Chameleon:生成理解统一模型的开山之作
🔖 https://arxiv.org/pdf/2405.09818
Chameleon 是一个既能做图像理解,又可以做图像或者文本生成任务的,从头训练的 Transformer 模型。完整记录了为实现 mixed-modal 模型的架构设计,稳定训练方法,对齐的配方。并在一系列全面的任务上进行评估:有纯文本任务,也有图像文本任务 (视觉问答、图像字幕),也有图像生成任务,还有混合模态的生产任务。
如下图所示,Chameleon 将所有模态数据 (图像、文本和代码) 都表示为离散 token,并使用统一的 Transformer 架构。训练数据是交错混合模态数据 ∼10T token,以端到端的方式从头开始训练。文本 token 用绿色表示,图像 token 用蓝色表示

Transfusion:使用一个模型完成图像生成和理解任务
概述
Transfusion 是一种从头训练的 Transformer 模型,专为图像理解和生成任务设计。它使用图像文本混合数据进行训练,目标函数包括 Diffusion Loss 和 Language Modeling Loss。
Transfusion 模型参数可达 7B,能够执行文本生成、图像生成和图像理解任务。与 Chameleon 模型相比,Transfusion 的性能更优,通过特定编码和解码层的引入可进一步提升性能。扩展到 7B 参数和 2T 多模态 token 训练后,Transfusion 能够在图像生成上媲美扩散模型,在文本生成上媲美语言模型。。
研究背景
多模态生成模型需同时处理离散元素(文本、代码)和连续元素(图像、音频、视频)。目前,LLM 在处理离散数据方面表现出色,而 Diffusion Model 及 Flow Matching 在连续数据领域占据主导地位。
已有研究尝试结合这两种模型,如将预训练的 Diffusion Model 嫁接到 LLM 上(DreamLLM),或在离散 token 上训练语言模型但牺牲部分信息。
本文提出的 Transfusion 创新性地通过单一模型同时预测离散文本 token 和扩散连续图像,实现两种模态的无缝集成。Transfusion 采用混合训练目标:在均等分配的文本和图像数据上预训练 Transformer,文本使用 next token prediction,图像使用 diffusion。
模型架构上,标准 Embedding 层处理文本 token,patchify 层将图像表示为 patch 向量序列。文本采用单向注意力机制,图像采用双向注意力。推理时,结合语言模型的文本生成和扩散模型的图像生成技术。
Transfusion(7B 参数量,含 0.27B U-Net 层)在 2T token 上训练(1T 文本,1T 图像,约 692M 张图)。实验表明,其图像生成能力优于 DALL-E 2 和 SDXL,文本生成能力达到 Llama 1 水平,展现了统一多模态生成的巨大潜力。
方法
Transfusion 是一种训练单个统一的模型来理解和生成离散和连续模态的方法,用两个目标训练的单一模型:语言建模和扩散。
数据准备
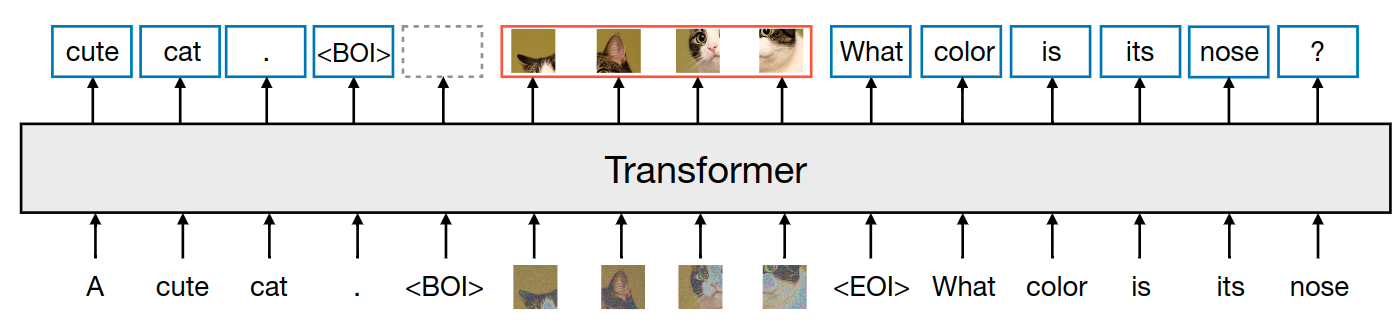
作者对两种模态的数据进行了实验:离散的文本和连续的图像。每个文本字符串都被标记为来自固定词汇表的离散 token 序列。每个图像都使用 VAE 编码为 latent patch,其中每个 patch 表示为一个连续向量。patch 从左到右的从上到下排序。也就是每个图像最终都会转化为一系列的 patch 向量。作者在把这些向量插入到文本序列之前,使用特殊的 BOI 作为开始 token,EOI 作为结束 token,围绕图像序列。
因此,最终序列的样子是:包含了离散元素 (表示文本 token 的整数) 和连续元素 (表示图像 patch 的向量)。
模型架构
模型参数的绝大部分都属于一个 Transformer,它输入一个序列,输出一个序列,无论模态如何。为了将数据转换到这个空间,作者对于不同模态的数据使用了具有非共享参数的特定的组件。
对于文本而言,文本是嵌入矩阵,将每个输入的token转换为向量空间,每个输出向量转换为词汇表上的离散分布。
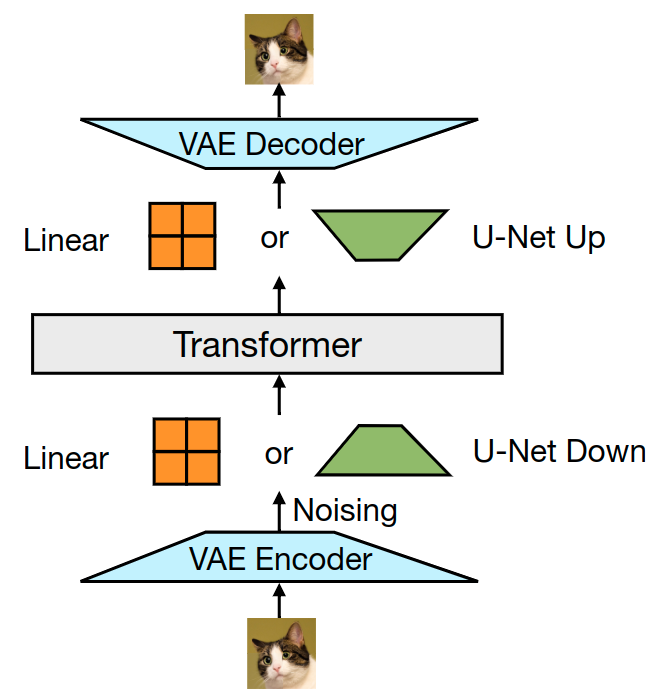
对于图像,将 \(k×k\) 的 patch 转化为单个向量的方法,作者试了 2 种:1) 线性层;2) U-Net Up 和 Down 层。如下图所示。
注意力机制
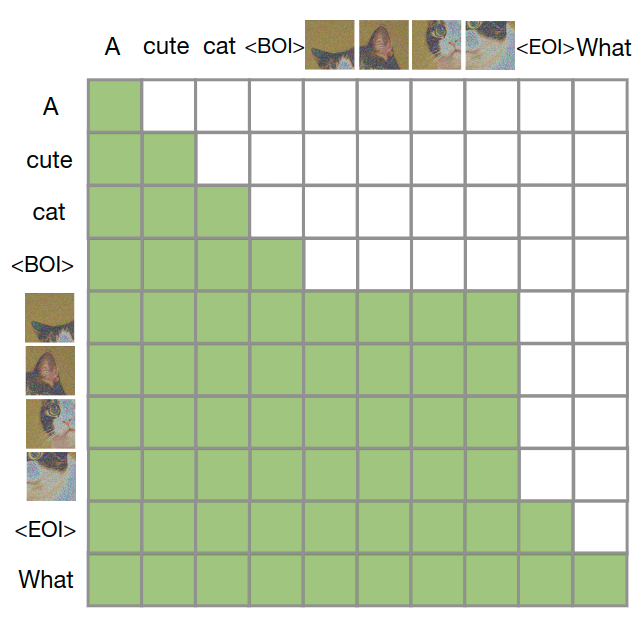
Transfusion 模型结合了因果注意力和双向注意力。文本的处理通常使用因果注意力,以防止未来信息泄露,而图像通常使用不受限制的双向注意力。Transfusion 通过对序列中的每个元素应用因果注意力,同时在每个单独图像元素之间应用双向注意力,将这两种注意力模式结合起来。这意味着每个图像 patch 可以关注同一图像中的所有其他 patch,但只能关注序列中之前出现的其他图像 patch 或文本。启用图像内注意力显著提高了模型性能。。下图显示了一个示例 Transfusion attention mask。
训练目标
- 语言建模目标(LLM):这是用于文本生成的目标函数,通常通过预测下一个 token 来进行训练。
- 扩散目标(LDDPM):这是用于图像生成的目标函数,基于扩散模型的原理。扩散模型通过向输入图像添加噪声,再逐步去噪来生成图像。
损失计算:
推理过程
- 语言模式(LM):在这个模式下,使用标准的 token-by-token 采样方法从预测分布中生成文本。
- 扩散模式:当采样到一个表示图像开始的 token (BOI) 时,模型切换到扩散模式。在此模式下,模型通过添加纯噪声并逐步去噪生成图像。
- 模式切换:一旦图像生成完成,模型会添加一个表示图像结束的 token (EOI),然后切换回语言模式继续生成文本。
Janus 系列:解耦统一多模态理解和生成模型的视觉编码
概述
Janus 系列是 DeepSeek 多模态团队的作品,是一种既能做图像理解,又可以做图像生成任务的 Transformer 模型。这类模型存在的问题之一是:由于多模态理解和生成所需的信息粒度不同,这种方法可能会导致次优的性能。
为了解决这个问题,Janus 仍利用单个统一的 Transformer,但是将视觉编码解耦为单独的路径。这种解耦不仅缓解了视觉编码器在理解和生成中的作用之间的冲突,而且增强了框架的灵活性。比如多模态理解和生成组件都可以独立选择最合适的编码方法。
Janus-Pro 是先前工作 Janus 的高级版本。Janus-Pro 具体特点:
- 优化的训练策略;
- 扩展训练数据;
- 更大的模型大小
通过这些改进,Janus-Pro 在多模态理解和文本到图像指令跟踪能力方面都取得了显著进步,同时还提高了文生图任务的稳定性。
Janus
模型结构
Janus 是使用一个统一的 Transformer 架构来统一多模态图像理解和多模态图像生成任务的模型。这种方法通常使用单个视觉编码器来处理这 2 个任务的输入。然而,多模态理解和生成任务所需的表征差异很大:
- 多模态理解任务中,视觉编码器的目的是提取高级语义信息。理解任务的输出不仅涉及从图像中提取信息,还涉及复杂的语义推理。因此,视觉编码器表示的粒度往往主要集中在高维语义的表征上
- 视觉生成任务中,主要关注点是生成局部细节并保持图像中的全局一致性。
在这种情况下,表征需要表示出细粒度的空间结构,以及纹理细节。在同一空间中统一这两个任务的表示将导致冲突。因此,现有的多模态理解和生成的统一模型通常会影响多模态理解性能,明显低于最先进的多模态理解模型。
Janus 作为一个类似的统一多模态模型,为了解决这个问题,将视觉编码进行解耦来进行多模态理解和生成。Janus 引入了 2 个独立的视觉编码路径:一个用于多模态理解,一个用于多模态生成,由相同的 Transformer 架构统一。
这有两个主要好处:
- Janus 减轻了源自多模态理解和生成的不同粒度需求的冲突,并消除了在选择视觉编码器时需要在 2 个任务之间进行权衡的需要。
- Janus 灵活且可扩展。在解耦后,理解和生成任务都可以采用各自领域里最先进的编码技术。
如图 3 所示是 Janus 的架构。对于纯文本理解、多模态理解和视觉生成,Janus 应用独立的编码方法将原始输入转换为特征,然后由统一的 Autoregressive Transformer 处理。
- 文本理解:使用 LLM 内置的 tokenizer 将文本转换为离散的 ID,并获得与每个 ID 对应的特征表征。
- 多模态理解:使用 SigLIPEncoder 从图像中提取高维语义特征。这些特征从二维网格 flattened 为一维序列,利用 Understanding Adaptor 将这些图像特征映射到 LLM 的输入空间。
- 图像生成:使用 LLamaGen中的 VQ tokenizer 将图像转换为离散的 ID。在 ID 序列被 flattened 为一维之后,使用 Generation Adaptor 将每个 ID 对应的 codebook embedding 映射到 LLM 的输入空间。
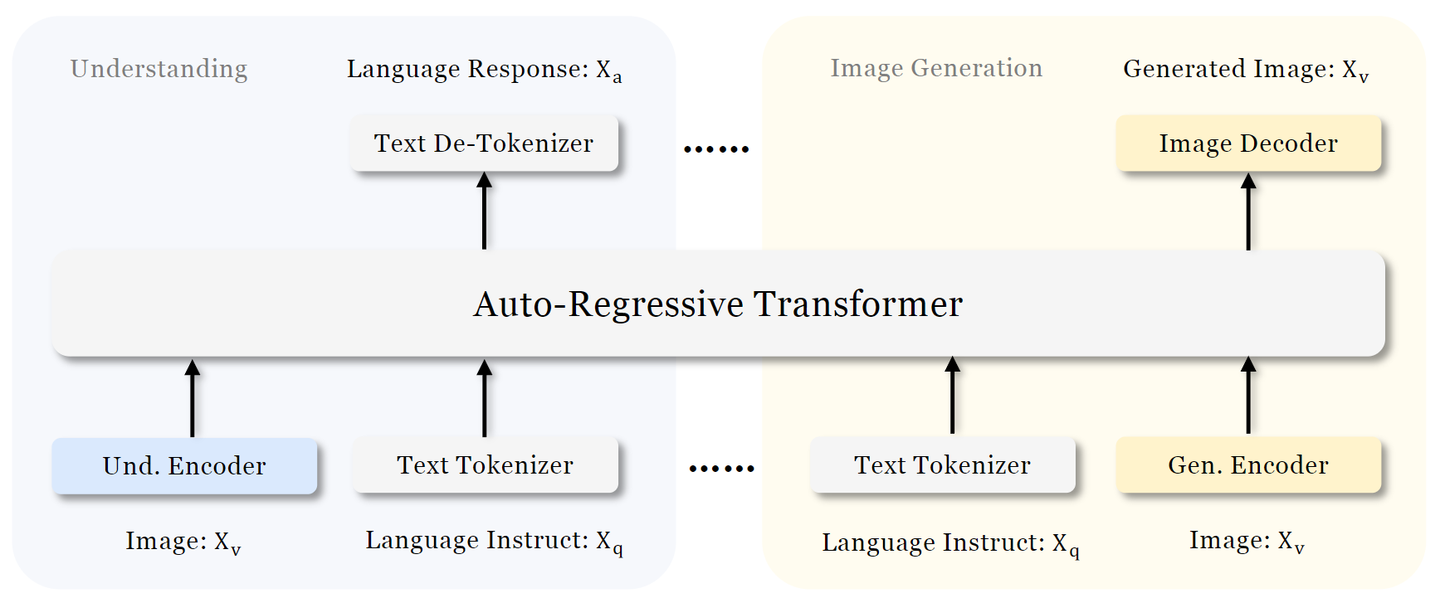
然后,将这些特征序列 Concatenate 起来形成一个多模态特征序列,然后将其输入到 LLM 进行处理。LLM 内置的预测头用于纯文本理解和多模态理解任务中的文本预测,而随机初始化的预测头用于生成任务中的图像预测。
整个模型遵循自回归框架,无需专门设计 Attention Mask。
训练策略
Janus 的训练分为 3 个阶段,如图所示:
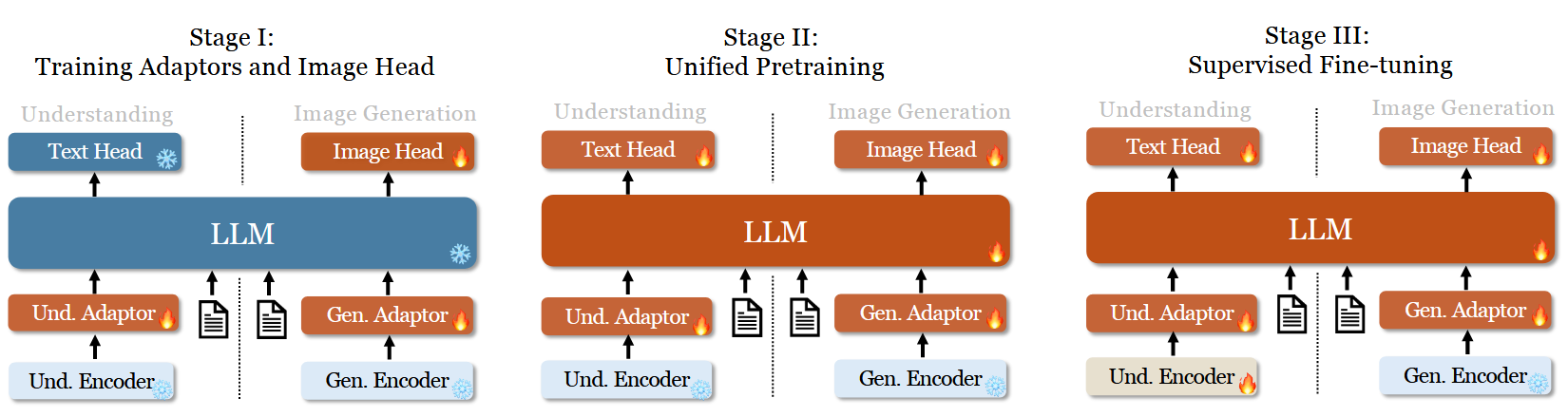
- 第 1 阶段:训练 Adaptors 和 Image Head。
- 第 2 阶段:联合预训练,除了理解编码器和生成编码器之外的所有组件都更新参数。
- 第 3 阶段:有监督微调,进一步解锁理解编码器的参数。
训练目标
Janus 是一个自回归模型,作者在训练期间简单地采用交叉熵损失:
这里,\(P(\cdot|\cdot)\) 表示由 Janus 的权重建模的条件概率。对于纯文本理解和多模态理解任务,作者计算纯文本序列的 loss。对于视觉生成任务,作者仅在图像序列上计算 loss。为了使设计简单,没有为不同的任务分配不同的权重。
推理过程
在推理过程中,Janus 模型采用 next-token prediction 方法。对于纯文本理解和多模态理解,作者遵循从预测分布顺序采样 token 的标准实践。对于图像生成,利用 classifier-free guidance (CFG),类似于先前的工作 Muse,LLamaGen。具体来说,对于每个 token,logit 的计算如下:
其中 \(l_c\) 是条件 logit, \(l_u\) 是无条件 logit, \(s\) 是无分类器指导的尺度。以下评估的默认数量为 5。
训练数据
- 阶段1:
- 阶段2:将数据组织成以下类别。
- 阶段3:
实验
Janus 利用最大支持序列长度为 4096 的 DeepSeek-LLM (1.3B)作为基础语言模型。对于理解任务中使用的视觉编码器,选择 SigLIP-Large-Patch16-384。generation encoder 有一个大小为 16,384 的 codebook,并将图像下采样 16 倍。Understanding Adaptor 和 Generation Adaptor 都是两层 MLP。所有图像都被调整为 384×384 像素。对于多模态理解数据,调整图像的长边,并用背景颜色 (RGB: 127, 127, 127) 填充短边,达到 384。对于视觉生成数据,短边被调整为 384,长边裁剪为 384。
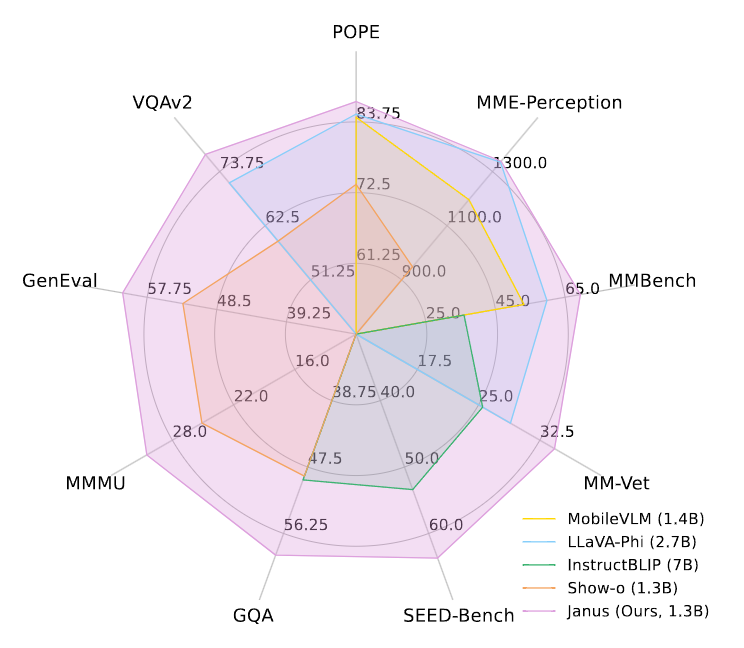
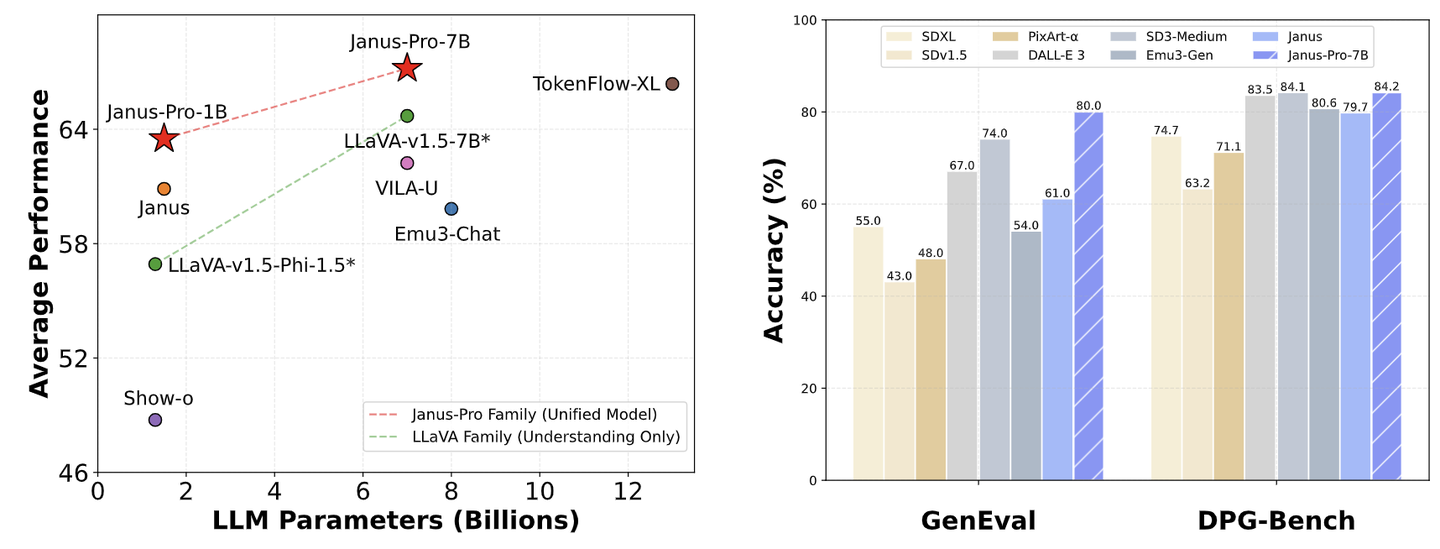
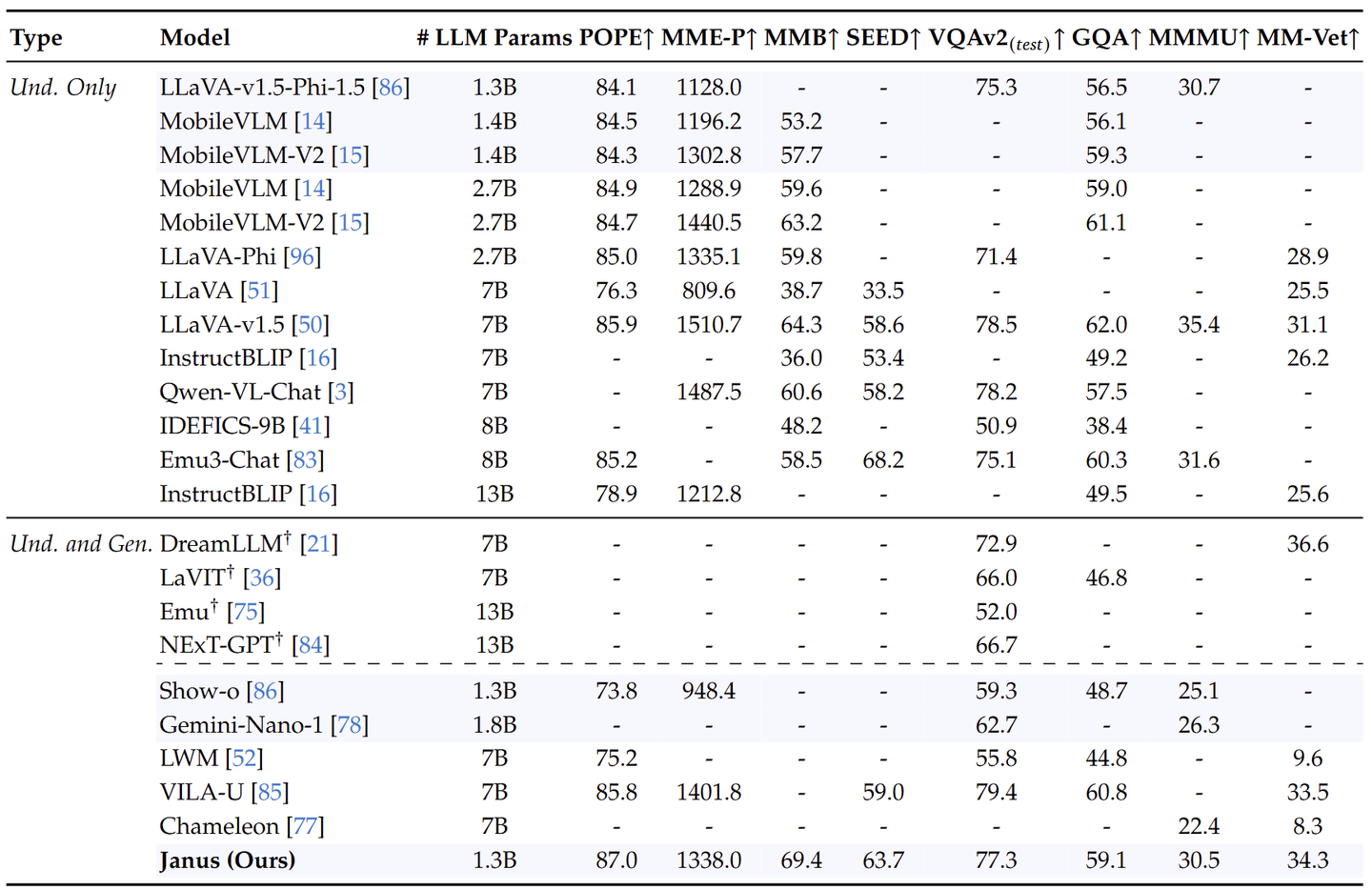
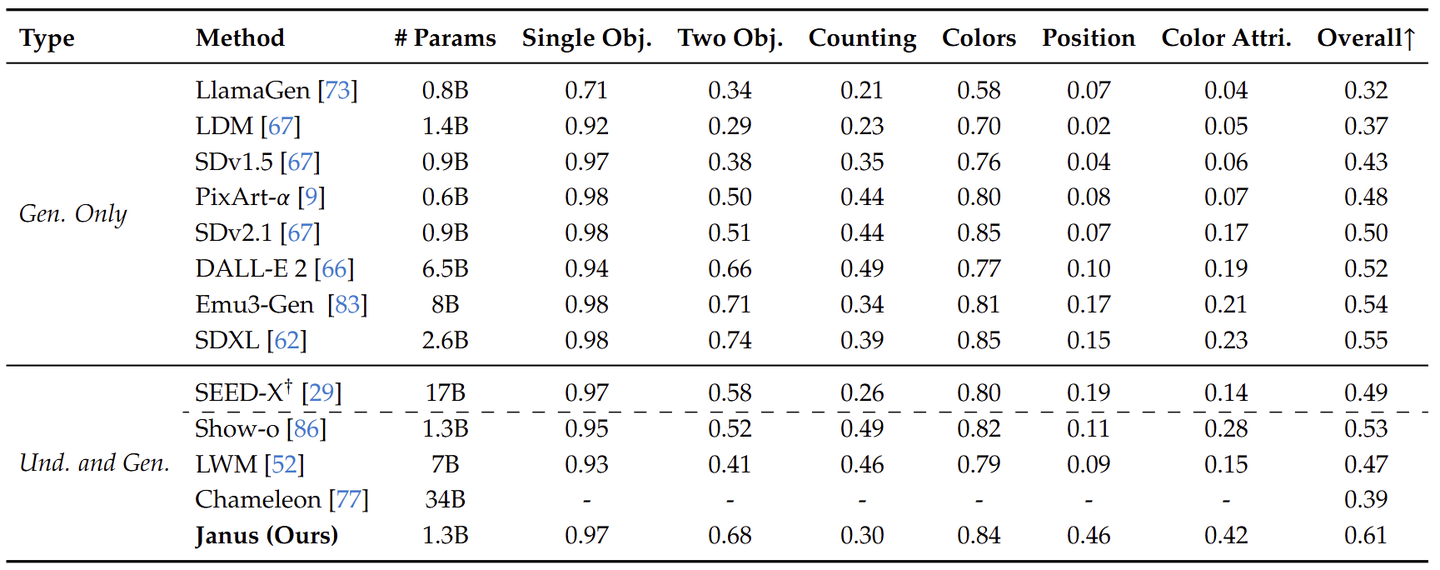
如下图 所示,比较了 Janus 与最先进的 Unified 模型以及 Understanding-only 模型。 Janus 在类似规模的模型中取得了最好的结果。具体来说,与之前的最佳统一模型 Show-o 相比,Janus 在 MME 和 GQA 数据集上分别实现了 41% (949 → 1338) 和 30% (48.7 → 59.1) 的性能改进。这可以归因于 Janus 将视觉编码解耦以进行多模态理解和生成,减轻了这两个任务之间的冲突。与尺寸明显较大的模型相比,Janus 仍然具有很强的竞争力。例如,Janus 在多个数据集上优于 LLaVA-v1.5 (7B),包括 POPE、MMbench、SEED Bench 和 MM-Vet。
Janus-Pro
模型
Janus 在 1B 参数量级上得到验证。然而,由于训练数据量有限,模型容量相对较小,存在一定的不足,例如:在短提示图像生成的性能次优,文生图质量不稳定。
Janus-Pro 是一种增强的 Janus 版本,结合了 3 个维度的改进:训练策略、数据和模型大小。Janus-Pro 系列包括两个模型大小:1B 和 7B,展示了视觉编码解码方法的可扩展性。
作者在多个基准上评估了 Janus-Pro,结果揭示了其优越的多模态理解能力,并显着提高了文生图的指令跟随性能。Janus-Pro-7B 在多模态理解基准 MMBench 上得分为 79.2,超过了最先进的统一多模态模型,例如 Janus (69.4)、TokenFlow (68.9) 和 MetaMorph (75.2)。此外,在文生图指令跟随排行榜 GenEval 中,Janus-Pro-7B 得分为 0.80,优于 Janus (0.61)、DALL-E 3 (0.67) 和 SD-3 Medium (0.74)。

Janus-Pro 的模型架构与 Janus 完全相同。整体架构的核心设计原则是将视觉编码解耦以进行多模态理解和生成。应用独立的编码方法将原始输入转换为特征,然后由 Unified Autoregressive Transformer 来处理。
对于多模态理解,使用 SigLIP Encoder 从图像中提取高维语义特征 (和 Janus 一致)。这些特征从二维网格 flattened 为一维序列,利用 Understanding Adaptor 将这些图像特征映射到 LLM 输入空间。
对于视觉生成任务,使用 LLamaGen中的 VQ tokenizer 将图像转换为离散的 ID (和 Janus 一致)。在 ID 序列被 flattened 为 1D 之后,使用 Generation Adaptor 将每个ID 对应的 codebook 嵌入映射到 LLM 输入空间。
然后,作者将这些特征序列连接起来形成一个多模态特征序列,然后将其输入到 LLM 进行处理。除了 LLM 的内置预测头外,作者还利用随机初始化的预测头进行视觉生成任务中的图像预测 (和 Janus 一致)。整个模型遵循 Autoregressive 框架。