论文名称:LLaMA: Open and Efficient Foundation Language Models
论文地址:
https://arxiv.org/pdf/2302.13971.pdf
代码链接:
https://github.com/facebookresearch/llama
背景
模型参数量级的积累,或者训练数据的增加,哪个对性能提升帮助更大?
以 GPT-3 为代表的大语言模型 (Large language models, LLMs) 在海量文本集合上训练,展示出了惊人的涌现能力以及零样本迁移和少样本学习能力。GPT-3 把模型的量级缩放到了 175B,也使得后面的研究工作继续去放大语言模型的量级。大家好像有一个共识,就是:模型参数量级的增加就会带来同样的性能提升。
但是事实确实如此吗?
最近的 "Training Compute-Optimal Large Language Models" 这篇论文提出一种缩放定律 (Scaling Law):
训练大语言模型时,在计算成本达到最优情况下,模型大小和训练数据 (token) 的数量应该比例相等地缩放,即:如果模型的大小加倍,那么训练数据的数量也应该加倍。
翻译过来就是:当我们给定特定的计算成本预算的前提下,语言模型的最佳性能不仅仅可以通过设计较大的模型搭配小一点的数据集得到,也可以通过设计较小的模型配合大量的数据集得到。
那么,相似成本训练 LLM,是大 LLM 配小数据训练,还是小 LLM 配大数据训练更好?
缩放定律 (Scaling Law) 告诉我们对于给定的特定的计算成本预算,如何去匹配最优的模型和数据的大小。但是本文作者团队认为,这个功能只考虑了总体的计算成本,忽略了推理时候的成本。因为大部分社区用户其实没有训练 LLM 的资源,他们更多的是拿着训好的 LLM 来推理。在这种情况下,我们首选的模型应该不是训练最快的,而应该是推理最快的 LLM。呼应上题,本文认为答案就是:小 LLM 配大数据训练更好,因为小 LLM 推理更友好。
LLaMa 做到了什么
LLaMa 沿着小 LLM 配大数据训练的指导思想,训练了一系列性能强悍的语言模型,参数量从 7B 到 65B。例如,LLaMA-13B 比 GPT-3 小10倍,但是在大多数基准测试中都优于 GPT-3。大一点的 65B 的 LLaMa 模型也和 Chinchilla 或者 PaLM-540B 的性能相当。
同时,LLaMa 模型只使用了公开数据集,开源之后可以复现。但是大多数现有的模型都依赖于不公开或未记录的数据完成训练。
LLaMa 预训练数据
LLaMa 预训练数据大约包含 1.4T tokens,对于绝大部分的训练数据,在训练期间模型只见到过1次,Wikipedia 和 Books 这两个数据集见过2次。
如下图1所示是 LLaMa 预训练数据的含量和分布,其中包含了 CommonCrawl 和 Books 等不同域的数据。
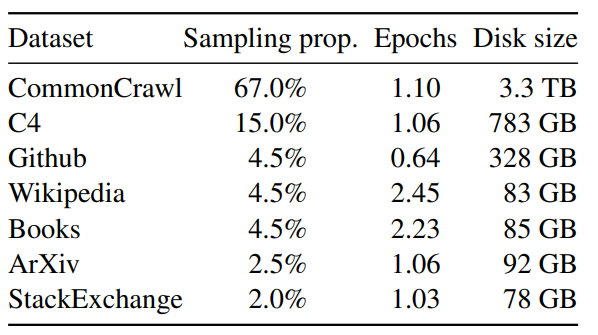
- CommonCrawl (占 67%):包含 2017 到 2020 的5个版本,预处理部分包含:删除重复数据,去除掉非英文的数据,并通过一个 n-gram 语言模型过滤掉低质量内容。
- C4 (占 15%):在探索性实验中,作者观察到使用不同的预处理 CommonCrawl 数据集可以提高性能,因此在预训练数据集中加了 C4。预处理部分包含:删除重复数据,过滤的方法有一些不同,主要依赖于启发式方法,例如标点符号的存在或网页中的单词和句子的数量。
- Github (占 4.5%):在 Github 中,作者只保留在 Apache、BSD 和 MIT 许可下的项目。此外,作者使用基于行长或字母数字字符比例的启发式方法过滤低质量文件,并使用正则表达式删除标题。最后使用重复数据删除。
- Wikipedia (占 4.5%):作者添加了 2022 年 6-8 月的 Wikipedia 数据集,包括 20 种语言,作者处理数据以删除超链接、评论和其他格式样板。
- Gutenberg and Books3 (占 4.5%):作者添加了两个书的数据集,分别是 Gutenberg 以及 ThePile (训练 LLM 的常用公开数据集) 中的 Book3 部分。处理数据时作者执行重复数据删除,删除内容重叠超过 90% 的书籍。
- ArXiv (占 2.5%):为了添加一些科学数据集,作者处理了 arXiv Latex 文件。作者删除了第一部分之前的所有内容,以及参考文献。还删除了 .tex 文件的评论,以及用户编写的内联扩展定义和宏,以增加论文之间的一致性。
- Stack Exchange (占 2%):作者添加了 Stack Exchange,这是一个涵盖各种领域的高质量问题和答案网站,范围从计算机科学到化学。作者从 28 个最大的网站保留数据,从文本中删除 HTML 标签并按分数对答案进行排序。
Tokenizer 的做法基于 SentencePieceProcessor,使用 bytepair encoding (BPE) 算法。
LLaMa 的 PyTorch 代码如下,用到了 sentencepiece 这个库。
# 引入 sentencepiece 库的 SentencePieceProcessor 模块,用于进行分词操作
from sentencepiece import SentencePieceProcessor
# 引入 logging 库的 getLogger 模块,用于生成日志
from logging import getLogger
# 引入 typing 库的 List 模块,用于注释函数参数或返回值的类型
from typing import List
# 引入 os 库,提供了大量与操作系统进行交互的接口
import os
# 创建一个日志记录器
logger = getLogger()
# 定义一个 Tokenizer 类
class Tokenizer:
# 初始化函数,参数为 SentencePiece 模型的路径
def __init__(self, model_path: str):
# 判断指定的模型文件是否存在
assert os.path.isfile(model_path), model_path
# 加载 SentencePiece 模型
self.sp_model = SentencePieceProcessor(model_file=model_path)
# 记录日志,提示模型加载成功
logger.info(f"Reloaded SentencePiece model from {model_path}")
# 获取模型的词汇量、开始标记 ID、结束标记 ID、填充标记 ID
self.n_words: int = self.sp_model.vocab_size()
self.bos_id: int = self.sp_model.bos_id()
self.eos_id: int = self.sp_model.eos_id()
self.pad_id: int = self.sp_model.pad_id()
# 记录日志,显示获取的信息
logger.info(
f"#words: {self.n_words} - BOS ID: {self.bos_id} - EOS ID: {self.eos_id}"
)
# 确保模型的词汇量与词片段大小一致
assert self.sp_model.vocab_size() == self.sp_model.get_piece_size()
# 编码函数,将输入的字符串编码为 token id 列表
def encode(self, s: str, bos: bool, eos: bool) -> List[int]:
# 检查输入的是否是字符串
assert type(s) is str
# 使用 SentencePiece 模型将字符串编码为 token id 列表
t = self.sp_model.encode(s)
# 如果需要在开头添加开始标记,就将开始标记 id 添加到列表的开头
if bos:
t = [self.bos_id] + t
# 如果需要在结尾添加结束标记,就将结束标记 id 添加到列表的结尾
if eos:
t = t + [self.eos_id]
# 返回 token id 列表
return t
# 解码函数,将 token id 列表解码为字符串
def decode(self, t: List[int]) -> str:
# 使用 SentencePiece 模型将 token id 列表解码为字符串
return self.sp_model.decode(t)
LLaMa 模型架构
RMSNorm
Pre-normalization [受 GPT3 的启发]:
为了提高训练稳定性,LLaMa 对每个 Transformer 的子层的输入进行归一化,而不是对输出进行归一化。使用 RMSNorm 归一化函数。
**class** **RMSNorm**(torch**.**nn**.**Module):
**def** __init__(self, dim: int, eps: float **=** 1e-6):
super()**.**__init__()
self**.**eps **=** eps
self**.**weight **=** nn**.**Parameter(torch**.**ones(dim))
**def** **_norm**(self, x):
# torch.rsqrt是开平方并取倒数
**return** x ***** torch**.**rsqrt(x**.**pow(2)**.**mean(**-**1, keepdim**=**True) **+** self**.**eps)
**def** **forward**(self, x):
output **=** self**.**_norm(x**.**float())**.**type_as(x)
**return** output ***** self**.**weight
常规的 Layer Normalization:
式中, \(𝑔_𝑖\) 和 \(𝑏_𝑖\) 是 LN 的 scale 和 shift 参数, \(𝜇\) 和 \(𝜎\) 的计算如下式所示:
RMSNorm:
相当于是去掉了 𝜇 这一项。
看上去就这一点小小的改动,有什么作用呢?RMSNorm 的原始论文进行了一些不变性的分析和梯度上的分析。
SwiGLU 激活函数 [受 PaLM 的启发]
为了更好的理解SwiGLU,首先你得先了解什么是ReLU和GLU
- ReLU的函数表达式为\(f(x) = max(0, x)\),这意味着对于所有负的输入值,ReLU函数的输出都是0,对于所有正的输入值,ReLU函数的输出等于输入值本身
- GLU 的基本思想是引入一种称为“门”机制,该机制可以动态地控制信息的流动
而LLaMA采用Shazeer(2020)提出的SwiGLU替换了原有的ReLU,SwiGLU的作用机制是根据输入数据的特性,通过学习到的参数自动调整信息流动的路径,具体是采用SwiGLU的Feedforward Neural Network (简称FNN,这是一种使用可学习的门控机制的前馈神经网络)
其在论文中以如下公式进行表述:
解释下这个公式
- 该公式先是通过Swish非线性激活函数处理 “输入\(x\) 和权重矩阵\(W\)的乘积”
- 上面步骤1得到的结果和 “输入与权重矩阵的乘积” 进行逐元素的乘法
这个操作相当于在 Swish 激活的输出和第二个线性变换的输出之间引入了一个类似于GLU的“门”,这个门的值是由原始输入 \(x\) 通过线性变换 \(V\) 计算得到的,因此,它可以动态地控制 Swish 激活的输出 - 最后乘以权重矩阵 \(W_2\)
至于Swish激活函数可表示为
\(\sigma\)表示sigmoid函数,但其输入被缩放了 \(\beta\) 倍,\(\beta\) 是一个可以学习的参数,比如下图,\(\beta\) 不同,Swish激活函数的形状则各异
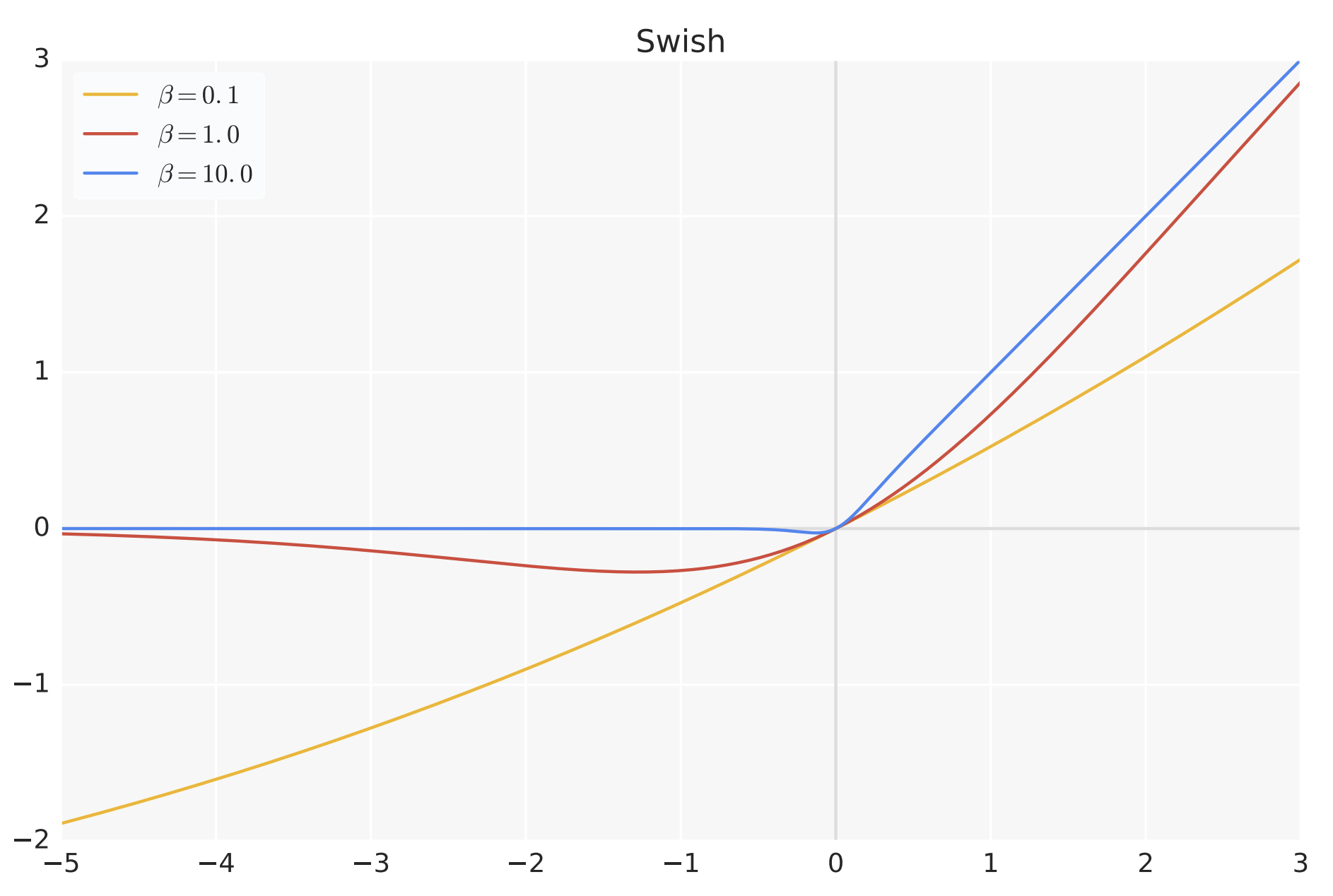
- 当 \(\beta\) 趋近于 0 时,Swish 函数趋近于线性函数 y = x
- 当 \(\beta\) 趋近于无穷大时,Swish 函数趋近于 ReLU 函数
Rotary Embeddings
LLaMa 去掉了绝对位置编码,使用旋转位置编码 (Rotary Positional Embeddings, RoPE) 详细见
https://blog.csdn.net/v_JULY_v/article/details/134085503
**Self-Attention **
PyTorch 代码:
**class** **Attention**(nn**.**Module):
**def** __init__(self, args: ModelArgs):
super()**.**__init__()
self**.**n_local_heads **=** args**.**n_heads **//** fs_init**.**get_model_parallel_world_size()
self**.**head_dim **=** args**.**dim **//** args**.**n_heads
self**.**wq **=** ColumnParallelLinear(
args**.**dim,
args**.**n_heads ***** self**.**head_dim,
bias**=**False,
gather_output**=**False,
init_method**=lambda** x: x,
)
self**.**wk **=** ColumnParallelLinear(
args**.**dim,
args**.**n_heads ***** self**.**head_dim,
bias**=**False,
gather_output**=**False,
init_method**=lambda** x: x,
)
self**.**wv **=** ColumnParallelLinear(
args**.**dim,
args**.**n_heads ***** self**.**head_dim,
bias**=**False,
gather_output**=**False,
init_method**=lambda** x: x,
)
self**.**wo **=** RowParallelLinear(
args**.**n_heads ***** self**.**head_dim,
args**.**dim,
bias**=**False,
input_is_parallel**=**True,
init_method**=lambda** x: x,
)
self**.**cache_k **=** torch**.**zeros(
(args**.**max_batch_size, args**.**max_seq_len, self**.**n_local_heads, self**.**head_dim)
)**.**cuda()
self**.**cache_v **=** torch**.**zeros(
(args**.**max_batch_size, args**.**max_seq_len, self**.**n_local_heads, self**.**head_dim)
)**.**cuda()
**def** **forward**(self, x: torch**.**Tensor, start_pos: int, freqs_cis: torch**.**Tensor, mask: Optional[torch**.**Tensor]):
bsz, seqlen, _ **=** x**.**shape
xq, xk, xv **=** self**.**wq(x), self**.**wk(x), self**.**wv(x)
xq **=** xq**.**view(bsz, seqlen, self**.**n_local_heads, self**.**head_dim)
xk **=** xk**.**view(bsz, seqlen, self**.**n_local_heads, self**.**head_dim)
xv **=** xv**.**view(bsz, seqlen, self**.**n_local_heads, self**.**head_dim)
xq, xk **=** apply_rotary_emb(xq, xk, freqs_cis**=**freqs_cis)
self**.**cache_k **=** self**.**cache_k**.**to(xq)
self**.**cache_v **=** self**.**cache_v**.**to(xq)
self**.**cache_k[:bsz, start_pos : start_pos **+** seqlen] **=** xk
self**.**cache_v[:bsz, start_pos : start_pos **+** seqlen] **=** xv
keys **=** self**.**cache_k[:bsz, : start_pos **+** seqlen]
values **=** self**.**cache_v[:bsz, : start_pos **+** seqlen]
xq **=** xq**.**transpose(1, 2)
keys **=** keys**.**transpose(1, 2)
values **=** values**.**transpose(1, 2)
scores **=** torch**.**matmul(xq, keys**.**transpose(2, 3)) **/** math**.**sqrt(self**.**head_dim)
**if** mask **is** **not** None:
scores **=** scores **+** mask *# (bs, n_local_heads, slen, cache_len + slen)*scores **=** F**.**softmax(scores**.**float(), dim**=-**1)**.**type_as(xq)
output **=** torch**.**matmul(scores, values) *# (bs, n_local_heads, slen, head_dim)*output **=** output**.**transpose(
1, 2
)**.**contiguous()**.**view(bsz, seqlen, **-**1)
**return** self**.**wo(output)
这里有几个地方值得注意一下:
model.py 文件里面从 fairscale 中 import 了3个类,分别是:ParallelEmbedding,RowParallelLinear,和 ColumnParallelLinear。
Fairscale 链接如下,是一个用于高性能大规模预训练的库,LLaMa 使用了其ParallelEmbedding 去替换 Embedding, 使用了其 RowParallelLinear 和 ColumnParallelLinear 去替换nn.Linear,猜测可能是为了加速吧
GitHub - facebookresearch/fairscale: PyTorch extensions for high performance and large scale training.github.com/facebookresearch/fairscale
另一个需要注意的点是:cache 的缓存机制,可以看到在构造函数里面定义了下面两个东西:
self.cache_k = torch.zeros((args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)).cuda()
self.cache_v = torch.zeros((args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)).cuda()
关键其实就是这几行代码:
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
在训练的时候,因为每次都是输入完整的一句话,所以 cache 机制其实是不发挥作用的。
在推理的时候,比如要生成 "I have a cat",过程是:
1 输入 ,生成 I。
2 输入 I,生成 I have。
3 输入 I have,生成 I have a。
4 输入 I have a,生成 I have a cat。
在执行3这一步时,计算 "a" 的信息时,还要计算 I have 的 Attention 信息,比较复杂。因此,cache 的作用就是在执行2这一步时,提前把 I have 的 keys 和 values 算好,并保存在 self.cache_k 和 self.cache_v 中。在执行3这一步时,计算 Attention 所需的 keys 和 values 是直接从这里面取出来的:
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
只需要额外地计算 "a" 的 keys 和 values 即可,这对模型的快速推理是至关重要的。
还有一个值得注意的点:self.cache_k = self.cache_k.to(xq)
这里使用的是 to() 函数的一种不太常见的用法:torch.to(other, non_blocking=False, copy=False)→Tensor
Returns a Tensor with same torch.dtype and torch.device as the Tensor other.

FFN 的 PyTorch 代码:
**class** **FeedForward**(nn**.**Module):
**def** __init__(
self,
dim: int,
hidden_dim: int,
multiple_of: int,
):
super()**.**__init__()
hidden_dim **=** int(2 ***** hidden_dim **/** 3)
hidden_dim **=** multiple_of ***** ((hidden_dim **+** multiple_of **-** 1) **//** multiple_of)
self**.**w1 **=** ColumnParallelLinear(
dim, hidden_dim, bias**=**False, gather_output**=**False, init_method**=lambda** x: x
)
self**.**w2 **=** RowParallelLinear(
hidden_dim, dim, bias**=**False, input_is_parallel**=**True, init_method**=lambda** x: x
)
self**.**w3 **=** ColumnParallelLinear(
dim, hidden_dim, bias**=**False, gather_output**=**False, init_method**=lambda** x: x
)
**def** **forward**(self, x):
**return** self**.**w2(F**.**silu(self**.**w1(x)) ***** self**.**w3(x))
这里需要注意的点是:
激活函数用的是 F.silu(),也就是 Swish 激活函数。
self.w2(F.silu(self.w1(x)) * self.w3(x))的实现也就是 SwiGLU 激活函数

Transformer Block 的 PyTorch 代码:
**class** **TransformerBlock**(nn**.**Module):
**def** __init__(self, layer_id: int, args: ModelArgs):
super()**.**__init__()
self**.**n_heads **=** args**.**n_heads
self**.**dim **=** args**.**dim
self**.**head_dim **=** args**.**dim **//** args**.**n_heads
self**.**attention **=** Attention(args)
self**.**feed_forward **=** FeedForward(
dim**=**args**.**dim, hidden_dim**=**4 ***** args**.**dim, multiple_of**=**args**.**multiple_of
)
self**.**layer_id **=** layer_id
self**.**attention_norm **=** RMSNorm(args**.**dim, eps**=**args**.**norm_eps)
self**.**ffn_norm **=** RMSNorm(args**.**dim, eps**=**args**.**norm_eps)
**def** **forward**(self, x: torch**.**Tensor, start_pos: int, freqs_cis: torch**.**Tensor, mask: Optional[torch**.**Tensor]):
h **=** x **+** self**.**attention**.**forward(self**.**attention_norm(x), start_pos, freqs_cis, mask)
out **=** h **+** self**.**feed_forward**.**forward(self**.**ffn_norm(h))
**return** out
Transformer 的 PyTorch 代码:
**class** **Transformer**(nn**.**Module):
**def** __init__(self, params: ModelArgs):
super()**.**__init__()
self**.**params **=** params
self**.**vocab_size **=** params**.**vocab_size
self**.**n_layers **=** params**.**n_layers
self**.**tok_embeddings **=** ParallelEmbedding(
params**.**vocab_size, params**.**dim, init_method**=lambda** x: x
)
self**.**layers **=** torch**.**nn**.**ModuleList()
**for** layer_id **in** range(params**.**n_layers):
self**.**layers**.**append(TransformerBlock(layer_id, params))
self**.**norm **=** RMSNorm(params**.**dim, eps**=**params**.**norm_eps)
self**.**output **=** ColumnParallelLinear(
params**.**dim, params**.**vocab_size, bias**=**False, init_method**=lambda** x: x
)
self**.**freqs_cis **=** precompute_freqs_cis(
self**.**params**.**dim **//** self**.**params**.**n_heads, self**.**params**.**max_seq_len ***** 2
)
@torch.inference_mode()
**def** **forward**(self, tokens: torch**.**Tensor, start_pos: int):
_bsz, seqlen **=** tokens**.**shape
h **=** self**.**tok_embeddings(tokens)
self**.**freqs_cis **=** self**.**freqs_cis**.**to(h**.**device)
freqs_cis **=** self**.**freqs_cis[start_pos : start_pos **+** seqlen]
mask **=** None
**if** seqlen **>** 1:
mask **=** torch**.**full((1, 1, seqlen, seqlen), float("-inf"), device**=**tokens**.**device)
mask **=** torch**.**triu(mask, diagonal**=**start_pos **+** 1)**.**type_as(h)
**for** layer **in** self**.**layers:
h **=** layer(h, start_pos, freqs_cis, mask)
h **=** self**.**norm(h)
output **=** self**.**output(h[:, **-**1, :]) *# only compute last logits
***return** output**.**float()