Focal Loss
在早期的目标检测中,最头疼的问题是正负样本极度不平衡(背景太多,物体太少),且大量背景是“容易分类的负样本”。传统的交叉熵损失(BCE)会被这些海量的简单样本淹没。
为了解决这个问题,Focal Loss (FL) 引入了一个动态缩放因子:
- 对于正样本,损失大致为:\(-(1-p)^\gamma \log(p)\)
- 核心逻辑: 如果模型已经预测得很准了(概率 \(p\) 接近 \(1\)),那么 \((1−p)^\gamma\)就会趋近于 \(0\),从而降低简单样本的权重,强迫模型去关注那些还没学好的“困难样本”。
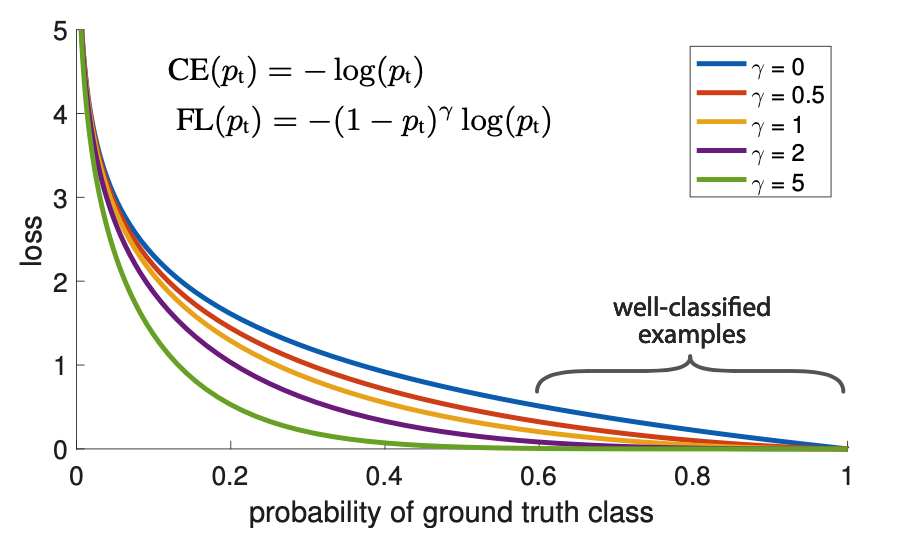
focal loss 形式如下
GFL(Generalized Focal Loss)
论文地址:arxiv.org/pdf/2006.04388.pdf
源码和预训练模型地址:github.com/implus/GFocal
MMDetection官方收录地址:github.com/open-mmlab/mmdetection/blob/master/configs/gfl/README.md
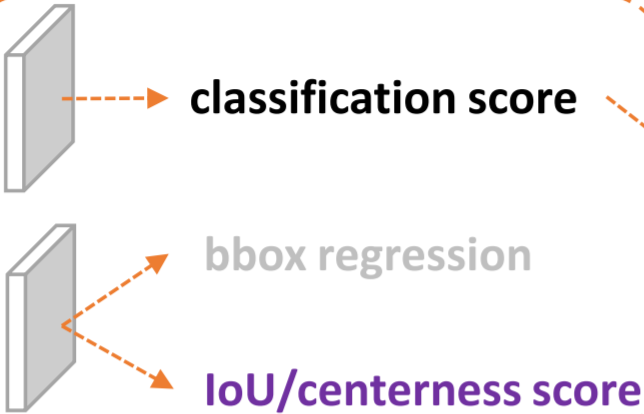
这个工作核心是围绕“表示”的改进来的,也就是大家所熟知的“representation”这个词。这里的表示具体是指检测器最终的输出,也就是head末端的物理对象,目前比较强力的one-stage anchor-free的检测器(以FCOS,ATSS为代表)基本会包含3个表示:
- 分类表示
- 检测框表示
- 检测框的质量估计(在FCOS/ATSS中,目前采用centerness,当然也有一些其他类似的工作会采用IoU,这些score基本都在0~1之间)
三个表示一般情况下如图所示:
那么要改进表示一定意味着现有的表示或多或少有那么一些问题。事实上,我们具体观察到了下面两个主要的问题:
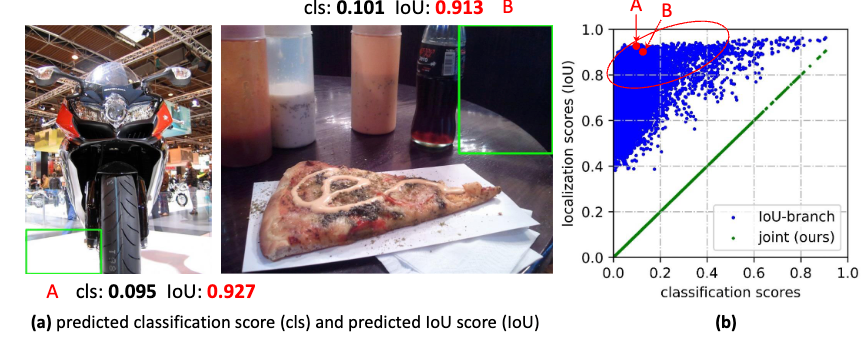
- 问题一:classification score 和 IoU/centerness score 训练测试不一致。
这个不一致主要体现在两个方面:
- 用法不一致。训练的时候,分类和质量估计各自训自己的,但测试的时候却又是乘在一起作为NMS score排序的依据,这个操作显然没有end-to-end,必然存在一定的gap。
- 对象不一致。借助Focal Loss的力量,分类分支能够使得少量的正样本和大量的负样本一起成功训练,但是质量估计通常就只针对正样本训练。那么,对于one-stage的检测器而言,在做NMS score排序的时候,所有的样本都会将分类score和质量预测score相乘用于排序,那么必然会存在一部分分数较低的“负样本”的质量预测是没有在训练过程中有监督信号的,也就是说对于大量可能的负样本,他们的质量预测是一个未定义行为。这就很有可能引发这么一个情况:一个分类score相对低的真正的负样本,由于预测了一个不可信的极高的质量score,而导致它可能排到一个真正的正样本(分类score不够高且质量score相对低)的前面。问题一如图所示:
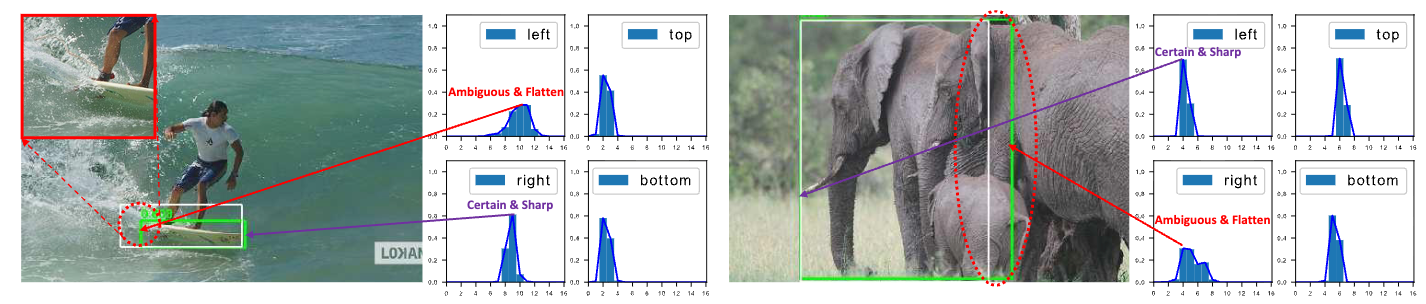
- 问题二:bbox regression 采用的表示不够灵活,没有办法建模复杂场景下的uncertainty。
问题二比较好理解,在复杂场景中,边界框的表示具有很强的不确定性,传统的回归模型把目标标签 \(y\) 看作是 Dirac delta 分布。这意味着模型认为物体的边界就在某个绝对精确的点上,100% 确定,其他任何位置的概率都是 0。而现实图片中,物体的边界往往是模糊的(比如大象的毛发、被遮挡的汽车边缘)。强迫模型输出一个绝对确定的死板数值,不仅违背直觉,还会让模型在遇到模糊边界时感到“困惑”,难以收敛。我们希望用一种general的分布去建模边界框的表示。问题二如图所示(比如被水模糊掉的滑板,以及严重遮挡的大象):
主要方法
那么有了这些问题,我们自然可以提出一些方案来一定程度上解决他们:
- 对于第一个问题,为了保证training和test一致,同时还能够兼顾分类score和质量预测score都能够训练到所有的正负样本,那么一个方案呼之欲出:就是将两者的表示进行联合。这个合并也非常有意思,从物理上来讲,我们依然还是保留分类的向量,但是对应类别位置的置信度的物理含义不再是分类的score,而是改为质量预测的score。这样就做到了两者的联合表示,同时,暂时不考虑优化的问题,我们就有可能完美地解决掉第一个问题。
- 对于第二个问题,我们选择直接回归一个任意分布来建模框的表示。当然,在连续域上回归是不可能的,所以可以用离散化的方式,通过softmax来实现即可。

Ok,方案都出来了还算比较靠谱,但是问题又来了:怎么优化他们呢?
这个时候就要派上Generalized Focal Loss出马了。我们知道之前Focal Loss是为one-stage的检测器的分类分支服务的,它支持0或者1这样的离散类别label。然而,对于我们的分类-质量联合表示,label却变成了0~1之间的连续值。我们既要保证Focal Loss此前的平衡正负、难易样本的特性,又需要让其支持连续数值的监督,自然而然就引出了我们对Focal Loss在连续label上的拓展形式之一,我们称为Quality Focal Loss (QFL),具体地,它将原来的Focal Loss 从 (1)改为:
其中\(y\)为\(0\sim 1\)的质量标签,\(\sigma\)为预测。注意QFL的全局最小解即是\(\sigma = y\)。这样交叉熵部分变为完整的交叉熵,同时调节因子变为距离绝对值的幂次函数。和Focal Loss类似,我们实验中发现一般取\(\beta = 2\)为最优。
对于传统的回归模型把目标标签 \(y\) 看作是 Dirac delta 分布:
为了解决这个边界模糊的问题,作者提出:不要让模型死磕一个具体的值,而是让它输出一个连续概率分布 \(P(x)\):
但由于神经网络无法直接输出无限连续的积分,作者做了一个非常聪明的离散化(Discretization)操作:
- 画格子: 把可能的坐标范围 \([y_0, y_n]\) 切分成一个个间隔为 \(\Delta=1\) 的离散“格子”(比如坐标从 0 到 10,分成 0, 1, 2...10)。
- 算概率:让模型通过一个 Softmax 层,预测边界落在每一个格子里的概率 \(P(y_i)\)(截图中简写为 \(S_i\))。
- 求期望:最终模型预测的坐标 \(\hat{y}\),就是所有格子坐标乘以对应概率的加权和(期望值)。
对于任意分布来建模框的表示,它可以用积分形式嵌入到任意已有的和框回归相关的损失函数上,例如最近比较流行的GIoU Loss。这个实际上也就够了,不过涨点不是很明显,作者又仔细分析了一下,发现如果分布过于任意,网络学习的效率可能会不高,原因是一个积分目标可能对应了无穷多种分布模式。如下图所示:
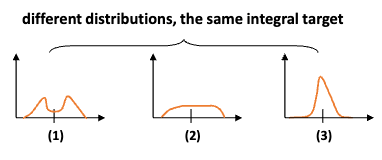
考虑到真实的分布通常不会距离标注的位置太远,所以又额外加了个loss,希望网络能够快速地聚焦到标注位置附近的数值,使得他们概率尽可能大。基于此,我们取了个名字叫Distribution Focal Loss (DFL):
其形式上与QFL的右半部分很类似,含义是以类似交叉熵的形式去优化与标签\(y\)最接近的一左一右两个位置的概率,从而让网络快速地聚焦到目标位置的邻近区域的分布中去。
最后,QFL和DFL其实可以统一地表示为GFL,我们将其称之为Generalized Focal Loss,同时也是为了方便指代,它不仅能用于坐标回归,还能用于分类分数的预测。为了让模型在预测时既能“找得准”又能“分得清”,GFL 在交叉熵的基础上,引入了一个动态缩放因子(Modulating Factor):\(|y - \hat{y}|^\beta\)。其具体形式如下:
- 预测值 \(\hat{y}\):即 \(y_l p_{y_l} + y_r p_{y_r}\),表示模型当前算出来的期望值。
- 缩放因子 \(|y - \hat{y}|^\beta\):这是 Focal Loss 家族的灵魂!如果模型预测的 \(\hat{y}\) 距离真实标签 \(y\) 还很远,这个因子就会变大,强迫模型加大力度学习;如果已经预测得很准了,这个因子就会趋近于 \(0\),让模型去关注其他没学好的样本。
- 后面的交叉熵部分: 依然是按照距离真实值 \(y\) 的远近,对左右两个概率 \(p_{y_l}\) 和 \(p_{y_r}\) 进行交叉熵惩罚。
作者证明了,当 GFL 达到全局最小值时,模型预测的概率会自动收敛到最优解:\(p_{y_l}^* = \frac{y_r - y}{y_r - y_l}\) 以及 \(p_{y_r}^* = \frac{y - y_l}{y_r - y_l}\)
这意味着,模型最终输出的期望值 \(\hat{y}\) 会100% 完美匹配真实的连续标签 \(y\)。更厉害的是,早期的 Focal Loss (FL)、质量焦点损失 (QFL) 和分布焦点损失 (DFL),在数学上全都是 GFL 的特例.
最终训练密集型目标检测器的总损失函数:
公式拆解:
- \(\mathcal{L}_{\mathcal{Q}}\) (QFL):负责分类分支的损失,让模型学会认出物体并评估预测框的质量。所有位置 $$z$$ 都要计算。
- \(\mathcal{L}_{\mathcal{B}}\) (GIoU Loss):传统的边界框损失,确保预测框整体和真实框的重合度。
- \(\mathcal{L}_{\mathcal{D}}\) (DFL):我们前面详细讲过的分布焦点损失,负责把边界框的概率分布捏得更紧凑、更精准。
- 指示函数 \(\mathbf{1}_{\{c_z^* > 0\}}\):这是一个开关。它表示 GIoU 和 DFL 这两个回归损失,只对正样本(包含物体的区域)计算。背景区域不需要算边界框损失。
- \(\lambda_0, \lambda_1\):用于平衡这三项损失的权重系数(通常 GIoU 权重给 \(2\),DFL 权重给 \(\frac{1}{4}\))。
这个损失将分类、传统的框回归和分布回归巧妙地结合在了一起。
实验
最后是实验。Ablation Study就不展开了,重点的结论即是:
- 这两个方法,即QFL和DFL的作用是正交的,他们的增益互不影响,所以结合使用更香(我们统一称之为GFL)。我们在基于Resnet50的backbone的ATSS(CVPR20)的baseline上1x训练无multi-scale直接基本无cost地提升了一个点,在COCO validation上从39.2 提到了40.2 AP。实际上QFL还省掉了原来ATSS的centerness那个分支,不过DFL因为引入分布表示需要多回归一些变量,所以一来一去inference的时间基本上也没什么变化。
- 在2x + multi-scale的训练模式下,在COCO test-dev上,Resnet50 backbone用GFL一把干到了43.1 AP,这是一个非常可观的性能。同时,基于ResNeXt-101-32x4d-DCN backbone,能够有48.2的AP且在2080Ti单GPU上有10FPS的测速,还是相当不错的speed-accuracy trade-off了。
最后,附录里面其实有不少彩蛋。
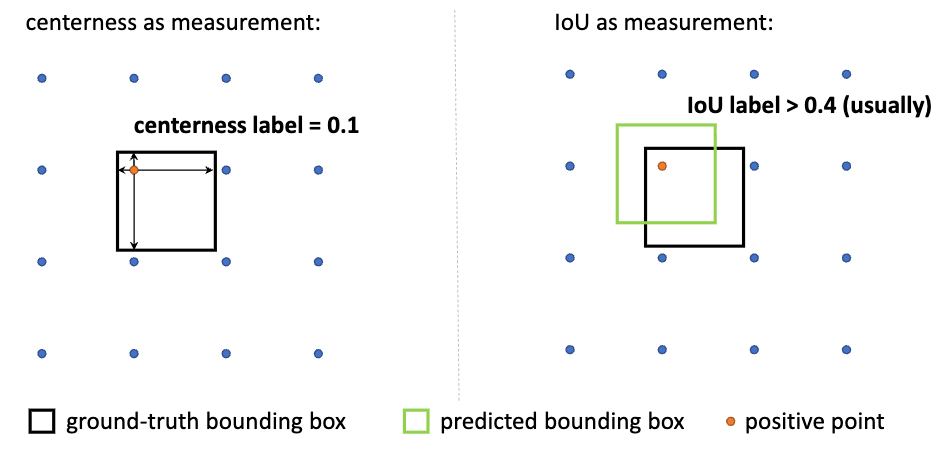
第一个彩蛋是关于IoU和centerness的讨论。在对比实验中,我们发现IoU作为框预测质量的度量会始终比centerness更优。于是我们又具体深入分析了一些原因,发现的确从原理上来讲,IoU可能作为质量的估计更加合适。具体原因如下:
- IoU本身就是最终metric的衡量标准,所以用来做质量估计和排序是非常自然的。
- centerness有一些不可避免的缺陷,比如对于stride=8的FPN的特征层(也就是P3),会存在一些小物体他们的centerness label极度小甚至接近于0,如下图所示:
而IoU就会相对好很多。我们也统计了一下两者作为label的分布情况,如图:
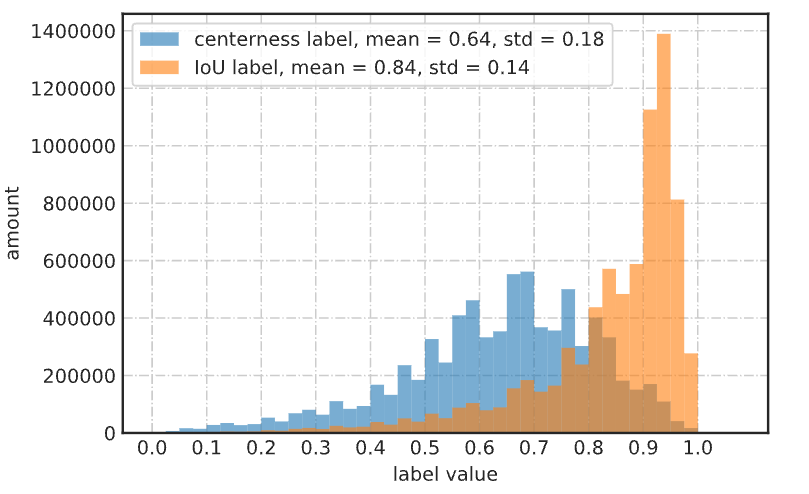
这意味着IoU的label相对都较大,而centerness的label相对都较小,同时还有非常非常小的。可以想见,如果有一些正样本的centerness的label本身就很小,那么他们最后在做NMS排序的时候,乘上一个很小的数(假设网络学到位了),那么就很容易排到很后面,那自然性能就不容易上去了。所以,综合各种实验以及上述的分析,个人认为centerness可能只是一个中间产物(当然,其在FCOS中提出时的创新性还是比较valuable的),最终历史的发展轨迹还是要收敛到IoU来。
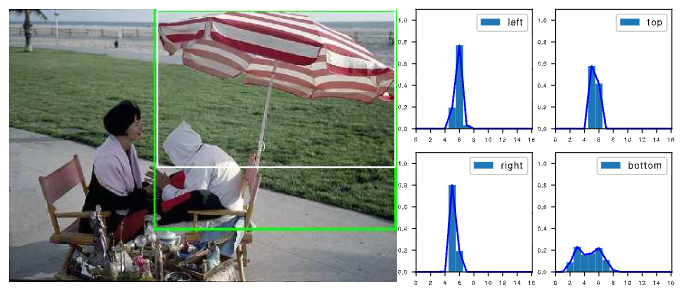
第二个彩蛋是分布式表示的一些有趣的观察。我们发现有一些分布式表示学到了多个峰。比如伞这个物体,它的伞柄被椅子严重遮挡。如果我们不看伞柄,那么可以按照白色框(gt)来定位伞,但如果我们算上伞柄,我们又可以用绿色框(预测)来定位伞。在分布上,它也的确呈现一个双峰的模式(bottom),它的两个峰的概率会集中在底部的绿线和白线的两个位置。这个观察还是相当有趣的。这可能带来一个妙用,就是我们可以通过分布shape的情况去找哪些图片可能有界定很模糊的边界,从而再进行一些标注的refine或一致性的检查等等。颇有一种Learn From Data,再反哺Data的感觉。
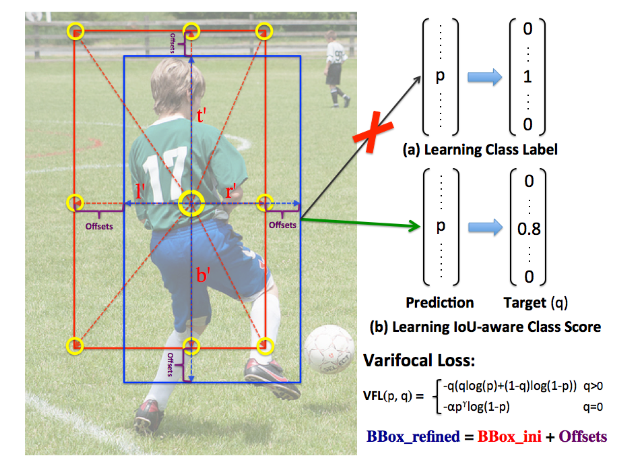
VarifocaLoss
论文名称:VarifocalNet: An IoU-aware Dense Object Detector
本文从fcos和atss存在的分类和回归分支不一致性问题出发,对推理过程进行详细分析,指出目前目标检测最大瓶颈依然是分类分支和回归分支分值不一致问题。虽然Generalized Focal Loss在atss基础上进一步缓解了该问题,但是或许有更好的解决办法,为此作者提出了两个改进:
- 提出了正负样本不对称加权的 Varifocal Loss
- 借助dcn思想,提出星型bbox特征提取refine网络,对atss的输出初始bbox进行refine
纵观全文,这篇论文和Generalized Focal Loss非常相似,不仅仅算法出发点类似,做法也类似,当然本文的改进也值得进行分析解读。
为了引出本文观点,作者对atss的推理过程进行了详细分析,如下所示:
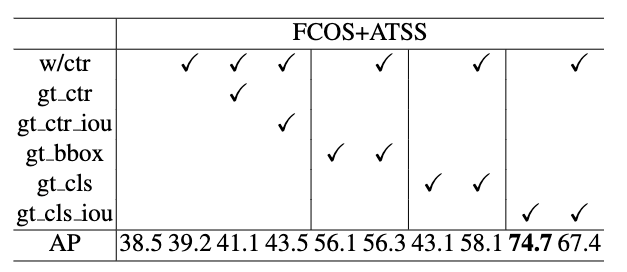
这副图才是本文最大亮点,值得深入思考,至于改进好像也没有特别大,性能也没有提升多少。
首先作者以ATSS算法为例,ATSS结构和FCOS完全相同,只不过在正负样本定义阶段引入了自适应策略而已,差别不大。
- 在没有centerness分支时候训练atss,其map是38.5,训练时候加入centerness即w/ctr(标准结构)从而得到39.2,此时baseline设置为39.2。
- gt_ctr是指在baseline基础上,测试时候把centerness分支替换为对应label值,可以发现map仅仅提高到41.1。
从以上两点分析可以说明centerness的作用其实非常不明显,引入这个额外分支最多也是从38.5提升到41.1,划不来。虽然分类和回归分支不一致性问题得到缓解,但是仅仅解决了一点点而已。
- 如果将centerness分支的输出变成预测bbox和gt bbox的iou值(gt_ctr_iou),也就是常说的iou感知分支,此时map是43.5。从这个角度来看,使用iou分支代替centernss是更好的,在Generalized Focal Loss中反映过这个问题,但是依然提升不大。
- 假设预测bbox回归分支值全部替换为真实gt bbox,在使用还是不使用centerness分支的时候,map没有很大改变。为啥全部替换为gt bbox,其map提升没有想象中的大?这很说明问题:影响mAP性能的主要因素不是bbox预测不准确,而在于分类分支,同时这个实验也可以看出centerness的作用非常微弱。
- 如果将分类分支的输出中,对应真实类别设置为1,也就是类别预测完全正确(gt_cls),此时map是43.1,加入centernes后提升到58.1,这也间距验证了(4)的说法,同时也说明nms排序分值非常重要,在类别预测完全正确的情况下,centerness可以在一定程度上区分准确和不准确的边界框。
- 惊奇的是:如果把分类分值的输出中,对应真实类别设置为预测bbox和真实bbox的iou(gt_cls_iou),那么即使不用centernss,也可以达到74.7,非常高,用于centerness还稍有下降。这其实很说明问题:目前的目标检测bbox分支输出的密集bbox中其实存在非常精确的预测框,关键是没有好的预测分值来选择出来,也就是Generalized Focal Loss中提到的如何加强分类分支和bbox分支一致性的问题。采用centerness分类分值的做法提升非常有限,最合适的做法就是将分类分支对应类别预测值中能够同时反映出物体类别和物体预测准确度,此时理论上限最高。
通过上述分析,本文目标就是要实现分类分支同时包含物体类别和物体预测准确度的功能,当然Generalized Focal Loss也是这样做的。通过上述分析,我们可以总结下:
- centernss作用还不如iou分支
- 单独引入一条centernss或者iou分支,作用非常有限
- 目前目标检测性能瓶颈不在于bbox预测不准确,而在于没有一致性极强的分值排序策略选择出对应bbox
- 将iou感知功能压缩到分类分支中是最合适的,理论mAP上限最高。
算法改进
在分析这个loss前,我们先回顾下Generalized Focal Loss做法, 如上文(1),(2)
其中\(y\)为\(0\sim 1\)的质量标签,来自预测的bbox和gt bbox的iou值,注意如果是负样本,则y直接等于0, \(\sigma\) 是分类分支经过sigmoid后的预测值。可以发现广义focal loss将focal loss只能支持离散label的限制推广到了连续label,并且强制将分类分支对应类别处的预测值变成了包括bbox预测准确度。
而本文的Varifocal Loss主要改进是提出了非对称的加权操作,focal loss和Generalized Focal Loss都是对称的。而非对称加权的思想来源于论文PISA,该论文指出首先正负样本有不平衡问题,即使在正样本中也存在不等权问题,因为mAP的计算是看主样本的。基于这些思想,作者的Varifocal Loss定义如下:
\(q\)是label,正样本时候\(q\)为预测bbox和gt bbox的iou,负样本时候\(q=0\),当为正样本时候其实没有采用focal loss,而是普通的bce loss,只不过多了一个自适应iou加权,用于突出主样本。而为负样本时候就是标准的focal loss了。可以明显发现本文所提Varifocal Loss比Generalized Focal Loss更加简单,主要特点是正负样本非对称加权、突出正样本的主样本。
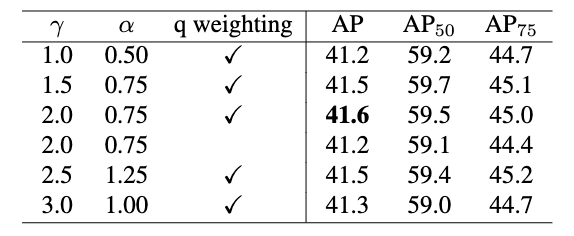
可以看出,虽然上述思想是很不错的,但是好像也没有提升多少。
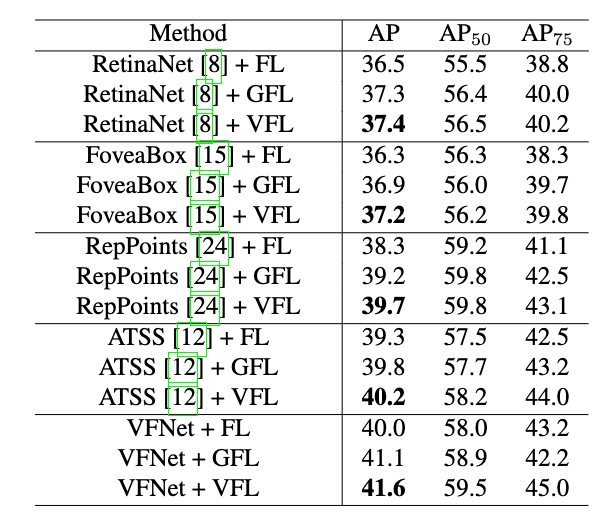
相比Generalized Focal Loss会好一点点的。
除了上面改进后,本文还提出bbox refinement思想,进一步提高性能。其整个网络结构如下:
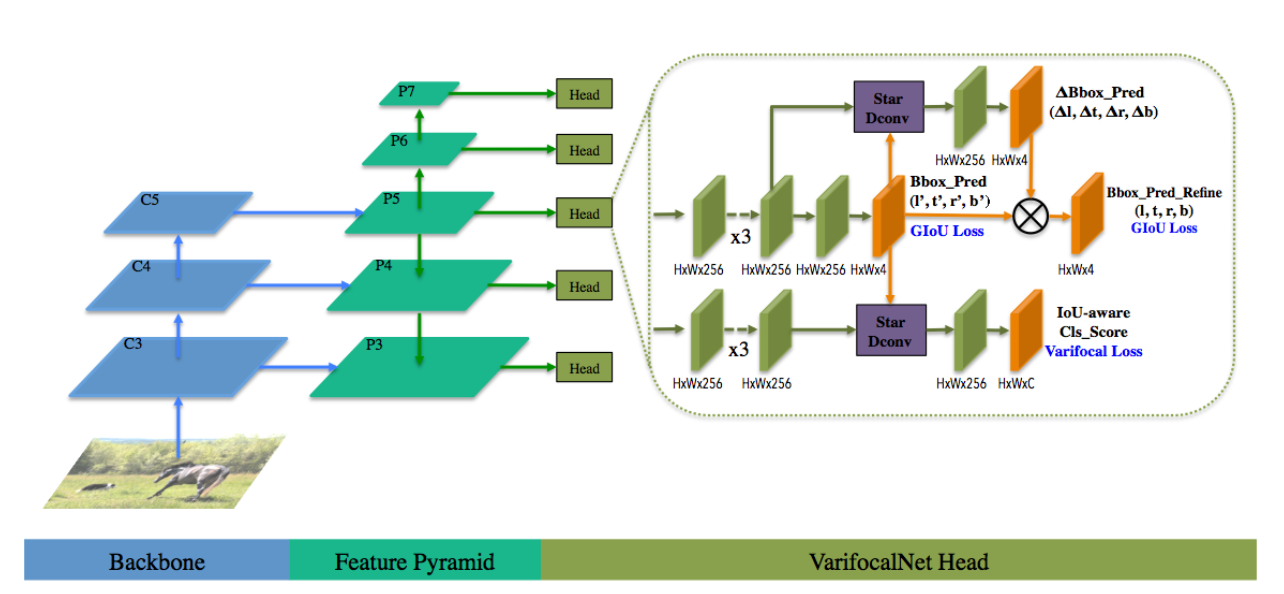
可以发现,和fcos的区别是:
- 不需要centerness分支
- 多了星型bbox特征提取和refine操作
其基本流程是:
- 任何一个head,对分类和回归分支特征图堆叠一系列卷积,输出通道全部统一为256
for cls_layer in self.cls_convs:
cls_feat = cls_layer(cls_feat)
for reg_layer in self.reg_convs:
reg_feat = reg_layer(reg_feat)- 对回归分支特征图进行回归预测,得到初始bbox预测值,输出通道是4,代表lrtb预测值,然后对预测值进行还原得到原图尺度的lrtb值
reg_feat_init = self.vfnet_reg_conv(reg_feat)
if self.bbox_norm_type == 'reg_denom':
# 默认
bbox_pred = scale(
self.vfnet_reg(reg_feat_init)).float().exp() * reg_denom- 利用lrtb预测值对每个特征图上面点生成9个offset坐标,示意图如下:
红色是(2)步骤在某个特征图点上生成的bbox坐标,然后利用\((x, y)\), \((x-l^{'}, y)\), \((x, y-t^{'})\),\( (x+r^{'}, y)\), \((x, y+b^{'})\), \((x-l^{'}, y-t^{'})\),\((x+l^{'}, y-t^{'})\), \((x-l^{'}, y+b^{'})\) 和 \((x+r^{'}, y+b^{'})\),得到9个采样点的浮点offset,此时每个特征图上面点都会得到9个新的浮点offset
dcn_offset = self.star_dcn_offset(bbox_pred, self.gradient_mul, stride)- 将offset作为变形卷积的offset输入,然后进行dcn操作,此时每个点的特征感受野就可以和初始时刻预测值重合,也就是常说的特征对齐操作,方便refine,此时就得到了refine后的bbox预测输出值,需要特别注意的是refine分支输出值是代表scale值 \(\Delta l,\Delta r,\Delta t,\Delta b\) ,将该refine输出值和初始预测值相乘即可得到refine后的真实bbox值
reg_feat = self.relu(self.vfnet_reg_refine_dconv(reg_feat, dcn_offset))
# bbox refine输出
bbox_pred_refine = scale_refine(
self.vfnet_reg_refine(reg_feat)).float().exp()
# 注意需要乘上bbox_pred.detach(),才是最终值
bbox_pred_refine = bbox_pred_refine * bbox_pred.detach()- 对分类分支也是同样处理,加强分类和回归分支一致性
cls_feat = self.relu(self.vfnet_cls_dconv(cls_feat, dcn_offset))
cls_score = self.vfnet_cls(cls_feat)总体效果如下所示:
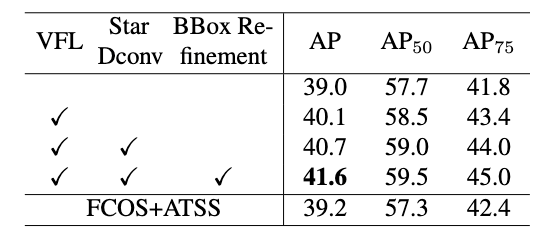
可以看出所提的两个部件确实有性能提升,但是好像不大哦!
loss设计
经过上述操作可以发现其包括三个输出:分类输出,初始回归输出和refine回归输出。对分类输出采用Varifocal Loss,对其余两个回归分支采用giou loss进行训练。还有一个小细节是两个回归分支的权重乘上了iou值,用于突出主样本。
DEIM--MAL
论文链接:arXiv reCAPTCHA
项目链接:https://www.shihuahuang.cn/DEIM/
代码链接:https://github.com/ShihuaHuang95/DEIM
DEIM主要做的工作是在实时目标检测领域,目前最主流的实时目标检测还是YOLO系列, 其是基于密集Anchors和在训练中使用一对多(One2Many, O2M)匹配策略,这样在推理的时候,对于单个物体,检测器预测多个高质量的重叠框,这样使得这些算法不得不使用一些后处理手段来清理重叠框,如非极大抑制(Non-Maximum Suppression,NMS)。而NMS这类的后处理算法需要对IoU阈值和置信度阈值同时调整才能使得性能最佳,最重要的是NMS会增加不可忽略的延迟,这样的延迟对于实时目标检测来说是非常致命的。
Detection with Transformer (DETR)是一种基于Transformer架构的,并且近几年受到了越来越多人的关注。DETR基于稀疏的可学习的Querie,并且在训练过程中使用一对一(One2one,O2O)匹配机制来限制每个目标仅匹配一个最好的正样本。通过这些方式,DETR是一种在训练和部署都实现端到端的目标检测框架,即摒弃了需要复杂的后处理如NMS。这样端到端的检测器对于实时目标检测任务更为友好,并随着对DETR框架的优化,DETR实现了低时延目标检测,慢慢地超越了YOLO,成为新的实时目标检测框架。
但是DETR的问题是:DETR的收敛速度较慢。对比Faster RCNN在COCO上仅用十几个epochs取得的效果,DETR需要数倍epochs,例如最开始的版本中需要500epochs。我们通过文献调研和进行实验,总结到导致这个问题的原因有两个:
- 稀少的监督信息——O2O匹配机制在训练过程中仅分配一个正样本给每个目标,对比O2M匹配机制则是分配数倍的正样本给每个目标,随着正样本减少,这样的监督信息大大地减少;
- 低质量的匹配(IoU很低)——不同于pixel-anchor based的YOLO检测器,在训练过程中会有10k左右的候选框,非常密集,甚至每个像素点都有好几个不同尺寸的候选框,使得最后目标附近有非常高质量的预测框。而DETR中的queries数一般是100或者300,这样少数量的queries在空间上也呈现稀疏性,会使得有一些匹配的框和目标空间交集很小(我们的理解:O2O是按照整体cost最小的来分配的,俗称矮个子里挑高个子),这样的低质量匹配会影响优化。
主要方法
DEIM整体由两部分组成:Dense O2O和MAL。
提升匹配数量——Dense O2O
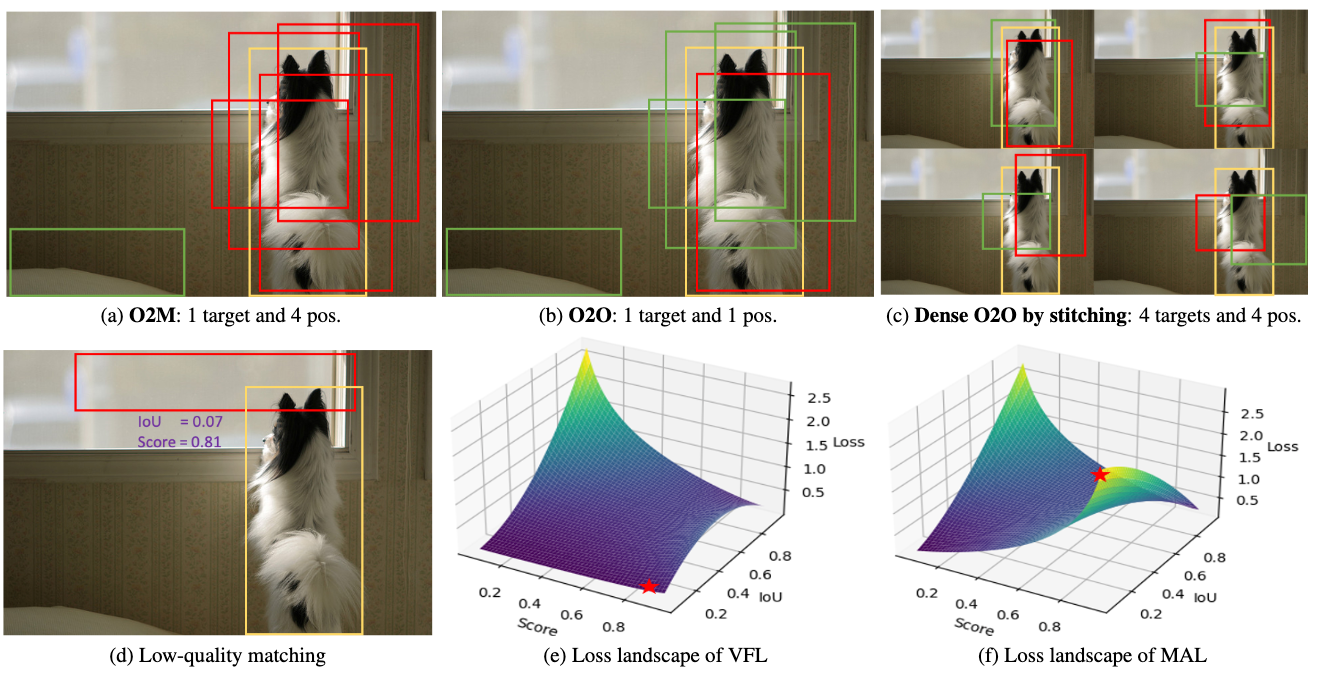
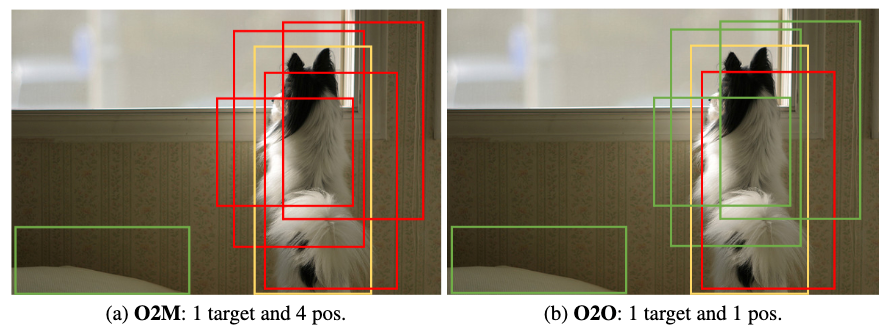
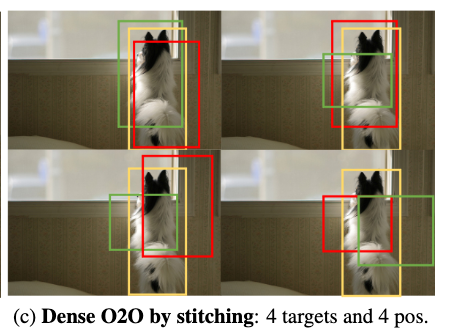
假如当前训练图片中仅有一个目标(如下图),O2M给这个目标分配4个正样本,而O2O则只给这个目标分配1个正样本,这样子的话O2O需要反复迭代这一张图片4次才能得到跟O2M相同的正样本数。
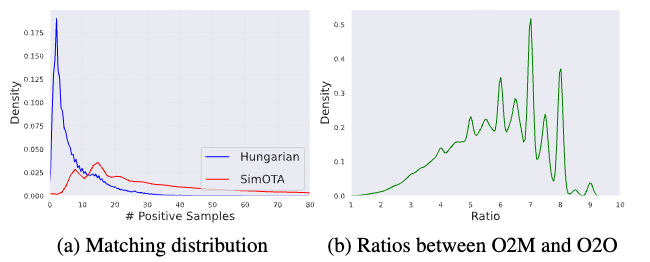
针对这个问题更深层次的理解,基于RT-DETRv2-R50模型,在一个epoch的COCO训练中,我们对每个训练样本同时统计了O2M和O2O分配正样本数量的多少,结果如下图所示。我们可以明显发现O2O匹配(Hungarian)下,绝大部分的训练数据的正样本数都少于10。我们同步对比了对于相同图片下,O2M和O2O之间正样本的比例 (O2M / O2O),如下图中右图所示,我们明显发现,O2M产生的正样本数是O2O的数倍,其中倍数甚至到了10,大部分也在6倍及以上。如何有效地增加正样本数,进而拥有密集的监督信息,成为了研究重点。
现在已经有一些工作在维持O2O的主框架,从增加每个目标的匹配数的角度来增加正样本数。有两个比较经典的工作Group DETR(使用多组queries,每组queries单独执行O2O,这样就能对于每个目标有多组正样本)和Co-DETR(引入常用的O2M匹配算法,如Faster R-CNN和FCOS,作为辅助训练)。但是这些算法都不可避免的:(1)需要多个辅助的Decoder,增加训练资源消耗;(2)需要平衡好跟主Decoder和主loss跟辅助的,以免影响主体的性能;(3)辅助训练可能的副作用,增加高质量的重叠框出现的概率,最后又不得不用NMS。
deim提出来的Dense O2O的想法就是通过有效地增加每张图片中目标数,这样就可以使得监督信息更加密集。我们呈现了一个很简单的例子(如下图)——通过把拥有单个目标的图片复制4份,拼接在一起,这样就有4个目标,继而有4个正样本,逼近O2M的策略,但是不至于引入O2M的问题,更重要的是这样的这样的方法接近免费,可通过简单的数据增强实现。
Matchability-Aware Loss,MAL
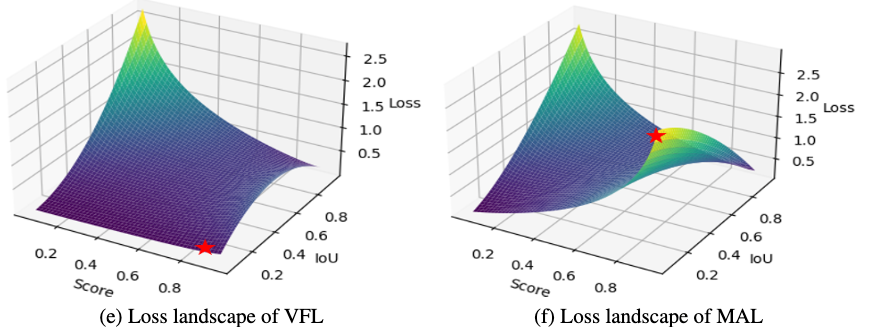
VFL是目前比较常用目标检测的损失函数,尤其是最近的实时DETR框架中,经常被用到。VFL是面向O2M和pixel anchor的检测器设计的,这样的检测器不会面临着正样本少和匹配质量差。在图7中显示,VFL对于DETR框架的话,就有两个明显的问题:
- 对于IoU很低的匹配,loss惩罚不会随着置信度增加而增加;
- IoU=0的时候,这被认为是负样本,进一步减少正样本数量。
因此我们重新基于Focal Loss提出了一个基于匹配度的损失函数,MAL。MAL可以有效地解决VFL存在的问题,且整体数学上更为简洁,仅有\(\gamma\)一个超参数。
MAL 做了哪些大刀阔斧的改变?
- 删除了外部的权重乘数:
注意看,MAL 的正样本公式前面没有那个\(q\) 了, 它变成了一个纯粹的交叉熵结构。这意味着,即使是低质量的框,也不会被强行按在地上摩擦,它们依然能产生足够大的损失来推动网络更新。
- 目标标签的非线性 (\(q \to q^\gamma\)):
MAL 没有直接用 \(q\) 作为目标,而是把目标改成了 \(q^\gamma\)(\(\gamma\)通常大于 1)。
为什么要加指数?因为如果直接用 \(q\),低质量框(比如 \(q=0.1\))的目标分数太低,模型容易把它当成背景。改成$\(q^\gamma\) 后,重塑了目标的分布,使得模型在优化时,对低质量框的置信度惩罚更加敏感
- 极简的负样本统一:
去掉了 VFL 中的平衡超参数 \(\alpha\)。因为正样本的目标变成了 \(q^\gamma\),负样本的权重是 \(p^\gamma\),两者在数学形式上达到了天然的对称和平衡,不再需要人工调参。
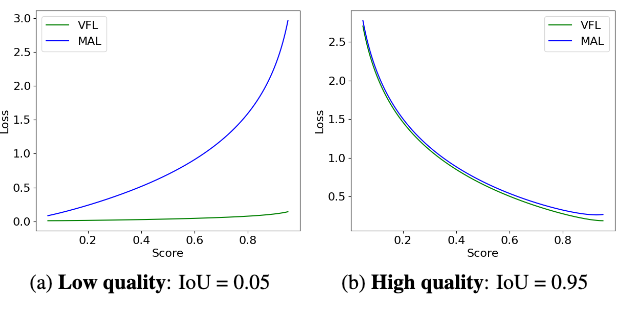
对比VFL和MAL:低质量匹配(IoU=0.05)和高质量匹配(IoU=0.95)的例子。通过对比发现,MAL在低质量匹配下,会随着置信度越高,惩罚越大,而VFL则没有明显惩罚;MAL和VFL在高质量的匹配下表现相同。认为继承了VFL的优点,但是大大地优化了其缺点。
总结
这篇论文的思路比较简单,DEIM通过使用Dense O2O(方法就是通过Mosaic和MixUp的数据增强方式),并改进了VFL分别提升匹配数量和匹配的质量
DEIMv2
DEIMv2最显著的特点,是它并非单一模型,而是一个庞大的模型家族,总共包含8个不同尺寸的型号,从最大规模的X,到L, M, S,再到为移动端和边缘设备设计的Nano, Pico, Femto, Atto。这种全方位的布局,旨在为各种不同的硬件和应用场景提供最优的性能-成本权衡。
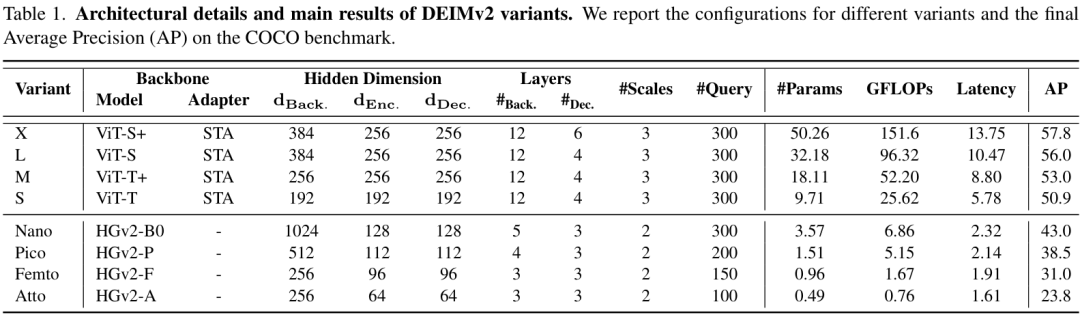
DEIMv2的核心思想,是借助强大的DINOv3视觉基础模型来提升实时检测器的特征表示能力。但直接用并不简单,因为DINOv3这类基础模型和目标检测任务之间存在一个“gap”。
挑战与解决方案:空间调优适配器(STA)
DINOv3的特征语义信息非常强,但它天然产生的是单尺度特征(1/16分辨率),并且缺乏用于精确定位的细粒度空间细节。而目标检测任务恰恰需要多尺度的特征图来检测大小各异的物体。
为了解决这个问题,作者们设计了一个即插即用、轻量且高效的模块——空间调优适配器(Spatial Tuning Adapter, STA)。
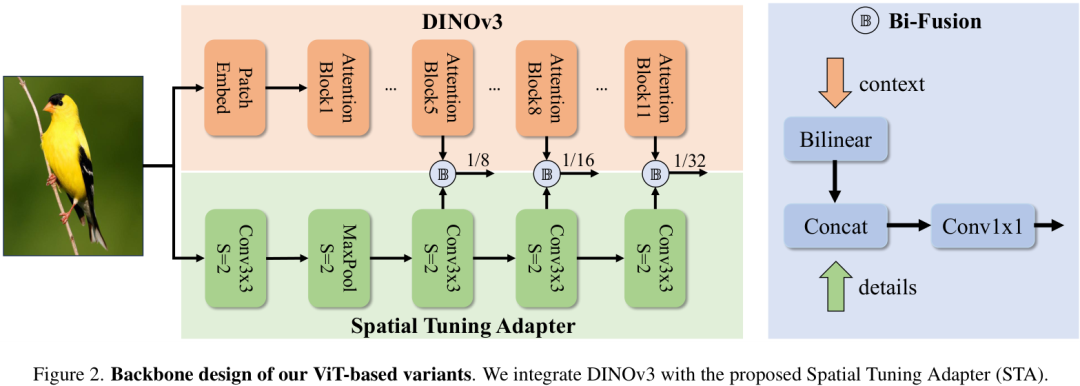
STA的结构非常巧妙:
- 它并行于DINOv3主干网络,通过一个极轻量的卷积网络,快速地从输入图像中提取出细粒度的多尺度细节特征。
- 同时,它将DINOv3不同层输出的特征图,通过简单的双线性插值,也转换成多尺度特征。
- 最后,通过一个Bi-Fusion算子,将DINOv3强大的“语义”特征和STA提供的“细节”特征进行融合。
CV君认为,这个STA模块是本文最大的亮点,它用一种“参数免费”的方式(双线性插值)和极小的代价(轻量CNN),就完美地将DINOv3的强大能力适配到了实时检测框架中。
其他优化
除了STA,DEIMv2还进行了一系列优化:
- 针对超轻量模型:对于Nano到Atto这些模型,作者没有使用ViT,而是选择了对移动端更友好的HGNetv2作为骨干,并对其进行了精细的深度和宽度剪枝,以满足极致的资源限制。
- 简化的解码器:采用了更高效的SwishFFN和RMSNorm,并共享了位置编码,进一步降低计算量。
- 增强的Dense O2O:引入了Copy-Blend数据增强,在不增加背景干扰的情况下,为模型提供了更强的监督信号。
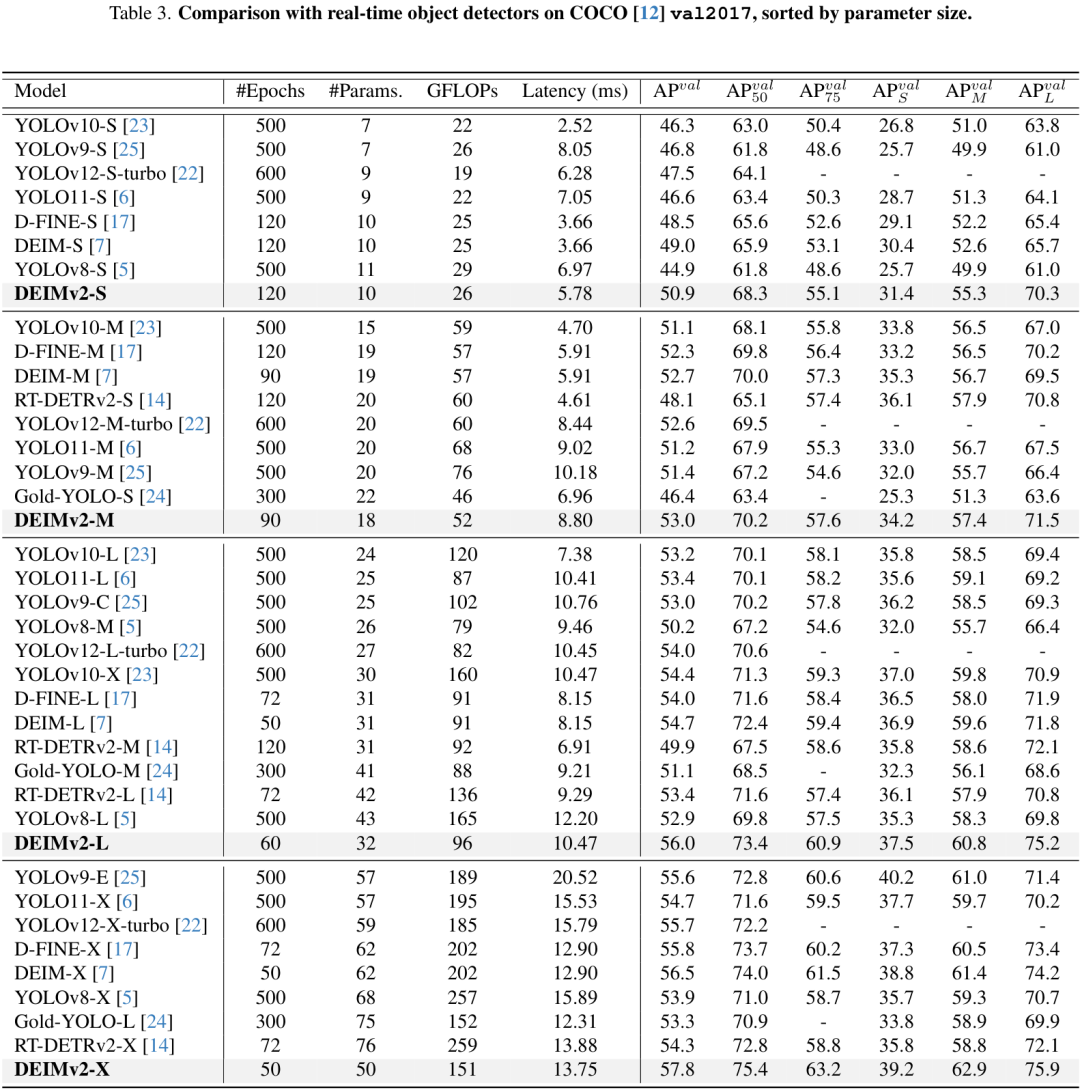
DEIMv2的性能表现只能用“惊艳”来形容,它在COCO数据集上建立了一系列新的SOTA记录。
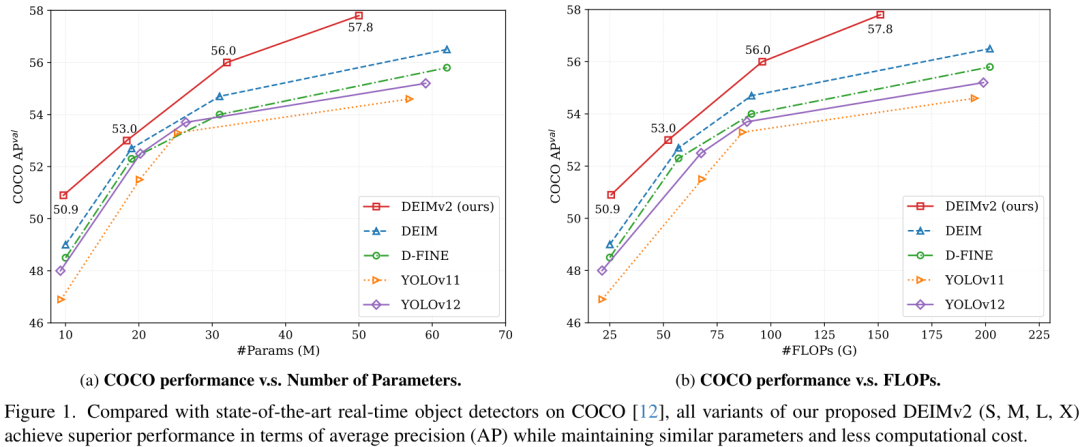
来看几个关键数据:
- DEIMv2-X:作为最大的型号,它用50.3M的参数量,达到了57.8 AP的惊人精度,远超之前需要60M+参数才能达到56.5 AP的同级模型。
- DEIMv2-S:这是第一个参数量低于10M(9.71M)却突破50 AP大关的模型,精度高达50.9 AP!这在轻量级检测器中是一个里程碑。
- DEIMv2-Pico:在超轻量级对决中,Pico版本用仅仅1.5M的参数量,就取得了38.5 AP的成绩,与参数量比它大50%的YOLOv10-Nano打成平手,展示了极致的参数效率。
下面的表格更详细地展示了DEIMv2家族与其他SOTA实时检测器(包括各种YOLO)的性能对比,优势非常明显。
Reference
知乎-mmdetection最小复刻版(十六):iou感知VarifocalNet深入分析
知乎-DEIM: DETR with Improved Matching for Fast Convergence (最强实时目标检测算法,已开源)