背景:大模型 vs. GPU Memory
大模型最大的特点是模型参数多,训练时需要很大的GPU显存。举个例子,帮助大家的理解:对于一个常见的7B规模参数的大模型(如LLaMA-2 7B),基于16-bit混合精度训练时,在仅考虑模型参数、梯度、优化器情况下,显存占用就有112GB,显然目前A100、H100这样主流的显卡单张是放不下的,更别提国内中小厂喜欢用的A6000/5000、甚至消费级显卡。
上面的例子中,参数占GPU 显存近 14GB(每个参数2字节)。再考虑到训练时 梯度的存储占14GB(每个参数对应一个梯度,也是2字节)、优化器Optimizer假设是用目前主流的AdamW则是84GB(每个参数对应一个参数的copy、一个momentum和一个variance,这三个都是float32),合计112GB。

这种情况,Torch中支持的大家熟悉的数据并行DataParallel是解决不了的。因为数据并行的前提是每个GPU可以host完整的模型。需要用到模型并行和流水线并行。下面对着三种方法做一个简单介绍。
三种模型训练的并行方案
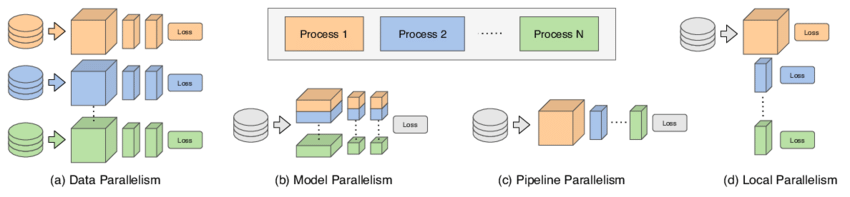
数据并行(Data Parallelism)
数据并行是一种常用的并行技术(一般的CV模型都是这种用法),它将训练数据集分割成多个micro-batch,并在多个GPU上同时处理这些micro-batch。在数据并行中,每个GPU都有一个模型的完整副本。关键步骤包括:
- 数据分割:训练数据被分割成多个小批次(例如在PyTorch中通过torch.nn.DataParallel实现)。
- 并行处理:每个处理器同时处理不同的数据批次。
- 梯度汇总和同步:每个处理器完成一次前向和反向传播后,梯度被汇总并在所有处理器间同步,以更新模型的参数。
模型并行(Model Parallelism)
模型并行涉及将一个模型的Layer/tensor分割成多个部分,并在不同的处理器上并行处理这些部分。模型并行的关键步骤包括:
- 模型分割:将模型的不同部分(例如,不同的层或子网络)分配给不同的处理器。
- 分部处理:每个处理器处理分配给它的模型部分。
- 交叉通信:处理器间必须进行数据交换,以便完成前向和反向传播。
流水线并行(Pipeline Parallelism)
流水线并行是一种在模型的不同阶段之间划分工作的策略,类似于工业生产中的装配线。在流水线并行中,模型被分割成几个阶段,每个阶段在不同的处理器上执行。关键步骤包括:
- 阶段划分:模型被分割成几个连续的阶段。
- 流水线处理:每个阶段独立处理其输入数据,然后将其输出传递给下一个阶段。
- 效率优化:为了最大限度地提高效率,需要仔细安排每个阶段的执行,以减少处理器的空闲时间。
从上图可以看到,模型并行和流水行的并行实现相对复杂, 需要实现相对复杂的模型拆分、卡间通讯等。以及在这些并行手段下,如果极致的优化显存占用,是非常关键的。这也是DeepSpeed被设计的初衷。
DeepSpeed
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
DeepSpeed项目最初就是论文中ZeRO方法的官方实现。
如今的DeepSpeed除了训练之后,还在推理、压缩、Science几个模块做了很多的工作,本文主要关注它在训练中的优化。

我们看看DeepSpeed Training的官方介绍:
DeepSpeed 提供了系统创新的融合,使大规模深度学习训练变得有效、高效,大大提高了易用性,并在可能的规模方面重新定义了深度学习训练格局。 ZeRO、3D-Parallelism、DeepSpeed-MoE、ZeRO-Infinity 等创新属于培训支柱。
可以看到ZeRO技术是非常核心的创新,排在首位。
DeepSpeed ZeRO的核心特点包括:
- 内存优化:通过创新的内存优化技术,DeepSpeed ZeRO能够显著减少大规模模型训练所需的GPU内存。这使得研究人员和开发人员能够在现有硬件上训练更大、更复杂的模型。
- 数据并行性:DeepSpeed ZeRO通过高效的数据并行方法提高了大规模模型训练的效率。它可以跨多个GPU和多个节点分布式地训练模型,从而提高训练速度和扩展性。
- 模型并行性:除了数据并行性之外,DeepSpeed ZeRO还支持模型并行性,允许模型的不同部分在不同的GPU上运行。这进一步增加了训练大型模型的灵活性和效率。
- 通信效率:DeepSpeed ZeRO优化了分布式训练中的通信机制,减少了节点间同步模型参数时的网络负载。这使得它在大规模分布式环境下更为高效。
- 易于使用:DeepSpeed ZeRO旨在与现有的深度学习框架(如PyTorch)无缝集成,使其易于使用和部署。
- 支持超大规模模型:DeepSpeed ZeRO被设计来支持非常大的模型,如数十亿甚至数千亿参数的模型,这对于传统训练方法来说是不可能的。
使用上,包括三个阶段:
- Stage 1:优化器状态(例如,对于 Adam 优化器、FP32的权重 及first, second moment estimates)在进程间(不同GPU)Split,以便每个进程仅更新其分区。
- Stage 2:用于更新模型权重的梯度(gradients)也被Split,以便每个进程仅保留与其优化器状态部分相对应的梯度。
- Stage 3:16 位模型参数(params)在进程之间被Split。 ZeRO-3会在前向和后向传递过程中自动收集和划分它们。
DeepSpeed ZeRO优化理论
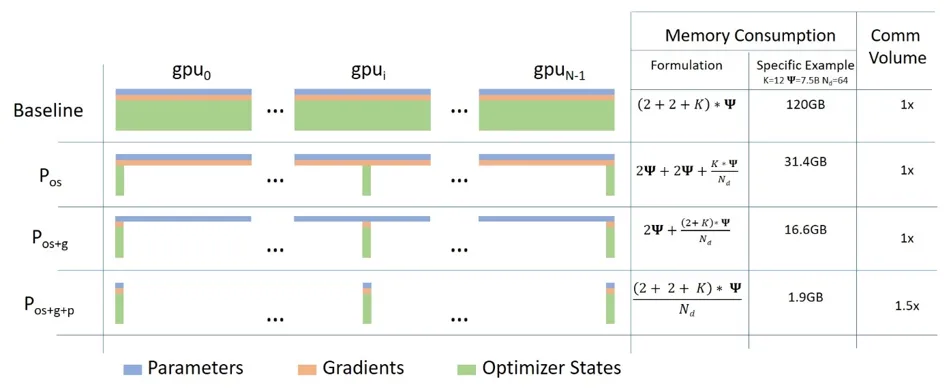
下面这张图是论文中的,一图胜千言。一共四种情况,其中 \(\Phi\) 是模型参数,其中 \(𝑁_𝑑\) 是GPU卡数:
- Baseline是没有ZeRO优化时的GPU消耗,显存消耗 \((2+2+K)* Φ\),
- \(P_{OS}\)是ZeRO Stage 1 ,对优化器状态都进行分片,占用内存为原始的1/4,通信容量与数据并行性相同,单卡显存消耗 \(2Φ+2Φ + \frac{K*Φ}{N_d}\)
- \(P_{OS+g}\)是ZeRO Stage 2,对优化器状态和梯度都进行分片,占用内存为原始的1/8,通信容量与数据并行性相同,单卡显存消耗 \(2\Phi + \frac{(2+K)\cdotΦ}{N_d}\)
- \(P_{OS+g+p}\)是ZeRO Stage 3,对优化器状态、梯度以及模型参数都进行分片,内存减少与数据并行度和复杂度成线性关系,同时通信容量是数据并行性的1.5倍:单卡显存消耗 \(\frac{(2+2+K)*Φ}{N_d}\)
从上面的公式可以看出来,关键点是 $𝑁_𝑑 $ 要大(也就是卡要多 ),当模型为7.5B,有64张GPU卡时,不同ZeRO Stage对显存的占用如下:
GPU卡间通讯的代价
当然,硬币都是有两面的,凡事也都有利弊。
DeepSpeed之所以这么大幅度的降低单卡显存的开销,背后思想是分布式计算的思路,需要用到什么的时候,临时去其他GPU显存中获取。这里就涉及到GPU通讯的reduce、gather等操作。
下面我们就分析下通信数据量,先说结论, \(P_{os}\) 和 $P_{os+g} $ 的通信量和传统数据并行相同, \(P_{os+g+p}\)会增加通信量。
传统数据数据并行在每一步(step/iteration)计算梯度后,需要进行一次AllReduce操作来计算梯度均值,目前常用的是Ring AllReduce,分为ReduceScatter和AllGather两步,每张卡的通信数据量(发送+接受)近似为 \(2Φ\)。
我们直接分析 $P_{os+g} $ ,每张卡只存储 \(\frac{1}{N}\) 的优化器状态和梯度,对于 gpu0 来说,为了计算它这 \(\frac{1}{N}\)梯度的均值,需要进行一次Reduce操作,通信数据量是 \(\frac{1}{N}Φ⋅N=Φ\),然后其余显卡则不需要保存这部分梯度值了。实现中使用了bucket策略,保证 \(\frac{1}{N}\) 的梯度只发送一次。
这里还要注意一点,假如模型最后两层的梯度落在 gpu0,为了节省显存,其他卡将这两层梯度删除,怎么计算倒数第三层的梯度呢?还是因为用了bucket,其他卡可以将梯度发送和计算倒数第三层梯度同时进行,当二者都结束,就可以放心将后两层梯度删除了。
当 gpu0 计算好梯度均值后,就可以更新局部的优化器状态了,当反向传播过程结束,进行一次Gather操作,更新模型参数,通信数据量是 \(\frac{1}{N}Φ⋅N=Φ\) 。
从全局来看,相当于用Reduce-Scatter和AllGather两步,和数据并行一致。
\(P_{os+g+p}\) 使得每张卡只存了 \(\frac{1}{N}\) 的参数,不管是在前向计算还是反向传播,都涉及一次Broadcast操作。
除了上述的ZeRO显存优化之外,还集成了ZeRO-Offload这样的方法
ZeRO-Offload
ZeRO-Offload: Democratizing Billion-Scale Model Training 发表在ATC 21,一作是来自UC Merced的Jie Ren,博士期间的研究方向是 Memory Management on Heterogeneous Memory Systems for Machine Learning and HPC. 所以看到这个题目也就不奇怪了。
一张卡训不了大模型,根因是显存不足,ZeRO-Offload的想法很简单:显存不足,内存来补。
直接看下效果,在单张V100的情况下,用PyTorch能训练1.4B的模型,吞吐量是30TFLOPS,有了ZeRO-Offload加持,可以训练10B的模型,并且吞吐量40TFLOPS。这么好的效果能不能扩展到多卡上面呢,能啊,比如只用一台DGX-2服务器,可以训练70B的模型,是原来只用模型并行的4.5倍,在128张显卡的实验上基本也是线性加速,此外还可以与模型并行配合,快乐加倍:)
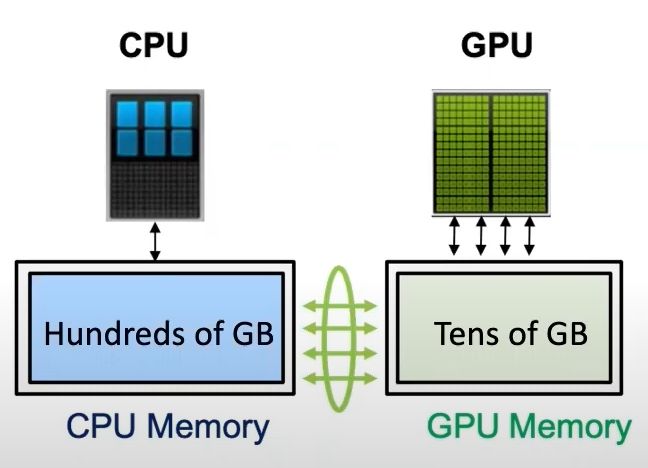
相比于昂贵的显存,内存廉价多了,能不能在模型训练过程中结合内存呢?其实已经有很多工作了,但是他们几乎只聚焦在内存上面,没有用到CPU计算,更没有考虑多卡的场景。ZeRO-Offload则将训练阶段的某些模型状态下放(offload)到内存以及CPU计算。
注:ZeRO-Offload没有涉及剩余状态(比如激活值)的下放,因为在Transformer LM场景中,他比模型状态占用的显存小。
ZeRO-Offload要做的事情我们清楚了,那么如何设计高效的offload策略呢?
Offload策略
ZeRO-Offload并不希望为了最小化显存占用而让系统的计算效率下降,否则的话,我们只用CPU和内存不就得了。但是将部分GPU的计算和存储下放到CPU和内存,必然涉及CPU和GPU之间的通信增加,不能让通信成为瓶颈,此外GPU的计算效率相比于CPU也是数量级上的优势,也不能让CPU参与过多计算,避免成为系统瓶颈,只有前两条满足的前提下,再考虑最小化显存的占用。
为了找到最优的offload策略,作者将模型训练过程看作数据流图(data-flow graph)。
- 圆形节点表示模型状态,比如参数、梯度和优化器状态
- 矩形节点表示计算操作,比如前向计算、后向计算和参数更新
- 边表示数据流向
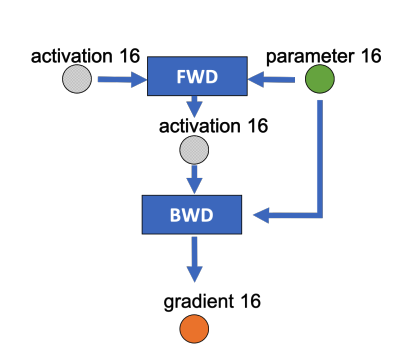
下图是某一层的一次迭代过程(iteration/step),使用了混合精读训练,前向计算(FWD)需要用到上一次的激活值(activation)和本层的参数(parameter),反向传播(BWD)也需要用到激活值和参数计算梯度,