Qwen-VL
模型框架
Qwen-VL的整体网络架构由三个组件组成:
- LLM:使用 Qwen-7B 的预训练权重进行初始化。
- 视觉编码器:Qwen-VL 的可视化编码器使用ViT 架构,使用 Openclip 的 ViT-bigG 的预训练权重进行初始化。在训练和推理过程中,输入图像的大小都会调整为特定分辨率。视觉编码器通过以 14 步幅将图像分割成块来处理图像,生成一组图像特征。
- 位置感知视觉语言适配器:为了缓解长图像特征序列带来的效率问题,Qwen-VL 引入了一种视觉语言适配器来压缩图像特征。类似QFormer,该适配器包括一个随机初始化的单层交叉注意力模块。使用一组可训练向量(嵌入)作为query,并将视觉编码器中的图像特征作为交叉注意力作的key。该机制将视觉特征序列压缩到固定长度 256。
图像输入
图像不会直接以像素形式喂给语言模型(LLM)。
典型流程是:
- Visual Encoder:把图片编码成一串视觉特征(embedding/feature sequence)。
- Adapter:把视觉特征映射到语言模型可接入的表征空间/维度。
最终得到:固定长度(fixed-length)的图像特征序列。意味着:无论原图分辨率如何,输出给 LLM 的视觉 token 数是固定的(由模型设计决定)。
在使用到语言模型时,使用特殊 token 标记图像内容边界,为了让模型明确“这段序列是图像特征,不是文本 token”,在图像特征序列的两端加边界标记:
- 开始 token:
<img> - 结束 token:
</img>
因此,在多模态输入中,可以把图像部分抽象成:
<img> [image_feature_1 ... image_feature_N] </img>bbox输入
Qwen-VL 为了提升细粒度视觉理解与grounding能力,引入了对应的训练数据形态与序列化方式。
训练数据包含:
- region descriptions(区域描述)
- questions(问题)
- detections(检测结果/框信息)
模型不是新增一套“框坐标词表/位置词表”,而是把坐标直接写成文本字符串,让 LLM 像读普通文本一样读它。
对任意 bounding box,先做一个归一化过程,使坐标落在范围:\([0, 1000)\)。这意味着:把原图像素坐标按宽高缩放到 0~999 的整数网格(论文这里没展开实现细节,但语义是“统一尺度,便于学习与生成”)。
归一化后的框用如下固定格式表达:"(Xtopleft, Ytopleft), (Xbottomright, Ybottomright)", 并且因为坐标字符串长得很像普通文本(括号、逗号、数字),为了避免模型混淆,引入了特殊的bbox边界特殊token:
<box>:框字符串开始</box>:框字符串结束
于是一个框在序列里像这样:
<box> (Xtopleft, Ytopleft), (Xbottomright, Ybottomright) </box>仅有框坐标还不够,训练时还需要让模型知道:哪些词/句子是在描述这个框指向的区域
因此引入:
<ref>:引用/指代开始</ref>:引用/指代结束
用于标记被框所指代的内容
模型训练
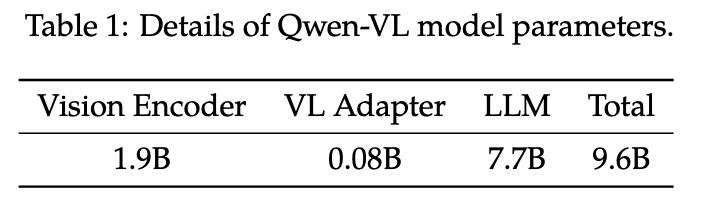
如下图所示,qwen-vl的训练包含三个阶段:Pretraining、Multi-task Pretraining和SFT
Pre-training
- 对于第一个阶段的预训练,训练时冻结LLM,只训练视觉编码器和适配器;
- 输入图像的大小将调整为 224 × 224;
- 训练数据经过对5b原始数据的清洗,一共包含1.4b图像文字对,训练数据如下图所示
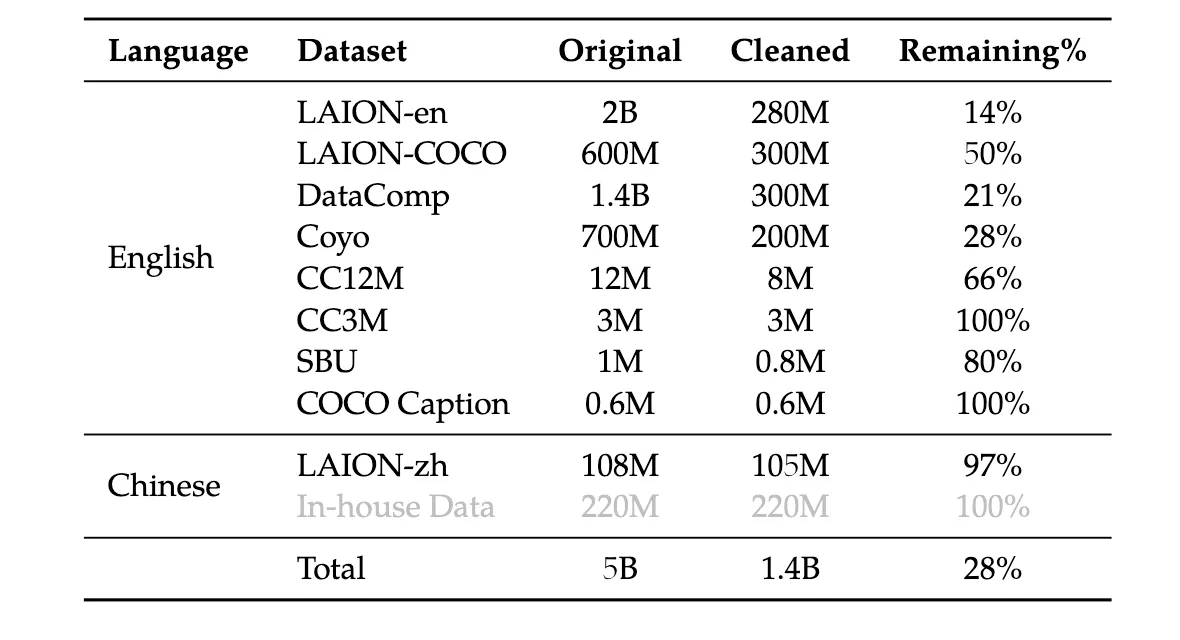
- 数据清洗的流程:
- 删除图像纵横比过大的数据对
- 删除图像太小的数据对
- 删除具有苛刻 CLIP 分数的配对(特定于数据集)
- 删除包含非英语或非中文字符的文本对
- 删除包含表情符号字符的文本对
- 删除文本长度太短或太长的对
- 清理文本的 HTML 标记
- 使用某些不规则模式清理文本
Multi-task Pre-training
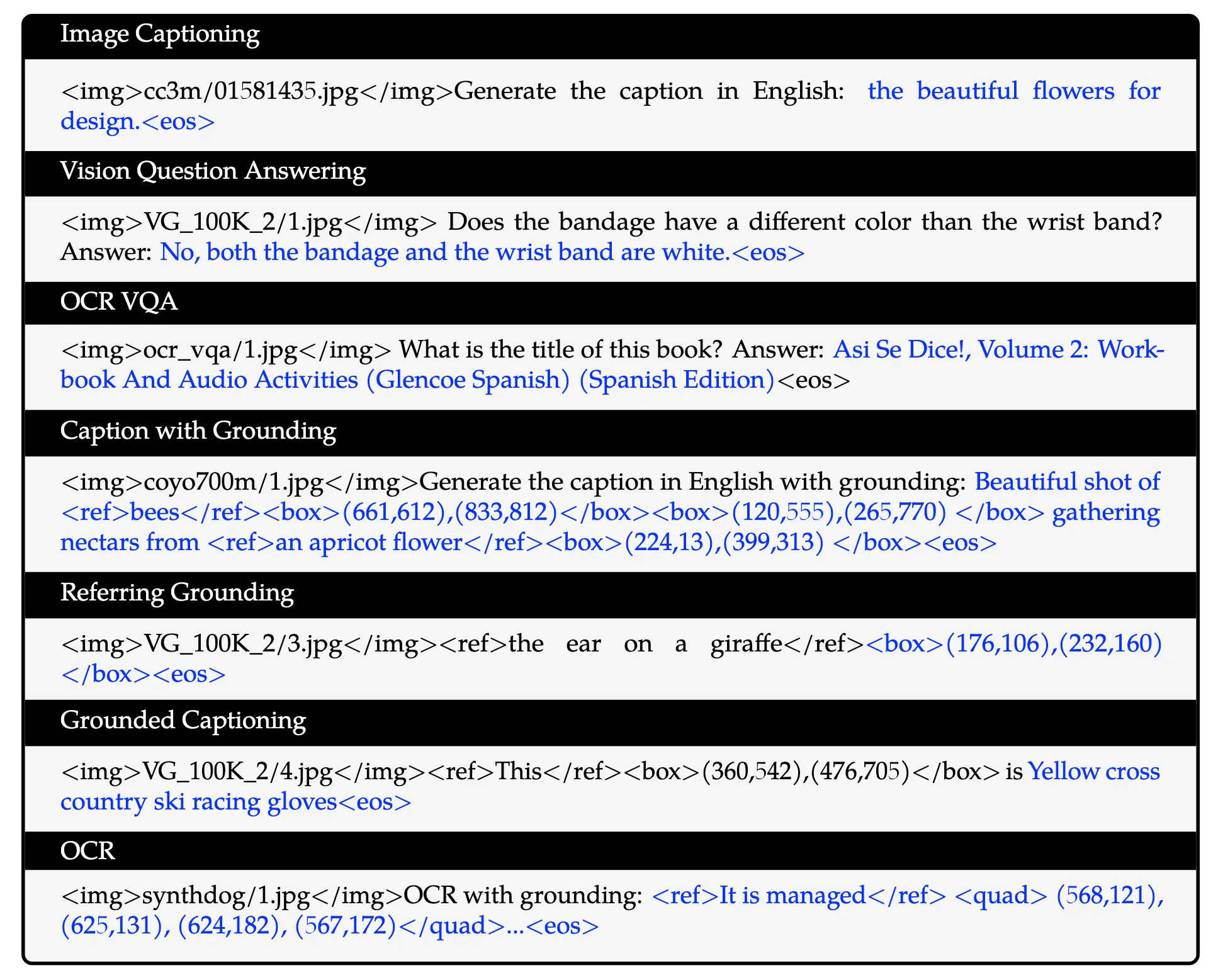
- 在多任务预训练的第二阶段,作者引入了具有更大输入分辨率的高质量、细粒度的VL标注数据和交错的图文数据。如下表所示,同时训练 Qwen-VL 执行 7 个任务。对于文本生成,使用内部收集的语料库来维护 LLM 的能力。caption数据与pretrain 相同,只是样本少得多且不包括 LAION-COCO

- 将视觉编码器的输入分辨率从 \(224×224\) 提高到 \(448×448\),减少了图像下采样造成的信息损失;
- 该阶段解冻了LLM并训练了整个模型。训练目标与预训练阶段相同;
- 该阶段对应的训练数据组织如下图所示,包含所有 7 个任务,其中黑色文本作为前缀序列,不做los,只对蓝色部分的文本做loss。
SFT
在此阶段,通过指令微调对Qwen-VL预训练模型进行了微调,以增强其指令跟随和对话能力,从而产生了交互式Qwen-VL-Chat模型。
- 多模态指令调优数据主要来自caption数据或通过LLM指令生成的对话数据,通常只针对单图对话和推理,仅限于图像内容理解。
- 作者通过手动标注、模型生成和策略串联来构建一组额外的对话数据,将定位和多图像理解能力融入Qwen-VL模型中。
- 在训练过程中混合了多模态和纯文本对话数据,以确保模型在对话能力上的通用性。指令调优数据一共有 350k。
- 在这个阶段,冻结了视觉编码器,只去训练LLM和适配器模块。
- 此阶段的数据格式如下图所示,为了更好地适应多图像对话和多个图像输入,在不同图像之前添加字符串“Picture id:”,其中 id 对应图像输入对话的顺序。在对话格式方面,使用了 ChatML(Openai)格式构建了指令调优数据集,其中每个交互的语句都标有两个特殊的标记(
<im_start>和<im_end>),以方便对话终止。

在训练过程中,仅监督answer部分和特殊标记(示例中的蓝色),而不监督角色名称或question提示来确保预测和训练分布之间的一致性。
Qwen2-VL
Update
- Qwen2-VL 将视觉编码器修改为朴素动态分辨率机制(NaViT),使模型能够将不同分辨率的图像动态处理为不同数量的视觉tokens。
- 集成了多模态旋转位置编码(M-RoPE),促进了文本、图像和视频中位置信息的有效融合。
- 采用统一的范式来处理图像和视频,增强模型的视觉感知能力。Qwen2-VL 能够理解超过 20 分钟的视频,增强其执行高质量的基于视频的问答、对话、内容创建等的能力。
- 多语言支持:为了服务英语和中文以外的全球受众,Qwen2-VL 现在支持图像中的多语言上下文理解,包括大多数欧洲语言、日语、韩语、阿拉伯语、越南语等。
模型框架
和 Qwen-VL的框架一致,该框架集成了视觉编码器和语言模型。其中语言模型选用了最新的Qwen2系列,视觉编码器采用了一个675M参数的ViT。
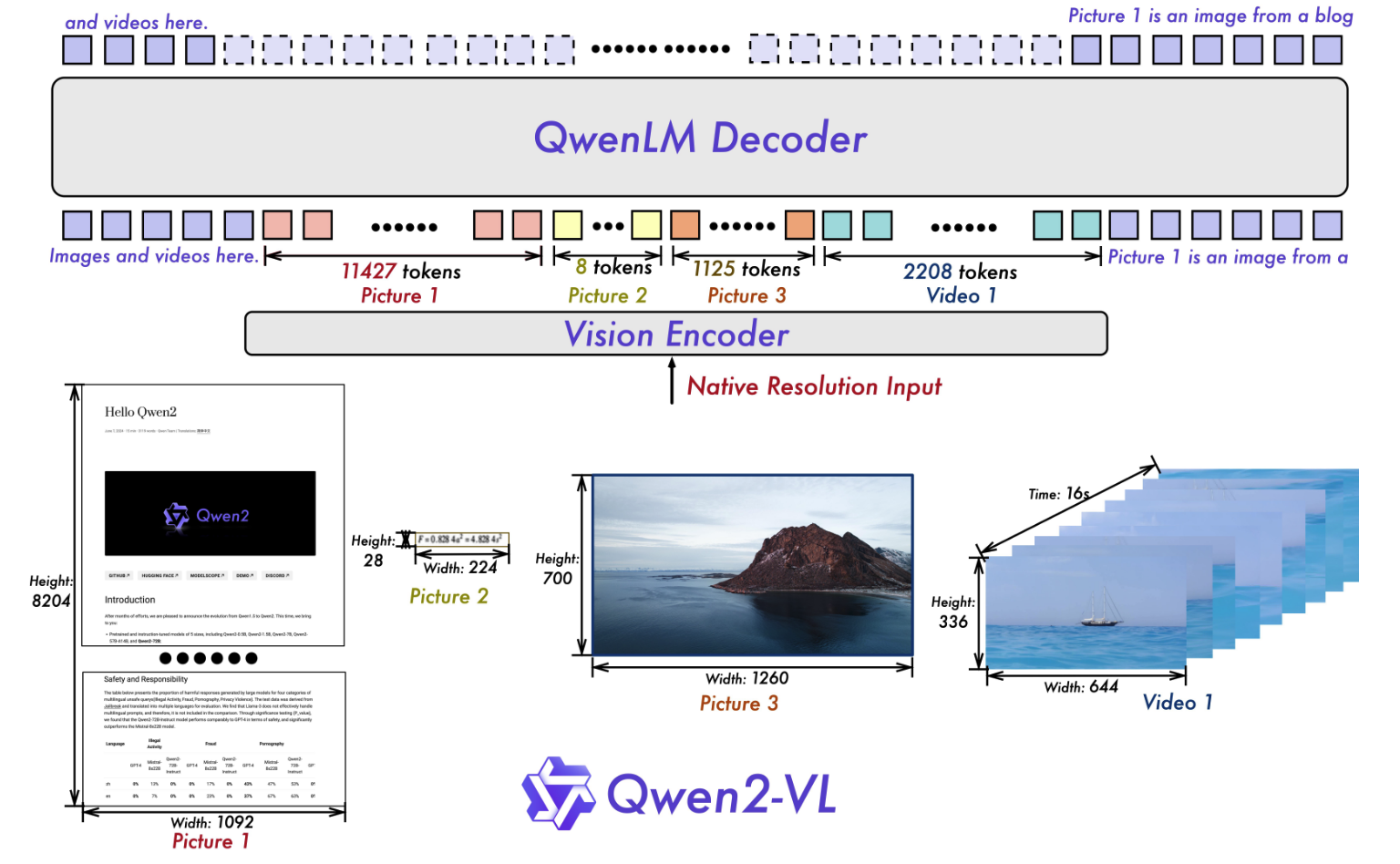
Naive Dynamic Resolution
Qwen2-VL 的一个关键架构改进是引入了朴素动态分辨率支持(NaViT)。与其前身不同,Qwen2-VL 现在可以处理任何分辨率的图像,将它们动态转换为可变数量的视觉tokens。
为了支持这一特性,作者通过删除原始的绝对位置编码并引入 2D-RoPE 来修改 ViT,捕获图像的二维位置信息。在推理阶段,不同分辨率的图像被打包成一个序列,并控制打包长度以限制 GPU 内存使用。此外,为了减少每个图像的视觉tokens,在ViT之后采用一个简单的MLP层,将相邻的2×2 token压缩为单个token,并将特殊的<|vision_start|>和<|vision_end|> token放置在压缩后的视觉token的开头和结尾。因此,分辨率为 \(224 × 224\) 的图像,使用 patch_size=14 使用 ViT 编码,在进入 LLM 之前将被压缩为 64+2 个tokens。
M-RoPE
另一个关键的架构增强是多模态旋转位置编码 (M-RoPE) 的创新。与LLM中传统的1D-RoPE仅限于对一维位置信息进行编码不同,M-RoPE有效地对多模态输入的位置信息进行了建模。这是通过将原始rope解构为三个部分来实现的:时间、高度和宽度。

如上图所示,对于文本部分使用了相同的三个ids,使 M-RoPE 在功能上等同于 1D-RoPE。在处理图像时,每个视觉标记的时间 ID 保持不变,而不同的 ID 则根据标记在图像中的位置分配给高度和宽度分量。对于被视为帧序列的视频,时间 ID 会随着每一帧递增,而高度和宽度分量遵循与图像相同的 ID 分配模式。在模型输入包含多种模态的场景中,每个模态的位置编号是通过将前一个模态的最大位置 ID 递增 1 来初始化的。M-RoPE 不仅增强了位置信息的建模,还降低了图像和视频的位置 ID 的值,使模型能够在推理过程中外推到更长的序列。
关于rope和2d-rope相关内容,详情见:旋转式位置编码 RoPE
统一图像和视频理解
Qwen2-VL 采用结合图像和视频数据的混合训练方案,确保熟练掌握图像理解和视频理解。为了尽可能完整地保留视频信息,以每秒两帧的速度对每个视频进行采样。此外,我们还集成了深度为2的3D卷积来处理视频输入,使模型能够处理3D tubes 而不是2D patches,从而使其能够在不增加序列长度的情况下处理更多的视频帧。为了保持一致性,每个图像都被视为两个相同的帧。为了平衡长视频处理的计算需求和整体训练效率,动态调整每个视频帧的分辨率,将每个视频的 token 总数限制为 16384。这种训练方法在模型理解长视频的能力和训练效率之间取得了平衡。
补充作者在github issue中的介绍:
vit使用dfn-h进行初始化,但为了适应动态分辨率,我们对它进行了改造,包括:
- 去除learnable position embedding;
- 去除patch embed后面接的layernorm;
- 以patch embed的权重初始化Conv3d;
- 增加2d-rope来建模不同分辨率下的位置信息
其实做了这些操作相当于已经改变vit的原始分布了,但我们没有再对它进行单独训练,而是直接对齐到LLM上,具体可参考qwen-vl的一阶段训练
模型训练
与Qwen-VL相同,Qwen2-VL同样采用了三阶段的训练方法。
- 在第一阶段,我们专门专注于训练视觉(ViT) 组件,利用大量的图像-文本对语料库来增强大型语言模型 (LLM) 中的语义理解。
- 在第二阶段,解冻所有参数,并使用更广泛的数据进行训练,以实现更全面的学习。
- 在最后阶段,冻结 ViT 参数,并使用指令数据集对 LLM 进行独占微调。
SFT部分用的训练数据形式和Qwen-VL一致,如下图所示:

为了赋予模型视觉定位能力,边界框坐标在[0, 1000)范围内进行归一化,并以“(\(X_{\text{top}\ \text{left}}\), \(Y_{\text{top}\ \text{left}}\)), (\(X_{\text{bottom}\ \text{right}}\), \(X_{\text{bottom}\ \text{right}}\))”的形式表示。使用标记<|box_start|>和<|box_end|>来界定边界框文本,为了准确的连接bbox和对应的文本描述,使用了<|object_ref_start|> 和 <|object_ref_end|> 来指示边界框引用的内容,从而允许模型有效地解释和生成特定区域的精确描述。数据形式如下图所示:

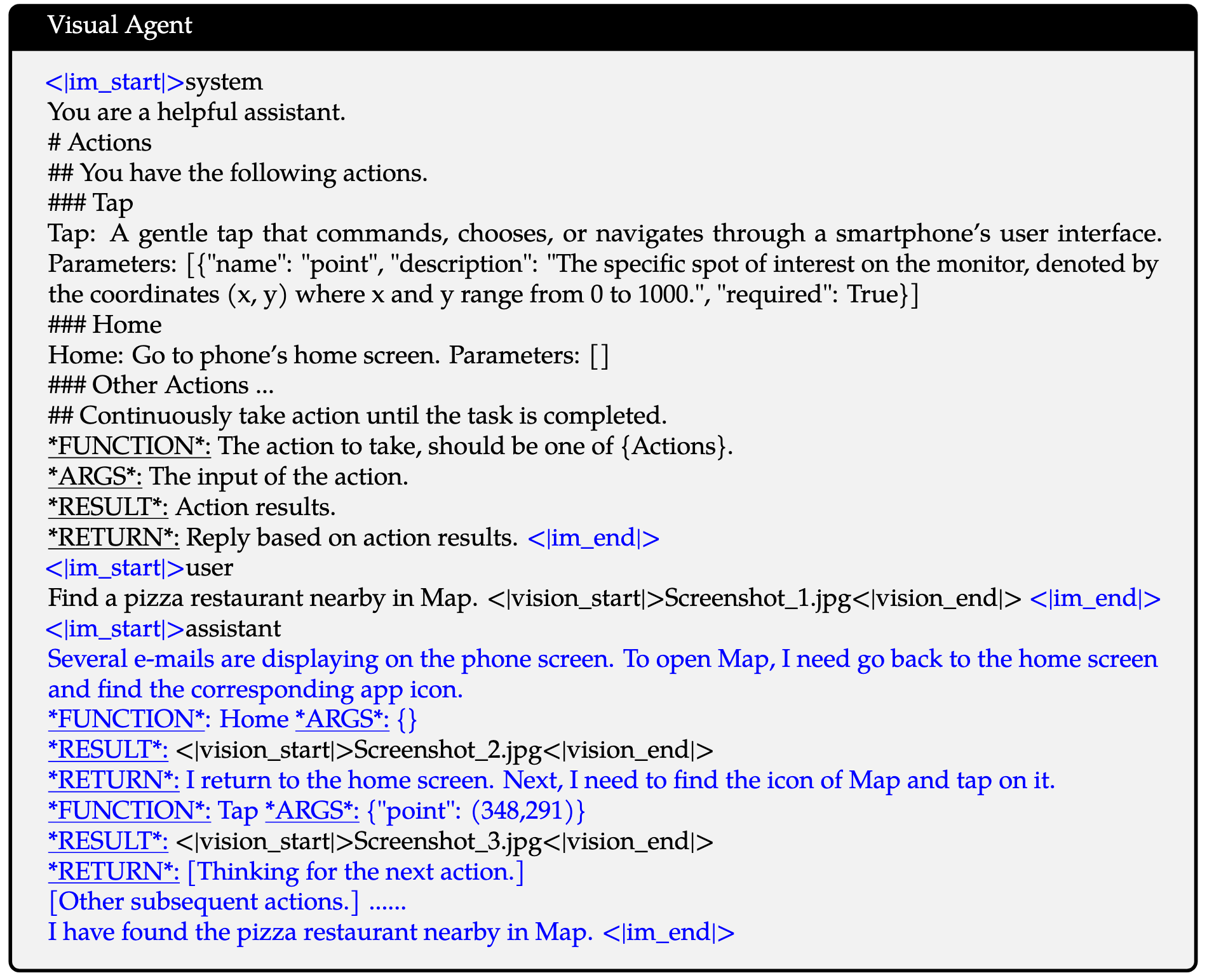
为了对Qwen2-VL引入通用视觉语言智能体(VL-Agent)的能力,将各种智能体任务,如UI操作、机器人控制、游戏和导航,视为序列决策问题,从而使Qwen2-VL能够通过多步骤动作执行完成任务。对于每个任务,首先定义一组允许的动作和功能调用关键词模式(下划线)。然后Qwen2-VL分析观察结果,进行推理和规划,执行选定的动作,并与环境互动以获取新的观察结果。这个周期会迭代重复,直到任务成功完成。通过整合各种工具并利用大型视觉语言模型(LVLMs)的视觉感知能力,Qwen2-VL能够迭代执行涉及现实世界视觉交互的日益复杂的任务,具体的数据形式如下图
Qwen2.5-VL
概述
Qwen2.5-VL 增强的能力
- 强大的文档解析功能:QWEN2.5-VL升级文本识别到综合分析,在处理多场景,多语言和各种内置(手写,表,图表,化学公式,化学公式和音乐表)文档方面表现出色。
- 跨格式Grouding:QWEN2.5-VL解锁了检测,pointing和计数对象的精度,增强了空间推理的绝对坐标和JSON格式输出的能力。
- 超长的视频理解和细粒度的视频Grounding:模型将天然动态分辨率扩展到时间维度,从而增强了在以秒为单位提取事件段的持续时间的能力。
- 增强计算机和移动设备的Agent功能:利用Grouding,推理和决策能力,通过智能手机和计算机上的优越Agent功能来提高模型。
模型架构
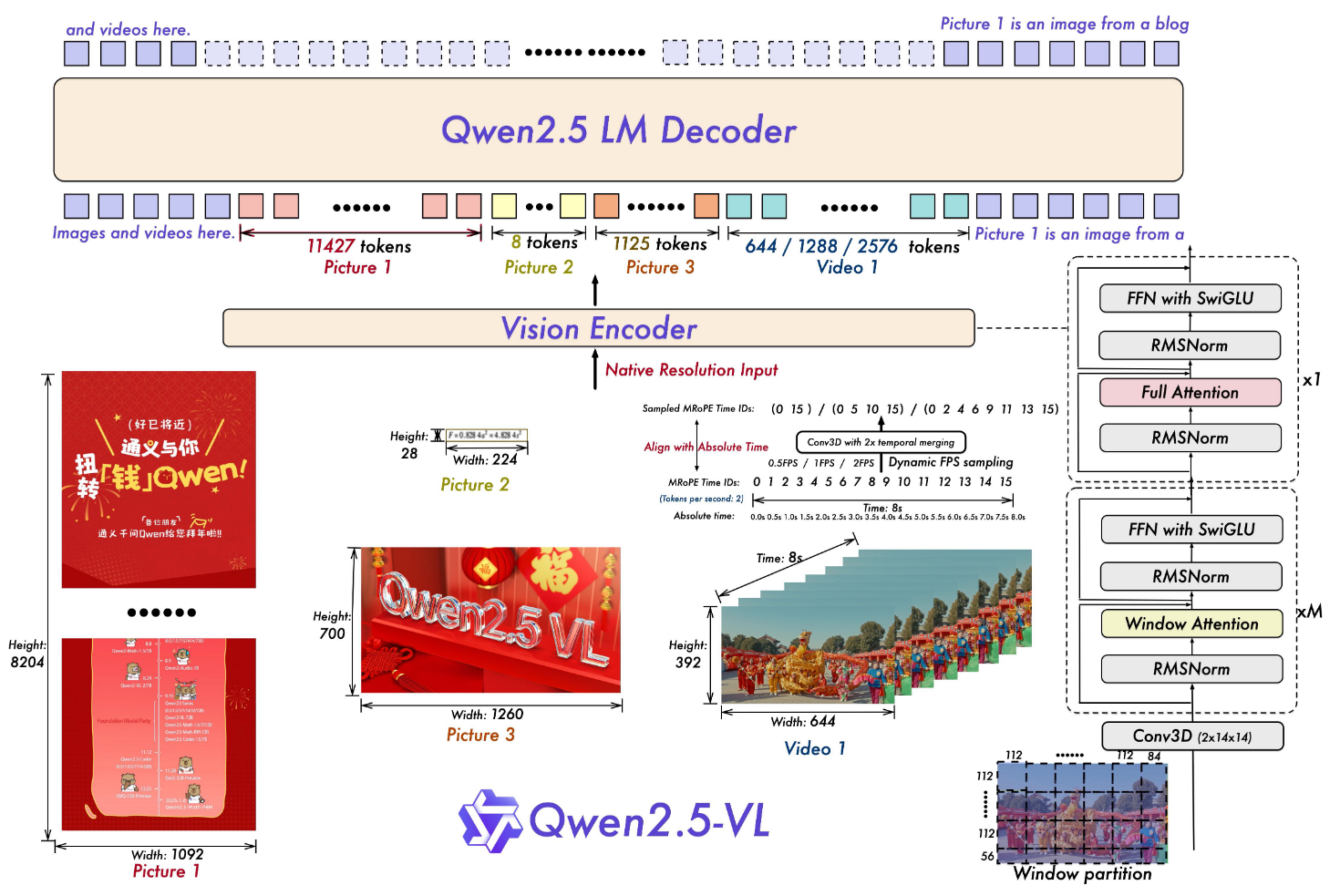
- 大型语言模型 (LLM)
- 以 Qwen2.5 LLM 的预训练权重为基础
- 对位置编码改进:从传统的 1D RoPE (Rotary Position Embedding) 改进为多模态旋转位置编码 (Multimodal Rotary Position Embedding), 这种编码与绝对时间对齐 (Aligned to Absolute Time),旨在更好地满足多模态理解的需求
- 视觉编码器 (Vision Encoder)
- 重新设计的 Vision Transformer (ViT) 架构
- 引入 2D-RoPE:处理二维图像数据的位置编码
- 引入窗口注意力机制 (window attention):支持原生输入分辨率并加速整个视觉编码器的计算
- 处理流程:
- 输入图像的高度和宽度在训练和推理过程中被调整为 28 的倍数
- 图像被分割成 patches,patch size为 14
- 生成一组图像特征
- 基于 MLP 的视觉-语言融合器 (MLP-based Vision-Language Merger)
- 不直接使用 ViT 提取的原始补丁特征,而是首先将空间上相邻的四个补丁特征分组
- 将这些分组特征连接起来,然后通过两层多层感知机 (MLP) 进行处理
- MLP 将特征投影到与 LLM 中使用的文本嵌入相匹配的维度
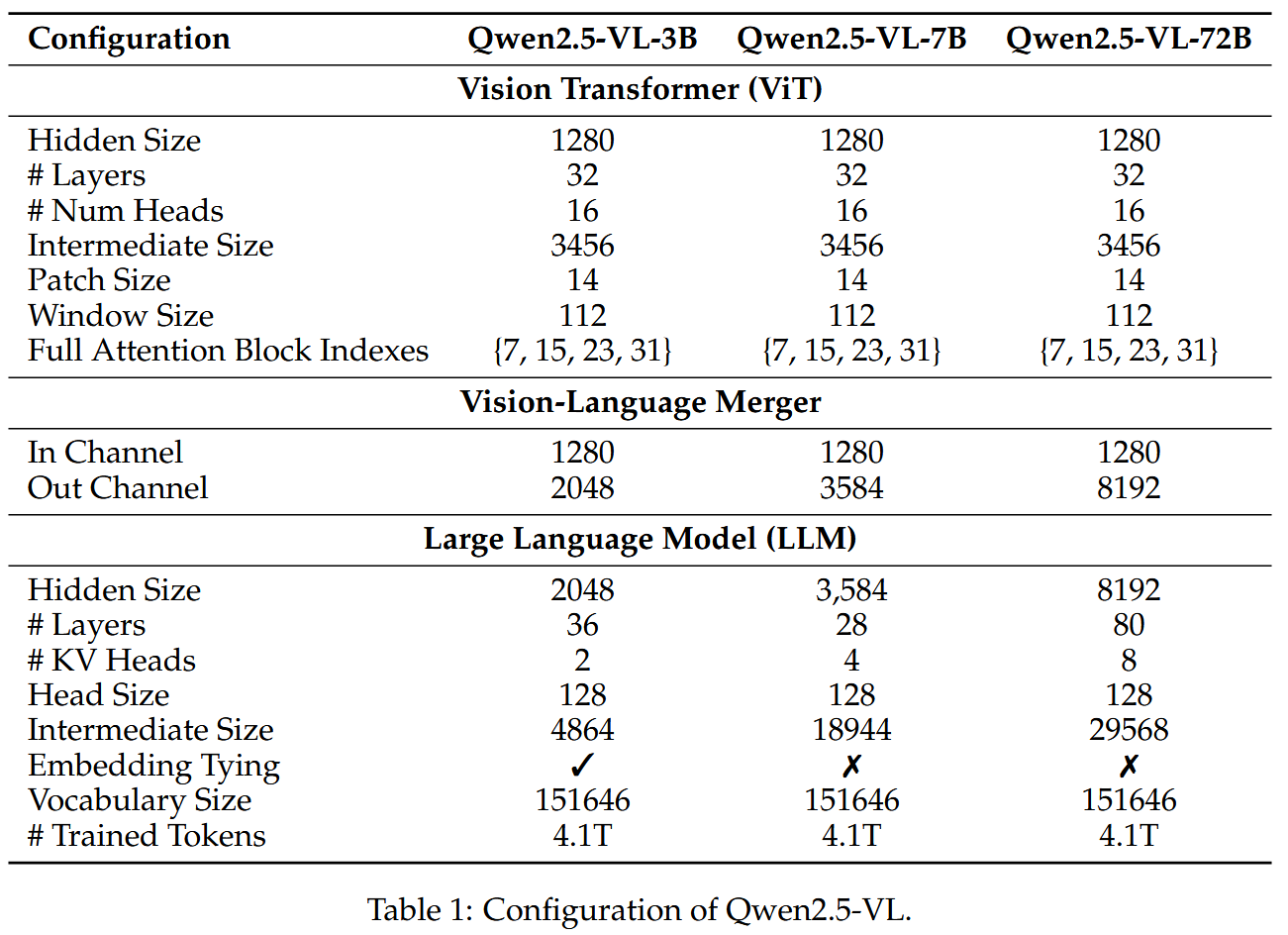
具体的模型参数如下表所示:
快速高效的视觉编码器
核心挑战:多模态大语言模型(MLLMs)在处理原生分辨率输入时面临计算负载不平衡,传统方法处理不同大小图像时的计算复杂度呈二次方增长,所以作者在大部分layer种引入了窗口注意力机制使计算成本与patch数量呈线性关系,而非二次方关系
- 窗口注意力机制(windowed attention)
它的主要目的是将图像分割成多个窗口,使得每个窗口内的特征可以相互关注,但不同窗口之间的特征不会直接交互。这样做可以显著降低计算复杂度,特别是对于高分辨率图像。
在视觉编码器中,仅4层使用完整的自注意力机制,其余层使用窗口注意力,最大窗口尺寸为 \(112×112\)(对应 \(8×8\) 个补丁),对于小于 \(112×112\) 的区域无需填充,保持原始分辨率,这种设计允许模型在输入分辨率下原生运行,避免不必要的缩放或失真 - 位置编码改进
对于图像,采用2D RoPE,有效捕获二维空间中的空间关系;视频处理:扩展到3D patches分割,基本单位为\(14×14\)图像patch(与传统ViT一致),并且对于视频数据中,两个连续帧被分组在一起,显著减少了输入语言模型的token数量,保持与现有架构的兼容性,同时提高处理序列视频数据的效率 - 网络结构优化
与LLM设计原则对齐,采用RMSNorm进行归一化,使用SwiGLU作为激活函数,这些选择增强了计算效率和视觉-语言组件之间的兼容性 - 训练策略
从头训练重新设计的ViT,分多阶段训练:- CLIP预训练
- 视觉-语言对齐
- 端到端微调
- 动态原生分辨率采样
训练时根据原始宽高比随机采样图像,使模型能够有效地泛化到不同分辨率的输入,确保在不同大小的视觉数据上稳定高效的训练
原生动态分辨率和帧率
- 空间维度处理:将不同大小的图像转换为相应长度的token序列,直接使用实际尺寸,而不是像传统方法那样标准化坐标。使用输入图像的实际尺寸来表示边界框、点和其他空间特征,使模型能够内在地学习比例信息,提高跨不同分辨率处理图像的能力
- 视频输入处理:动态帧率(FPS)训练,适应可变帧率,更好地捕获视频内容的时间动态。采用绝对时间编码,将MRoPE ID直接与时间戳对齐,这样做的好处是可以让模型通过时间维度ID之间的间隔理解时间的节奏,无需额外的计算开销,区别于其他需要文本时间戳或额外头部的方法
多模态旋转位置编码
- Qwen2-VL 中的MRoPE
将位置嵌入分解为三个维度:时间,高度和宽度
不同输入类型的处理:- 文本输入:三个组件使用相同的位置ID(等同于传统1D RoPE)
- 图像输入:
- 时间ID在所有视觉token中保持不变
- 高度和宽度组件基于每个token在图像中的空间位置分配唯一ID
- 视频输入:
- 每帧的时间ID递增
- 高度和宽度组件遵循与静态图像相同的分配模式
- Qwen2.5-VL的改进
- Qwen2-VL的局限性:MRoPE中的时间位置ID与输入帧数绑定,没有考虑内容变化速度或视频中的绝对时间
- 关键改进:将MRoPE的时间组件与绝对时间对齐
- 工作原理:利用时间ID之间的间隔,使模型能够学习跨不同FPS采样率视频的一致时间对齐,这种方法能够更准确地表示视频中的时间流逝
代码分析
图像与视频预处理
- 对图像或视频帧序列做 resize,scale和normalize
processed_images = []
for image in images:
if do_resize:
resized_height, resized_width = smart_resize(
height,
width,
factor=patch_size * merge_size,
min_pixels=size["shortest_edge"],
max_pixels=size["longest_edge"],
)
image = resize(
image, size=(resized_height, resized_width), resample=resample, input_data_format=input_data_format
)
if do_rescale:
image = self.rescale(image, scale=rescale_factor, input_data_format=input_data_format)
if do_normalize:
image = self.normalize(
image=image, mean=image_mean, std=image_std, input_data_format=input_data_format
)
image = to_channel_dimension_format(image, data_format, input_channel_dim=input_data_format)
processed_images.append(image)
- 对图像和视频帧整合和patchify,这里
temporal_patch_size是时间维度的patch大小,定义为2,对于单个图像,为了跟视频输入兼容,把每张图片看成是一模一样的两帧。 这么操作的主要目的还是为了增强模型对video的理解能力,对video的精细理解要求帧数要足够多才能避免遗漏关键信息,以 \(2\times14\times14 \) 的tube作为最小处理单位是一种非常cheap的处理方式,它可以在不增加seq_length的情况下提高模型处理帧数的上限。在前期实验里作者也发现以\(2\times14\times14 \) tube相较于\(1\times14\times14 \) patch在video任务上有一定提升;
if patches.shape[0] % temporal_patch_size != 0:
repeats = np.repeat(patches[-1][np.newaxis], temporal_patch_size - 1, axis=0)
patches = np.concatenate([patches, repeats], axis=0)
channel = patches.shape[1]
grid_t = patches.shape[0] // temporal_patch_size
grid_h, grid_w = resized_height // patch_size, resized_width // patch_size
patches = patches.reshape(
grid_t,
temporal_patch_size,
channel,
grid_h // merge_size,
merge_size,
patch_size,
grid_w // merge_size,
merge_size,
patch_size,
)
patches = patches.transpose(0, 3, 6, 4, 7, 2, 1, 5, 8)
flatten_patches = patches.reshape(
grid_t * grid_h * grid_w, channel * temporal_patch_size * patch_size * patch_size
)最终返回的数据形式为: grid_t * grid_h * grid_w, channel * temporal_patch_size * patch_size * patch_size 。
Patch Embedding
class Qwen2_5_VisionPatchEmbed(nn.Module):
def __init__(
self,
patch_size: int = 14,
temporal_patch_size: int = 2,
in_channels: int = 3,
embed_dim: int = 1152,
) -> None:
super().__init__()
self.patch_size = patch_size
self.temporal_patch_size = temporal_patch_size
self.in_channels = in_channels
self.embed_dim = embed_dim
kernel_size = [temporal_patch_size, patch_size, patch_size]
self.proj = nn.Conv3d(in_channels, embed_dim, kernel_size=kernel_size, stride=kernel_size, bias=False)
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
target_dtype = self.proj.weight.dtype
hidden_states = hidden_states.view(
-1, self.in_channels, self.temporal_patch_size, self.patch_size, self.patch_size
)
hidden_states = self.proj(hidden_states.to(dtype=target_dtype)).view(-1, self.embed_dim)
return hidden_states对输入的数据首先会做一层3d卷积,处理时序数据(单图同样),相当于对对视频和图像数据统一做了embedding,处理成patch_num*hidden_size的形式
2D-ROPE计算
def rot_pos_emb(self, grid_thw):
pos_ids = []
for t, h, w in grid_thw:
hpos_ids = torch.arange(h).unsqueeze(1).expand(-1, w)
hpos_ids = hpos_ids.reshape(
h // self.spatial_merge_size,
self.spatial_merge_size,
w // self.spatial_merge_size,
self.spatial_merge_size,
)
hpos_ids = hpos_ids.permute(0, 2, 1, 3)
hpos_ids = hpos_ids.flatten()
wpos_ids = torch.arange(w).unsqueeze(0).expand(h, -1)
wpos_ids = wpos_ids.reshape(
h // self.spatial_merge_size,
self.spatial_merge_size,
w // self.spatial_merge_size,
self.spatial_merge_size,
)
wpos_ids = wpos_ids.permute(0, 2, 1, 3)
wpos_ids = wpos_ids.flatten()
pos_ids.append(torch.stack([hpos_ids, wpos_ids], dim=-1).repeat(t, 1))
pos_ids = torch.cat(pos_ids, dim=0)
max_grid_size = grid_thw[:, 1:].max()
rotary_pos_emb_full = self.rotary_pos_emb(max_grid_size)
rotary_pos_emb = rotary_pos_emb_full[pos_ids].flatten(1)
return rotary_pos_emb- 根据
grid_thw计算图像或视频中 每个位置的id,pos_ids,以grid_thw=[2, 36, 66]为例,根据空间压缩比例spatial_merge_size,将位置进行分组排列(每个时序帧上的空间位置id相同)
(Pdb) pos_ids
tensor([[ 0, 0],
[ 0, 1],
[ 1, 0],
...,
[34, 65],
[35, 64],
[35, 65]])
(Pdb) pos_ids[:4]
tensor([[0, 0],
[0, 1],
[1, 0],
[1, 1]])- 计算2d-rope的频率
rotary_pos_emb_full = self.rotary_pos_emb(max_grid_size)
class Qwen2_5_VisionTransformerPretrainedModel(Qwen2_5_VLPreTrainedModel):
config_class = Qwen2_5_VLVisionConfig
_no_split_modules = ["Qwen2_5_VLVisionBlock"]
def __init__(self, config, *inputs, **kwargs) -> None:
super().__init__(config, *inputs, **kwargs)
...
head_dim = config.hidden_size // config.num_heads
self.rotary_pos_emb = Qwen2_5_VisionRotaryEmbedding(head_dim // 2)
...
class Qwen2_5_VisionRotaryEmbedding(nn.Module):
def __init__(self, dim: int, theta: float = 10000.0) -> None:
super().__init__()
inv_freq = 1.0 / (theta ** (torch.arange(0, dim, 2, dtype=torch.float) / dim))
self.register_buffer("inv_freq", inv_freq, persistent=False)
def forward(self, seqlen: int) -> torch.Tensor:
seq = torch.arange(seqlen, device=self.inv_freq.device, dtype=self.inv_freq.dtype)
freqs = torch.outer(seq, self.inv_freq)
return freqs注意这里是在计算2d-rope的频率,如下公式所示,对应的频率每四个维度共用一个频率,所以传入计算频率时的维度对应为:head_dim // 2
- 对每个位置\((x, y)\)应用计算出的频率
rotary_pos_emb = rotary_pos_emb_full[pos_ids].flatten(1), 返回的rotary_pos_emb维度为(thw,head_dim//2) - 计算 cos和sin值后传入attention计算
emb = torch.cat((rotary_pos_emb, rotary_pos_emb), dim=-1)
position_embeddings = (emb.cos(), emb.sin())- 对
q和k计算2d-rope 以eager模式的attention为例:
q, k = apply_rotary_pos_emb_vision(q, k, cos, sin)def rotate_half(x):
"""Rotates half the hidden dims of the input."""
x1 = x[..., : x.shape[-1] // 2]
x2 = x[..., x.shape[-1] // 2 :]
return torch.cat((-x2, x1), dim=-1)
def apply_rotary_pos_emb_vision(
q: torch.Tensor, k: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor
) -> Tuple[torch.Tensor, torch.Tensor]:
orig_q_dtype = q.dtype
orig_k_dtype = k.dtype
q, k = q.float(), k.float()
cos, sin = cos.unsqueeze(-2).float(), sin.unsqueeze(-2).float()
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
q_embed = q_embed.to(orig_q_dtype)
k_embed = k_embed.to(orig_k_dtype)
return q_embed, k_embed
Windows-Attention
- 计算窗口索引以及对应的每个窗口的序列长度
def get_window_index(self, grid_thw):
window_index: list = []
cu_window_seqlens: list = [0]
window_index_id = 0
vit_merger_window_size = self.window_size // self.spatial_merge_size // self.patch_size
for grid_t, grid_h, grid_w in grid_thw:
llm_grid_h, llm_grid_w = (
grid_h // self.spatial_merge_size,
grid_w // self.spatial_merge_size,
)
index = torch.arange(grid_t * llm_grid_h * llm_grid_w).reshape(grid_t, llm_grid_h, llm_grid_w)
pad_h = vit_merger_window_size - llm_grid_h % vit_merger_window_size
pad_w = vit_merger_window_size - llm_grid_w % vit_merger_window_size
num_windows_h = (llm_grid_h + pad_h) // vit_merger_window_size
num_windows_w = (llm_grid_w + pad_w) // vit_merger_window_size
index_padded = F.pad(index, (0, pad_w, 0, pad_h), "constant", -100)
index_padded = index_padded.reshape(
grid_t,
num_windows_h,
vit_merger_window_size,
num_windows_w,
vit_merger_window_size,
)
index_padded = index_padded.permute(0, 1, 3, 2, 4).reshape(
grid_t,
num_windows_h * num_windows_w,
vit_merger_window_size,
vit_merger_window_size,
)
seqlens = (index_padded != -100).sum([2, 3]).reshape(-1)
index_padded = index_padded.reshape(-1)
index_new = index_padded[index_padded != -100]
window_index.append(index_new + window_index_id)
cu_seqlens_tmp = seqlens.cumsum(0) * self.spatial_merge_unit + cu_window_seqlens[-1]
cu_window_seqlens.extend(cu_seqlens_tmp.tolist())
window_index_id += (grid_t * llm_grid_h * llm_grid_w).item()
window_index = torch.cat(window_index, dim=0)
return window_index, cu_window_seqlens这里得到的 window_index 即为该序列再转成(window_num, window_size,window_size)后的index排列, 方便后续在reshape后的序列重索引;而cu_window_seqlens则为每个窗口的序列长度
- 重索引: 针对序列和对应的rope频率 group成
windows_num个序列后重新索引
seq_len, _ = hidden_states.size()
hidden_states = hidden_states.reshape(seq_len // self.spatial_merge_unit, self.spatial_merge_unit, -1)
hidden_states = hidden_states[window_index, :, :]
hidden_states = hidden_states.reshape(seq_len, -1)
rotary_pos_emb = rotary_pos_emb.reshape(seq_len // self.spatial_merge_unit, self.spatial_merge_unit, -1)
rotary_pos_emb = rotary_pos_emb[window_index, :, :]
rotary_pos_emb = rotary_pos_emb.reshape(seq_len, -1)- 通过设置
attention_mask来计算window-attention
attention_mask = torch.full(
[1, seq_length, seq_length], torch.finfo(q.dtype).min, device=q.device, dtype=q.dtype
)
for i in range(1, len(cu_seqlens)):
attention_mask[..., cu_seqlens[i - 1] : cu_seqlens[i], cu_seqlens[i - 1] : cu_seqlens[i]] = 0多模态RoPE索引计算
Qwen2.5-VL模型采用了一种复杂的三维旋转位置编码(3D RoPE)机制来处理多模态输入(文本、图像和视频)。具体在代码中来说,对应为get_rope_index方法,这是模型处理多模态位置编码的核心。
可以通过这个方法的注释来窥得一二:
Explanation:
Each embedding sequence contains vision embedding and text embedding or just contains text embedding.
For pure text embedding sequence, the rotary position embedding has no difference with modern LLMs.
Examples:
input_ids: [T T T T T], here T is for text.
temporal position_ids: [0, 1, 2, 3, 4]
height position_ids: [0, 1, 2, 3, 4]
width position_ids: [0, 1, 2, 3, 4]
For vision and text embedding sequence, we calculate 3D rotary position embedding for vision part
and 1D rotary position embedding for text part.
Examples:
Temporal (Time): 3 patches, representing different segments of the video in time.
Height: 2 patches, dividing each frame vertically.
Width: 2 patches, dividing each frame horizontally.
We also have some important parameters:
fps (Frames Per Second): The video's frame rate, set to 1. This means one frame is processed each second.
tokens_per_second: This is a crucial parameter. It dictates how many "time-steps" or "temporal tokens" are conceptually packed into a one-second interval of the video. In this case, we have 25 tokens per second. So each second of the video will be represented with 25 separate time points. It essentially defines the temporal granularity.
temporal_patch_size: The number of frames that compose one temporal patch. Here, it's 2 frames.
interval: The step size for the temporal position IDs, calculated as tokens_per_second * temporal_patch_size / fps. In this case, 25 * 2 / 1 = 50. This means that each temporal patch will be have a difference of 50 in the temporal position IDs.
input_ids: [V V V V V V V V V V V V T T T T T], here V is for vision.
vision temporal position_ids: [0, 0, 0, 0, 50, 50, 50, 50, 100, 100, 100, 100]
vision height position_ids: [0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1]
vision width position_ids: [0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1]
text temporal position_ids: [101, 102, 103, 104, 105]
text height position_ids: [101, 102, 103, 104, 105]
text width position_ids: [101, 102, 103, 104, 105]
Here we calculate the text start position_ids as the max vision position_ids plus 1.说明: 每个嵌入序列包含视觉嵌入和文本嵌入,或仅包含文本嵌入。
- 对于纯文本嵌入序列,旋转位置嵌入与现代大语言模型(LLM)没有区别。
示例:- input_ids: [T T T T T],其中 T 代表文本。
- temporal position_ids(时间位置编号):[0, 1, 2, 3, 4]
- height position_ids(高度位置编号):[0, 1, 2, 3, 4]
- width position_ids(宽度位置编号):[0, 1, 2, 3, 4]
- 对于包含视觉和文本嵌入的序列,视觉部分计算三维旋转位置嵌入,文本部分计算一维旋转位置嵌入。
示例:
这里将文本的起始位置编号设为视觉部分最大位置编号加 1。- 时间(Temporal):3 个 patch,表示视频中不同时间段的片段。
- 高度(Height):2 个 patch,将每一帧在垂直方向上分割。
- 宽度(Width):2 个 patch,将每一帧在水平方向上分割。
- fps(每秒帧数):视频的帧率,这里设置为 1,即每秒处理一帧。
- tokens_per_second:这是一个关键参数,决定了每秒视频中“时间步”或“时间 token”的数量。在本例中,每秒有 25 个 token。因此,每秒的视频会被表示为 25 个独立的时间点。它本质上定义了时间上的细粒度。
- temporal_patch_size:组成一个时间 patch 的帧数,这里为 2 帧。
- interval:时间位置编号的步长,计算方法为 tokens_per_second * temporal_patch_size / fps。本例中,25 * 2 / 1 = 50。意味着每个时间 patch 在时间位置编号上相差 50。
- input_ids: [V V V V V V V V V V V V T T T T T],其中 V 代表视觉。
- 视觉时间位置编号(vision temporal position_ids):[0, 0, 0, 0, 50, 50, 50, 50, 100, 100, 100, 100]
- 视觉高度位置编号(vision height position_ids):[0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1]
- 视觉宽度位置编号(vision width position_ids):[0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1]
- 文本时间位置编号(text temporal position_ids):[101, 102, 103, 104, 105]
- 文本高度位置编号(text height position_ids):[101, 102, 103, 104, 105]
- 文本宽度位置编号(text width position_ids):[101, 102, 103, 104, 105]
# if we get 4D attention mask we cannot calculate rope deltas anymore. TODO @raushan fixme
if position_ids is None and (attention_mask is None or attention_mask.ndim == 2):
# calculate RoPE index once per generation in the pre-fill stage only
if (
(cache_position is not None and cache_position[0] == 0)
or self.rope_deltas is None
or (past_key_values is None or past_key_values.get_seq_length() == 0)
):
position_ids, rope_deltas = self.get_rope_index(
input_ids,
image_grid_thw,
video_grid_thw,
second_per_grid_ts,
attention_mask,
)
self.rope_deltas = rope_deltas
# then use the prev pre-calculated rope-deltas to get the correct position ids
else:
batch_size, seq_length, _ = inputs_embeds.shape
delta = (
(cache_position[0] + self.rope_deltas).to(inputs_embeds.device)
if cache_position is not None
else 0
)
position_ids = torch.arange(seq_length, device=inputs_embeds.device)
position_ids = position_ids.view(1, -1).expand(batch_size, -1)
if cache_position is not None: # otherwise `deltas` is an int `0`
delta = delta.repeat_interleave(batch_size // delta.shape[0], dim=0)
position_ids = position_ids.add(delta)
position_ids = position_ids.unsqueeze(0).expand(3, -1, -1)Qwen2.5-VL的RoPE索引计算基于以下关键概念:
- 三维位置编码:不同于传统语言模型的一维位置编码,Qwen2.5-VL使用三维位置编码(时间、高度、宽度)来表示视觉数据的空间和时间关系。
- 模态混合序列:输入序列可能包含纯文本,也可能是文本和视觉数据(图像/视频)的混合。
- 位置偏移量(rope_deltas):用于在生成过程中保持正确的位置关系。
get_rope_index方法的主要流程如下:
- 初始化和参数准备
spatial_merge_size = self.config.vision_config.spatial_merge_size
image_token_id = self.config.image_token_id
video_token_id = self.config.video_token_id
vision_start_token_id = self.config.vision_start_token_id
mrope_position_deltas = []spatial_merge_size:视觉特征的空间合并大小,用于降低视觉特征的空间分辨率, 默认为2- 各种特殊token的ID:用于识别输入序列中的图像和视频部分
- 多模态输入处理
当输入包含视觉数据时:
if input_ids is not None and (image_grid_thw is not None or video_grid_thw is not None):创建一个形状为(3, batch_size, sequence_length)的张量来存储三维位置ID:
position_ids = torch.ones(
3,
input_ids.shape[0],
input_ids.shape[1],
dtype=input_ids.dtype,
device=input_ids.device,
)
- 逐样本处理
对批次中的每个样本:
for i, input_ids in enumerate(total_input_ids):识别视觉内容:
vision_start_indices = torch.argwhere(input_ids == vision_start_token_id).squeeze(1)
vision_tokens = input_ids[vision_start_indices + 1]
image_nums = (vision_tokens == image_token_id).sum()
video_nums = (vision_tokens == video_token_id).sum()处理每个视觉元素:
- 查找图像或视频token的位置
- 根据类型(图像/视频)获取对应的时间、高度和宽度信息, 其中
second_per_grid_t表示每个时间网格的实际持续时间(秒) - 计算网格维度:
llm_grid_t, llm_grid_h, llm_grid_w
for _ in range(image_nums + video_nums):
# 查找图像和视频标记
if image_token_id in input_tokens and remain_images > 0:
ed_image = input_tokens.index(image_token_id, st)
else:
ed_image = len(input_tokens) + 1
if video_token_id in input_tokens and remain_videos > 0:
ed_video = input_tokens.index(video_token_id, st)
else:
ed_video = len(input_tokens) + 1
# 确定处理哪种模态
if ed_image < ed_video:
# 图像
t, h, w = (
image_grid_thw[image_index][0],
image_grid_thw[image_index][1],
image_grid_thw[image_index][2],
)
second_per_grid_t = 0
image_index += 1
remain_images -= 1
ed = ed_image
else:
# 视频
t, h, w = (
video_grid_thw[video_index][0],
video_grid_thw[video_index][1],
video_grid_thw[video_index][2],
)
if second_per_grid_ts is not None:
second_per_grid_t = second_per_grid_ts[video_index]
else:
second_per_grid_t = 1.0
video_index += 1
remain_videos -= 1
ed = ed_video
llm_grid_t, llm_grid_h, llm_grid_w = (
t.item(),
h.item() // spatial_merge_size,
w.item() // spatial_merge_size,
)
text_len = ed - st- 计算位置ID:
- 对于文本部分, 创建一个从
0到text_len-1的连续整数序列; 并将其扩展为3行(对应时间、高度、宽度三个维度)
- 对于文本部分, 创建一个从
st_idx = llm_pos_ids_list[-1].max() + 1 if len(llm_pos_ids_list) > 0 else 0
llm_pos_ids_list.append(torch.arange(text_len).view(1, -1).expand(3, -1) + st_idx)- 对于视觉部分(3D位置编码):
# 1.时间维度
# 创建一个从0到llm_grid_t-1的序列,表示时间网格索引
range_tensor = torch.arange(llm_grid_t).view(-1, 1)
# 将时间索引扩展到空间维度(高度×宽度)
expanded_range = range_tensor.expand(-1, llm_grid_h * llm_grid_w)
# 将时间索引转换为实际的时间位置
time_tensor = expanded_range * second_per_grid_t * self.config.vision_config.tokens_per_second
# 最终的时间维度位置索引(展平为一维)
t_index = time_tensor.long().flatten()
# 2.高度维度
h_index = torch.arange(llm_grid_h).view(1, -1, 1).expand(llm_grid_t, -1, llm_grid_w).flatten()
# 3.宽度维度
w_index = torch.arange(llm_grid_w).view(1, 1, -1).expand(llm_grid_t, llm_grid_h, -1).flatten()
# 合并三个维度的位置编码
llm_pos_ids_list.append(torch.stack([t_index, h_index, w_index]) + text_len + st_idx)计算位置偏移量:
mrope_position_deltas.append(llm_positions.max() + 1 - len(total_input_ids[i]))这个偏移量确保在自回归生成过程中,新生成的token能够有正确的位置编码。
- 纯文本输入处理
当输入不包含视觉数据时:
else:
if attention_mask is not None:
position_ids = attention_mask.long().cumsum(-1) - 1
position_ids.masked_fill_(attention_mask == 0, 1)
position_ids = position_ids.unsqueeze(0).expand(3, -1, -1).to(attention_mask.device)
max_position_ids = position_ids.max(0, keepdim=False)[0].max(-1, keepdim=True)[0]
mrope_position_deltas = max_position_ids + 1 - attention_mask.shape[-1]
else:
position_ids = torch.arange(input_ids.shape[1], device=input_ids.device).view(1, 1, -1).expand(3, input_ids.shape[0], -1)
mrope_position_deltas = torch.zeros([input_ids.shape[0], 1], device=input_ids.device, dtype=input_ids.dtype)
rope_deltas的作用
在Qwen2.5-VL模型中,rope_deltas是一个关键参数,用于处理多模态序列中的位置编码差异,特别是在自回归生成过程中。
rope_deltas表示多模态RoPE(旋转位置编码)与序列长度之间的索引差异。从代码中可以看到,它的计算方式为:
mrope_position_deltas.append(llm_positions.max() + 1 - len(total_input_ids[i]))
这个计算公式揭示了rope_deltas的本质:
llm_positions.max() + 1:多模态序列中最大的位置ID加1len(total_input_ids[i]):输入序列的实际长度- 两者的差值代表了"虚拟位置"与"实际位置"之间的偏移量
rope_deltas参数的具体作用:
- 解决多模态位置编码与线性位置的不一致问题
在处理多模态输入时,视觉内容(图像和视频)使用三维位置编码,这会导致位置索引"跳跃"。例如:
这导致序列的最大位置ID可能远大于序列的实际长度,rope_deltas记录了这个差异。- 文本使用连续的位置ID:0, 1, 2, 3...
- 视觉内容可能使用跳跃的位置ID,如视频的时间维度:0, 0, 0, 0, 50, 50, 50, 50...
- 在自回归生成过程中保持位置连续性
在模型的forward方法中,我们可以看到rope_deltas的关键应用:这段代码展示了两个关键场景:
if position_ids is None and (attention_mask is None or attention_mask.ndim == 2):
# 第一次计算(预填充阶段)
if (
(cache_position is not None and cache_position[0] == 0)
or self.rope_deltas is None
or (past_key_values is None or past_key_values.get_seq_length() == 0)
):
position_ids, rope_deltas = self.get_rope_index(
input_ids,
image_grid_thw,
video_grid_thw,
second_per_grid_ts,
attention_mask,
)
self.rope_deltas = rope_deltas
# 使用预先计算的rope_deltas获取正确的position_ids
else:
batch_size, seq_length, _ = inputs_embeds.shape
delta = (
(cache_position[0] + self.rope_deltas).to(inputs_embeds.device)
if cache_position is not None
else 0
)
position_ids = torch.arange(seq_length, device=inputs_embeds.device)
position_ids = position_ids.view(1, -1).expand(batch_size, -1)
if cache_position is not None:
delta = delta.repeat_interleave(batch_size // delta.shape[0], dim=0)
position_ids = position_ids.add(delta)
position_ids = position_ids.unsqueeze(0).expand(3, -1, -1)- 预填充阶段(第一次前向传播):
- 计算完整的三维位置编码
- 存储
rope_deltas以备后续使用
- 自回归生成阶段:
- 使用缓存的
rope_deltas - 为新生成的token分配正确的位置ID,确保它们与之前的位置编码保持一致
- 使用缓存的
- 预填充阶段(第一次前向传播):
- 确保位置编码的连续性
在自回归生成过程中,模型每次只生成一个新token,但需要确保新token的位置编码与之前生成的内容保持连续。通过cache_position[0] + self.rope_deltas,模型能够正确计算新token的位置ID,即使原始多模态序列中存在位置"跳跃"。
模型训练
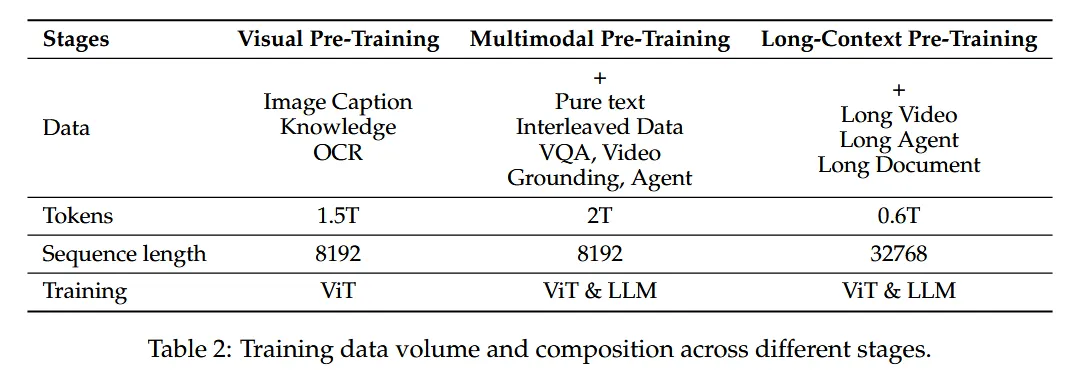
Pre-Training
- 数据量大幅增加:从Qwen2-VL的1.2万亿tokens扩展到约4万亿tokens
- 数据来源多样化:通过清洗原始网络数据、合成数据等多种方法构建
- 多模态数据类型丰富:包含图像描述、图文交错数据、OCR数据、视觉知识、学术问题、定位数据、文档解析、视频描述等
Post-Training
整个后训练包含两个阶段SFT和DPO
- 指令数据 (Instruction Data)
一共包含约200万条数据,其中包含 纯文本数据:50%,多模态数据:50%(图文和视频文本组合),主要为中文和英文,补充多语言数据以支持更广泛的语言多样性
针对对话复杂性,作者设计了几种模式,包含:单轮对话,多轮对话以及视觉输入的变化(单图像输入,多图像序列,模拟真实对话动态) - 数据过滤管道 (Data Filtering Pipeline)
- 第一阶段,领域特定分类,基于Qwen2-VL-Instag(基于Qwen2-VL-72B的专门分类模型)。将数据分为**8个主要领域,如编程和规划,和30个细粒度子类别,**例如编程领域细分为:代码调试,代码生成,代码翻译,代码理解等
- 第二阶段 域限制过滤:
- 规则基础过滤,如重复模式识别,格式检查,内容审核;
- 模型过滤,其中过滤模型使用基于Qwen2.5-VL系列训练的奖励模型进行多维度评估:对查询的复杂性和相关性进行评估,仅保留那些具有挑战性且在上下文相关的示例。根据正确性,完整性,清晰度,与查询相关性和乐于助人对答案进行评估。在视觉接地任务中,特别注意验证视觉信息的准确解释和利用。这种多维评分确保只有高质量数据才能发展为SFT阶段。
- 增强推理的拒绝采样 (Rejection Sampling)
特别适用于需要复杂推理的任务:数学问题求解,代码生成,领域特定的视觉问答
拒绝采样流程- 数据准备: 起始数据包含真实标注的数据集;任务类型为需要多步推理的任务并使用Qwen2.5-VL中间版本评估生成响应
- 保留标准:模型输出与预期答案匹配并确保数据集仅包含高质量、准确的示例
- 排除标准:代码切换,过度冗长和重复的模式
- 多模态整合:中间推理步骤可能无法充分整合视觉信息,可能忽略相关视觉线索或误解视觉内容,因此,作者采用了规则基础过滤策略来验证中间推理步骤准确性,模型驱动过滤策略以确保每个CoT步骤有效整合视觉和文本模态
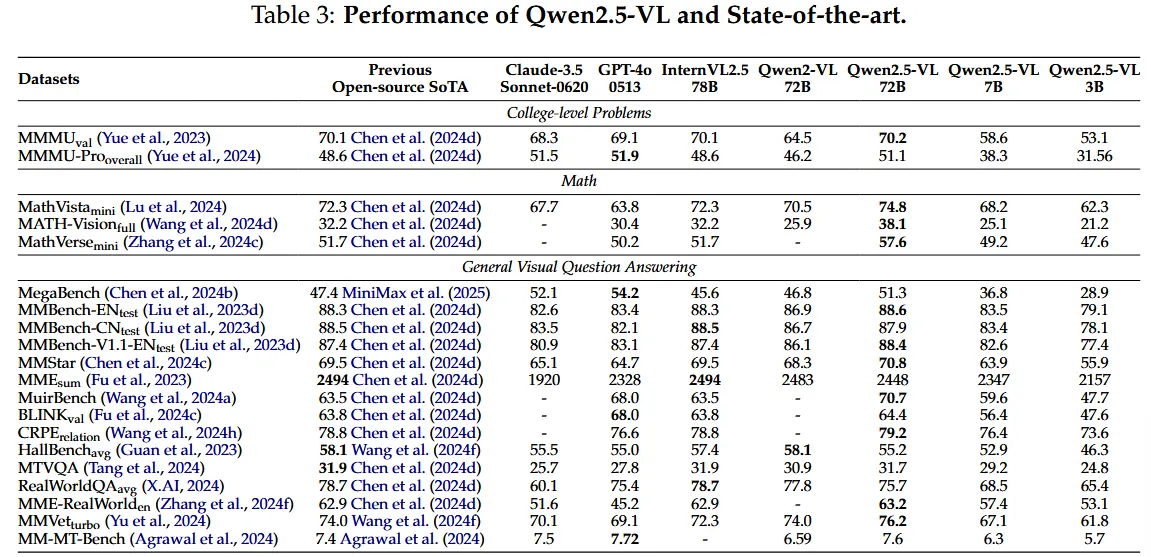
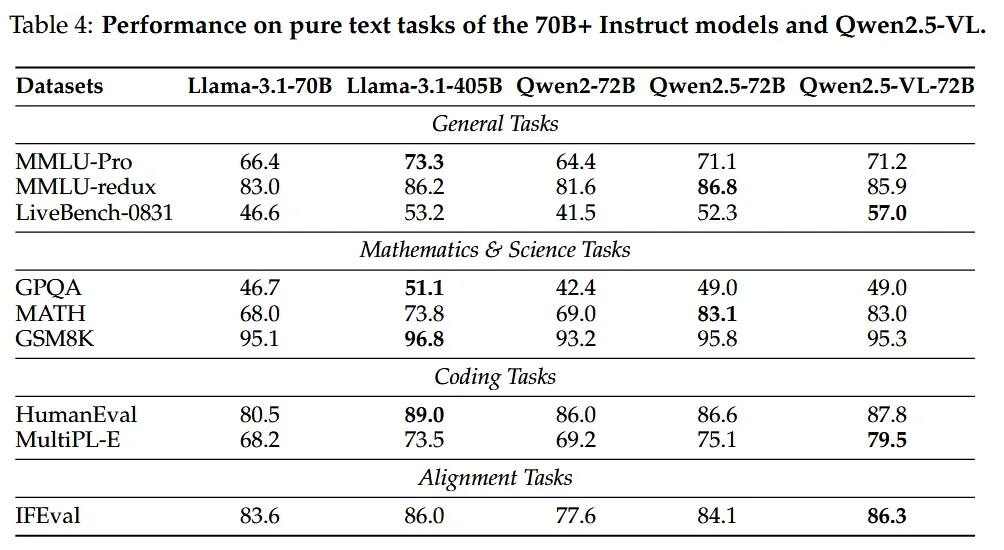
实验
Qwen3-VL
- LLM:包含3种dense模型和2种MOE模型,旗舰模型为 Qwen3-VL-235B-A22B。在自注意力中使用了QK-Norm,并且在前3层进行Deepstack特征融合。
- ViT:复用SigLIP-2架构,在其基础上进行继续预训练(Qwen2.5VL重新训练ViT)。
- patch_embed中开启了bias,patch-size变成16(Qwen2.5VL关闭 bias,patch-size14)。
- MLP中激活函数变成PytorchGELUTanh(Qwen2.5VL SiLU)。
- 位置编码仍然采用2D-RoPE,支持动态分辨率,并根据输入尺寸插值绝对位置嵌入。
- 采用LayerNorm(Qwen2.5VL 采用RMSNorm)。
- 定位从绝对坐标又改回了相对坐标。
- Merger:与Qwen2.5VL一样采用两层的MLP,将视觉特征压缩为1个token。区别是采用LayerNorm,并使用了DeepStack机制(后面介绍)。
视觉模型
使用SigLIP-2架构作为视觉编码器,并继续使用动态输入分辨率对其进行训练,初始化自官方预训练检查点。为了有效地适应动态分辨率,采用了2D-RoPE并根据输入大小插值绝对位置嵌入,这里主要采用了CoMP中的对齐方案。具体来说,默认使用SigLIP2-SO-400M变体,对于小规模LLM(2B和4B),使用SigLIP2-Large(300M)
并且,Qwen3-VL引入DeepStack技术,融合 ViT 多层次特征,提升视觉细节捕捉能力和图文对齐精度;沿用DeepStack的核心思想,将以往多模态大模型(LMM)单层输入视觉tokens的范式,改为在大型语言模型 (LLM) 的多层中进行注入。这种多层注入方式旨在实现更精细化的视觉理解。
在此基础上,进一步优化了视觉特征 token 化的策略。具体而言,作者将来自 ViT 不同层的视觉特征进行 token 化,并以此作为视觉输入。这种设计能够有效保留从底层(low-level)到高层(high-level)的丰富视觉信息。实验结果表明,该方法在多种视觉理解任务上均展现出显著的性能提升。
ViT预训练和对齐(CoMP)
这里简单介绍一下CoMP(Continual Multimodal Pre-training for Vision Foundation Models)的方案
CoMP的主要目的是在一些现有的视觉模型(如:SigLIP、AIMv2)上继续训练让多模态视觉语言模型并支持原生支持任意分辨率图像输入
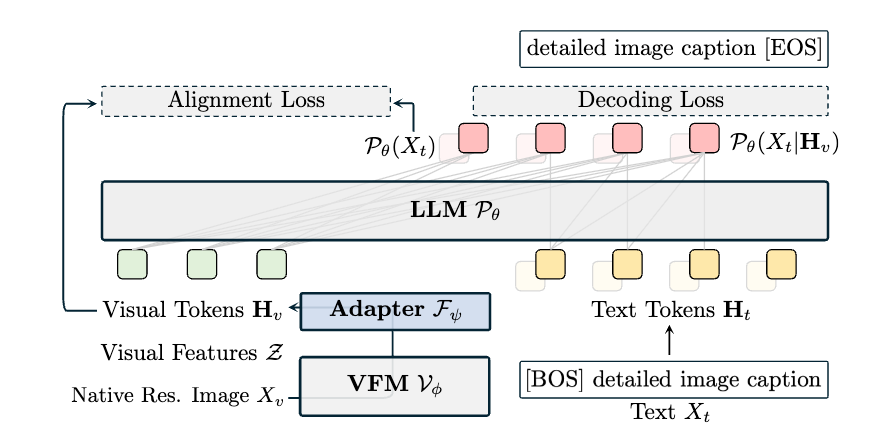
COMP的目标是让现有视觉基础模型(VFMs)原生支持任意分辨率图像输入,并将其视觉表征与大语言模型(LLMs)的语言表征直接对齐。整体流程如上图:原生分辨率图像经VFMs(含C-ROPE)生成视觉特征,文本经LLM生成文本特征,通过双损失函数联合训练,最终输出增强后的VFMs。方法如下:
- 原生分辨率适配
现有VFMs的位置嵌入是为固定分辨率设计的,处理不同尺寸图像时常用“插值调整位置嵌入”,但会丢失细节;纯RoPE2D(旋转位置嵌入)虽支持分辨率外推,但数据效率低、训练不稳定。因此C-ROPE的核心是 结合绝对位置嵌入的“稳定性”和相对RoPE2D的“分辨率适应性”。
C-ROPE的设计核心是 “结合绝对位置嵌入的稳定性 + RoPE2D的分辨率适应性”,实现原生分辨率支持。

C-ROPE的流程如上图所示:
- 图像分块(Patchify):将原生分辨率为的图像分割为个patch(为patch尺寸,为图像通道数),得到patch特征;
- 绝对位置嵌入插值:将预训练好的固定尺寸位置嵌入通过双线性插值调整到当前patch数量,加到patch特征中,提供基础位置信息;
- RoPE2D旋转:对Transformer的query和key应用2D旋转矩阵,捕捉patch间的相对位置关系(适配任意分辨率);
- 后续通过投影层和前馈网络输出视觉特征。
对应的公式为:
其中 \(E \in \mathbb{R}^{(P^2 \cdot C \times D_v)}\) 和 \(E_{pos} \in \mathbb{R}^{N \times D_v}\) 分别表示图像块嵌入 (patch embedding) 和可学习的位置嵌入 (learnable position embedding),\(D_v\) 表示视觉编码器的隐藏层维度,\(\mathcal{I}nt(\cdot)\) 代表双线性插值。
\(\mathcal{P}roj(\cdot)\) 是投影层,\(\mathcal{F}FN(\cdot)\) 表示标准的前馈网络,\(L\) 表示编码器的层数。\(\mathbf{R}\)是二维旋转矩阵:
通过上述流程:无需固定图像输入尺寸,原生支持高分辨率图像(如1024px、2048px); 相比纯RoPE2D,数据效率更高(消融实验显示,C-ROPE在相同数据下性能提升显著)
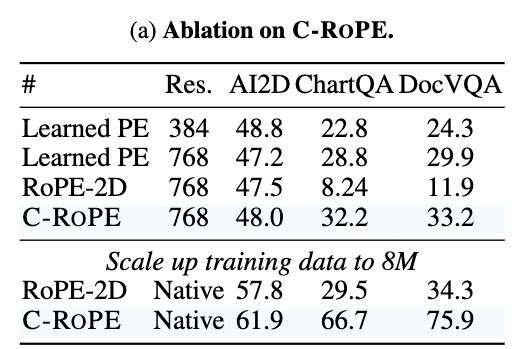
- Alignment Loss:跨模态表征对齐损失
传统方法通过适配器(Adapter)将视觉特征投影到语言空间,但监督信号(如next-token预测)过于间接,尤其是纯视觉预训练的VFMs(如DINOv2),表征差距难以缩小。Alignment Loss的核心是 直接对齐视觉与语言特征,且无需大batch或额外文本编码器。
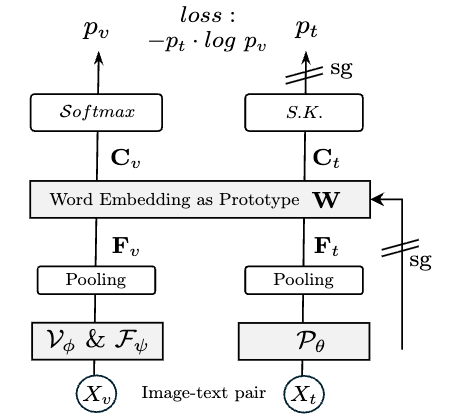
Alignment Loss的操作流程如上图所示:
提取全局特征:
- 视觉全局特征:对VFMs输出的视觉特征做无参数全局平均池化;
- 文本全局特征:对LLMs处理文本后的特征做全局平均池化(不含图像前缀,避免信息泄露);
原型映射:将视觉特征\(\mathbf{F}_v\)和文本\(\mathbf{F}_t\)特征通过LLM的词嵌入矩阵\(\mathbf{W}\in\mathbf{D_t\times K}\)(作为固定原型,不更新梯度)映射到语言空间,得到\(\mathbf{C}_v\)和\(\mathbf{C}_t\)(\(K\)为LLM词汇表大小);
软归一化:
- 视觉特征用Softmax归一化得到;
- 文本特征用 Sinkhorn-Knopp算法 归一化得到(利用词嵌入的先验分布,比Softmax更灵活);
- 交叉熵损失:计算和的交叉熵,仅更新VFMs参数(LLM参数冻结),确保视觉特征向语言空间对齐。
- 训练方法
- 阶段一:视觉-语言适配器预热。冻结 VFM 和 LLM,仅在固定低图像分辨率下训练适配器,且不使用 RoPE-2D。
- 阶段二:原生分辨率适应。使用 RoPE-2D 在固定高图像分辨率下训练整个模型一段时间,随后在原生分辨率下继续训练。
- 阶段三:指令微调(可选)。在原生分辨率下使用 RoPE-2D 对整个模型进行指令数据集的微调,以适应不同类型的数据输入。
训练目标
DeepStack
从代码来看Qwen3-vl这次的视觉模型去掉了window-attn操作 改成直接使用deepstack,也对其他参数做了一些更改比如patch_size 从14变为16, 并相应将模型变短变窄,缩小了整体模型的大小。
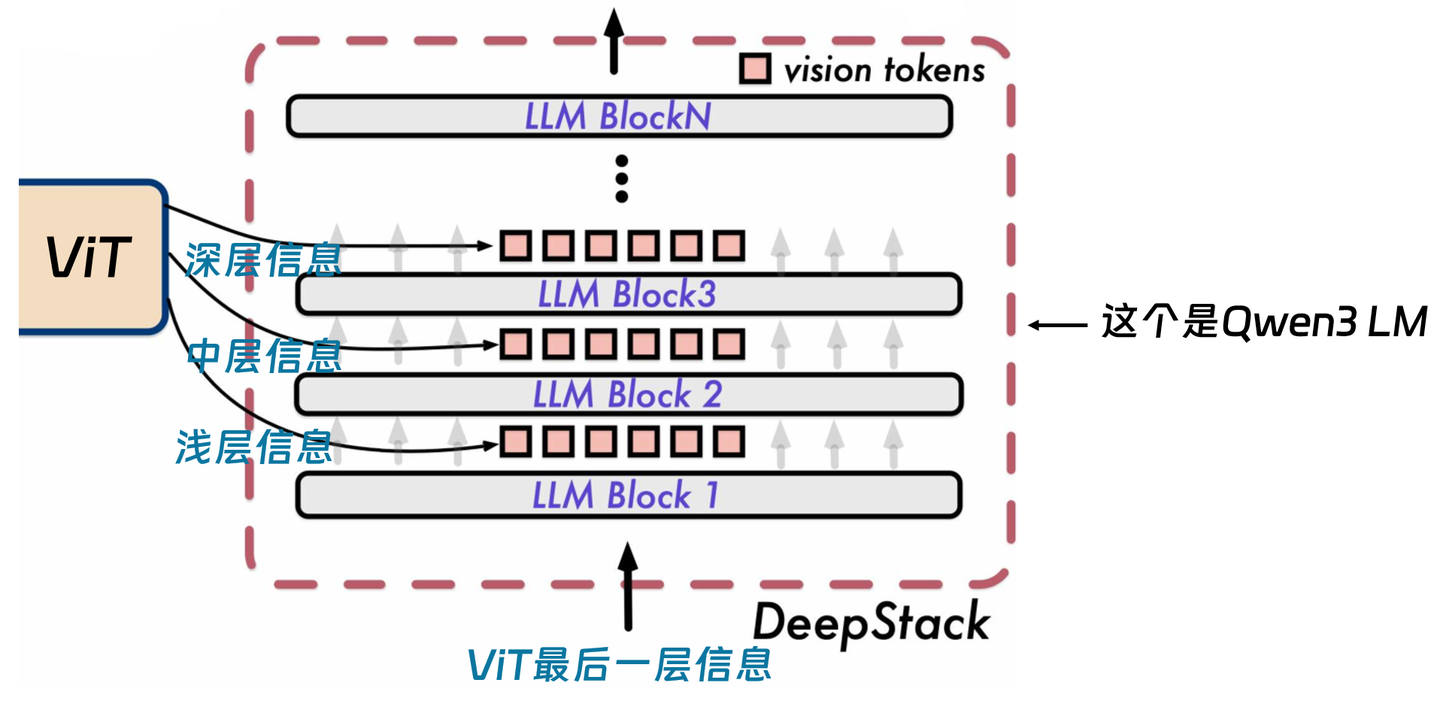
因为之前的所有输入token本身就是semantic level的特征,跟llm过几层transfomer就更high-level了,因此模型擅长做“整体识别”,但弱于细粒度理解(如“狗的左耳有缺口”)或空间推理(如“杯子在笔记本的右边”)。Qwen3-vl从 SigLIP-2 ViT 中选出 3 个不同深度的层(比如第 4 层、第 8 层、第 12 层)这些层分别代表:
- 浅层(early):低级特征(边缘、角点、颜色)
- 中层(middle):局部结构(部件、形状)
- 深层(late):高级语义(物体、场景、动作)
每个视觉层 → 专属两层 MLP → 输出与 LLM 隐藏维度对齐的视觉 token。
浅层视觉特征 → 加到 LLM 第 1 层 的 hidden state,中层视觉特征 → 加到 LLM 第 2 层,深层视觉特征 → 加到 LLM 第 3 层
(注意:是“加”(add),不是“拼接”(concat),所以不增加上下文长度)
def _deepstack_process(
self, hidden_states: torch.Tensor, visual_pos_masks: torch.Tensor, visual_embeds: torch.Tensor
):
visual_pos_masks = visual_pos_masks.to(hidden_states.device)
visual_embeds = visual_embeds.to(hidden_states.device, hidden_states.dtype)
local_this = hidden_states[visual_pos_masks, :].clone() + visual_embeds
hidden_states[visual_pos_masks, :] = local_this
return hidden_states
多模态位置编码
qwen3-vl相比qwen2-5vl 使用了时间戳来区分不同的时间步,每个时间戳包含着一个帧,所以处理起来跟处理图像的区别不大,也可以从下面的代码注释中看出区别
"""Different from the original implementation,
Qwen3VL use timestamps rather than absolute time position ids."""
# Since we use timestamps to seperate videos,
# like <t1> <vision_start> <frame1> <vision_end> <t2> <vision_start> <frame2> <vision_end>,
# the video_grid_thw should also be splitInterleaved MRoPE
之前的 Qwen2-VL 用了一种叫 MRoPE 的位置编码,把时间(\(t\))、水平(\(h\))、垂直(\(w\))分开编码。但qwen团队发现,这样做会导致频率谱不平衡,简单说就是模型在处理长视频时,对时间的感觉会变差。
Qwen3-VL 改用了 Interleaved MRoPE。和名字一样,就是:它把 \(t\), \(h\), \(w\) 的编码像洗牌一样均匀地插在了一起。这让模型在长达 256K 的上下文里,依然能精准地定位到“视频第 58 分钟左上角的那只猫”。
具体可以参考:多摸位置编码的进一步探索--MHRoPE / MRoPE-I
文本时间戳
Qwen2.5-VL 用绝对时间位置编码来告诉模型“这是第几秒”,mrope时间轴 position id 是这样来的:
- 用
fps / tokens_per_second / temporal_patch_size计算一个 interval - 每个 temporal patch 的 \(t\) 位置以 interval 为步长递增,比如 \(0, 50, 100, ...\)
- 这是把真实时间(秒)映射为RoPE 的 temporal position_id 数值(“与绝对时间绑定”)
形式上可以概括为:
这存在两个问题
- 长视频下 temporal position id 过大且稀疏(large & sparse)
当视频很长时,\(t_k\) 会变得非常大,并且相邻 patch 的 \(t\) 跳得很大(例如每次 +50、+100,甚至更大,取决于 fps/patch_size/tokens_per_second)。
- 分布外问题:训练时模型看到的 \(t\) 范围有限,推理长视频时 \(t\) 远超训练分布,RoPE 相位 \(\omega_i t\) 的统计特性变化,注意力对相对时间差的可泛化性变差。
- 稀疏刻度问题:当 \(t\) 的刻度被“按秒/按真实时间”强行拉开,模型需要靠 RoPE 的周期性相位去表达很大的时间差,容易出现混叠/难学(尤其在超长跨度、跨 patch 对齐时更明显)。
- 需要跨各种 fps 大量、均匀采样,数据构造成本高
因为 interval 里显式除以 fps:不同 fps 会导致 \(t\) 的标号尺度不同。要让模型“学会”在各种 fps 下都正确理解同样的真实时间差,你必须让训练数据覆盖:
- 多 fps 分布(1, 2, 5, 10, 25, 30, 60…)
- 并且覆盖要“均匀”才稳(否则模型在某些 fps 上会系统性偏差)
Qwen3-VL 不再把真实时间编码进 RoPE 的 temporal position_id 数值里,而是改成直接用纯文本来打标签,如:<4.0 seconds>。,训练时还混合生成两种格式:
- 秒格式:
< 3.0 seconds> - HMS 格式:
<01:02:03>
对应到 Qwen3-VL 注释 <t1> <vision_start> <frame1> <vision_end> <t2> <vision_start> <frame2> <vision_end>
这就是“把时间信息显式变成 token”,并且用这些 token 把视频段落切开,所以 video_grid_thw也要按段 split——因为每段 <vision_start>...<vision_end>对应一段独立的视觉网格。
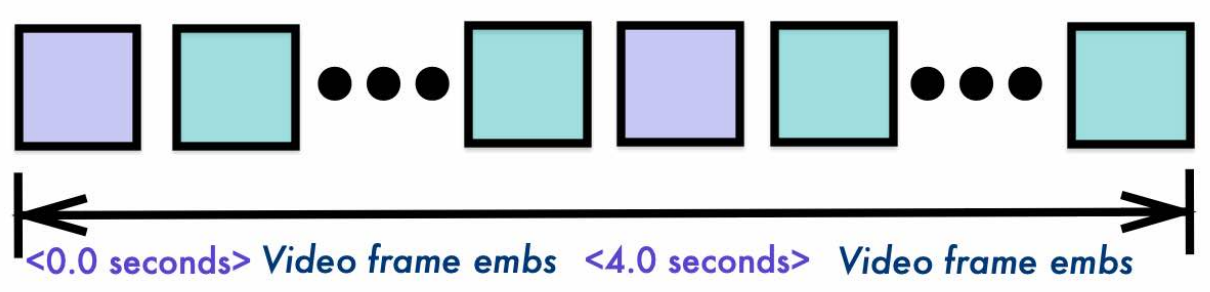
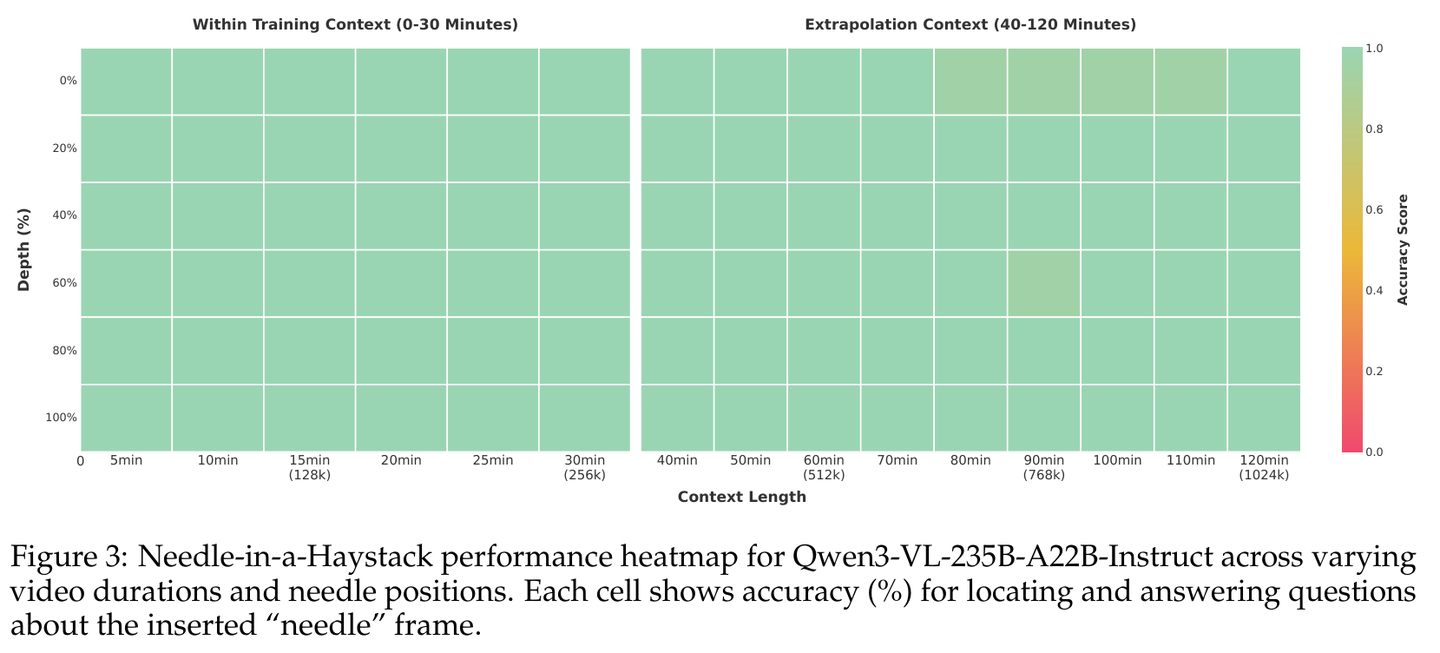
这就好比,与其给模型一个复杂的数学坐标,不如直接在画面上贴个便利贴写着“这是第 4 秒”。实验证明,这种贴便利贴的朴素方法效果拔群:在 256K 上下文(约30分钟视频)的大海捞针测试中,Qwen3-VL 实现了 100% 的帧定位准确率;即便外推到 1M 上下文(约2小时视频),准确率依然高达 99.5%。
模型训练
Pretrain
- 图文对与交错数据
图文对:通过 Qwen2.5-VL-32B 模型对原始图像文本重写生成更细粒度、流畅的描述;基于语义去重,结合视觉嵌入聚类进行稀疏区域数据增强
交错图文:从真实网页中采集中英文多模态文档,用轻量模型过滤低质内容(如广告);对书籍类数据,用 Qwen2.5-VL-7B 精确解析图文对齐,并拼接成最长 256K token 的序列,确保图文交互密度。
- 知识增强数据
构建涵盖动物、地标、食物等十余类实体的视觉知识库,采用重要性采样平衡高频与长尾实体,并用 LLM 生成富含属性、上下文和空间关系的增强描述。 - OCR 与文档理解
OCR:通过无监督伪标签流程,扩展至 39 种语言,构建 3000 万高质量多语言样本。
文档解析:从 Common Crawl 和内部收集 700 万 PDF,用布局模型预测阅读顺序,Qwen2.5-VL-72B 执行区域识别,输出支持 HTML(细粒度定位)和 Markdown(仅表格/图像定位)两种格式。
- 长文档理解:合成多页 PDF 序列,并构建跨页 VQA 数据,问题需融合图表、表格、正文等多元素进行多跳推理。
- 视觉定位与计数能力
这里专门说一下针对bbox/point坐标的格式,与 Qwen2.5-VL 不同的是,Qwen3-VL采用了缩放到范围 \([0, 1000]\) 的归一化坐标系版本。这种设计提高了对不同图像分辨率和纵横比变化的鲁棒性输入,同时还简化了后处理并增强了预测坐标的可用性下游应用。
- 坐标系:Qwen3-VL 的默认坐标系已从 Qwen2.5-VL 中使用的绝对坐标更改为 0 到 1000 范围内的相对坐标。(您不需要计算
resized_w) - 多目标定位:Qwen3-VL 提升了其多目标定位能力。
- 支持边界框和点两种定位方式。框定位融合 COCO、Objects365 等公开数据,并通过自动合成管道扩展;点定位结合 PixMo 和合成数据
- 计数任务包含直接计数、框内计数和点引导计数三种形式。
- 坐标系:Qwen3-VL 的默认坐标系已从 Qwen2.5-VL 中使用的绝对坐标更改为 0 到 1000 范围内的相对坐标。(您不需要计算
- 空间理解与 3D 感知
- 空间理解数据包含关系描述(如“杯子在笔记本左边”)、物体可操作性(如“可按压”)和动作规划问题,强调相对位置而非绝对坐标。
- 3D 定位数据基于单视角图像,提供 9 自由度 3D 边界框,并统一到虚拟相机坐标系;文本描述包含属性、布局、交互等细粒度信息。
- 代码能力
- 纯文本代码:复用 Qwen3-Coder 的大规模代码语料
- 多模态代码:涵盖 UI 转 HTML/CSS、图像转 SVG、可视化编程题、带图的 StackOverflow 问答、图表转 LaTeX 等任务,实现视觉到可执行代码的映射。
- 视频理解
- 采用“由短到长”的密集字幕合成策略,生成带时间戳的连贯故事描述;构建时空定位数据,标注对象、动作和人物。
- 视频来源覆盖教学、电影、第一人称视角等,通过元数据平衡类别;训练时动态调整采样帧率和最大帧数,适应不同上下文长度。
- STEM 推理
- 视觉感知:程序化生成 100 万点定位样本和 200 万 VQA 对,覆盖几何图;通过两阶段 LLM 校验生成 600 万高质量图注。
- 多模态推理:清洗 6000 万 K–12 至大学习题,标准化答案格式;合成 1200 万带图的长思维链样本,仅保留经验证的高难度问题。
- 语言推理:复用 Qwen3 的纯文本推理数据作为基础。
- 智能体能力
- GUI 交互:构建跨平台(桌面/手机/Web)界面理解数据,包括元素描述、密集定位;通过自演进轨迹生成多步操作序列,并人工审核。
- 函数调用:设计多模态函数调用轨迹合成流程,无需真实执行函数即可生成大规模调用样本。
- 搜索能力:收集带图像/文本搜索工具的多模态事实查询轨迹,训练模型主动检索网络信息以回答长尾问题。
Post Training
后训练被设计为一个三阶段的流水线:
- 第一阶段:监督微调(SFT)。赋予模型基础的指令跟随能力并激活潜在推理能力。训练分为两个步骤:先在32k上下文长度下训练,随后扩展到256k以处理长文档和长视频。数据被分为“普通模式”和显式建模推理过程的“思维链(CoT)模式”。
- 第二阶段:强弱蒸馏(Strong-to-Weak Distillation)。利用强大的教师模型通过纯文本数据对学生模型的Backbone进行微调,有效提升文本和多模态任务中的推理能力。
- 第三阶段:强化学习(RL)。分为“推理RL”和“通用RL”,在大规模文本和多模态领域(如数学、OCR、Grounding)上进一步提升细粒度能力。
在监督微调(SFT)阶段,研究人员不仅是简单地喂数据,而是设计了一套复杂的课程学习(Curriculum Learning)和双重过滤机制。
- SFT
- 数据总量约 120 万样本,其中 1/3 为纯文本,2/3 为图文或视频-文本对,覆盖中英为主、多语言为辅的语种。
- 包含单轮与多轮对话,并设计交错图文样本以支持工具调用、图像搜索等智能体行为。
- 针对 256K 长上下文能力,采用两阶段训练:先在 32K 上跑一个 epoch,再在 256K 上训练,后者混合长上下文(如整本教材、2 小时视频)与 32K 数据以提升效率。
- SFT数据的微观构成(约120万条):
- 数据包含专门设计的交错图文(Interleaved image-text)样本,这是为了支持复杂的Agent行为,例如“工具增强的图像搜索”。
- 不仅有单图,还特意包含了多图序列,以模拟真实环境下的多轮对话动态。
- 双重数据过滤机制:
- 查询过滤:用 Qwen2.5-VL 识别不可验证或模糊查询,仅保留复杂度适中、语义清晰的样本;
- 回答过滤:
- 规则过滤:剔除重复、不完整、格式错误或有害内容;
- 模型过滤:用 Qwen2.5-VL 系列奖励模型从正确性、完整性、清晰度、视觉信息利用等维度评分,识别语言混杂、风格突变等细微问题。
- Strong-to-Weak Distillation
- Off-policy Distillation:
在第一阶段,由强教师模型(如大参数量的 Qwen3)对输入提示生成回答,这些回答被用作监督信号来训练轻量级的学生模型。此过程不依赖学生模型自身的输出,而是直接利用教师模型的高质量响应,帮助学生模型掌握基础的推理能力和知识表达,为后续训练打下坚实基础。 - On-policy Distillation:
在第二阶段,学生模型根据输入提示自主生成回答,再将这些回答与教师模型在相同提示下的输出进行对齐。具体做法是最小化学生模型与教师模型预测 logits 之间的 KL divergence,从而让学生的输出分布逼近教师的输出分布。这一阶段使学生模型不仅模仿结果,还能内化教师的推理风格和决策逻辑,提升泛化能力与一致性。
- Off-policy Distillation:
整体而言,该蒸馏流程结合了静态知识迁移与动态行为对齐,有效将大规模模型的能力高效迁移到小型模型中,这一版只tune LLM。
- Long-CoT冷启动数据
- 数据中图文与纯文本比例约为 1:1,重点强化 STEM 与智能体工作流任务。
- 实施三重筛选:
- 难度筛选:保留基线模型通过率低、回答更长的难题;
- 多模态必要性筛选:剔除无需图像即可由 Qwen3-30B-nothink 正确解答的题目,确保任务真正依赖视觉输入;
- 回答质量控制:去除错误答案、无推理过程、语言混杂或重复冗余的样本。
- 推理型强化学习(Reasoning RL)
- 任务覆盖数学、编程、逻辑、视觉谜题等,所有答案均可通过规则或代码执行器确定性验证。
- 数据准备:
- 使用 Qwen3-VL-235B-A22B 初版模型为每条查询生成 16 个回答,仅保留至少有一个正确回答的查询;
- 剔除改进潜力低的数据源,最终保留约 3 万条 RL 查询;
- 训练时过滤通过率 >90% 的简单样本,并按任务比例混合构建批次。
- 奖励系统:
- 统一框架支持多任务,任务专用提示确保输出格式合规,避免依赖格式奖励;
- 若回答语言与提问语言不一致,施加惩罚以抑制语言混杂。
- 算法:采用 SAPO(Smooth and Adaptive Policy Optimization)算法,在不同模型规模和架构上均表现稳定。
- 通用强化学习(General RL)
- 目标:提升泛化能力、纠正 SFT 阶段形成的错误先验、抑制不良行为(如语言混杂、重复、格式错误)。
- 双维度优化:
- 指令遵循:评估对内容、格式、长度、结构化输出(如 JSON)等约束的满足程度;
- 偏好对齐:在开放性任务中优化有用性、事实准确性与风格适切性。
- 错误纠正策略:
- 构建专门数据集,包含易引发错误的样本(如反直觉计数、复杂钟表识别),通过 RL 覆盖错误认知;
- 针对低频不良行为,构造高密度触发样本,施加高频惩罚以高效抑制。
- 混合奖励机制:
- 规则奖励:用于可验证任务,提供高精度、抗“奖励欺骗”的反馈;
- 模型奖励:由 Qwen2.5-VL-72B-Instruct 或 Qwen3 作为评判模型,多维度打分,避免因格式非常规而误判有效回答。
- Thinking with Images智能体训练
- 采用两阶段范式训练具备工具调用与环境交互能力的视觉智能体:
- 第一阶段:合成约 1 万条简单两轮 VQA 任务(如属性识别),在 Qwen2.5-VL-32B 上进行 SFT,模拟“思考→行动→分析反馈→作答”流程,并辅以多轮工具集成 RL。
- 第二阶段:将训练好的智能体蒸馏为约 12 万条多轮交互数据,用于 Qwen3-VL 的后训练。
- RL 奖励信号:
- 答案准确奖励:由 Qwen3-32B 判断最终答案是否正确;
- 多轮推理奖励:由 Qwen2.5-VL-72B 评估是否合理利用工具反馈并进行连贯推理;
- 工具调用奖励:将实际调用次数与专家预估目标(由 Qwen2.5-VL-72B 离线生成)对比,鼓励任务自适应的工具探索。
- 为防止模型“偷懒”仅调用一次工具以满足前两项奖励,显式引入工具调用奖励以对齐任务复杂度。
- 采用两阶段范式训练具备工具调用与环境交互能力的视觉智能体:
一些实验结论
- 小模型表现超预期,甚至超越 GPT-5-nano Qwen3-VL 的 2B、4B、8B 等小型模型不仅全面领先同类规模模型,还在不少任务上显著优于 OpenAI 的 GPT-5-nano(推测为轻量级闭源模型)。
- 工具调用带来的增益超过单纯扩大模型规模 在细粒度感知任务(如 V∗、HRBench)上,即使使用相同规模的模型,引入外部工具(如高分辨率图像处理工具)后性能提升约 5 个百分点,这一提升幅度甚至大于从 8B 扩展到 32B 带来的收益。
- 3D 与空间理解能力达到顶尖水平 在 Omni3D 等 3D 定位基准上,Qwen3-VL 系列模型全面超越 Gemini-2.5-Pro 等竞品。例如,在 SUN RGB-D 数据集上,Qwen3-VL-235B-Thinking 比 Gemini-2.5-Pro 高出 5.2 个百分点。其空间理解能力也体现在 Embodied AI 任务中,如在 RoboSpatialHome 上得分 73.9,接近人类水平。
- 视频理解能力随上下文长度显著增强 得益于 256K 超长上下文支持,Qwen3-VL 在长视频任务(如 MLVU、LVBench)上表现优异。即使对比仅支持数百帧输入的竞品(如 GPT-5 限 256 帧),Qwen3-VL 能处理长达 2 小时的视频(约 100 万 token),并在长视频理解任务中反超。
- 视觉-语言模型也能在纯文本任务上媲美大语言模型 在纯文本任务(如 MMLU-Pro、AIME-25、LiveCodeBench)上的表现与同规模纯文本大模型 Qwen3 相当,甚至在数学和编程上更优。这证明其成功实现了视觉与语言能力的深度融合,未因多模态设计牺牲语言能力。
- 轻量模型通过蒸馏实现高效迁移 通过“强到弱蒸馏”策略,Qwen3-VL-2B/4B/8B 等小模型在各项任务上显著优于同规模纯文本基线。例如,Qwen3-VL-4B 在 AIME-25 上得分 46.6,而 Qwen3-4B 仅为 19.1。这表明蒸馏能有效将多模态能力迁移到小模型,极大降低部署成本。
- 视觉编码器与 DeepStack 架构有效提升性能 消融实验表明,新设计的 Qwen3-ViT 视觉编码器在知识密集型任务(如 OmniBench)上明显优于 SigLIP-2;而 DeepStack 融合机制在文档理解(DocVQA、InfoVQA)等细粒度任务上带来稳定提升,证明架构创新切实有效。