了新的最先进的水平。
UNITER称得上是Region Feature Based多模态预训练的集大成者,同时期的大多数工作也多是类似结构上的修补或增强。但也不乏另辟蹊径的工作,其中以Grid Feature Based相关工作最具影响力。
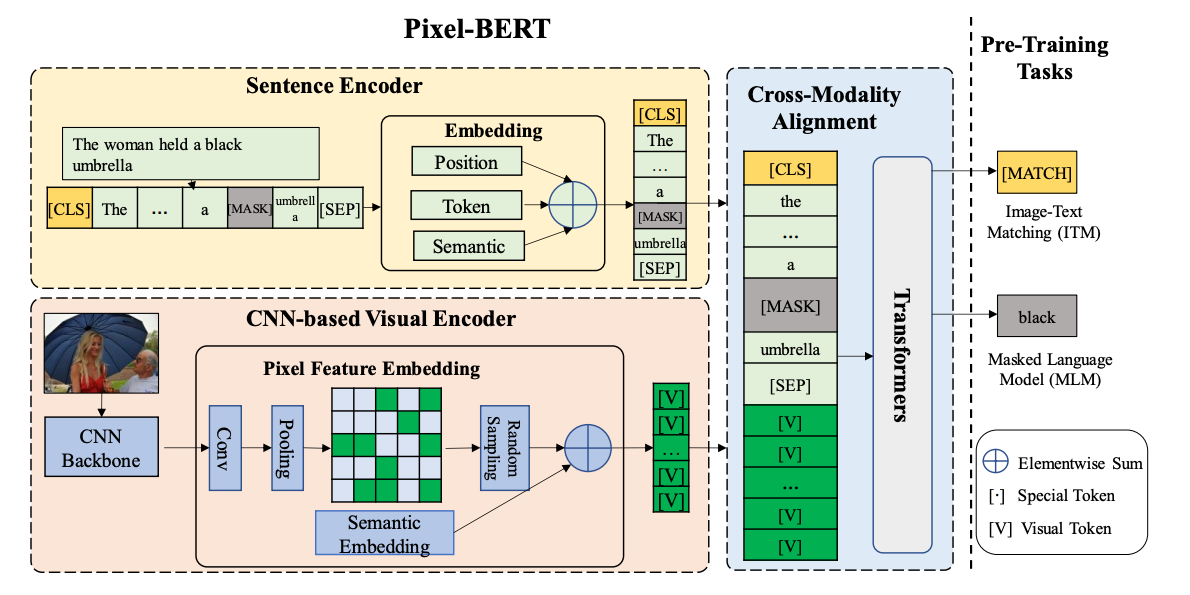
Pixel-BERT
Pixel-BERT是Grid Feature Based多模态融合代表工作之一。如图,与Region Feature Based方法不同的是,Pixel-BERT不需要使用目标检测模型进行ROI区域的特征抽取,而是直接通过卷积网络提取图片的像素级别特征,直接和文本特征一起输入到下游的Transformer网络进行特征融合。这种方式减少了目标检测区域框标注的成本,同时缓解了视觉语义label与文本语义的不均衡问题(区域框的物体类别往往上千规模,而文本可以表达的语义远不止于此)。
详细来说,当时主流的Region Feature Based方法提取视觉特是使用如Fast R-CNN的目标检测模型,通常在Visual Genome数据集上训练得到。这种目标检测模型,通常先提取可能存在物体的区域,然后根据区域特征进行物体类别的分类。相应的,这些区域的特征往往局限在固定的类目集合范围内,语义范围较为有限,这是也使用区域语义特征的固有缺陷。
Pixel-BERT的思路是直接学习像素级别的表征来代替物体框为主的区域特征,具体的,像素特征通过ResNet之类的卷积神经网络提取得到。对于给定的图片 \(I\),先使用CNN backbone提取特征(如从2242243 经过多层卷积网络到55channel_dim)。然后按空间顺序,铺平网格特征序列,计作\(\mathbf{v}=\left\{v_1,v_2,...,v_k\right\}\in\mathbb{R}^d\),\(k\) 为像素特征的数量。最终的视觉语义embedding特征记作 \(v=\{\hat{v}_1,\hat{v}_2,...,\hat{v}_k\}\) ,\(\hat{v}_i=v_i+s_v\),其中 \(𝑠_𝑣\) 是可学习的语义表征向量,用于区分文本表征向量。由于所有的像素共用\(s_v\),索引\(s_v\) 也可以看作是CNN backbone的一个bias项。
此外,Pixel-BERT使用随机像素采样机制来增强视觉表示的鲁棒性,并使用MLM和ITM作为预训练任务进行预训练。最后通过对下游任务进行广泛的实验,在包括视觉问答(VQA)、图像文本检索和视觉推理等下游任务中取得了SOTA效果。
VIT范式视觉表征和预训练
Pixel-BERT之类的网络,减少了对与目标检测模型的依赖,仅使用深层卷积神经网络提取像素级别的特征作为下游多模态融合模块,极大简化了图文多模态表征模型的网络结构。那么,我们能不能进一步简化视觉表征模块,直接把图像特征简单加工后就直接输入到Transformer网络和文本特征一起做模态的融合?要做到这一点,我们需要先回答另一个问题,Transformer网络能不能替换CNN作为视觉表征的Backnone?虽然现在来看,答案是肯定的,但在开始阶段,这个过程并不是那么顺利。
我们知道,CNN应用于视觉表征有着很强的归纳偏置或者说先验,在 CNN 中,局部性、二维邻域结构和平移不变性是在整个模型的每一层中都有体现,和视觉图像的特点极其类似:
- 局部感知性:卷积层通过卷积操作和参数共享,能够高效地提取输入图像的局部特征。这种局部感知性使得CNN能够捕捉图像中的局部结构,例如边缘、纹理等,从而更好地表征图像。
- 层级结构:CNN的层级结构包括卷积层、激活函数、池化层和全连接层。这种层级结构使得CNN能够逐层提取和组合特征,从低级到高级,形成更复杂的视觉表征。
- 参数共享:卷积层中的参数共享使得CNN的训练更加高效。相同的卷积核在不同位置对图像进行卷积操作,共享参数减少了模型的复杂度,同时也增强了模型的泛化能力。
- 空间不变性:卷积操作具有平移不变性,即无论图像中的物体在图像中的位置如何变化,卷积核都能检测到相应的特征,这对于图像分类、目标检测和图像分割等计算机视觉任务非常重要。
而在 Transformer 中的Self-Attention层则是全局的,对于视觉输入的局部关系建模、图像的2D位置关系的建模,以及图像元素的平移不变性的把握上,都需要从头学习。然而,即便是困难重重,因为有BERT的巨大成功,仍然有许多的研究者前赴后继投入到这个方向,并最终取得成功,其中Vision Transformer (ViT) 是最为经典的案例之一。
VIT:Transformer视觉表征
如下图,VIT将输入图片平铺成2D的Patch序列(16x16),并通过线性投影层将Patch转化成固定长度的特征向量序列,对应自然语言处理中的词向量输入。同时,每个Patch可以有自己的位置序号,同样通过一个Embedding层对应到位置向量。最终Patch向量序列和视觉位置向量相加作为Transfomer Encoder的模型输入,这点与BERT模型类似。
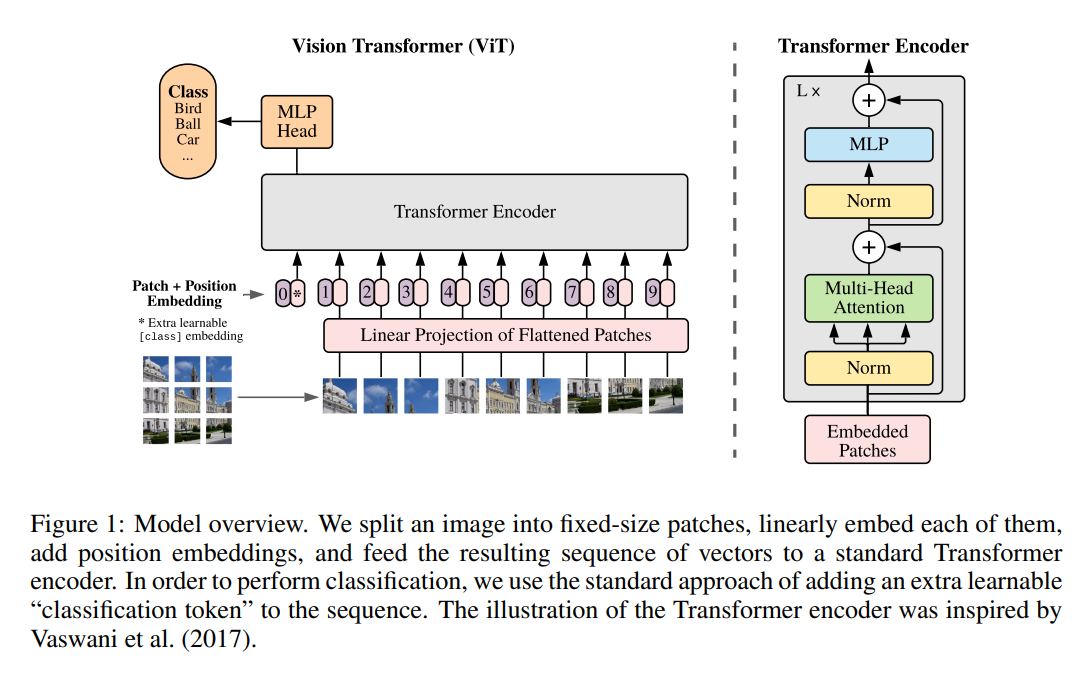
同样,VIT通过一个可训练的CLS token得到整个图片的表征,并接入全链接层服务于下游的分类任务。当经过大量的数据上预训练,迁移到多个中等或小规模的图像识别基准(ImageNet, CIFAR-100, VTAB 等)时,ViT取得了比CNN系的模型更好的结果,同时在训练时需要的计算资源大大减少。按说,ViT的思路并不复杂,甚至一般人也不难想到,但是为什么真正有效的工作确没有很快出现?不卖关子,VIT成功的秘诀在于大量的数据做预训练,如果没有这个过程,在开源任务上直接训练,VIT网络仍会逊色于具有更强归纳偏置的CNN网络。
因此,在此之后的一大研究方向就是如何更加有效的对VIT结构的网络进行预训练。下面我们通过MAE和BEIT两个优秀的工作,来讨论这个方向上的两类主流方案。
关于ViT的介绍可以参考:ViT
MAE
与自然语言理解类似,VIT模型能取得成功得益于预训练+微调的训练范式。前文提到,传统CNN视觉模型的预训练,仅仅是在大量的图像任务数据集上进行预先训练(如ImageNet分类任务等),然后使用训练后的权重进行初始化Backbone,在下游任务上继续微调完成相应任务。
早期的VIT的预训练和CNN预训练一样,都是通过大规模的有监督分类任务数据集进行训练,和BERT的自监督预训练仍有区别。而自监督预训练有着数据获取成本低、不需要标注、任务难度大模型学习充分等诸多好处,因此很多研究工作探索自监督视觉预训练,比较有代表性的实践工作如Masked AutoEncoder(MAE)。
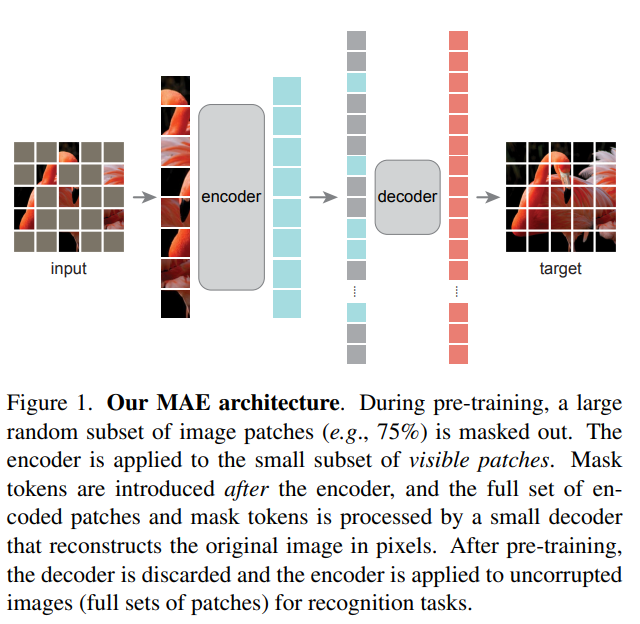
如上图,所示,MAE以VIT为基础模型,先对完整图片进行Patch掩码,接着使用一个Transformer Encoder对未Mask的Patch进行编码,然后通过相对小的Transformer Decoder模型还原被Masked Patch,从而实现模型的自监督预训练。
MAE取得成功的另一个核心原因是通过75%的高掩码率来对图像添加噪音,这样图像便很难通过周围的像素来对被掩码的像素进行重建,从而使编码器去学习图像中的语义信息。预训练之后,解码器被丢弃,编码器可以应用于未掩码的图像来进行识别任务。
相对于自然语言的自监督训练,MAE使用了更大的掩码比例。后人进一步分析,这么做动机是考虑自然语言和视觉特征的信息密度不同,简单来说:文本数据是经过人类高度抽象之后的一种信号,信息是密集的,可以仅仅预测文本中的少量被掩码掉的单词就能很好的捕捉文本的语义特征。而图像数据是一个信息密度非常小的矩阵,包含着大量的冗余信息,像素和它周围的像素存在较大的相似性,恢复被掩码的像素并不需要太多的语义信息。
BEIT:视觉“分词”表征预训练
另一类Transformer视觉模型预训练的代表范式是BEIT(BERT Pre-Training of Image Transformers)模型。为了与BERT的预训练框架对齐,BEIT通过辅助网络模块先对视觉Patch进行Tokenizer,得到整张图各部分的视觉Token ID。然后将视觉Patch视为自然语言中的单词进行掩码预测,完成预训练流程。

具体的如上图,在预训练之前,BEIT先通过一个离散自回归编码器( discrete Variational AutoEncoder,dVAE)学习了一个“图像分词”器,最终可以将图像编码成离散的视觉Token集合。而在预训练阶段,输入的图片存在两个视角,一是图像Patch,另一个是视觉Token。BEIT随机对Patch进行掩码,并将掩码部分替换为特殊的Mask Embedding([M],图中的灰色部分),随后将掩码后的Patch序列输入到VIT结构的模型中。预训练的目标则是基于被掩码的图像输入向量序列,预测源图像对应的视觉Token ID。
BEIT需要单独的dVAE网络辅助,相对MAE更为复杂。在效果上,MAE验证了使用normalized pixels进行目标像素重建,也可以实现类似效果,因此视觉tokenization过程并非必须。但即便如此,BEIT为视觉预训练提供了一个不错的范式,同样是一次十分有价值的探索。
详情见:BEiT:视觉BERT预训练模型
VIT为基础的多模态对齐与预训练
以VIT为基础的视觉预训练可以通过Transformers对视觉进行有效表征,这种方法也逐渐成为目前视觉信息编码的主流手段。以此为延伸,基于此的多模态预训练工作也层出不穷,也为如今的多模态大模型的顺理成章打下了坚实基础。
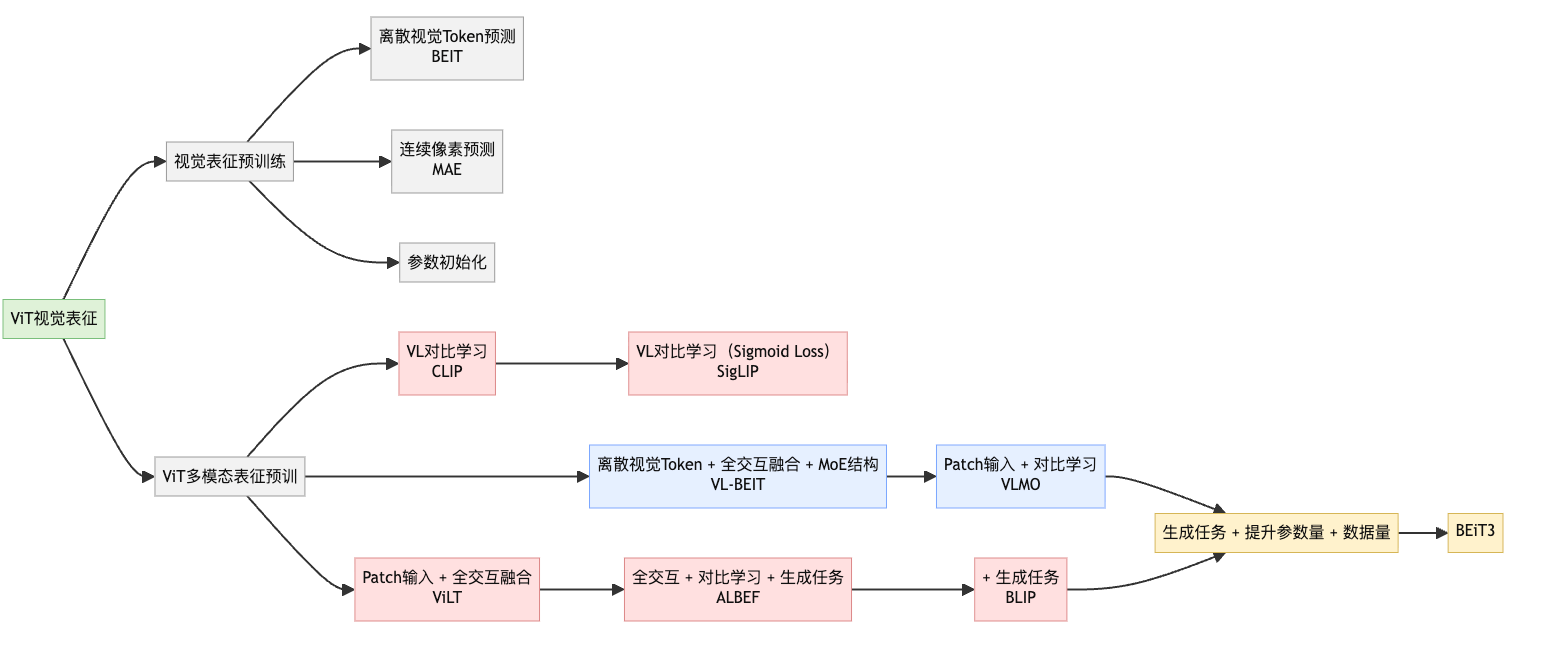
如下图,梳理了以VIT为延伸的多模态对齐和预训练工作,各工作之间都或多或少的有所关联,可谓是一脉相承。下面我们分别介绍这个技术方向的经典工作,读完本小结下面的内容再来看图中的模型关系,可能会更有感觉。
CLIP
CLIP模型是OpenAI 2021发布的多模态对齐方法。与OpenAI的许多工作类似,CLIP强调强大的通用性和Zero-Shot能力,也因此至今仍有很强的生命力,相关技术被广泛应用。
CLIP的核心思路是通过对比学习的方法进行视觉和自然语言表征的对齐。如下图(1),CLIP首先分别对文本和图像进行特征抽取,文本的Encoder为预训练BERT,视觉侧的Encoder可以使用传统的CNN模型,也可是VIT系列模型。得到图文表征向量后,在对特征进行标准化(Normalize)后计算Batch内图文Pair对之间的余弦距离,通过Triple Loss或InfoNCELoss等目标函数拉近正样本对之间的距离,同时使负样本对的距离拉远。
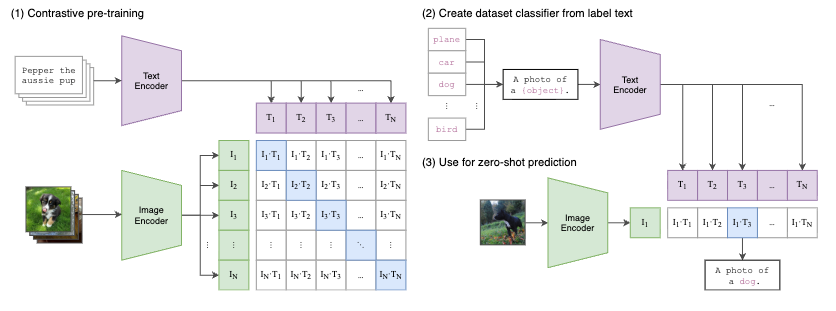
经过大量的图文Pair对进行预训练后,我们可以得到在同一表征空间下的文本Encoder和图像Encoder。下游应用通常也是两种方式,一是在下游任务上对模型进行微调,适应定制的图文匹配任务,或者仅使用文本或图像Encoder做单模态任务;另一种使用方式是直接使用预训练的图文表征Zero-Shot方式完成下游任务。
CLIP进行Zero-Shot的一种使用方式如图(2)和(3),对于一个图像分类任务,可以首先将所有的候选类别分别填充“A photo of a {object}”的模板,其中object为候选类别,对于一张待预测类别的图像,通过图像Encoder的到视觉表征后,与所有类别的模板文本Encoder表征进行相似度计算,最后选择相似度最高的类别即可作为预测结果。
CLIP凭借其简洁的架构和出众的效果,被后来很多工作引用,并使用CLIP预训练的Backbone作为视觉表征模块的初始化参数。
详情见:CLIP
VILT
CLIP方法简单有效,双塔的网络结构对于下游应用也十分友好。但是如同表示型语义匹配类似,双塔结构同样也有交互不足的问题,内积或余弦距离的模态融合方式匹配能力上限较低,对于一些需要细粒度跨模态匹配的任务(VQA等)有时力不从心。因此,交互式的多模态对齐和融合仍然极具价值,典型的如VILT模型。
视觉-语言模型的分类
作者首先对视觉-语言模型做了一个像综述一样的分类,说主要是基于以下两点分类:
- 图像和文本这两个模态的编码器是不是具有相似的参数或者计算成本。
- 这两个模态的编码结果是不是通过一个深度模型进行交互。
按照这两个分类依据,视觉-语言模型能够分为以下4类,如下图所示。
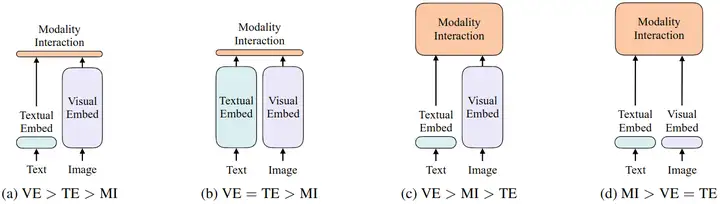
- 第1种模型如图 (a) 所示,属于是视觉模型占大部分算力,用简单的点积或浅注意层来表征两种模态中特征的相似性,代表模型是 VSE++和 SCAN。
- 第2种模型如图 (b) 所示,属于是视觉模型和文本模型都使用较大算力,用简单的点积或浅注意层来表征两种模态中特征的相似性,代表模型是 CLIP。但是,这种方法对于视觉-语言下游任务性能很差,比如 CLIP 在 NLVR2 数据集上面性能较差,说明纵使单一模态的编码器很好,但是对其输出的简单融合可能也不足以学习复杂的视觉和语言任务,这可能就需要我们去研究更严格的跨模态交互方案了。
- 第3种模型如图 (c) 所示,属于是视觉模型占大部分算力,使用 Transformer 对图像和文本特征的交互进行建模,代表模型是 FiLM和 MoVie。
- 第4种模型如图 (d) 所示,属于是视觉模型和文本模型都极其简单,大部分计算力集中在模态的交互上面,使用 Transformer 对图像和文本特征的交互进行建模,代表模型是本文的 ViLT。
VILT是VIT在图文多模态方向上的工作延续。我们了解了基于Transformer的自然语言模型和视觉模型的预训练范式后,进阶到多模态融合十分容易理解。如图所示,与BERT文本对的输入方式类似,VILT将文本和视觉Patch的Embedding直接拼接作为Transformer编码器的输入,两种模态有各自可学习的位置编码和模态类型编码。
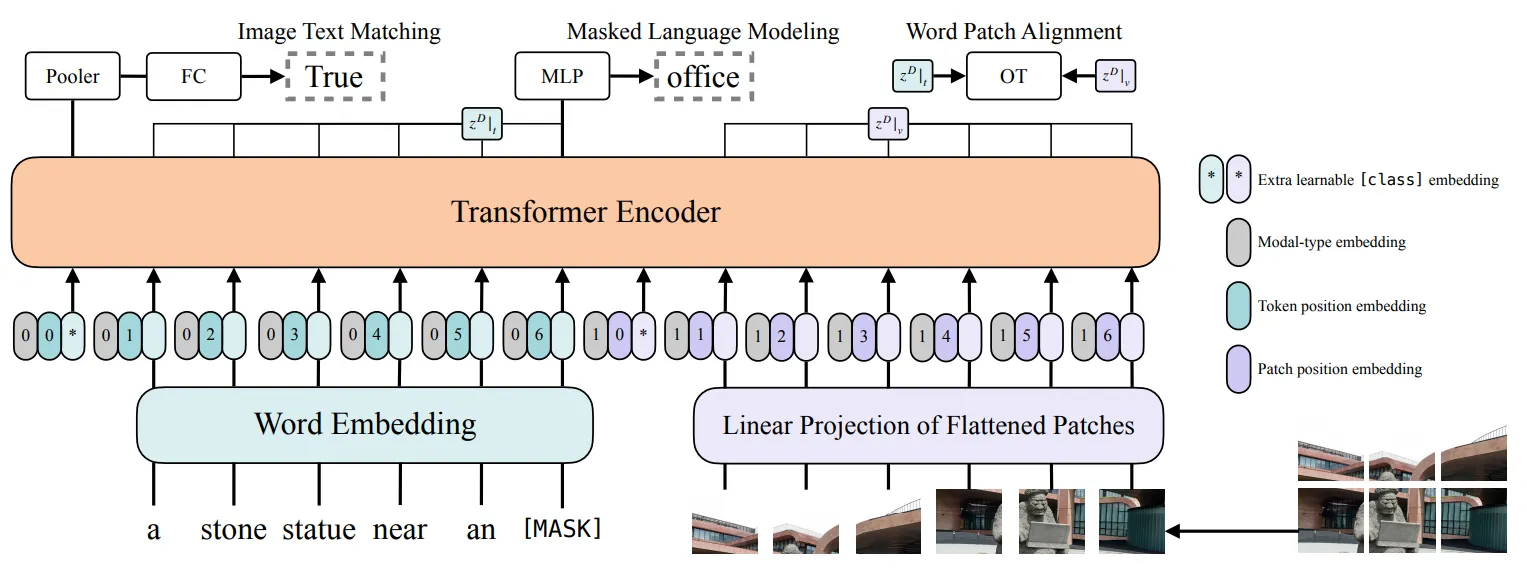
通过深层的Transformer编码,文本与视觉的模态得到了充分的融合。ViLT使用常用的ITM(Image Text Matching)和MLM(Masked Language Modeling)作为预训练目标。
- ITM(Image Text Matching):图文是否匹配的二分类目标,正样本为常用数据集中提供的语义一致的图文Pair对,负样本对以0.5的概率随机地用替换正图文对中的图片为其他图片;此外借鉴前人工作,匹配目标还增加了图文子区域的匹配目标Word Patch Alignment (WPA),该目标并不常用,我们也不作过多展开。
- MLM(Masked Language Modeling):以0.15的概率对文本的Token进行掩码,并通过图文的整体上下文信息对预测被掩码的Token。
如下图,可以对比以CNN为基础的多模态预训练和以VIT为基础的预训练,在模型架构上的区别。
而在ViLT之后,多模态预训练的一个较为明显的趋势,是进一步提升模态对齐与融合的效果以及模型结构的通用性,使用统一模型视角进行跨模态对齐和融合。在这个过程中,ALBEF(Align before Fuse)、BLIP(Bootstrapping Language-Image Pre-training)与BEIT-3系列等工作极具参考价值,下面我们简单对比其设计思路。
ALBEF
ALBEF(Align before Fuse)
- 针对 "图片的嵌入特征和单词的嵌入特征各自在各自的空间,难以交互" 的问题,ALBEF 提出:图文对齐后再融合。具体而言就是对于图片的 Embedding 和文本的 Embedding 引入一个对比学习的损失函数 image-text contrastive loss,在融合之前提前把图片和文本的表征对齐。这样做就使得后续的多模态 Transformer 更容易执行跨模态学习。
- 针对 "目标检测器计算代价较高" 的问题,ALBEF 的视觉编码器和文本编码器均不使用目标检测器 类似VILT。
- 针对 "图像文本数据集有噪声" 的问题,ALBEF 提出:动量蒸馏 (MoD) 的方法使模型能够利用更大的带噪声数据集。在训练期间,作者维持一个动量模型,其参数就是之前模型参数的移动平均。然后使用这个动量模型生成伪目标作为额外的监督。MoD 技术的作用是:当数据中有噪声导致监督信号不合理时,动量模型就可以给出额外的监督信号,改善模型的预训练。作者表明 MoD 不仅适用于预训练数据集有噪声的情况,还适用于预训练数据集很干净的情况。
ALBEF通过多任务联合训练将类似CLIP的对比学习和类ViLT的交互融合范式统一到一个训练框架中。如图所示,模型结构包括:
- 视觉编码器就是 ViT,初始化权重也是来自它。
- 文本编码器是 BERT 的一半,前6层做文本编码,初始化权重也是来自它。
- 视觉编码器的体量大于文本,经验发现这样做效果好。
- 多模态编码器是 BERT 的另一半,后6层做多模态编码。
ALBEF的训练任务包括图文对比ITC(Image-Text Contrastive Learning)、ITM(Image-Text Matching)、MLM(Masked Language Modeling)。
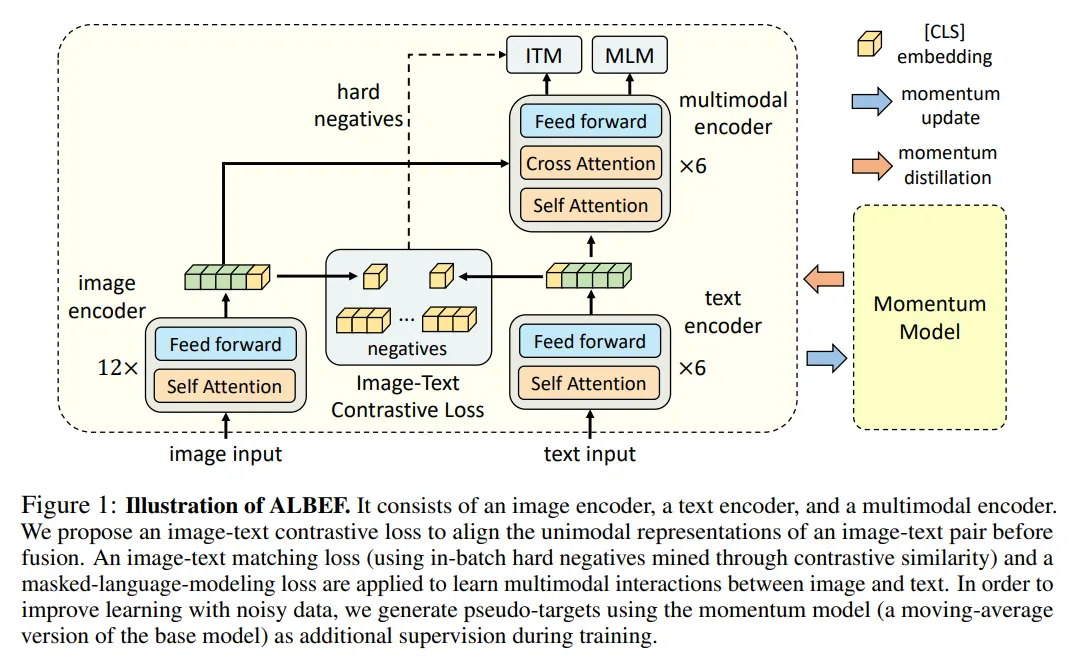
- ITC:在图文模态深层融合之前,在对图文的表征序列Pooling后,通过对比学习Loss对图文单模态表征进行对齐。这部分和CLIP模型的训练设置类似,不同的是文本的Encoder相对视觉Encoder层数更浅。
- ITM:图文Encoder输出的表征序列深层交互后,判断输入图文对是否匹配,与VILT一样是二分类任务。不同的是负样本对的构造,使用对比学习模块进行了Batch内的难负样本挖掘。主要思路是,对比学习模块中一个Batch中,模型认为最为相似的负样本对可以作为难负样本。
- MLM:与VILT类似,随机对输入文本token进行掩码,通过图文上下文的输入信息预测被掩码的Token。
最后,由于ALBEF的预训练数据多数为互联网中挖掘的图文对,天然存在较大的噪声数据。为了缓解这个问题,ALBEF在训练过程中通过一个动量自蒸馏的模块(一个移动平均版本的ALBEF模型),生成训练数据集的伪标签,用来辅助模型的训练。
动量模型是另一套参数的 ALBEF,它的参数是单模态和多模态编码器的指数移动平均版本 (Exponential-Moving-Average)。这样训练时的目标就不仅仅是 GT 标签,还有这个动量教师模型了。而这个动量教师模型的参数又随着 ALBEF 模型的训练而缓慢地更新。
ALBEF通过多任务训练机制将模态对比匹配和深度模态融合结合在一起,下游任务可以根据具体需求使用不同的模块进行微调。
CoCa
CoCa (Contrastive Captioners) 就是在训练的时候使用两个目标函数,分别是基于对比学习的损失函数 Contrastive Loss 和基于生成式图像字幕任务的目标函数 Captioning Loss。CoCa 采用 Encoder-Decoder 架构,包括 Image Encoder,单模态 Text Encoder 和多模态 MultiModal Encoder。
CoCa 使用大规模的网络数据集从头训练模型,在一众单模态视觉任务和多模态任务上拔得头筹,如图所示。单模态任务包括视觉识别 (ImageNet, Kinetics400/600/700, Moments-in-Time),多模态任务包括跨模态检索 (MSCOCO, Flickr30K, MSR-VTT) 和多模态理解任务 (VQA, SNLI-VE, NLVR2) 和图像字幕 (MSCOCO, NoCaps)。

- CoCa 是 ALBEF 的后续工作,一些过程继承了 ALBEF 的过程,详细过程如下:
- 左边是 Image Encoder,右边是 Text Decoder
- 图像的 [CLS] token 和文本的 [CLS] token 做一个 contrastive loss,然后剩下的图像 token 做一下 Attention pooling,然后再传到 多模态的 Text Decoder 里做 Cross-Attention ,这样就把 V&L 的特征融合到一起了。
- 最后用了 Captioning Loss
- 与 ALBEF 的区别
- 图像的 attention pooling 是可学的,能针对不同任务学到更好特征。
- 文本这一端,不论是单文本还是多模态用的都是 Decoder。
- 采用 Captioning Loss 与 Decoder 结构目的是加快运算速度。
- 模型参数 2.1B
- 数据集:
- GFT 3B 转化成了多模态数据集
- 还有一个之前训练 Align 的数据集
BLIP
与之遥相呼应的的是BLIP模型,在ALBEF基础上,将MLM替换为LM( Language Modeling)Loss,使得训练得到的模型同时可以支持图像描述文本的生成能力,如图所示。使得多模态融合预训练有了多模态大模型即视感。
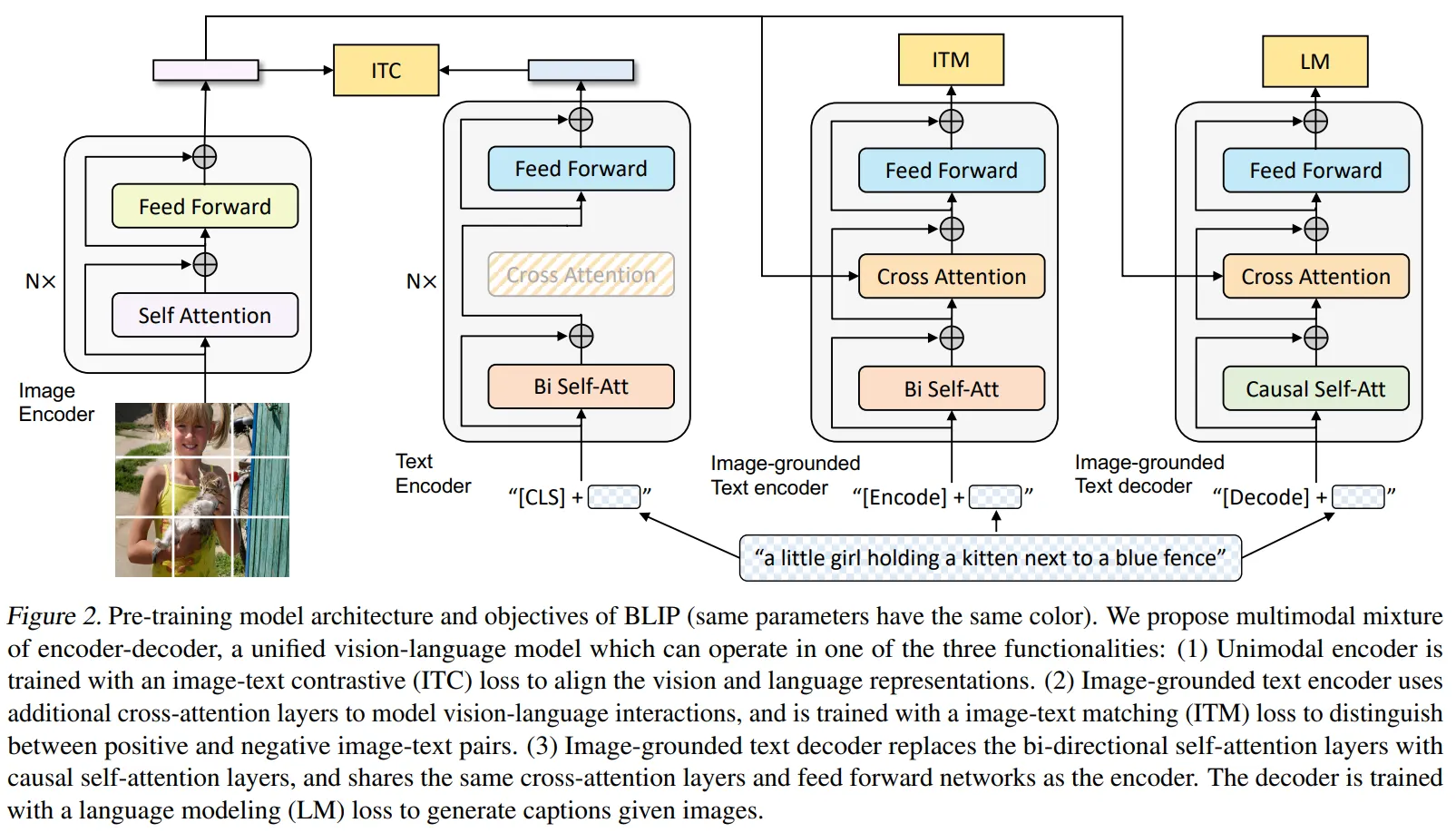
经过大规模多模态数据的预训练,ALBEF和BLIP在下游任务微调中均取得了十分亮眼的效果,在工业界也被广泛应用。
VLMO
ALBEF和BLIP之类的工作虽然能够同时兼顾对比和深度融合两种训练模式,但视觉和自然语言仍然需要单独的Encoder分别编码,这显然还不是我们所期望的真正的多模态统一模型框架。我们可以从Microsoft Research的VLMO、VL-BEIT与BEIT-3这一系列工作一窥这个方向的探索过程。
VLMo 是一种多模态 Transformer 模型,从名字可以看得出来它是一种 Mixture-of-Modality-Experts (MOME),即混合多模态专家。怎么理解呢?主流 VLP 模型分为两种,一种是双塔结构 (Dual Encoder),主要用来做多模态检索任务;一种是单塔结构 (Fusion Encoder),主要用来做多模态分类任务。VLMo 相当于是一个混合专家 Transformer 模型,预训练完成后,使用时既可以是双塔结构实现高效的图像文本检索,又可以是单塔结构成为分类任务的多模态编码器。
作者为 VLMo 量身定制了一种分阶段的预训练策略,这种策略除了图像-文本对之外,它可以有效地利用大规模仅图像和纯文本数据。
我们在前面提到,VLMo 相当于是一个混合专家 Transformer 模型。那既然是 Transformer 模型 (Mixture-of-Modality-Experts, MoME),就肯定还是需要遵循 Transformer 的一般设计思路,即:如下图所示, MoME Transformer 也是先一个 Multi-Head Self-Attention 的子模块,再串联一个 FFN 的子模块。但是和正常 Transformer 不同的是,这个 FFN 子模块是由3个并行,独立的 FFN 并联得到的。这3个 FFN 分别是 Vision-FFN,Language-FFN 和 Vision-Language-FFN,作者称它们分别为:视觉专家,文本专家和视觉文本专家。它们可以看成是3个专家模型,但是前面的 Multi-Head Self-Attention 都是共享权重的。
那设计成这样的好处是什么呢?就是这个 MoME Transformer 可以分情况选择不同的专家来使用。
- 当我们要做对比学习任务 (ITC) 的时候,如下图右上所示,VLMo 和 CLIP 很像,可以让视觉专家 V-FFN 输入视觉信息,让文本专家 L-FFN 输入文本信息,把得到的输出做对比学习即可。
- 当我们要做图文匹配任务 (ITM,二分类) 的时候,如下图右中所示,可以在前几个 Block 让视觉专家 V-FFN 输入视觉信息,让文本专家 L-FFN 输入文本信息,在后几个 Block 把信息给视觉文本专家,然后做二分类即可。
- 当我们要做完形填空任务 (MLM,预测任务) 的时候,如下图右下所示,可以在前几个 Block 让视觉专家 V-FFN 输入视觉信息,让文本专家 L-FFN 输入文本信息,在后几个 Block 把信息给视觉文本专家,然后做预测即可。
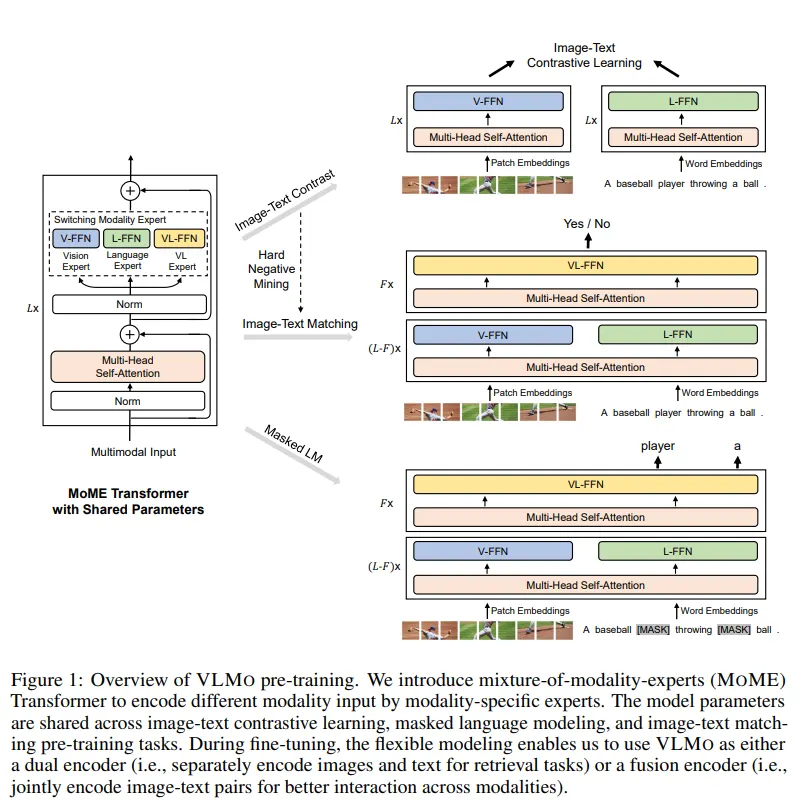
简答概括一下就是:如果输入是纯图像或者纯文本,就使用视觉专家和文本专家分别对输入的图像和文本进行编码。如果输入由多模态的向量组成,比如是图像和文本的拼接,就先使用视觉专家和文本专家分别对输入的图像和文本进行编码,再使用多模态专家进行联合地交互。VLMo 根据需求可以灵活地使用不同的专家模型,不论是架构层面还是训练层面都很灵活。
VL-BEIT
VL-BEIT 是 VLMo 的后续工作,它的技术方案建立在三种重要的视觉,文本方面的自监督学习算法之上。
- BERT:提出完形填空 (Masked Language Modeling, MLM) 技术自监督训练文本 Transformer 模型。
- BEIT:提出掩码图像建模 (Masked Image Modeling, MIM) 技术自监督训练视觉 Transformer 模型。
- VLMo:基于以上两种技术,基于视觉文本预训练 (Vision-Language Pretraining) 技术自监督训练多模态 Transformer 模型。
以上三种技术的共同特点可以概括为:都是基于掩码-预测的范式 (Mask-then-Predict Paradigm)。VLMo 在使用上面三种技术时是顺序进行的,即分3个阶段。意思就是先使用 BEIT 的 MIM 技术训练好视觉模型,再使用 BERT 的 MLM 技术训练好文本模型。在第3阶段训练多模态模型时,使用第1阶段训练好的视觉模型和第2阶段训练好的文本模型的初始化参数。
VL-BEIT 是在单个训练的阶段里面,通过一种统一的掩码-预测的任务直接完成多模态模型的训练,相比于之前的多个阶段训练更加地简单而有效。这个统一的任务就包含多种预训练的目标了:
- 首先就是 BEIT 的 MIM 技术,它依靠于大规模的纯视觉数据集 (单模态数据集)。
- 然后是 BERT 的 MLM 技术,它依靠于大规模的纯文本数据集 (单模态数据集)。
- 最后是 VLMo 的视觉-语言建模,它依靠于大规模的视觉文本数据集 (多模态数据集)。
那么如何让 VL-BEIT 模型既可以接受单模态数据集作为输入,又可以接受多模态数据集作为输入呢?作者这里还是遵循了 VLMo 的架构设计思路。这样做的好处是在预训练之后,VL-BEIT 模型可以微调为纯视觉模型,又可以微调为双塔多模态模型或者单塔多模态模型,以用于各种视觉和视觉语言下游任务。
VL-BEIT 的模型架构和 VLMo 一致,是一个混合专家 Transformer 模型 (Mixture-of-Modality-Experts, MoME)。
这样设计的好处是:MoME Transformer 可以分情况选择不同的专家来使用。
- 当我们要做纯视觉任务的时候,可以只让视觉专家 V-FFN 输入视觉信息,这样 VL-BEIT 就变成了纯视觉模型。
- 当我们要做纯文本任务的时候,可以只让文本专家 L-FFN 输入文本信息,这样 VL-BEIT 就变成了纯文本模型。
- 当我们要做多模态分类任务的时候,可以让视觉文本专家 VL-FFN 工作,这样 VL-BEIT 就变成了单塔多模态模型。
- 当我们要做多模态检索任务的时候,可以让视觉文本专家 VL-FFN 工作,这样 VL-BEIT 就变成了双塔多模态模型。
VL-BEIT 根据不同的需求可以让不同的专家模型工作,不论是架构层面还是训练层面都很灵活。
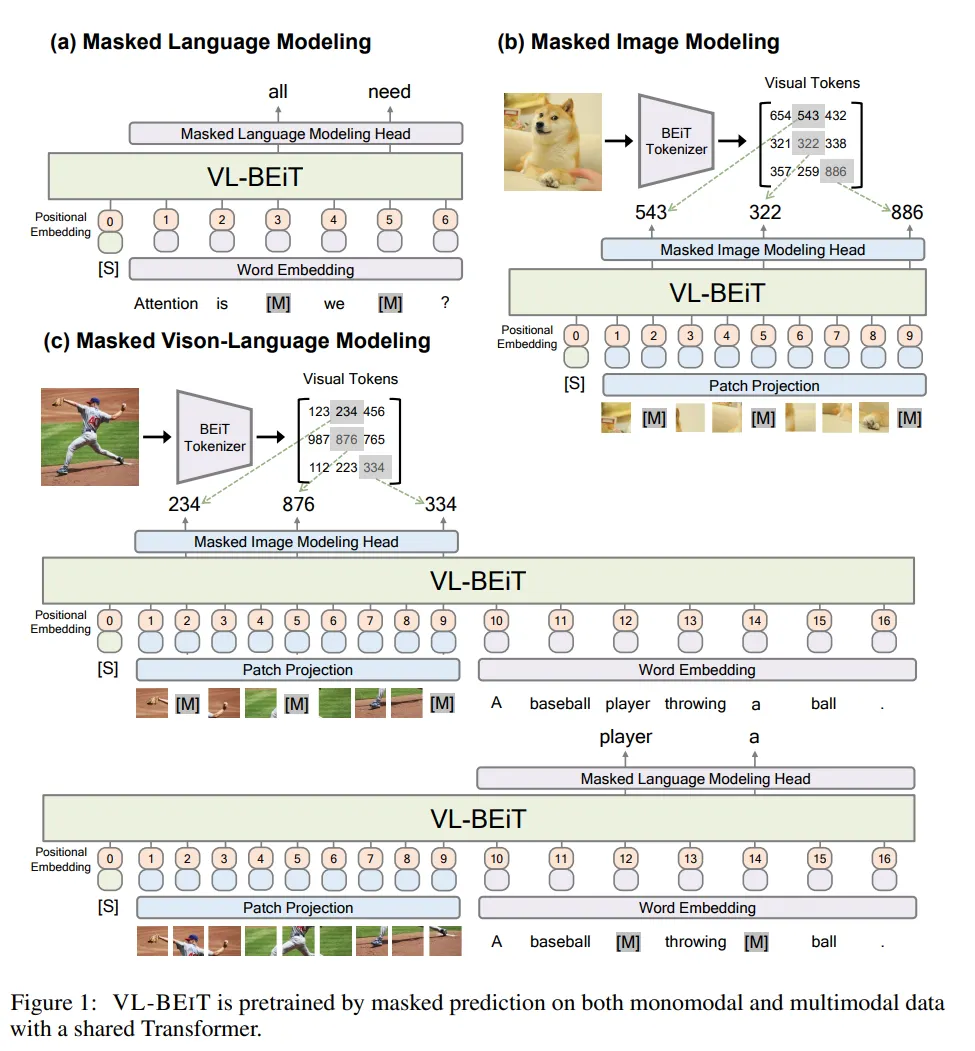
VL-BEIT 在预训练时同时使用了3个预训练任务,它们分别是:
掩码语言建模 (Masked Language Modeling, MLM)
使用掩码语言建模 (MLM) 从大规模纯文本数据中学习语言表征,如图 (a) 所示。遵循 BERT 的做法,随机选择文本序列中的一些 token,并用 [MASK] token 替换。每个 [MASK] token 有 80% 的概率正常使用 [MASK] token,有 10% 的概率保留原始 token,有 10% 的概率替换为随机 token。MLM 任务预训练的目标是从损坏的文本中去恢复这些被 mask 掉的 token。
掩码图像建模 (Masked Image Modeling, MIM)
使用掩码图像建模 (MIM) 从大规模图像数据中学习视觉表征,如图 (b) 所示。遵循 BEiT 的做法,随机选择图像序列中的 40% 的 patch,并用 [MASK] patch 替换。MIM 任务预训练的目标是从损坏的图片中去恢复这些被 mask 掉的 patch。作者使用 BEIT v2 的 image tokenizer 来获得离散的 token 作为重建目标。
掩码视觉语言建模 (Masked Vision-Language Modeling, MVLM)
把掩码图像建模的方法扩展到多模态数据。注意这个任务使用的数据集是成对的图片,文本对。这个任务的目标是根据图片和对应的文本线索,去恢复被 mask 的图像 patch 和文本 token,如图 (c) 所示。以 50% 的概率随机 mask 文本 token,根据图片和损坏的文本的联合表征来恢复 mask 的文本 token。同样随机 mask 图片 patch,根据损坏的图片和文本的联合表征来恢复 mask 的图片 patch。MVLM 任务鼓励模型去学习图片线索和文本信息之间的对齐。
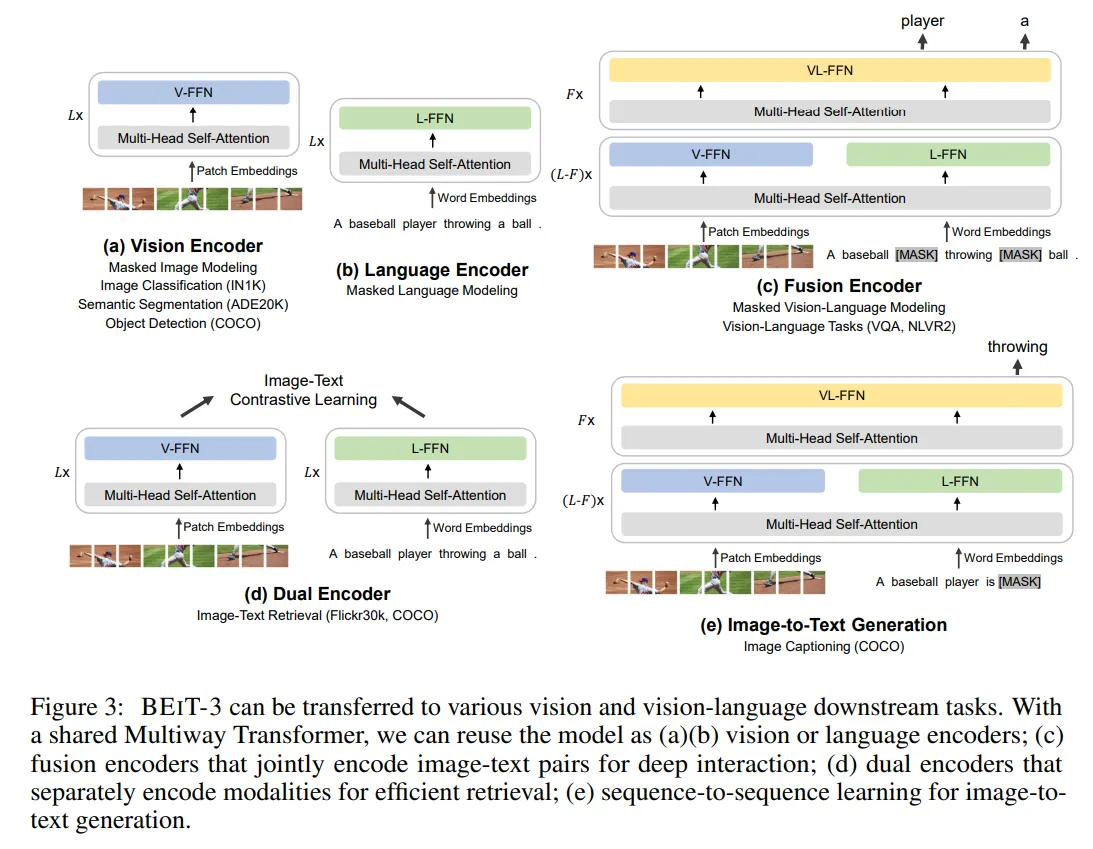
BEIT-3
这个工作的主要观点和思路就是 Abstract 的第一句话:A big convergence of language, vision, and multimodal pretraining is emerging,即视觉的表征,语言的表征和多模态的表征都在大一统。BEIT-3 就是对这种思想的集大成者,用出这种思想 (使用 Transformer 模型统一处理视觉和文本信息,使用 Mask Data Modeling 的训练策略统一建模视觉和文本信息)。
具体而言,作者从三个方面实现了大一统:模型架构 (VLMo 中使用的 Mixture-of-Modality-Experts, MoME,即 Multiway Transformer)、预训练任务 (Mask Data Modeling) 和模型缩放 (把模型放大)。
与VLMO网络结构类似,BEIT-3将图像、文本和图文多模态输入统一到一个单独的Multiway Transformer网络。不同于经典的Transformer,BEIT-3使用一个多类型输入共享的多头自注意力模块(Multi-Head Self-Attention),不同类型的模态输入各有一个全连接专家模块单独学习。如下图,视觉模态使用V-FFN、文本模态对应L-FFN,图文多模态输入对应VL-FFN,模型会根据不同类型的模态输入选择不同的模块生效。
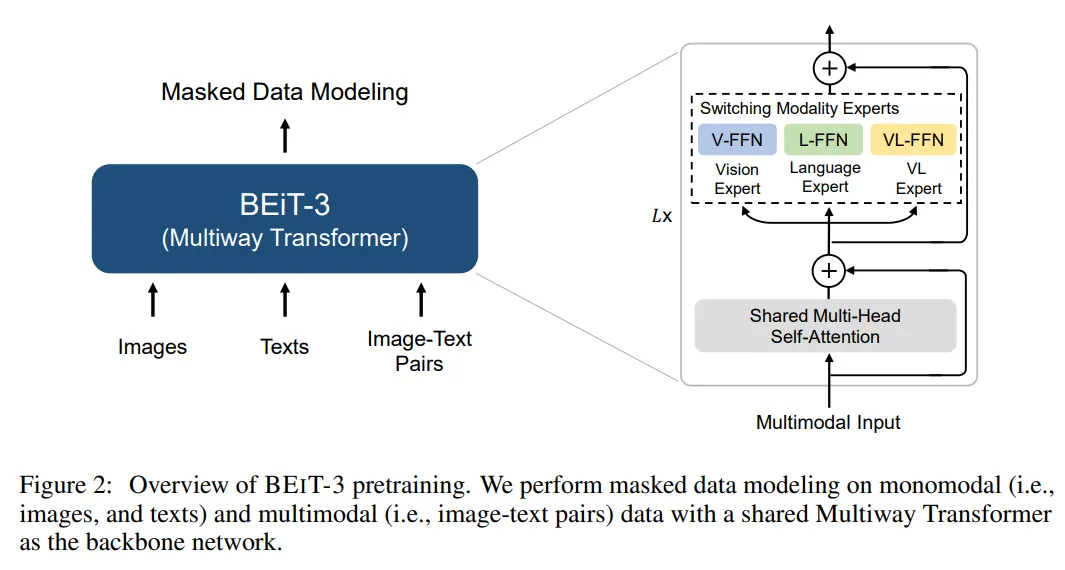
在预训练任务上,Mask Data Modeling 这个预训练的范式已经在文本 (以 BERT 为代表的 Mask Language Modeling) 和视觉 (以 BEIT 为代表的 Mask Image Modeling) 这两个领域都取得了成功。
BEIT-3 这个工作将 Mask Data Modeling 的训练范式扩展到了多模态领域,将图片 Image 视为一种外语 Imglish,和文本 English 一起采用 Mask Data Modeling 的做法进行训练。
当前的多模态模型的预训练方法还有使用图像-文本匹配 (Image-Text Matching Loss) 图像-文本对比学习 (Image-Text Contrastive Loss) 等等,但是相比之下还要平衡各个损失函数之间的权重,很麻烦。而 BEIT-3 就仅仅采用了 Mask Data Modeling 这一个目标函数。这个简单而有效的方法学习了强大的可转移表征,在视觉和语言任务上都实现了最先进的性能。
这种大一统的 mask-then-predict 任务不仅学习表征,而且学习不同模态之间的对齐。具体而言,文本数据是由 SentencePiece tokenizer 进行标记。图像数据由 BEIT v2 的 tokenizer 进行标记,以获得离散视觉标记作为重建的目标。作者从单模态文本中随机 mask 掉 15% 的文本,从图片-文本对中随机 mask 掉 50% 的文本。在 mask 图像时采用 BEIT 的做法 mask 掉 40%。
BEIT-3使用了更多的预训练数据,模型容量相对于之前的工作也有了显著的提高(达到1.9B),相应地最终也取得了在当时更好的效果。
BEIT-3将多模态对齐和预训练的研究推到了一个新的高度,验证了更多的数据+更大的模型取得更好的效果,在这个研究方向仍不失准。虽然开始饱受争议,但随着ChatGPT的问世,这个发展思路的正确性被进一步加深,也催生了后面多模态大模型的一众研究工作。
SigLip
这篇paper提出用sigmoid loss来做图文对比训练。这个方案既能降低训练成本,在小batch下(低于32k)performance也优于传统方法。
详情见: SigLIP系列
多模态与大模型
Flamingo
如今GPT-4代表着多模态大模型的顶尖水平,但在此之前,甚至在ChatGPT之前就已有相关探索工作,其中谷歌的Flamingo最具当前主流技术雏形。事实上,Flamingo更像是图文多模态领域的GPT-3,不同的是它支持图文上下文的输入,通过In-Context Few-Shot方式完成任务。Flamingo同样支持视频帧序列作为输入,通过Prompt指令完成Video理解任务。

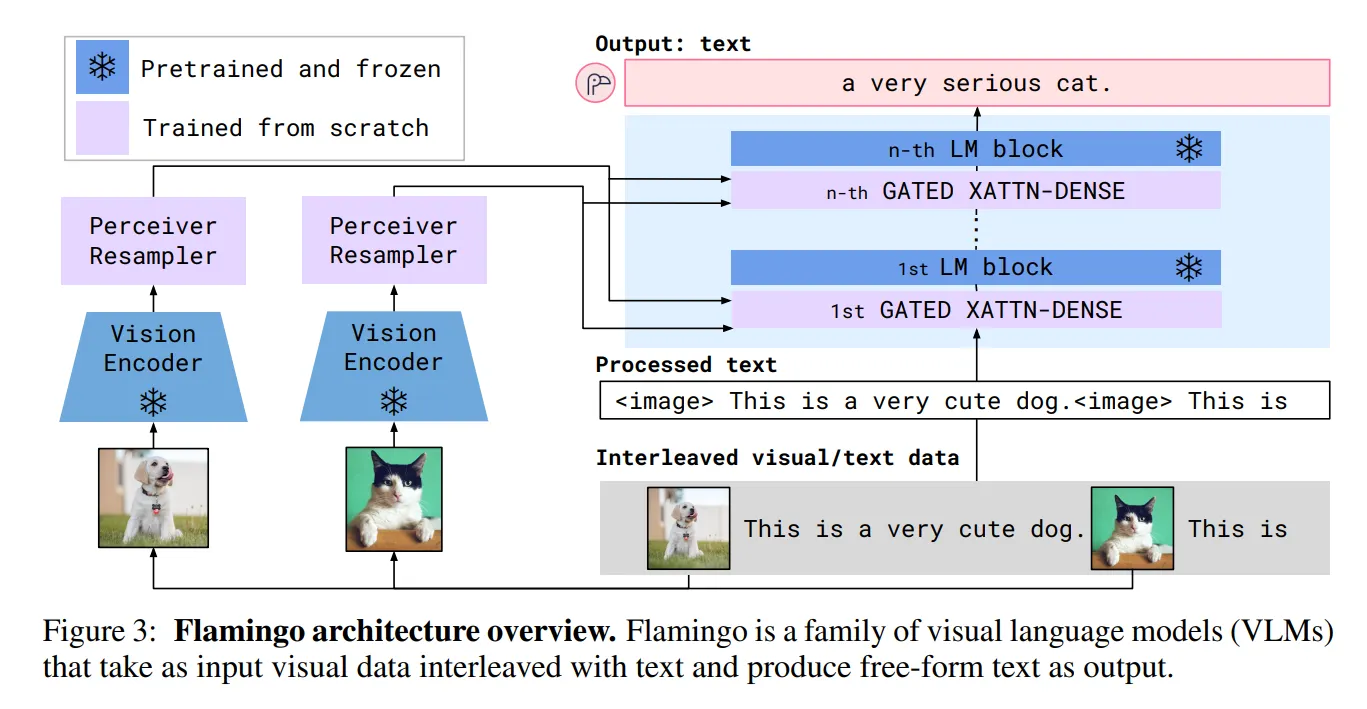
做到这种功能,在模型侧和GPT-3类似,不同的是Flamingo在文本Transfomer网络中增加视觉输入特征,模型结构如下图,包括三个部分。
- 视觉侧特征抽取使用预训练的ResNet和采样模块(Perceiver Resampler,将变长的视觉特征输入转成少量的视觉特征)模型;
- 文本侧模型使用LLM(基座使用Chinchilla,同样是谷歌发布的对标GPT-3的大语言模型,并提供了1.4B、7B、和70B等版本,分别对应Flamingo-3B、Flamingo-9B和Flamingo-80B);
- GATED XATTN-DENSE层,用于连接LLM 层与视觉特征,允许 LM 在处理文本时考虑视觉信息。通过交叉注意力,LM 可以关注与视觉特征相关的部分。预训练LLM和视觉ResNet参数训练过程中是冻结状态。
相应的,在数据层面Flamingo也是使用了多样形式的训练语聊,包括:
- 图文穿插形式:MultiModal MassiveWeb (M3W),43 Million;
- 图文Pair对形式:LTIP(Long Text & Image Pairs),312 Million;
- 带文本描述的短视频:VTP (Video & Text Pairs) ,27 Million 。
最后Flamingo在各种多模态任务上的效果也非常优秀,甚至在有些数据集上通过few-shot方式可以超过经典模型的SOTA。
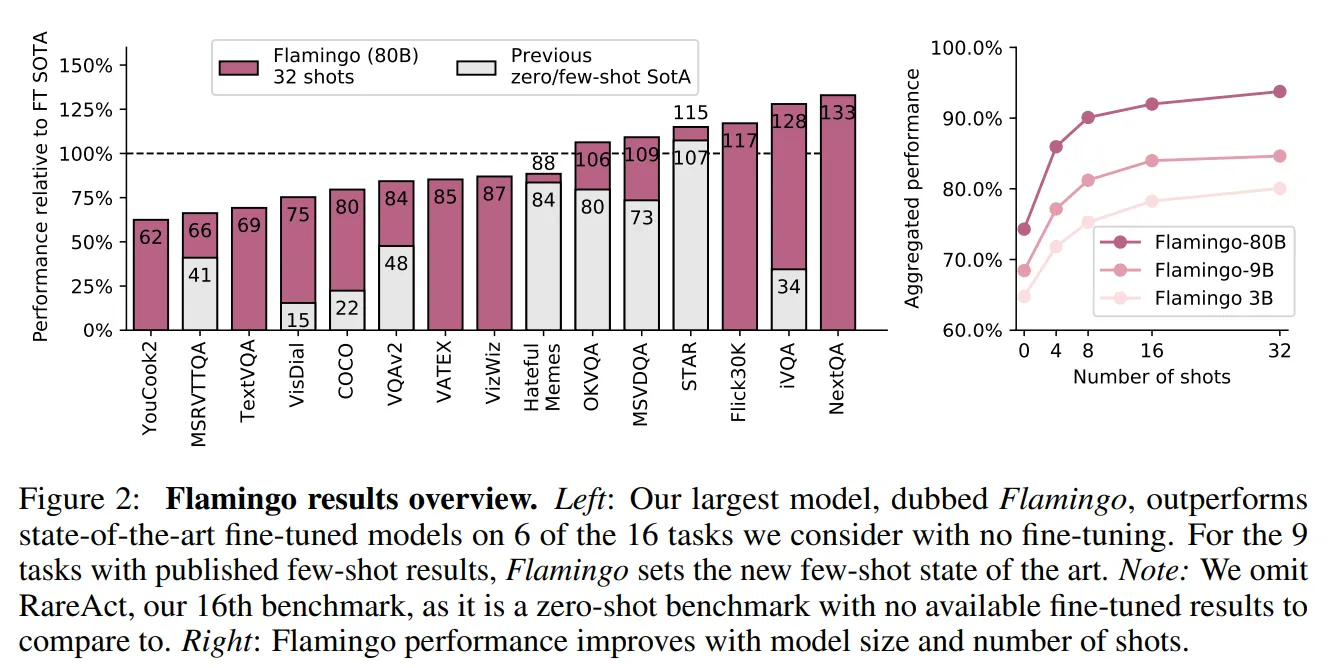
Flamingo凭借其出色的效果,吸引了许多研究者对于多模态大模型的注意,但当时这种规模的模型训练不是谁都能玩的起,因此并没有引起特别火热的跟风潮。直到ChatGPT的出现,让人逐渐接受了大模型这条道路的正确性,以前觉得自己玩不起的机构,砸锅卖铁拉投资也愿意投入,自此相关的开源研究开始如火如荼。
在众多开源工作中,BLIP-2以及与之一脉相承的InstructBLIP算是早期的探路者之一,我们可以从这两个工作开始讲起。
BLIP-2
BLIP-2的论文标题是Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models,核心思路是通过利用预训练好的视觉模型和语言模型来提升多模态效果和降低训练成本。
BLIP-2的网络结构和Flamingo十分类似。包括视觉编码层、视觉与文本的Adapter(Q-Former)以及大语言模型层。
- 视觉编码层:使用ViT模型,权重初始化通过CLIP预训练完成,并剔除最后一次提升输出特征的丰富性;训练过程中冻结权重,不更新;
- 文本侧的大语言模型层:早期的BLIP-2使用OPT/FlanT5来实验Decoder based和Encoder-Decoder based LLM的效果;这部分同样在训练过程中冻结权重,不更新;
- 图文Adapter层:Q-Former结构,类似BLIP网络(同样先进行了图文多模态预训练模块),通过Queries向量,提取视觉侧的关键信息输入到LLM;这部分是多模态大模型训练过程中的主要参数。
具体细节还是见:BLIP系列:统一理解和生成的自举多模态模型
InstructBLIP
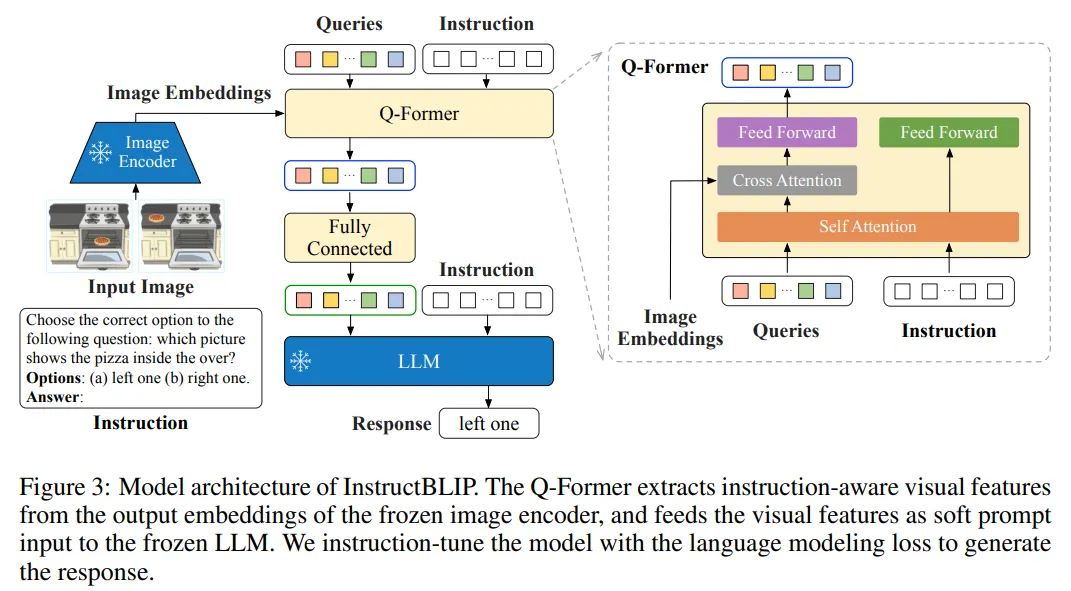
InstructBLIP 是 BLIP 作者团队在多模态领域的又一续作。现代的大语言模型在无监督预训练之后会经过进一步的指令微调 (Instruction-Tuning) 过程,但是这种范式在视觉语言模型上面探索得还比较少。InstructBLIP 这个工作介绍了如何把指令微调的范式做在 BLIP-2 模型上面。用指令微调方法的时候会额外有一条 instruction,如何借助这个 instruction 提取更有用的视觉特征是本文的亮点之一。InstructBLIP 的架构和 BLIP-2 相似,从预训练好的 BLIP-2 模型初始化,由图像编码器、LLM 和 Q-Former 组成。在指令微调期间只训练 Q-Former,冻结图像编码器和 LLM 的参数。作者将26个数据集转化成指令微调的格式,把它们分成13个 held-in 数据集用于指令微调,和13个 held-out 数据集用于 Zero-Shot 能力的评估。
如下图所示是 InstructBLIP 的模型架构,和 BLIP-2 保持一致,依然由视觉编码器,Q-Former 和 LLM 组成。视觉编码器提取输入图片的特征,并喂入 Q-Former 中。此外,Q-Former 的输入还包括可学习的 Queries (BLIP-2 的做法) 和 Instruction。Q-Former 的内部结构如图中黄色部分所示,其中可学习的 Queries 通过 Self-Attention 和 Instruction 交互,可学习的 Queries 通过 Cross-Attention 和输入图片的特征交互,鼓励提取与任务相关的图像特征。
Q-Former 的输出通过一个 FC 层送入 LLM,Q-Former 的预训练过程遵循 BLIP-2 的两步:
- 不用 LLM,固定视觉编码器的参数预训练 Q-Former 的参数,训练目标是视觉语言建模。
- 固定 LLM 的参数,训练 Q-Former 的参数,训练目标是文本生成。
对应的,InstructBLIP的另一个不同是训练数据也使用指令形式,将各种类型任务的开源学术数据,使用模板构造成指令多模态数据。数据模板如下。

更多多模大模型的内容,可以详见:
更多模态
ImgaeBind
由于嵌入特征的模态局限性:
- 只使用一对嵌入 (比如视觉和文本),或者较少的几对嵌入。
- 学习到的嵌入仅限于用于训练的模态对。比如,视频音频嵌入不能直接用于图像文本任务。
ImageBind 提出了一种通过利用多种模态 (text, audio, depth, IMU) 与 image 的配对数据来学习共享的表征空间的方法。它不需要所有模态彼此同时出现的数据集,比如不需要配对的 image + text + audio + depth + IMU 数据。而是只需要与 image/video 配对的数据即可,比如,image + text,image + audio 这样的数据集。这就大大减小了对数据集质量的要求。
因此,本文方法取名 ImageBind ,意思是通过 image/video 这种模态,来 "绑定" 其他多种模态的数据。这允许 ImageBind 将文本嵌入隐式对齐到其他模态,例如音频、深度等,从而在该模态上实现零样本识别能力,而无需显式语义或文本配对。而且,作者表明 ImageBind 可以使用 CLIP 等大规模视觉语言模型进行初始化,从而利用这些模型丰富的图像和文本表示。因此,ImageBind 可以在只进行少量训练的情况下轻松应用于多种模态任务。
ImageBind 使用的数据集不仅有图像-文本对,还包括了4种新的模态:audio, depth, thermal, 和 Inertial Measurement Unit (IMU),并在每种模态的任务上面都表现出了强大的 Emergent Zero-Shot 分类和检索性能。
ImageBind 的联合嵌入表征可以用于各种组合任务,如下图所示,包括
- 跨模态检索:快速对齐音频,深度图和文本信息。
- 给一个嵌入增加来自不同模态的另一个嵌入可以自然地增加语音信息。
- 音频到图像的生成,通过预训练的 DALLE-2 解码器,旨在与 CLIP 的文本嵌入一起工作

ImageBind 假设图像模态数据为 \(𝐼\),其他模态的数据为 \(𝑀\)。考虑一个数据对 \((𝐼,𝑀)\),给定一个图像\(𝐼_𝑖\) 及其在另一种模态 \(𝑀_𝑖\),首先将它们编码为归一化的嵌入 \(𝑞_𝑖=𝑓(𝐼_𝑖)\) 和 \(𝑘_𝑖=𝑓(𝑀_𝑖)\),其中 \(𝑓,𝑔\)是深度神经网络。然后使用 InfoNCE损失函数优化下面的目标:
作者对 images, text, audio, thermal images, depth images, 和 IMU 使用单独的编码器,在每个编码器上添加特定于模态的线性投影头来获得固定大小的\(d\) 维嵌入,该嵌入被归一化并用于式1的 InfoNCE 损失函数。除了易于学习之外,这种设置还允许使用预训练的 CLIP 或 OpenCLIP 的图像和文本编码器。
Meta-Transformer
Meta-Transformer 探索了 Transformer 架构处理12种模态的潜力,包括图像 (images)、自然语言 (natural language)、点云 (point cloud)、音频谱图 (audio spectrogram)、视频 (video)、红外 (infrared)、高光谱 (hyperspectral)、X射线 (X-Ray)、IMU、表格 (tabular)、图 (graph) 和时间序列 (time-series) 数据,如图所示。
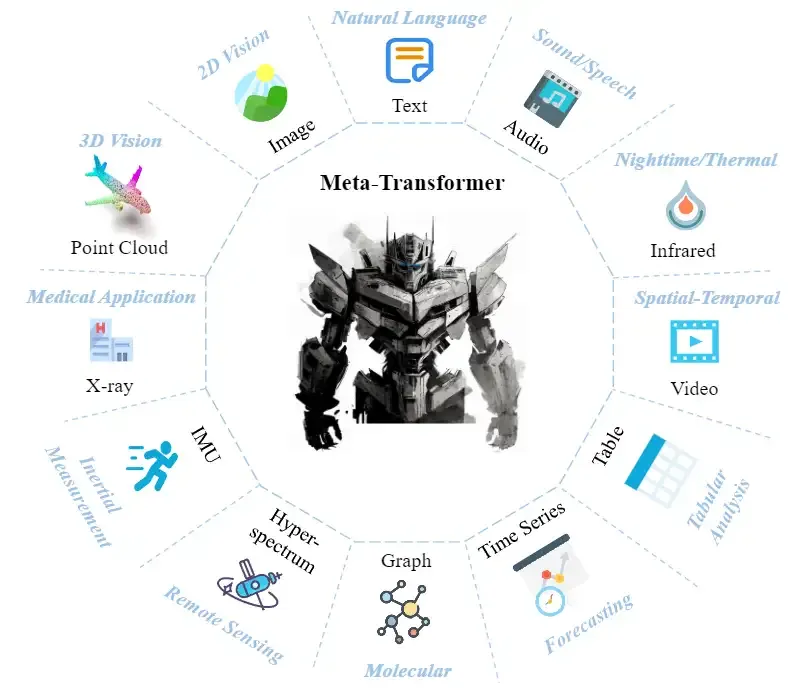
Meta-Transformer 是第一个使用一套参数来同时编码来自12个模态数据的框架。Meta-Transformer 主要由3部分组成:模态专家 (modality-specialist),数据序列化器 (data-to-sequence tokenization),和模态共享的编码器 (modality-shared encoder) 和特定任务的头 (task-specific heads)。Meta-Transformer 的具体做法在下面集结分别介绍。
如下图所示是 Meta-Transformer 的架构图。
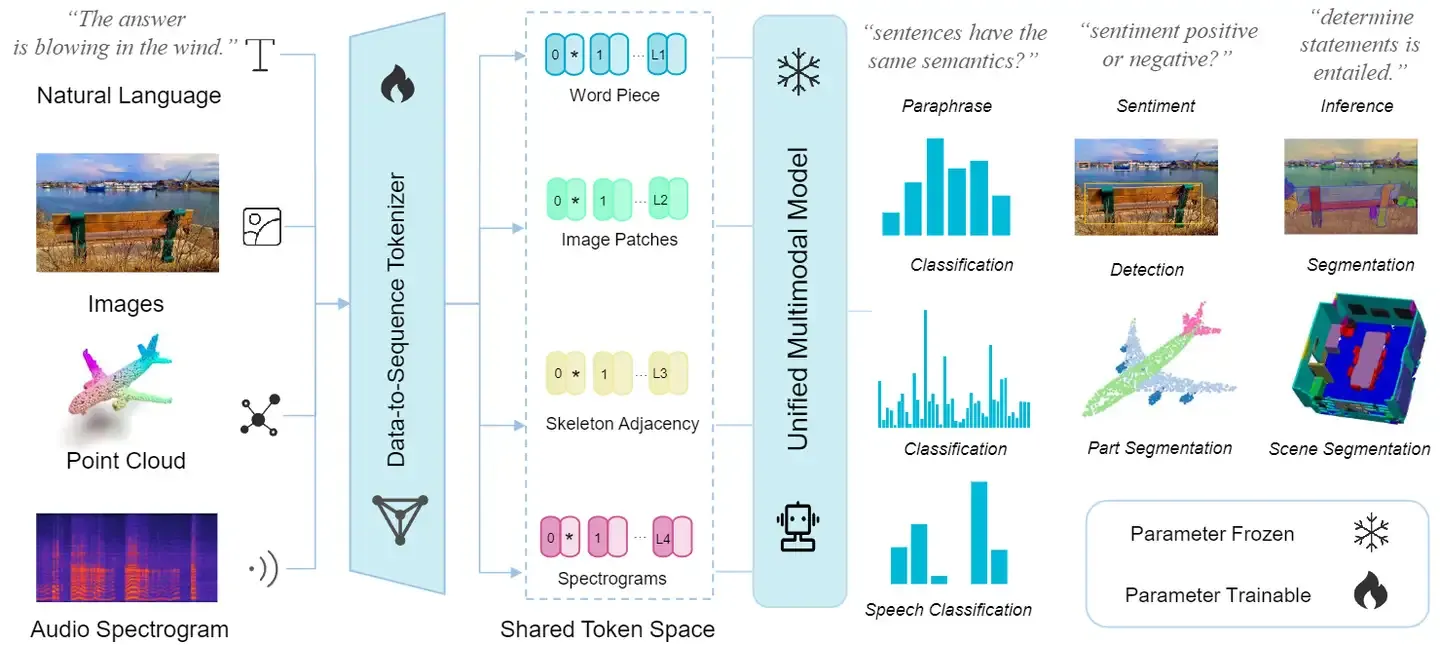
假定 𝑛 个模态的数据和对应的标签分别是: \(\{\mathcal{X}_1, \mathcal{X}_2, \cdots, \mathcal{X}_n\}\) 和 \(\{\mathcal{Y}_1, \mathcal{Y}_2, \cdots, \mathcal{Y}_n\}\),作者假定对于每种模态都有一个参数空间 \(\Theta_i\),可以用来处理该模态的数据。Meta-Transformer 希望找到一个共享的参数空间 \(𝜃^∗\) 使其满足:
并且假定满足:
多模态神经网络可以表述为一个统一的映射函数 \(\mathcal{F}: \boldsymbol{x}\in \mathcal{X} \rightarrow \hat{y} \in \mathcal{Y}\),满足:
就是对所有模态的数据,优化模型参数\(𝐹\),使得模型的预测值和真实值尽量接近。
在通过 Transformer Encoder 得到表征之后,作者进一步把它们送到特定任务的 head 中。它们主要由 MLP 构成,并且因模式和任务而异,Meta-Transformer 的学习目标可以概括表达为:
式中,\(f(\cdot), g(\cdot), h(\cdot)\) 分别表示 tokenizer,Encoder 和 head。