搜索引擎概述
推荐和搜索比较
推荐系统和搜索应该是机器学习乃至深度学习在工业界落地应用最多也最容易变现的场景。而无论是搜索还是推荐,本质其实都是匹配,搜索的本质是给定query,匹配doc;推荐的本质是给定user,推荐item。
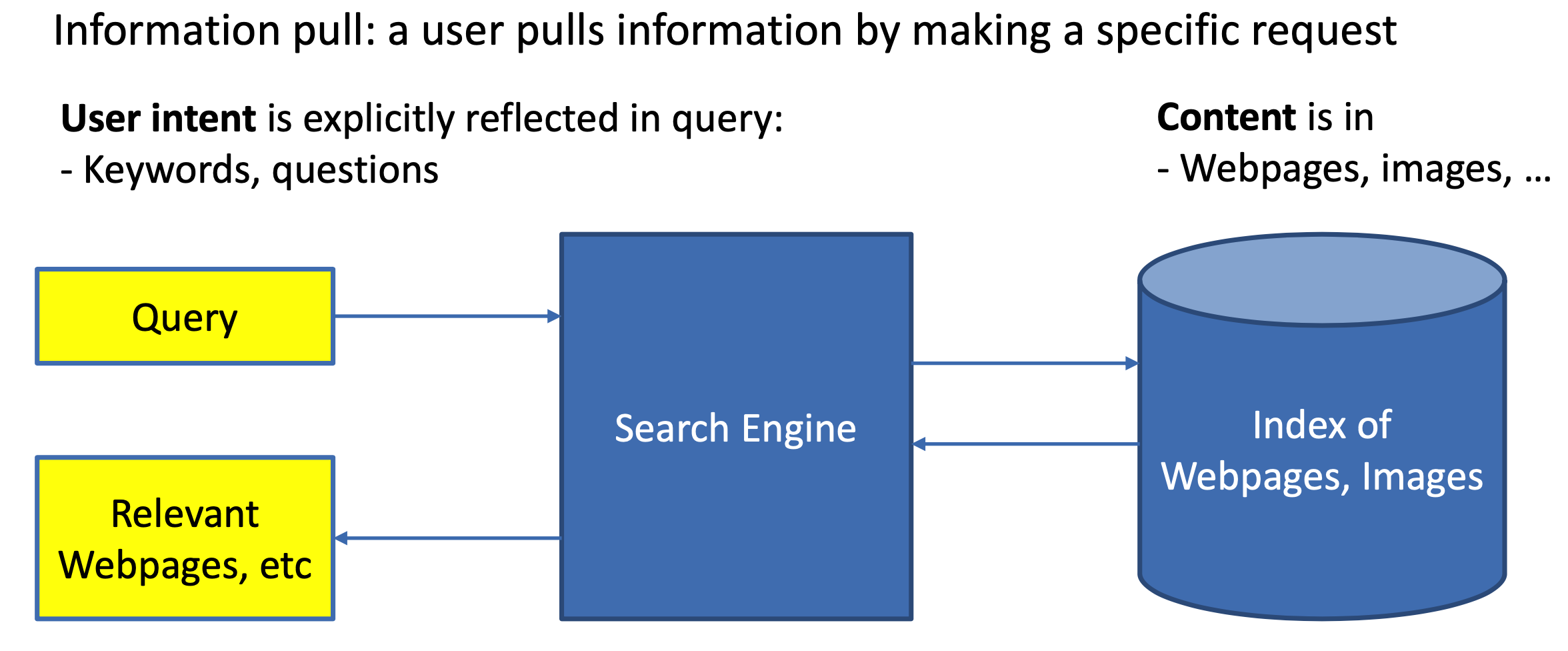
对于搜索来说,搜索引擎的本质是对于用户给定query,搜索引擎通过query-doc的match匹配,返回用户最可能点击的文档的过程。从某种意义上来说,query代表的是一类用户,就是对于给定的query,搜索引擎要解决的就是query和doc的match,如图1.1所示。
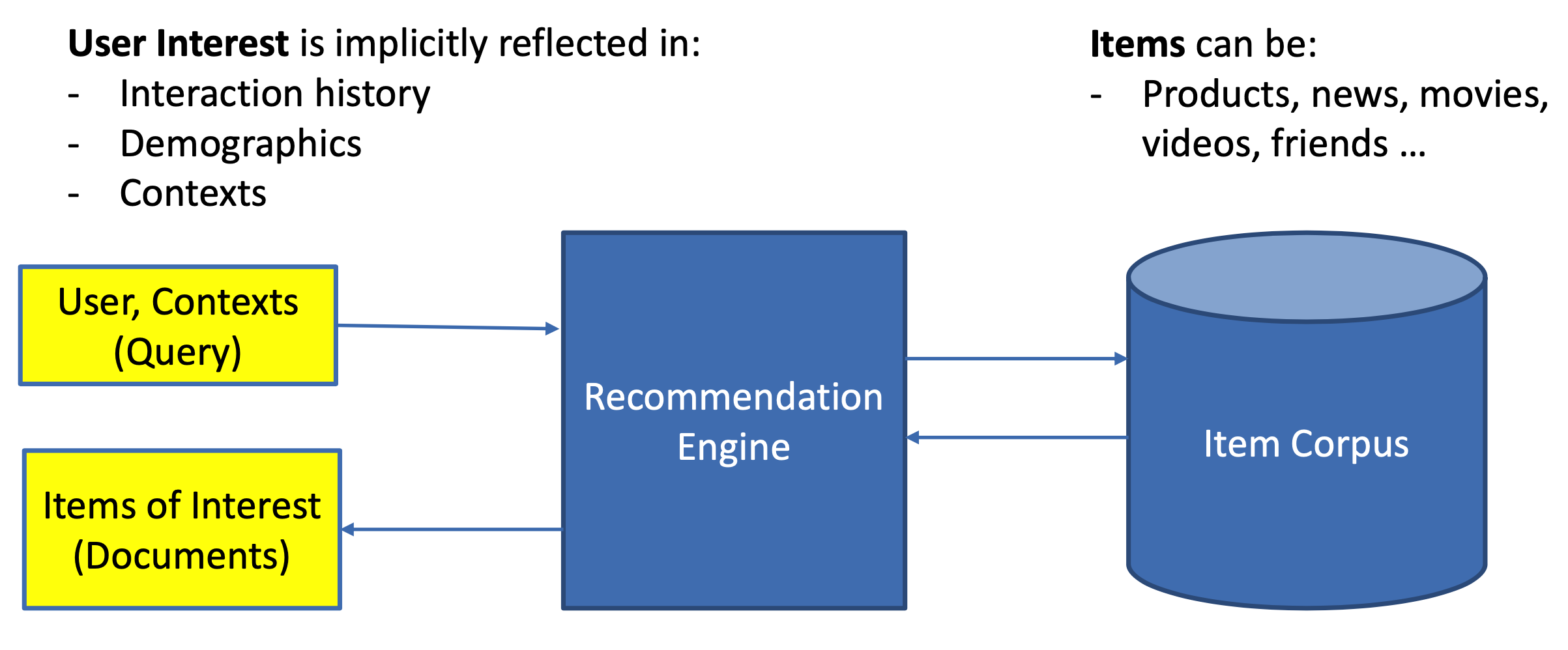
对于推荐来说,推荐系统就是系统根据用户的属性(如性别、年龄、学历等),用户在系统里过去的行为(例如浏览、点击、搜索、收藏等),以及当前上下文环境(如网络、手机设备等),从而给用户推荐用户可能感兴趣的物品(如电商的商品、feeds推荐的新闻、应用商店推荐的app等),从这个过程来看,推荐系统要解决的就是user和item的match,如图1.2所示。
不同之处
- 意图不同
搜索是用户带着明确的目的,通过给系统输入query来主动触发的,搜索过程用户带着明确的搜索意图。而推荐是系统被动触发,用户是以一种闲逛的姿态过来的,系统是带着一种“猜”的状态给用户推送物品。
简单来说,搜索是一次主动pull的过程,用户用query告诉系统,我需要什么,你给我相关的结果就行;而推荐是一次push的过程,用户没有明显意图,系统给用户被动push认为用户可能会喜欢的东西吧。
- 时效不同
搜索需要尽快满足用户此次请求query,如果搜索引擎无法满足用户当下的需求,例如给出的搜索结果和用户输入的query完全不相关,尽是瞎猜的结果,用户体验会变得很差。
推荐更希望能增加用户的时长和留存从而提升整体LTV(long time value,衡量用户对系统的长期价值),例如视频推荐系统希望用户能够持续的沉浸在观看系统推荐的视频流中;电商推荐系统希望用户能够多逛多点击推荐的商品从而提高GMV。
- 相关性要求不同
搜索有严格的query限制,搜索结果需要保证相关性,搜索结果量化评估标准也相对容易。给定一个query,系统给出不同结果,在上线前就可以通过相关性对结果进行判定相关性好坏。例如下图中搜索query为“pool schedule”,搜索结果“swimming pool schedule”认为是相关的、而最后一个case,用户搜索“why are windows so expensive”想问的是窗户为什么那么贵,而如果搜索引擎将这里的windows理解成微软的windows系统从而给出结果是苹果公司的mac,一字之差意思完全不同了,典型的bad case。

而推荐没有明确的相关性要求。一个电商系统,用户过去买了足球鞋,下次过来推荐电子类产品也无法说明是bad case,因为用户行为少,推完全不相关的物品是系统的一次探索过程。推荐很难在离线阶段从相关性角度结果评定是否好坏,只能从线上效果看用户是否买单做评估。
- 实体不同
搜索中的两大实体是query和doc,本质上都是文本信息。这就是上文说到的为什么搜索可以通过query和doc的文本相关性判断是否相关。Query和doc的匹配过程就是在语法层面理解query和doc之间gap的过程。
推荐中的两大实体是user和item,两者的表征体系可能完全没有重叠。例如电影推荐系统里,用户的特征描述是:用户id,用户评分历史、用户性别、年龄;而电影的特征描述是:电影id,电影描述,电影分类,电影票房等。这就决定了推荐中,user和item的匹配是无法从表面的特征解决两者gap的。

- 个性化要求不同
虽然现在但凡是一个推荐系统都在各种标榜如何做好个性化,“千人千面”,但搜索和推荐天然对个性化需求不同。搜索有用户的主动query,本质上这个query已经在告诉系统这个“用户”是谁了,query本身代表的就是一类用户,例如搜索引擎里搜索“深度学习综述”的本质上就代表了机器学习相关从业者或者对其感兴趣的这类人。在一些垂直行业,有时候query本身就够了,甚至不需要其他用户属性画像。例如在app推荐系统里,不同的用户搜索“京东”,并不会因为用户过去行为、本身画像属性不同而有所不同。
而推荐没有用户主动的query输入,如果没有用户画像属性和过去行为的刻画,系统基本上就等于瞎猜。
相同之处
- 本质是都是match过程
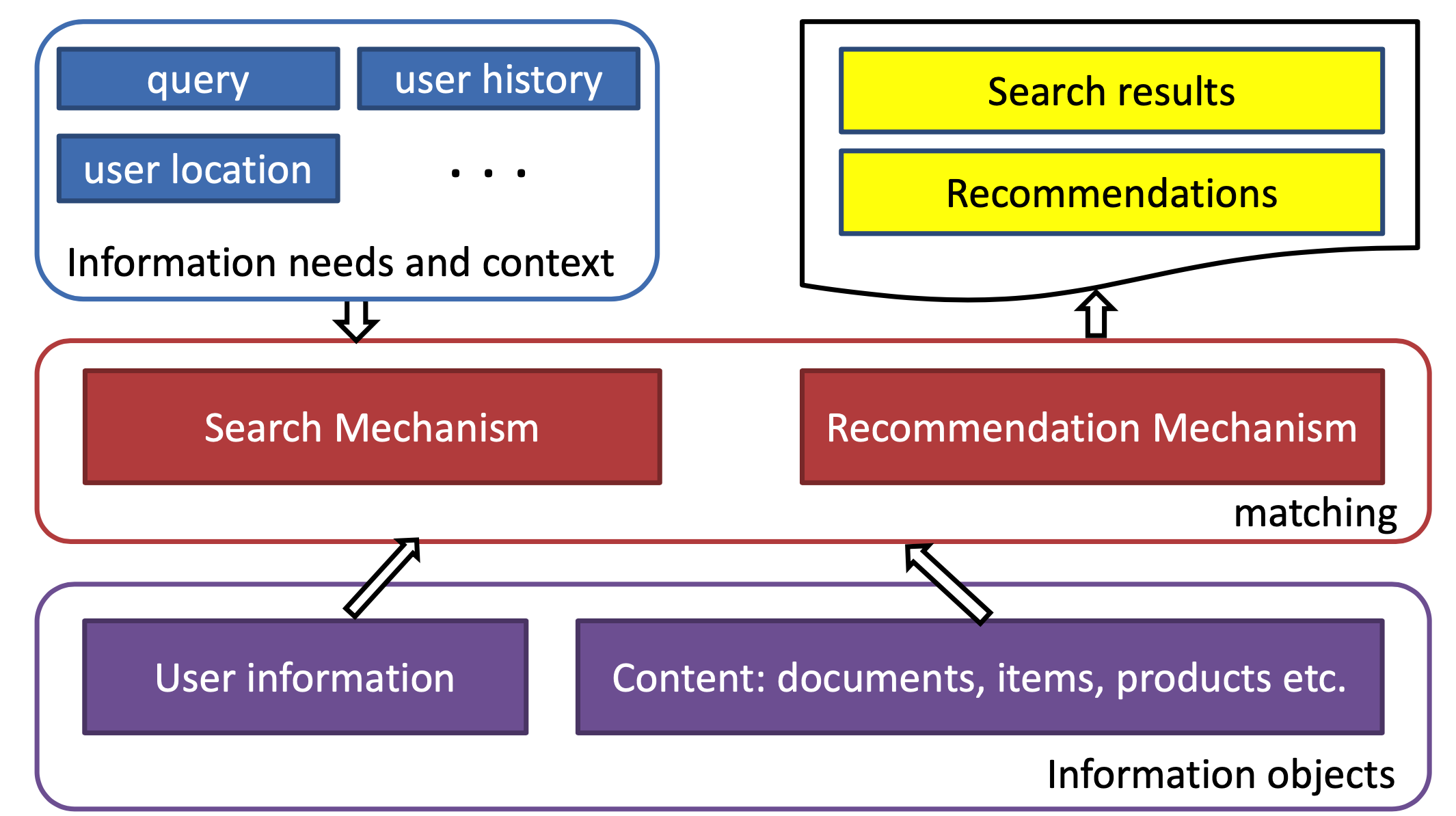
如果把user比作query,把item比作doc,那么推荐和搜索在这个层面又是相同的,都是针对一个query(一个user),从海量的候选物品库中,根据query和doc的相关性(user过去的历史、画像等和item的匹配程度),去推荐匹配的doc(item)
- 目标相同
搜索和推荐的目标都是针对一次context(或者有明确意图,或者没有),从候选池选出尽可能满足需求的物品。两者区别只是挑选过程使用的信息特征不同。
- 语义鸿沟(semantic gap)都是两者最大的挑战
在搜索里表现是query和doc的语义理解,推荐里则是user和item的理解。例如,搜索里多个不同的query可能表示同一个意图;而推荐里用来表示user和item的特征体系可能完全不是一个层面的意思。
搜索匹配
在目前工业界的大多数主流系统里,推荐系统和搜索引擎一般分为召回和排序两个过程,这个两阶段过程称呼较多,召回也会叫粗排、触发、matching;排序过程也会叫精排、打分、ranking。
而在本文要讲到的匹配,并不仅仅指的是第一阶段这个matching的过程,而是泛指整个query和doc的匹配。图1.6可以表示本文要讲的query和doc的匹配表示,通过给定的training data,通过learning system,学习得到query和doc的匹配模型\(f_M(q, d)\)。然后对于test data,也就是给定的需要预测的\(q\)和\(d\),便可以通过这个模型,预测得到\(q\)和\(d\)的匹配分数\(f_M(q, d)\)。

由于query和doc本身都是文本表示,所以本质上来说,这篇文章要讲的东西也是文本的深度匹配模型。大部分自然语言处理的任务基本都可以抽象成文本匹配的任务。
- 信息检索(Ad-hoc Information Retrieval):也就是本文要介绍的主体,在搜索引擎里,用户搜索的query以及网页doc是一个文本匹配的过程
- 自动问答(Community Question Answer): 对于给定的问题question,从候选的问题库或者答案库中进行匹配的过程
- 释义识别(Paraphrase Identification):判断两段文本string1和string2说的到底是不是一个事儿
- 自然语言推断(Natural Language Inference):给定前提文本(premise),根据该premise去推断假说文本(hypothesis)与premise的关系,一般分为蕴含关系和矛盾关系,蕴含关系表示从premise中可以推断出hypothesis;矛盾关系即hypothesis与premise矛盾。
搜索中的传统匹配模型
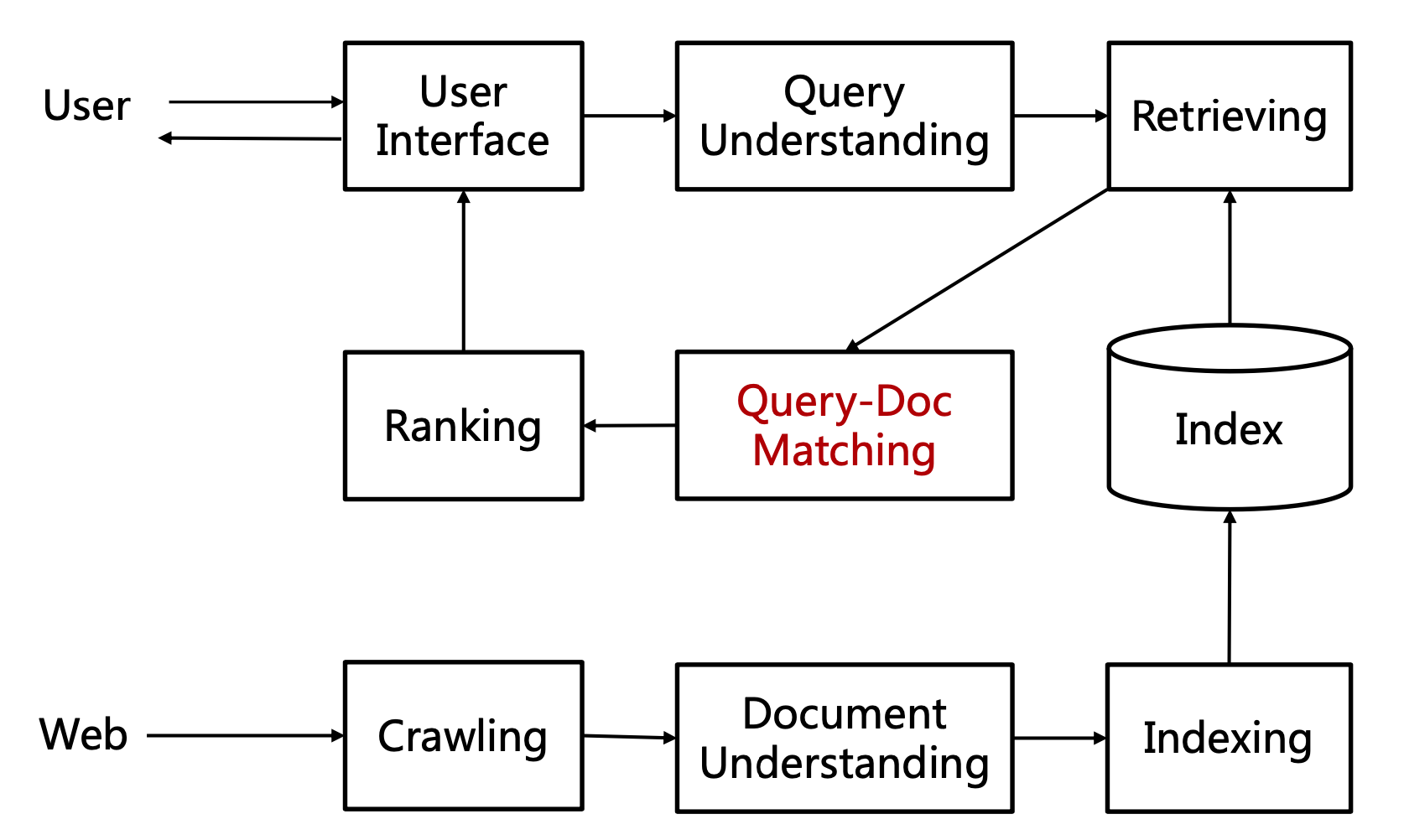
图2.1表示的是 query-doc的匹配在整个搜索引擎流程中的流程。在讲整个搜索的深度匹配模型之前,我们先来看下传统的匹配模型。
更早之前有基于term的统计方法,例如TF-IDF等,而从match的角度,按照query和doc是否映射到同一个空间,可以分为两大类,一类是基于隐空间的match,将query和doc都映射到同一个latent space,如图2.2所示;第二种是基于翻译空间的match,将doc映射到query的空间,然后学习两者的匹配。
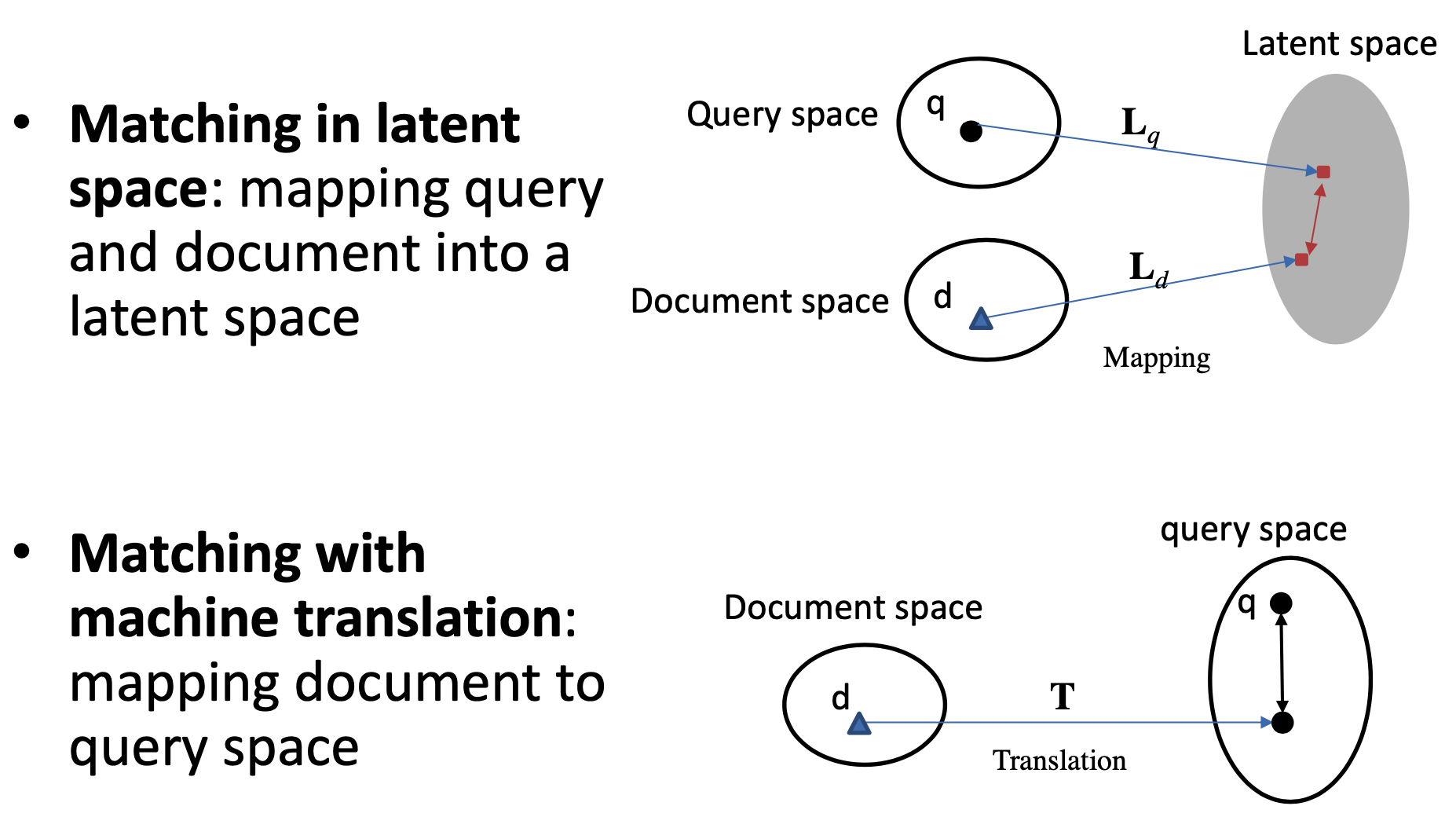
基于latent space的传统匹配方法
BM25
对于第一种方法,基于隐空间的匹配,重点是将query和doc都同时映射到同一空间,经典的模型有BM25。BM25方法核心思想是,对于query中每个term,计算与当前文档doc的相关性得分,然后对query中所有term和doc的相关得分进行加权求和,可以得到最终的BM25,整体框架如图2.3所示
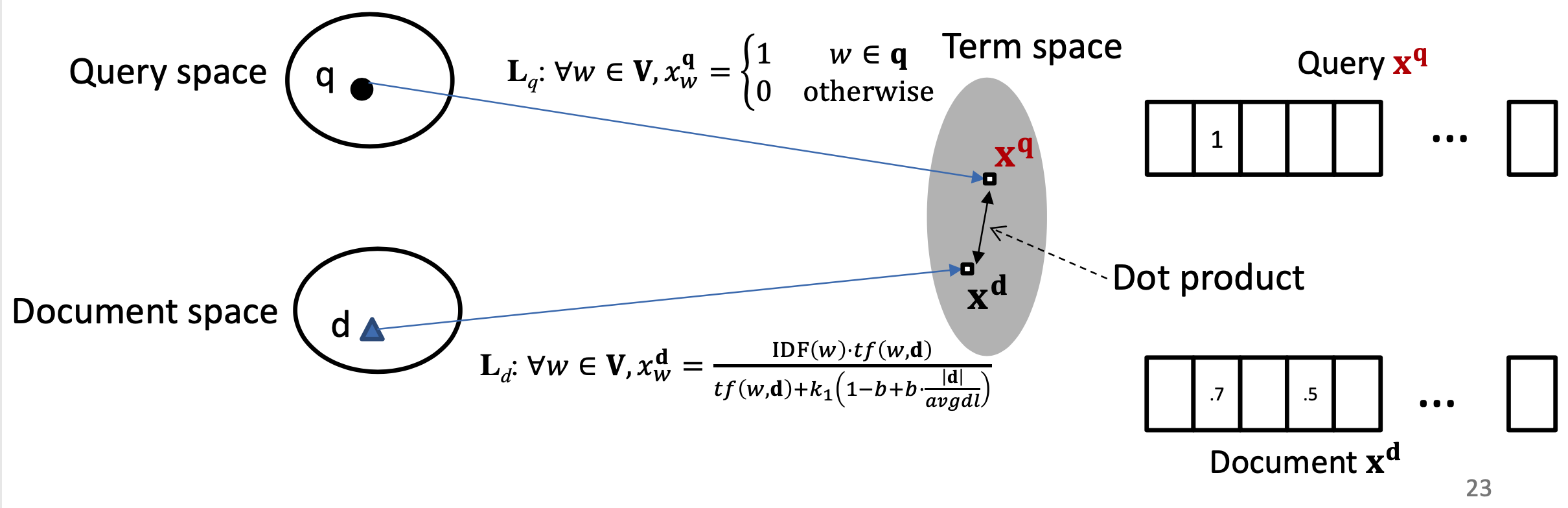
对于query的表示采用的是布尔模型表达,也就是term出现为1,否则为0;
BM25公式为query中所有term的加权求和表达,可以分为两部分,第一部分是每个term \(q_i\)的权重,用IDF表示,也就是一个term在所有doc中数显次数越多,说明该\(q_i\)对文档的区分度越低,权重越低。
公式中第二部分计算的是当前term \(q_i\)与doc d的相关得分,分子表示的是\(q_i\)在doc中出现的频率;分母第中\(dl\)为文档长度,\(avgdl\)表示所有文档的平均长度,\(|d|\)为当前文档长度,\(k1\)和\(b\)为超参数。直观理解,如果当前文档长度\(|d|\)比平均文档长度\(avgdl\)大,包含当前query中的term \(q_i\)概率也越高,对结果的贡献也应该越小。
PLS方法
PLS方法全称是Partial Least Square,用偏最小二乘的方法,将query和doc通过两个正交映射矩阵LX和LY映射到同一个空间后得到向量点积,然后通过最大化正样本和负样本的点积之差,使得映射后的latent space两者的距离尽可能靠近。
- query和doc的空间表示
- 训练数据和模型
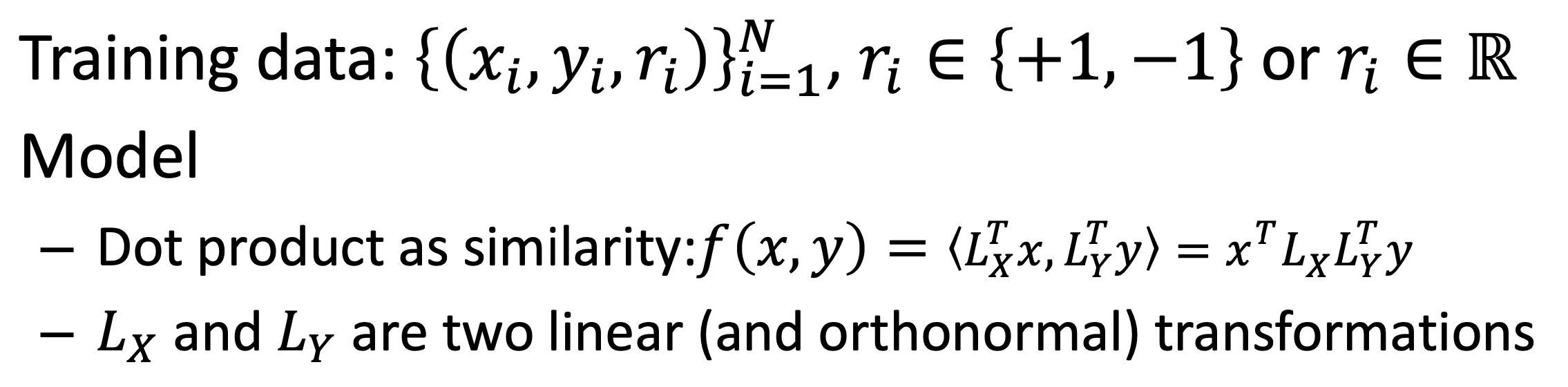
用两个线性映射矩阵\(L_X\)和\(L_Y\)分别将query和doc的原始空间\(x\)和\(y\)映射后的点积作为匹配分数,并且要求两个转化矩阵都必须是正交的
- 优化目标
上述用映射后的空间的向量点积作为匹配分数,在求最优化时,目标就是最大化正样本query-doc的pair对,以及负样本query-doc的pair对的向量点击差异,并且满足两个转化矩阵\(L_X\)和\(L_Y\)都是正交的约束条件,如下公式所示
RMLS模型
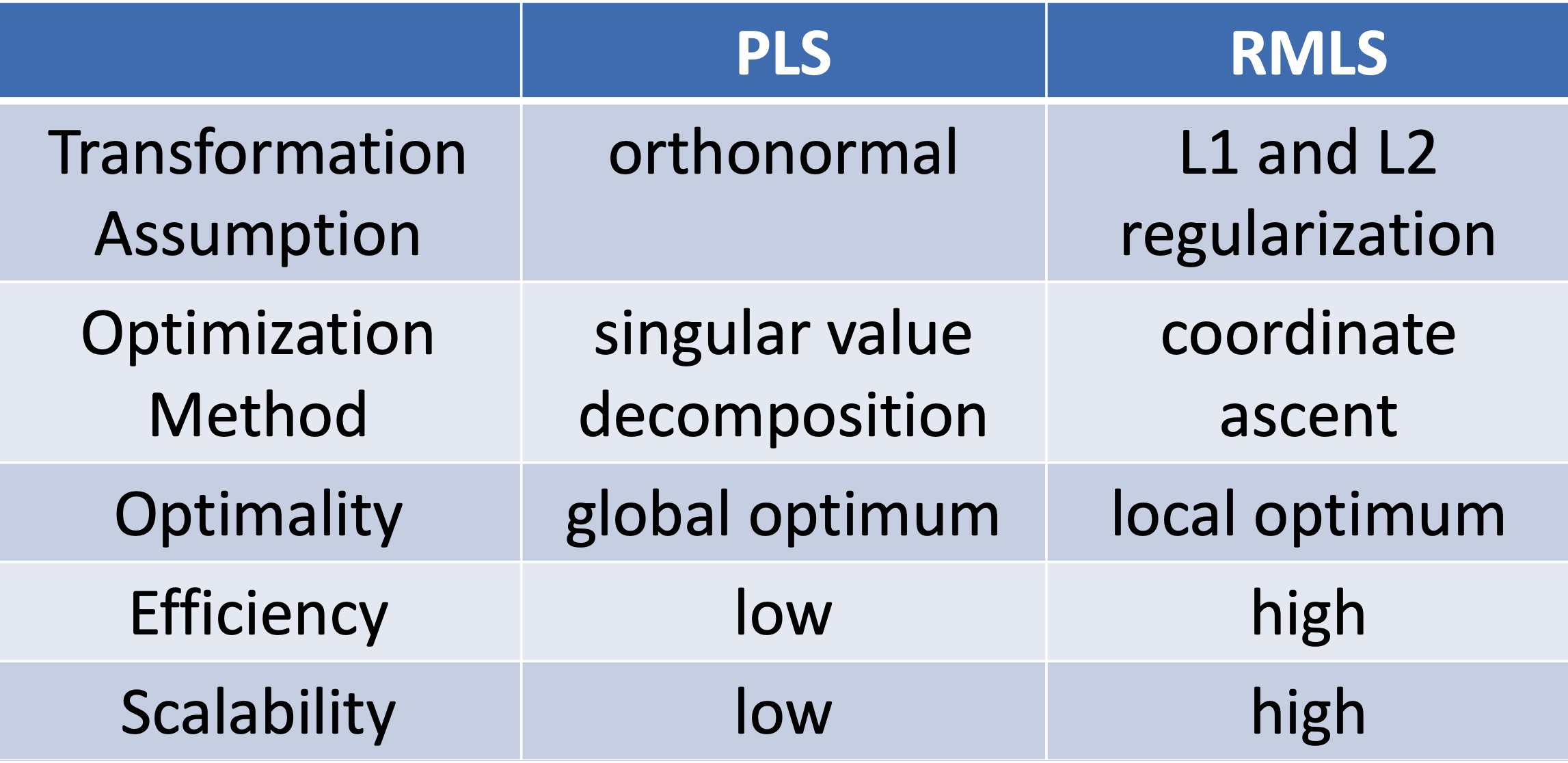
Regularized Mapping to Latent SpacePLS在空间表示、训练数据以及优化目标表示上都一致,区别在于转化矩阵\(L_X\)和\(L_Y\)上,PLS模型的基本假设要求两个矩阵是正定的;而RMLS模型在此基础上加入了正则限制,整体优化目标下公式所示
总结下PLS和RMLS的特点如下:
基于translation的传统匹配方法
query和doc的匹配过程,就是将原本属于不同空间的两段文本映射到一个空间后进行匹配。基于translation的方法把这个过程类比于机器翻译过程:query看成是目标语言E,把doc看成是源语言C,目的是为了得到源语言到目标语言的概率 \(P(E|C)\) 最大化,也就是\(P(query|doc)\) 最大化
SMT模型
Baseline方法的基于统计机器翻译的方法,给定源语言C(document),以及目标语言E(query),从源语言到目标语言的翻译过程,就是将doc映射到query的过程。
其中,\(h(C,E)\)是关于\(C\)和\(E\)的特征函数。整个求解过程看成是特征函数的线性组合
WTM模型
Word-base Translation Model,简称WTM模型,把doc和query的关系看成是概率模型,也就是给定doc,最大化当前的query的概率。Doc生成query的过程可以看成两部分组成,第一项\(p(q|w)\)是概率模型,也就是doc中的单词\(w\),翻译到当前query的单词q的概率,称为translation probability;\(p(w|d)\)注意doc是加粗表示整个文档,也就是doc生成每个单词w的概率,称为document language model。
上述公式将doc->query的翻译过程拆成了两个模型的连乘,对于很多稀疏的term,一旦出现某个概率为0,最终结果也将变为0。为了防止这种情况就需要做平滑,下述公式通过引入background language model的\(p(q|C)\),并且用参数\(\alpha\)进行线性组合来做平滑。\(C\)代表的是整个collection.
从贝叶斯公式,可以得到\(p(q|C)\)以及\(p(w|D)\)的表达;\(C(q;C)\)表示的是当前query的单词q在整个collection出现的次数;\(C(w;D)\)表示的是单词w在文档D中出现的次数
但是这种方法也存在问题,就是self-translation问题。原本这个问题是在机器翻译过程中,但是在query和doc过程中,源语言和目标语言都是同一种语言,也就是doc中的每个term都有可能映射到query中相同的term,即\(p(q=w|w)>0\)。因此,CIKM2010年引入了unsmoothed document language model,也就是\(p(q|d)\)来解决这种问题
基于representation learning的深度匹配模型
在搜索的深度模型匹配中,我们发现这一步和推荐系统的深度匹配模型一样,也可以分为两类模型,分别是基于representation learning的模型以及match function learning的模型。
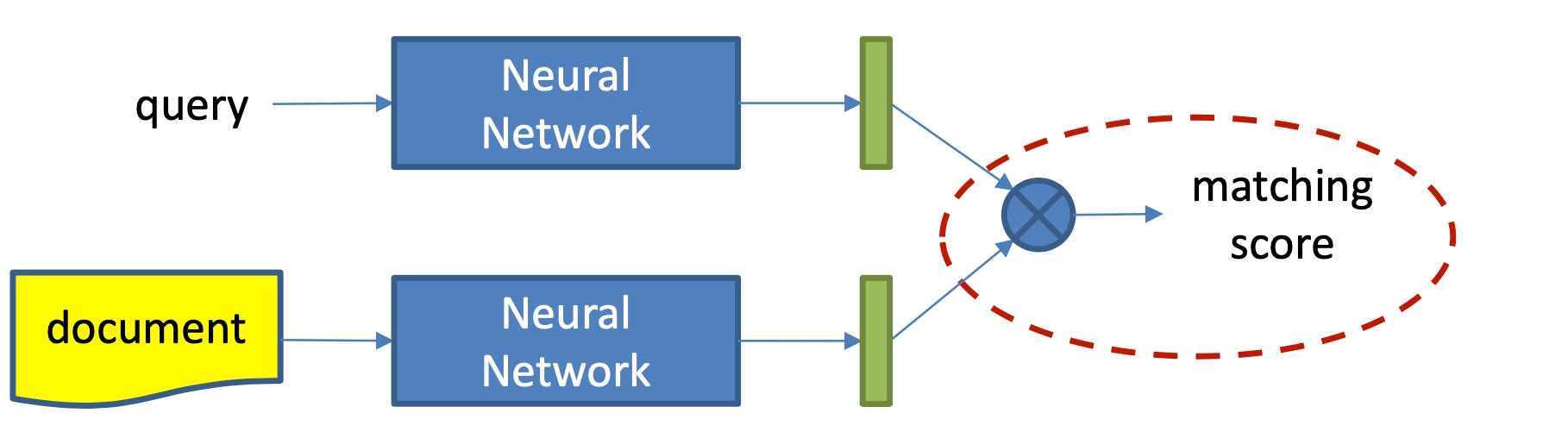
本章主要讲述第一种方法,representation learning,也就是基于表示学习的方法,这种方法会分别学习query和doc(放在推荐里就是user和item)的representation表示,然后通过定义matching score函数,例如简单点的做法有向量点积、cosine距离等来得到query和doc两者的匹配,整个representation learning的框架如图3.1所示,是个经典的双塔结构。
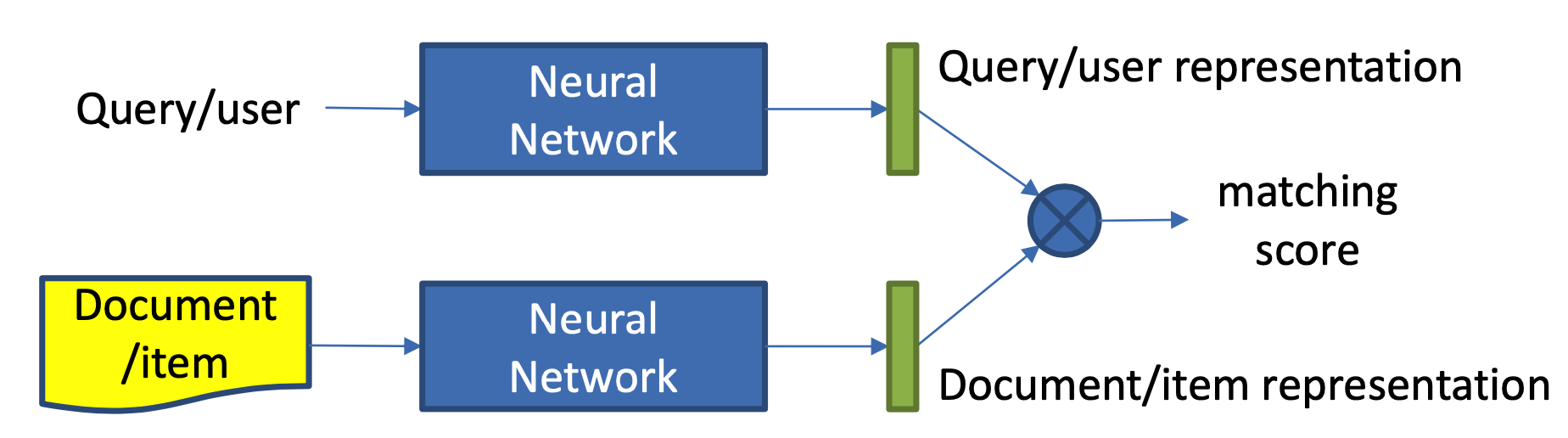
整个学习过程可以分为两步:
- 表示层:计算query和doc各自的representation,如图3.2中蓝色圈所示
- 匹配层:根据上一步得到的representation,计算query-doc的匹配分数,如图3.2中红色圈所示
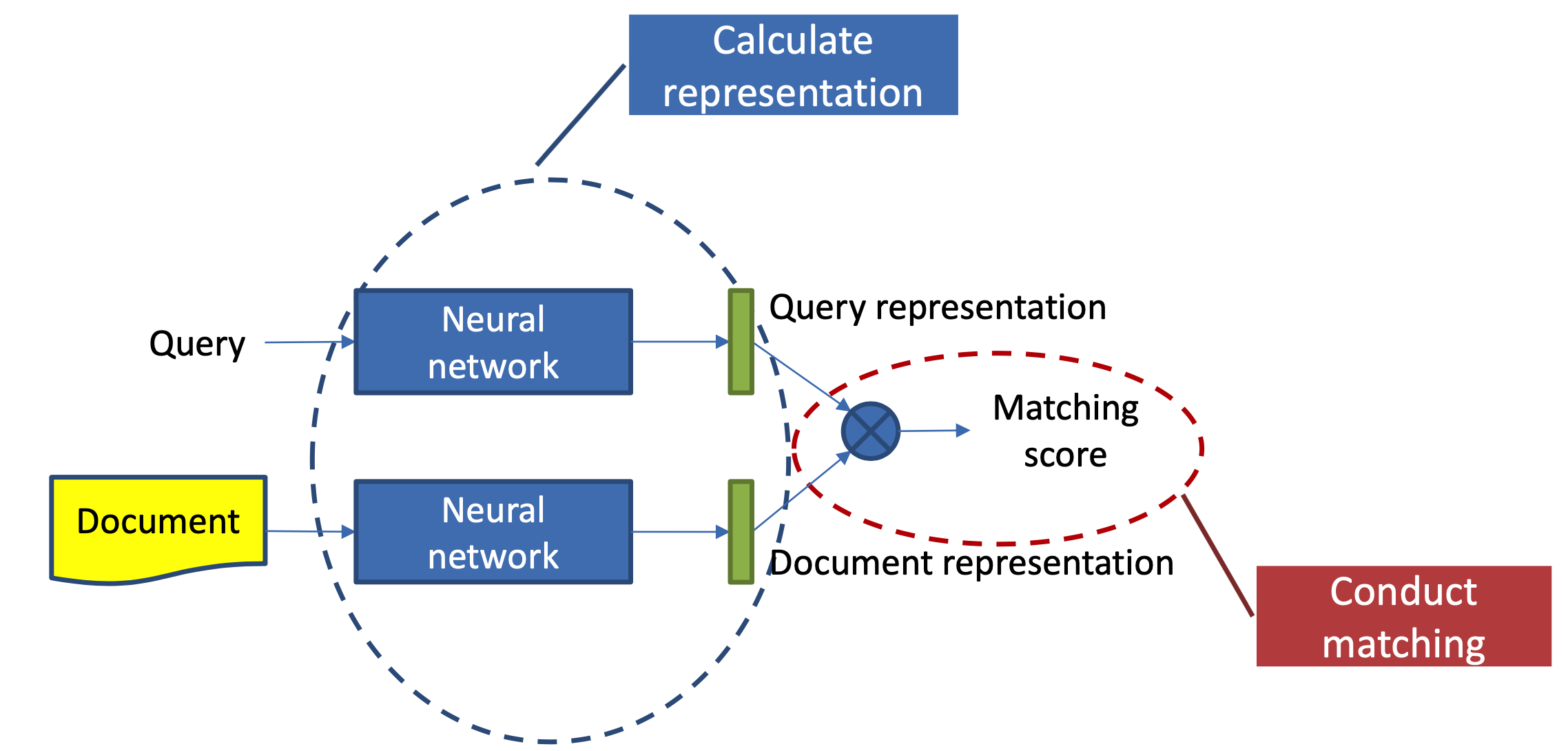
因此,基于representation learning的深度匹配模型,无外乎围绕着表示层和匹配层进行模型结构的改造,其中大部分工作都集中在表示层部分。表示层的目的是为了得到query和doc的向量,在这里可以套用常用的一些网络框架,如DNN、CNN或者RNN等,本章也将沿着这3种框架进行表述。
representation learning匹配模型的特点是:
- 采用 Siamese 结构,共享网络参数。
- 对表示层进行编码,使用 CNN, RNN, Self-attention 均可。
- 匹配层进行交互计算,采用点积、余弦相似度、高斯距离、相似度矩阵均可。
基于DNN的模型
DSSM模型
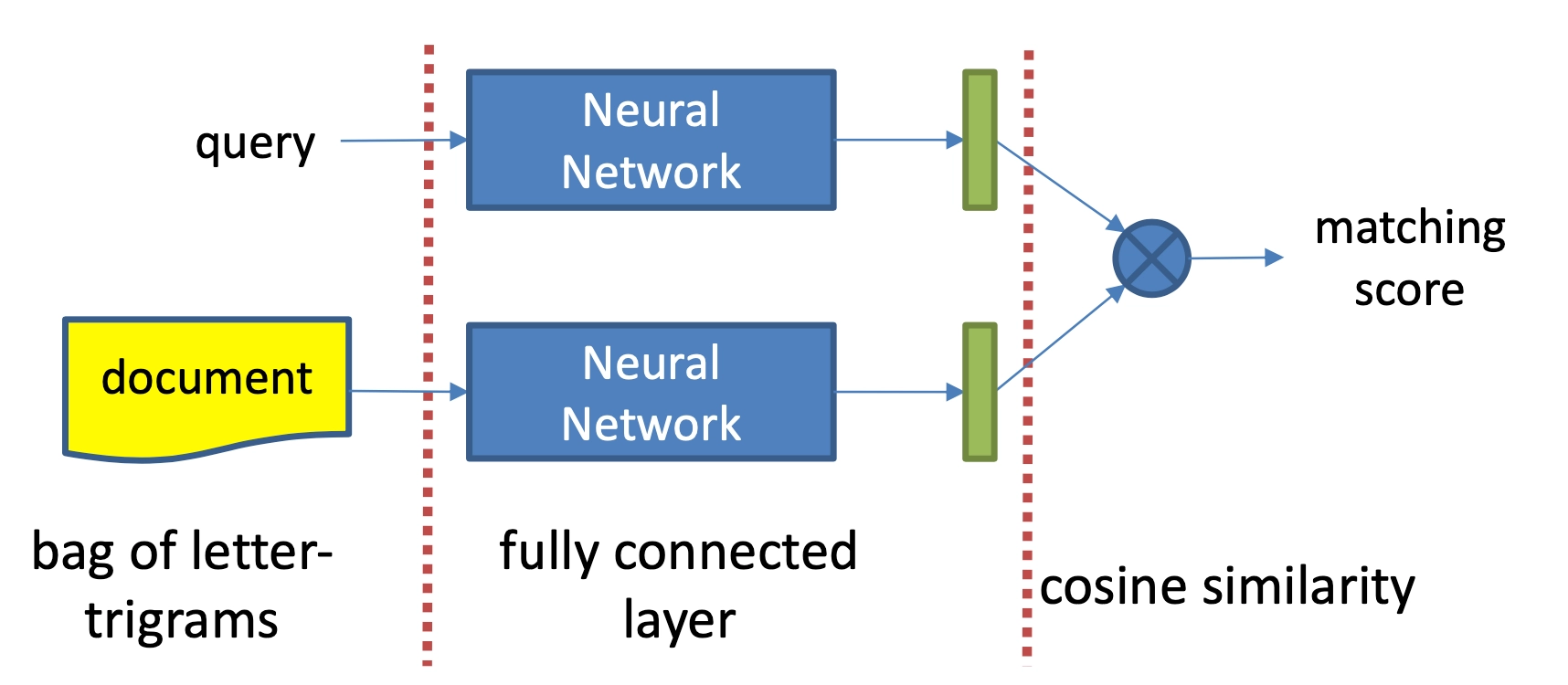
DSSM模型全称是deep struct semantic model,是微软在2013年提出来的深度匹配模型,后续一举成为表示学习的框架鼻祖。同年百度NLP团队也提出了神经网络语义匹配模型simnet,本质上两者在模型框架上是一致的,如图3.3所示,都是典型的双塔模型,通过搜索引擎里query和doc的海量用户曝光点击日志,用DNN把query和doc通过表示层,表示为低维的embedding向量,然后通过匹配层来计算query和doc的embedding向量距离,最终得到匹配分数。
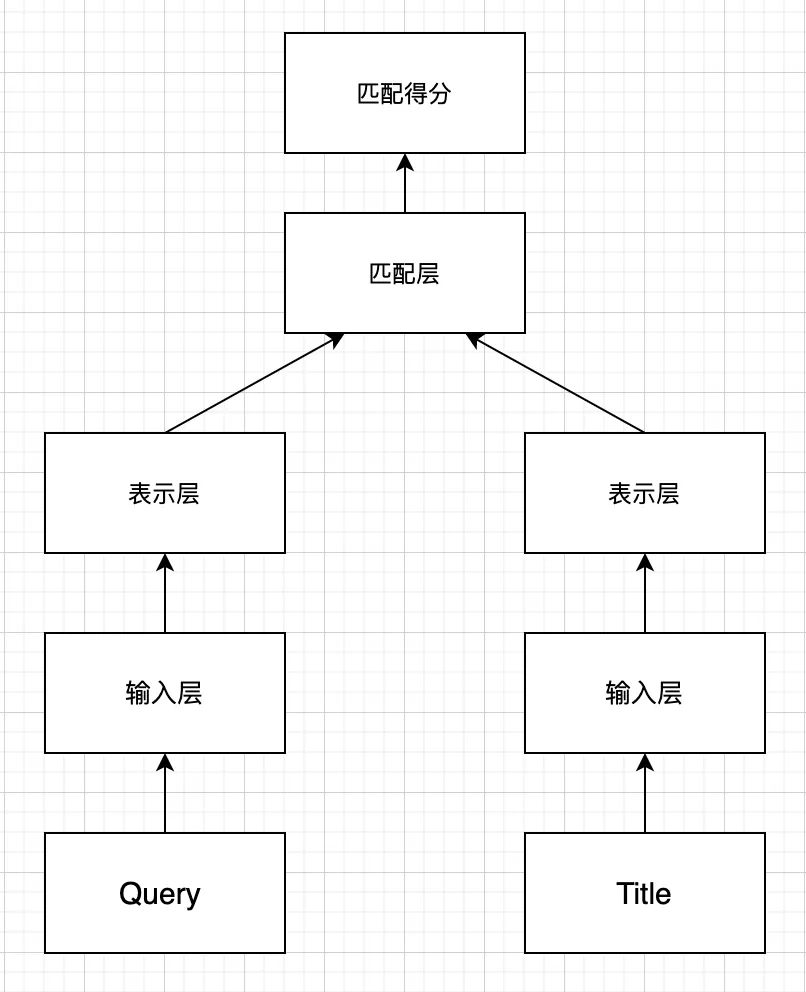
传统的搜索文本相关性模型,如BM25通常计算Query与Doc文本term匹配程度。由于Query与Doc之间的语义gap, 可能存在很多语义相关,但文本并不匹配的情况。为了解决语义匹配问题,出现很多LSA,LDA等语义模型。随着深度学习在NLP的应用,在IR和QA(问答系统)中出现了很多深度模型将query和doc通过神经网络embedding,映射到一个稠密空间的向量表示,然后再计算其是否相关,并取得很好的效果。
DSSM作为框架型的模型得到大范围应用,除了其简洁经典的三段式结构:输入层-表示层-匹配层来得到最终的匹配得分,还有个很重要的原因:通过表示层得到的query和doc的向量是个非常重要的产物,可以在后续很多任务如召回层等地方继续使用。
整个DSSM可以分为3层,输入层、表示层和输出层
- 输入层
输入层做的事情是把原始的句子(query或者doc)映射到一个向量空间并进入表示层。这里由于中文和英文本身的构造不同,在处理方式上也有所不同。
- 英文输入
DSSM论文里对英文的处理方式是word hashing,对于每个单词前后都用#表示作为开始符和结束符。例如对于单词boy,采用n-gram方式表达,以trigram为例(\(n=3\)),将表示为#bo, boy, boy# 这三个trigram。由于这种切分方法是在letter字符级别的,因此称为letter-trigram,目的是为了区分后面会提到的其他trigram方法。
这种方法可能存在的一个问题就是单词冲突问题。举个例子,god和dog采用原始的one-hot是两个不同单词,但是用trigram的话这两个词的输入将是一个向量,因此产生了冲突。
通过word hash的方式有两个好处,第一是可以大大减少原始输入空间。以4万单词为例,采用trigram的hash方法以后,将压缩到1万左右的输入空间。而对于一个50万单词的词表的话,将压缩到3万,与此同时trigram的冲突率只有22/50w=.0044%

- 中文输入
对于中文而言,没有英文输入这种char级别的语法构造,因此不适用word hash的方法。在NLP领域对中文的原始输入都会采用各种分词工具进行分词的预处理,而对于正常规模的汉字,单字规模1.5万左右,双字规模在百万左右,因此对于中文的输入,采用的是单字的输入
- 表示层
在DSSM中表示层采用的是词袋模型(bag of words),也就是说不区分word的输入顺序,整个句子的所有单词都是无序输入的。这也为后面各种DSSM-based模型提供了很多优化工作。
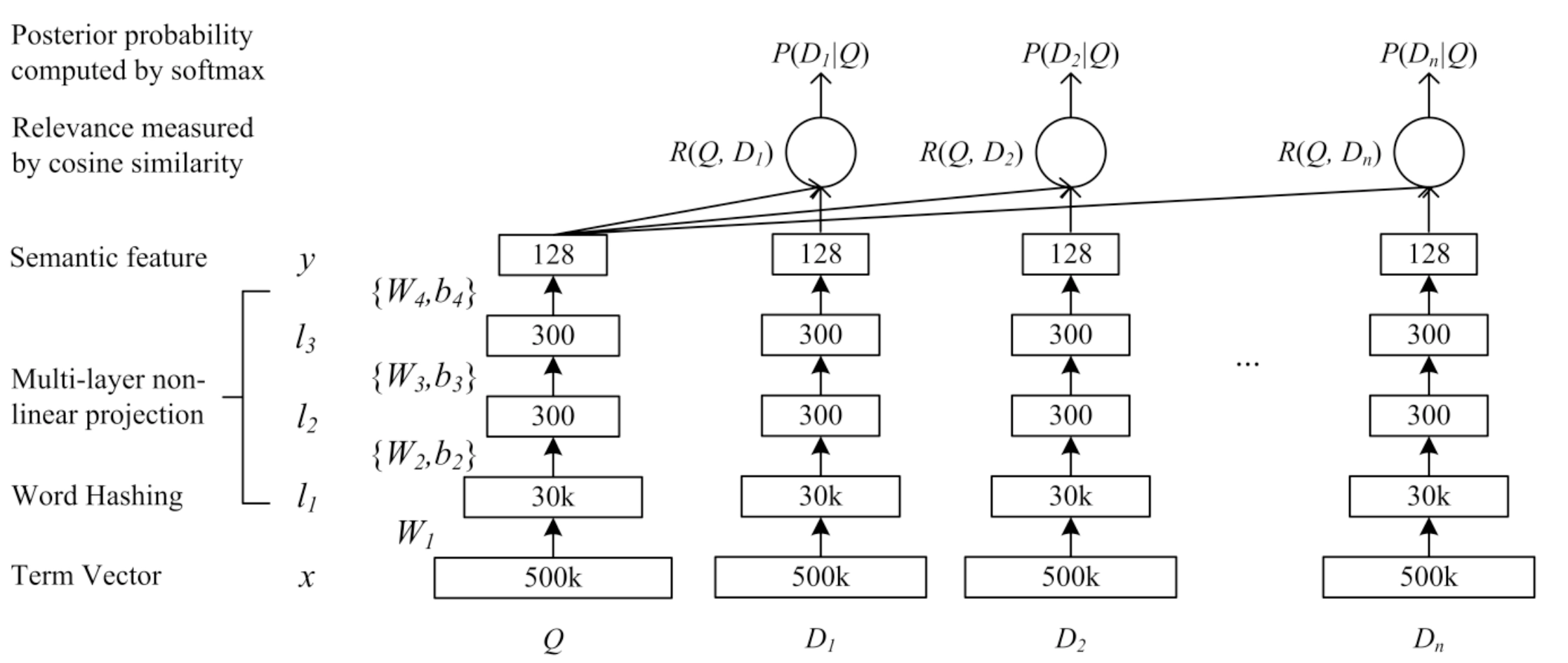
在embedding层之后,对每个sentence使用的是MLP网络,经典的隐层参数是300->300>128,也就是说最后,每个句子都将表示成一个128维度的向量。
- 匹配层
在原始的DSSM模型使用的是cosine作为两个向量的匹配分数,用\(Q\)来表示一个query, \(D\)来表示一个doc,那么他们的相关性分数可以用下面的公式衡量:
其中,\(y_Q\) 与 \(y_D\) 是query与doc的语义向量, 该语义向量由两个DNN结构分别学习得到。在搜索引擎中,给定一个query,会返回一些按照相关性分数排序的文档。
点击日志里通常包含了用户搜索的query和用户点击的doc,可以假定如果用户在当前query下对doc进行了点击,则该query与doc是相关的。通过该规则,可以通过点击日志构造训练集与测试集。
首先,通过softmax 函数可以把query 与样本 doc 的语义相似性转化为一个后验概率:
其中\(\gamma\) 是一个softmax函数的平滑因子, \(\mathbf{D}\)表示被排序的候选文档集合,在实际中,对于正样本,每一个(query, 点击doc)对,使用 \((Q,D^+)\) 表示;对于负样本,随机选择4个曝光但未点击的doc,用 \(D_j^-,j=1,...,4\)来表示。
在训练阶段,通过极大似然估计来最小化损失函数:
其中 \(\Lambda\)表示神经网络的参数。模型通过随机梯度下降(SGD)来进行优化,最终可以得到各网络层的参数 \(\{W_i,b_i\}\) 。
DSSM模型的优缺点
优点:
- 解决了LSA、LDA、Autoencoder等方法存在的字典爆炸问题,从而降低了计算复杂度。因为英文中词的数量要远远高于字母n-gram的数量;
- 中文方面使用字作为最细切分粒度,可以复用每个字表达的语义,减少分词的依赖,从而提高模型的泛化能力;
- 字母的n-gram可以更好的处理新词,具有较强的鲁棒性;
- 使用有监督的方法,优化语义embedding的映射问题;
- 省去了人工特征工程;
- 采用有监督训练,精度较高。传统的输入层使用embedding的方式(比如Word2vec的词向量)或者主题模型的方式(比如LDA的主题向量)做词映射,再把各个词的向量拼接或者累加起来。由于Word2vec和LDA都是无监督训练,会给模型引入误差。
缺点:
- Word Hashing可能造成词语冲突;
- 采用词袋模型,损失了上下文语序信息。这也是后面会有CNN-DSSM、LSTM-DSSM等DSSM模型变种的原因;
- 搜索引擎的排序由多种因素决定,用户点击时doc排名越靠前越容易被点击,仅用点击来判断正负样本,产生的噪声较大,模型难以收敛;
- 效果不可控。因为是端到端模型,好处是省去了人工特征工程,但是也带来了端到端模型效果不可控的问题。
DSSM系列问题
DSSM 系列的模型看起来在真实文本场景下可行性很高,但不一定适合所有的业务。
- DSSM 是端到端的模型,对于一些要保证较高准确率的场景,最好先用人工标注的有监督的数据,再结合无监督的 w2v 等方法进行语义特征的向量化,效果会更加可控。
- DSSM 是弱监督模型。dssm 的训练样本都是点击曝光日志里的 Query 与 Tiltle,但点击的 title 不一定与 query 是语义匹配的,因此想要从这种非常弱的信号里提取出语义相似性就需要有海量的训练样本。
- DSSM 均使用 cosine 相似度作为匹配的结果,而余弦相似度是无参匹配公式,个人感觉加一层 MLP 会更好一点。
接下来介绍两个 DSSM 系列之外的匹配模型。
基于CNN的模型
以DSSM为代表的基于DNN的表示学习匹配模型如3.1分析,无论是bow的表示还是DNN全连接网络结构的特点,都无法捕捉到原始词序和上下文的信息。因此,这里可以联想到图像里具有很强的local relation的CNN网络结构,典型代表有ARC-I模型,CNN-DSSM模型,以及CNTK模型。
ARC-I模型
针对上述讲到的DSSM模型对query和doc序列和上下文信息捕捉能力的不足,华为诺亚方舟在2015年在DSSM的模型基础上加入了CNN模块,里面提到了两种模型ARC-I和ARC-II,前者是基于representation learning的模型,后者是基于match function learning的模型将在第三章讲到。两个模型对比原始的DSSM模型,最大的特点是引入了卷积和池化层来捕捉句子中的词序信息,ARC-I全称Architecture-I,框架如图3.7所示。
ARC-I模型引入了类似CNN模块的卷积层和池化层,整体框架如图3.8所示
卷积层
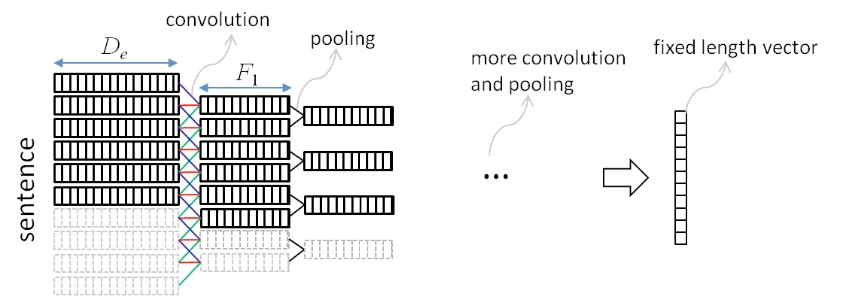
其中\(\mathbf{z_i}^{(l,f)}\)表示的是第\(l\)层中第\(f\)个filter位置为\(i\)的word的卷积输出,word滑动窗口大小为\(k_1\)(图3.8中\(k_1=3\)),word embedding的大小为\(D_e\)。这里不同的filter可以得到不同的feature map,通过\(\mathbf{w}^{(l,f)}\) 和\(b^{(l,f)}\)进行加权,表示的是第\(l\)层第\(f\)个filter的待学习参数。
用矩阵形式来表达如下:
其中\(z_i^{(l-1)}\)表示第\(l-1\)层第\(i\)个元素的向量,维度大小为\(F_{l-1}\)。对于第一层卷积层,将连续的\(k_1\)个word向量直接concat起来,如下所示,维度为\(k_1*D_e\)
池化层
卷积层提取了相邻word的关系,不同的feature map提供了不同的word的组合,通过池化层进行选择。ARC-I选择的滑动窗口为2,用max-pooling提取相邻两个滑动窗口的最大值,用公式表示如下
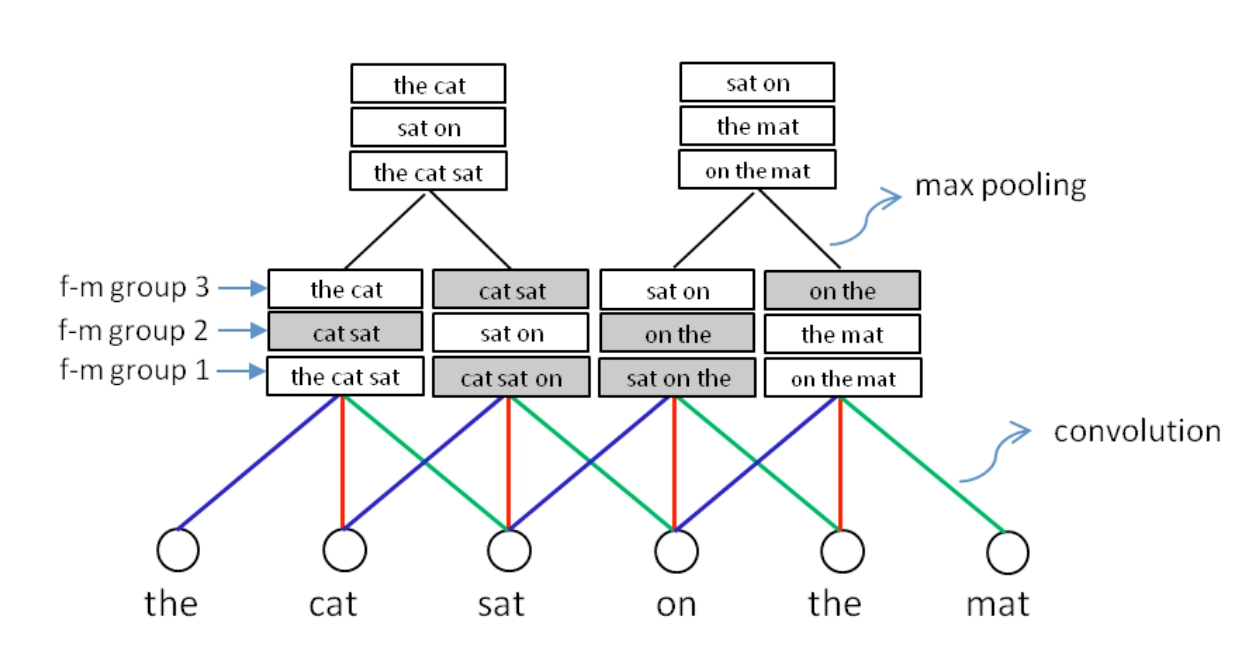
总结下ARC-I的特点:
- 对于query和doc两段文本的匹配,相比DSSM引入了word-ngram网络
- 通过卷积层不同的feature map来得到相邻term之间的多种组合关系
- 通过池化层max pooling来提取这些组合关系中最重要的部分,进而得到query和doc各自的表示。
- 表示层:通过上述卷积层和池化层来强化相邻word的关系,因此得到的query和doc的表示比原始DSSM能捕捉到词序信息
- 缺点:卷积层虽然提取到了word-ngram的信息,但是池化层依然是在局部窗口进行pooling,因此一定程度上无法得到全局的信息
CNN-DSSM模型
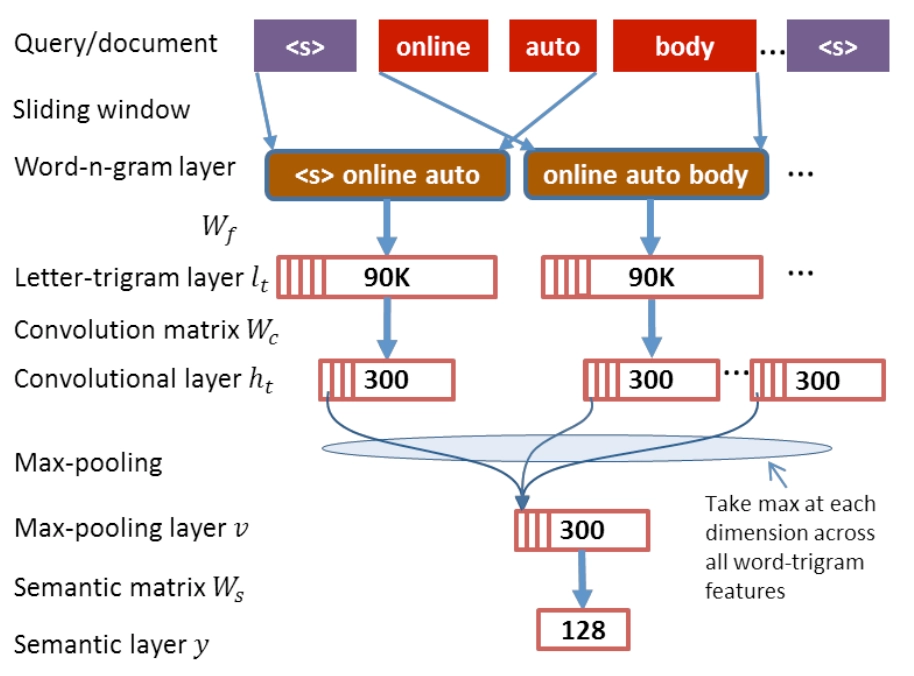
CNN-DSSM模型也称CLSM,是CIKM2014微软提出的基于CNN的DSSM模型,在DSSM框架上引入了CNN,整体来看可以分为输入层、表示层和匹配层,模型框架如图3.10所示
- 输入层
- 英文
对比DSSM模型,在输入层除了做了word hash的letter-trigram,同时也捕捉了word级别的信息,称为word-trigram。Word-trigram同样采用的是n=3的上下文单词的滑动窗口,每个窗口包含3个单词。例如<s> online auto boy … <s>这句话,可以提取得到三组信息,第一组是<s> online auto,第二组是online auto boy,第三组是auto boy <s>。
通过word-trigram提取得到的3组句子都各有3个单词,对每个单词按照DSSM中的letter-trigram方法进行word hash后,映射到一个3万维的embedding里,因此每个句子都可以得到9万维的embedding向量。
上述公式\(f_t\)表示第\(t\)个单词的word-n-gram表示, \(n=2d+1\)则为滑动窗口大小,\(d\)则表示用该单词前后单词个数,例如\(d=1,n=3\)表示word-trigram,使用当前word前后各1个单词以及自身进行表示。
- 中文
对于中文,和DSSM模型一样,采用的是字级别的编码
- 表示层
- 卷积层
通过输入层得到的每个句子是一个m*90k维的矩阵,其中m代表的是query或者doc的长度,为矩阵的行,而90k理解成每个word的embedding size,为矩阵的列。对于query和doc的句子不等长情况,可以通过padding方式进行补齐,确保所有句子都是等长的。论文中使用m=300,就是每个query和都需要pad到300维。
为了说明整个卷积过程,这里借用文本分类的经典模型textCNN模型来展示,如图3.11所示。卷积核Wc大小为390k,3表示的是卷积高度,代表每次滑动进行卷积的词窗口大小为3,90k是为了和原始句子的embedding size保持一致,整个卷积过程从上到下进行卷积,最终每个卷积核得到一个\(m*1\)的特征向量(feature map)。
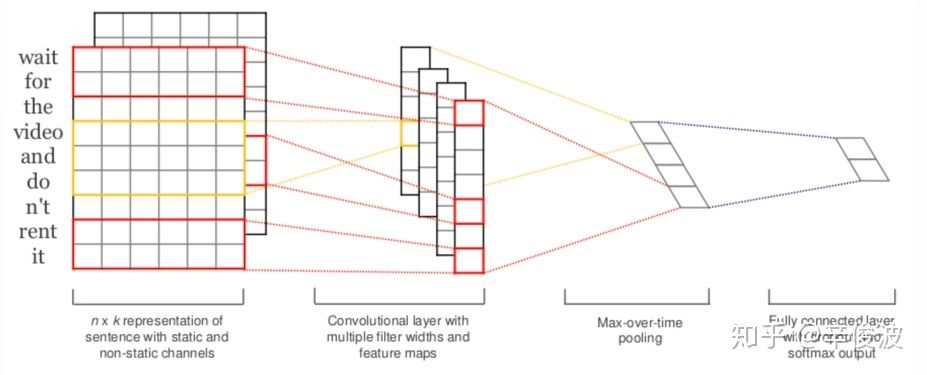
论文使用了300个卷积核,因此可以得到300*m的一个矩阵(前300为filter个数,后300表示的是每个feature map的行数)
- 池化层
前面卷积层每个filter得到的feature map维度是300,采用max pooling的方式选择最大的一个,总共有300个filter,因此max pooling可以得到一个300*1的定长特征向量
通过一层MLP网络后,用tanh进行激活输出,从300维的向量映射到一个128维的特征向量
- 匹配层
在原始的DSSM模型使用的是cosine作为两个向量的匹配分数
训练和损失函数和原始DSSM论文一致,这里不再赘述。
总结下CNN-DSSM模型,对比原始DSSM模型主要区别如下:
- 输入层除了letter-trigram,增加了word-trigram,提取了词序局部信息
- 表示层的卷积层采用和textCNN的方法,通过n=3的卷积滑动窗口捕获query和doc的上下文信息
- 表示层中的池化层通过max-pooling,得到卷积层提取的每个feature map的最大值,从而一定程度的捕获了全局上下文信息
- 表示层中的池化层的max-pooling对比ARC-I的max pooling不同之处在于ARC-I的池化层是在相邻的两个滑动窗口进行max pooling,得到的还是局部关系;而CNN-DSSM模型是在每个feature map整个句子进行max pooling,能得到全局的关系
CNTN模型
前面提到的两种基于CNN的模型ARC-I模型以及CNN-DSSM模型核心在于表示层上引入了CNN模型结构,对匹配层依然是沿用了DSSM的cosine来计算query和doc的匹配分数。而在IJCAI2015年提出的Convolutional Neural Tensor Network,简称CNTN模型,除了一样在表示层引入CNN学习query和doc的表示,另外也在匹配层做了改造,引入了Neural Tensor Network,整体框架表示如图3.12所示。
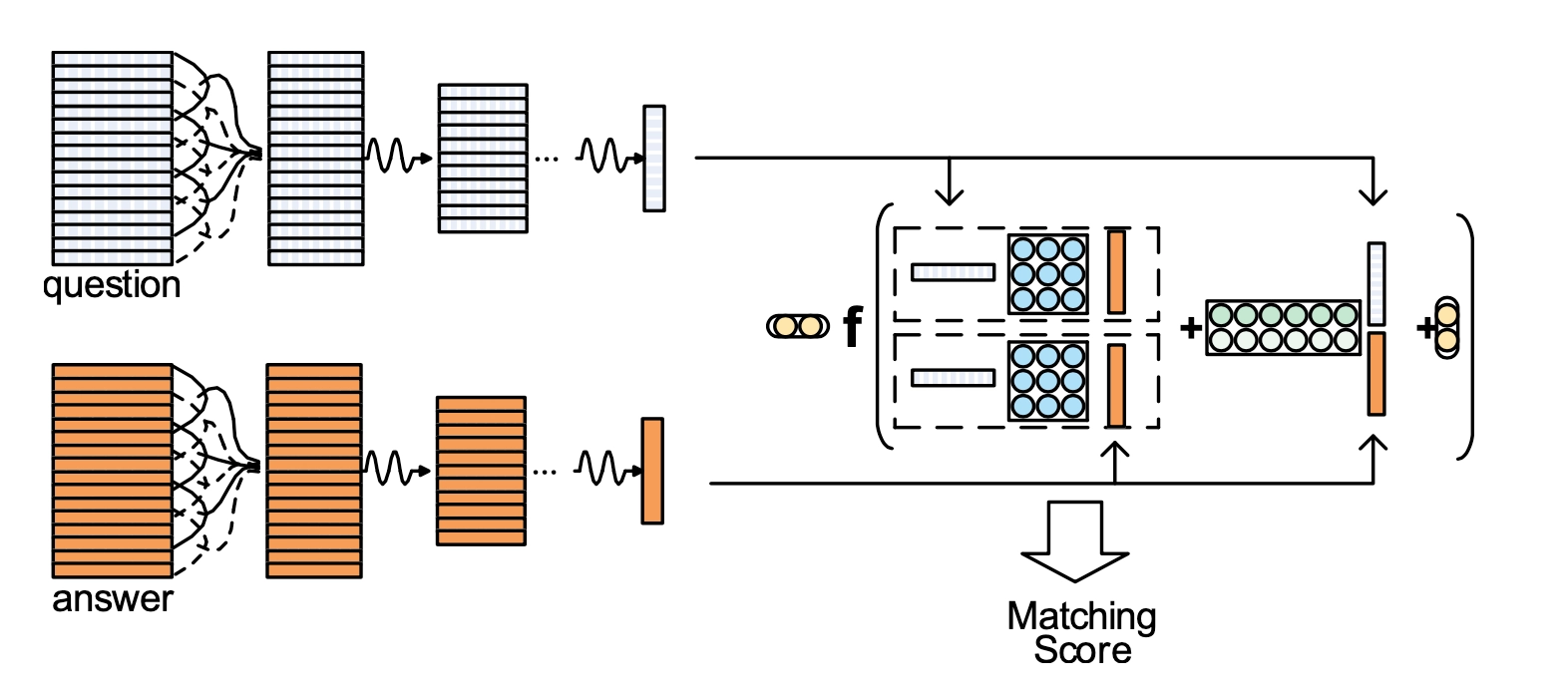
对于给定的query和doc,从表示层已经得到各自的表示\(q\)和\(d\),在匹配层引入了neural tensor network,也就是更多的网络参数来学习\(q\)和\(d\)的匹配分数,用公式表示如下:
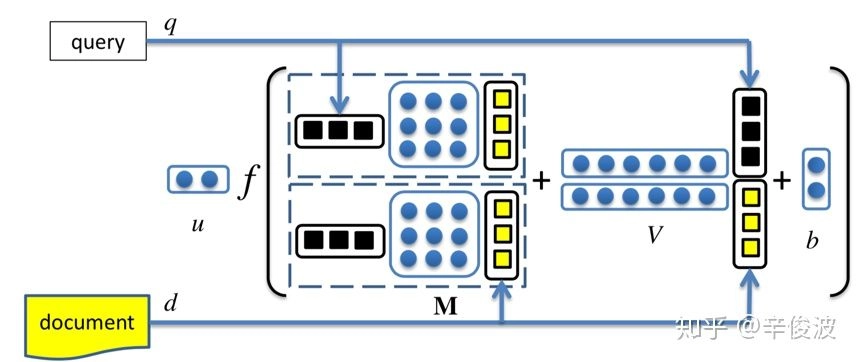
其中query和doc都各自由3个word组成,query 为图中的黑色部分,doc为黄色方块。\(M^{[1:r]}\)中的每个\(r\)(图中等于2),是query和doc之间的一个\(3*3\)转换矩阵,因此,\(v_q^T\mathbf{M}^{[1:r]}\)产生的是一个\(r\)维度的向量,在途中就是2维向量。公式的第二部分,\(V\)是一个\(3*2\)的矩阵,乘以\(q\)和\(d\)两个向量concat一起的向量后,也得到一个2维向量,在加上一个维度为2的bias向量\(b\)。
通过中间括号的操作得到一个2维的向量后,引入了非线性函数f进行拟合,再通过左侧一个线性矩阵u的映射,最终得到匹配分数
基于RNN的模型
作为空间关系代表的CNN网络结构能够捕捉到query和doc的局部关系,RNN作为时间序列相关的网络结构,则能够捕捉到query和doc中前后词的依赖关系。因此,基于RNN的表示学习框架如图3.14所示,query或者doc用黄色部分表示,通过RNN网络结构作为隐层来建模序列关系,最后一个word作为输出,从而学习得到query和doc的表示。对于RNN结构,可以使用业内经典的LSTM或者GRU网络结构,如图3.14所示。
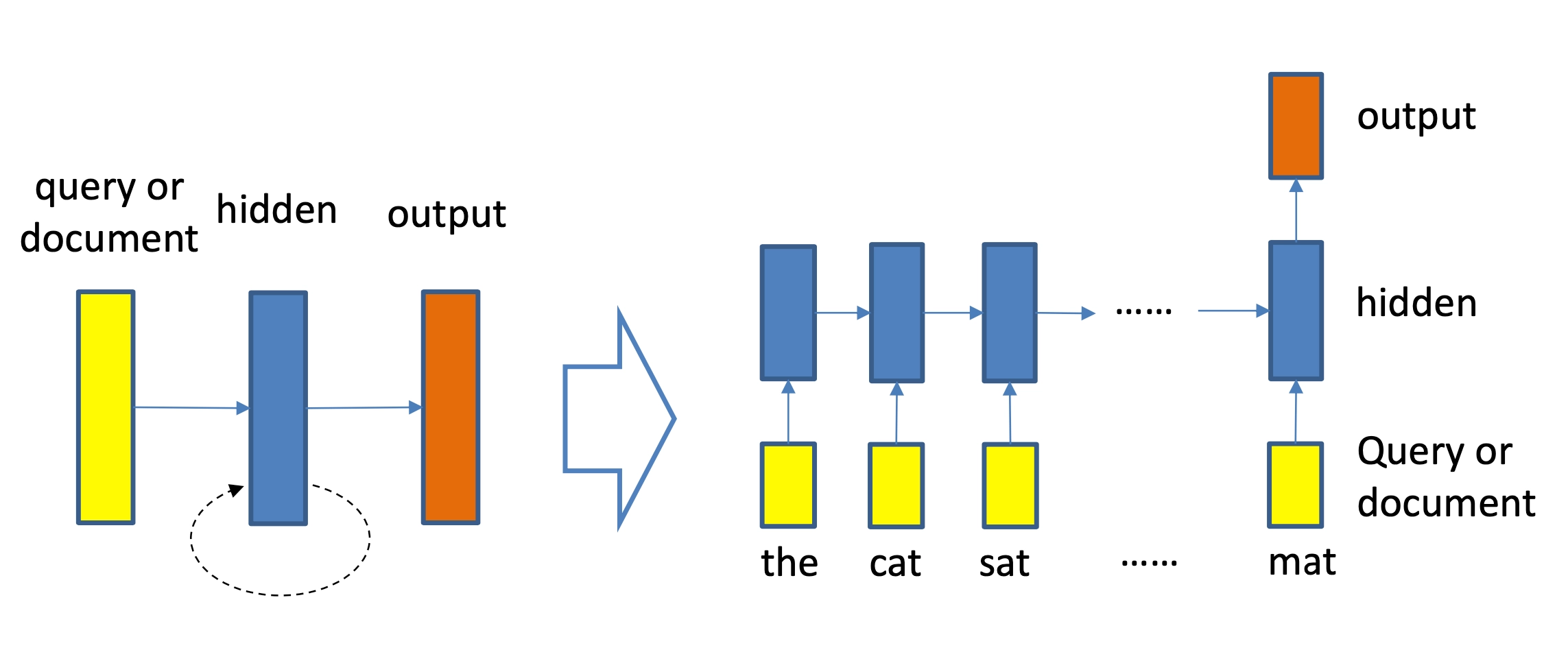
LSTM-RNN模型
2016在TASLP上提出的LSTM-RNN模型,在DSSM的基础上提出了用LSTM来强化query和doc的representation。整个模型思想很简单,通过将原始query和doc的文本转换成embedding向量,然后通过LSTM-RNN的网络结构进行抽取转换。假设原始的query或者doc有\(m\)个word,得到的最后一个隐层的输出\(h_m\)就是整个query或者doc的最终表达,框架如图3.15所示
文中核心的改造在于表示层中使用了LSTM来捕捉序列关系,在LSTM的多种变体结构中,作者使用了peephole connection的变体,也就是说让门结构(输入门、输出门、遗忘门)也会接受前一时刻的细胞状态作为输入.
总结LSTM-RNN模型的几个特点:
- 相比于DSSM模型引入了LSTM网络结构来捕捉次序的关系
- LSTM最后一个隐层的输出作为query和doc的representation
representation learning模型总结
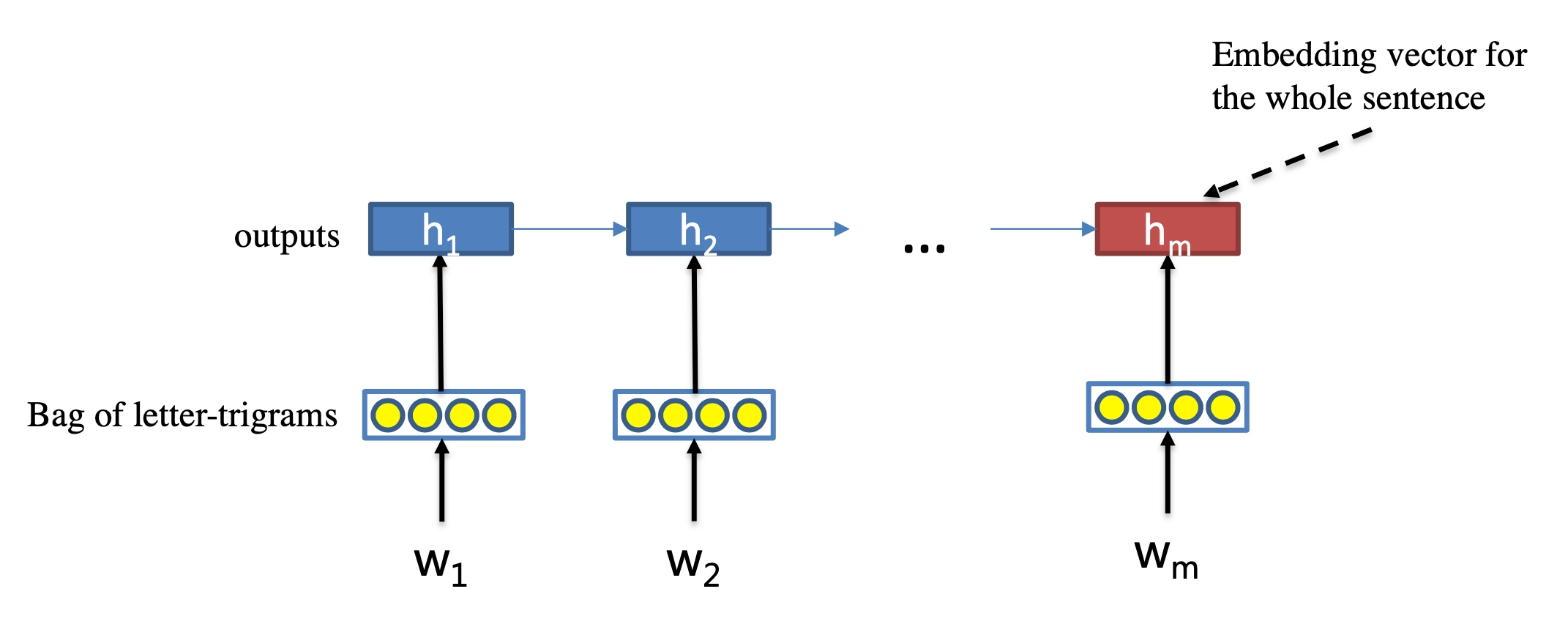
总结下基于representation learning的深度匹配模型框架,核心在于表示层和匹配层
表示层
- DNN框架:DSSM模型
- CNN框架:ARC-I模型、CNN-DSSM模型、CNTN模型
- RNN框架:LSTM-RNN模型
匹配层
匹配函数有两大类,一种是直观无需学习的计算,如cosine、dot product,一种是引入了参数学习的网络结构,如MLP网络结构,或者如CNTN的
(1) cosine函数:DSSM模型、CNN-DSSM模型、LSTM-RNN模型
(2) dot product:
(3) MLP网络:ARC-I模型
(4 )Neural Tensor Network:CNTN模型
基于match function learning的深度匹配模型
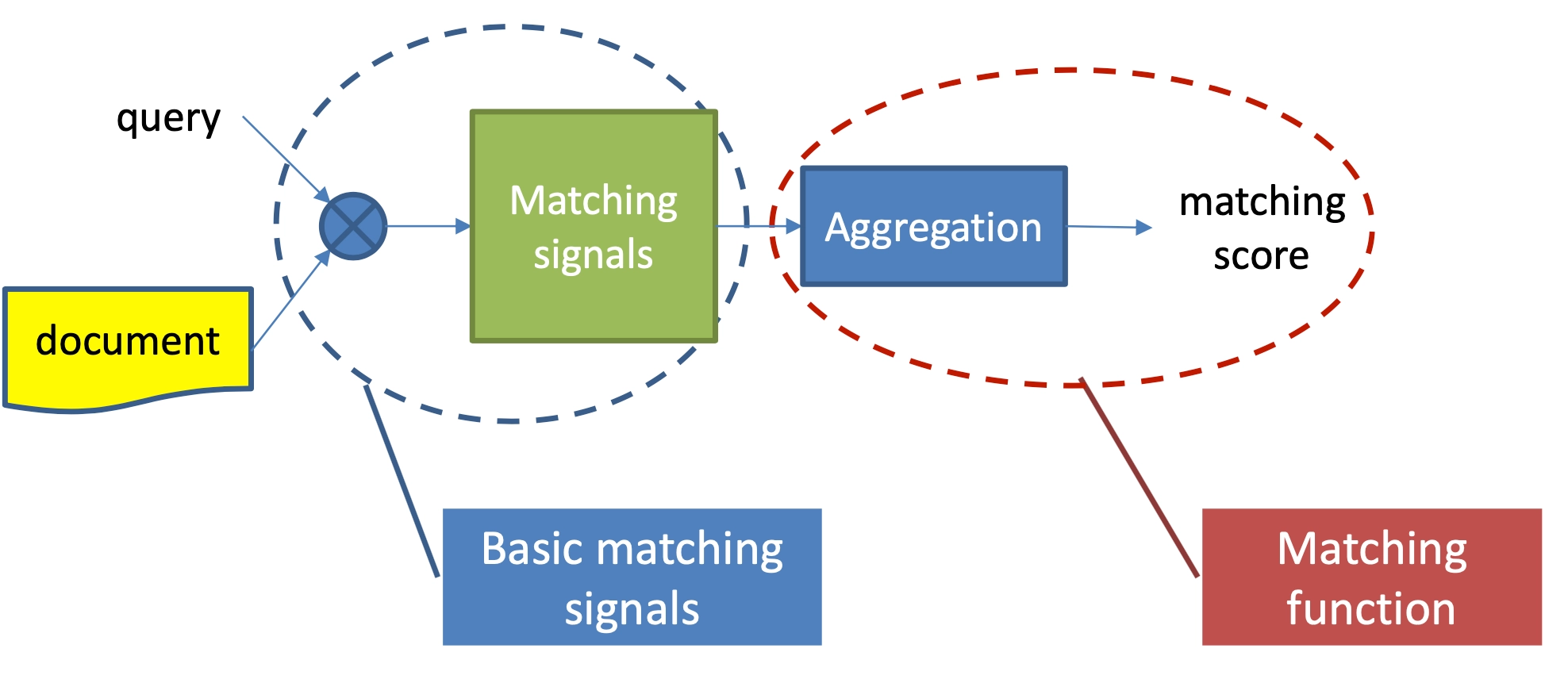
对比representation learning的深度匹配模型,match function learning方法的特点,是不直接学习query和doc的表示,而是一开始就让query和doc进行各种交互,通过两者交互的match signals进行特征提取,然后通过aggregation对提取到的match signals用各种网络结构进行学习得到最终的匹配分数,如图4.1所示。
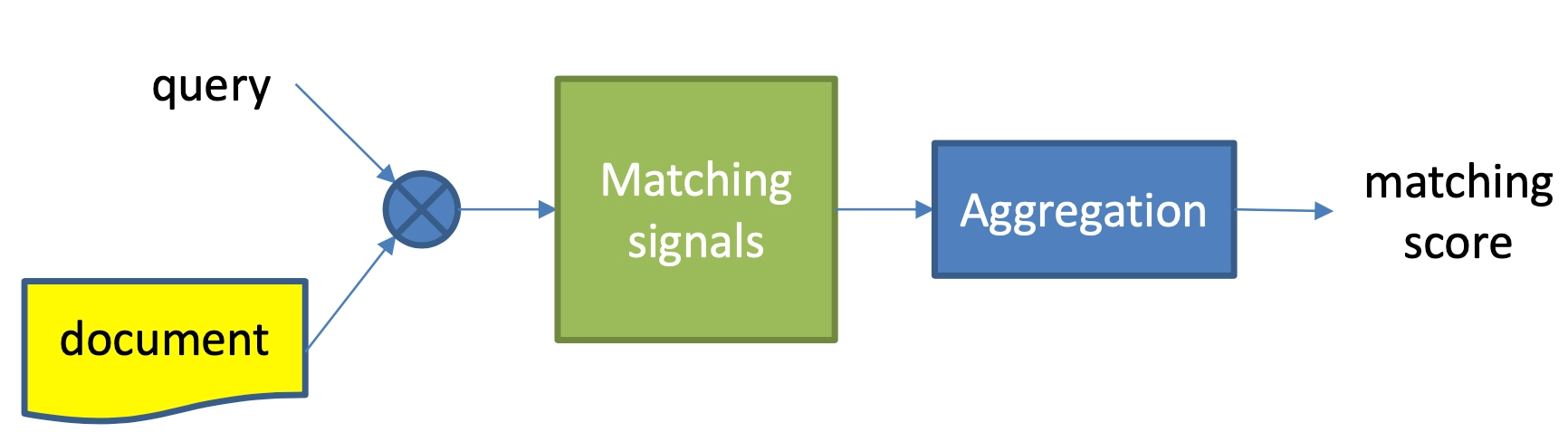
和representation learning匹配模型一样,match function learning的匹配过程也一样可以分为两步:
- 基础匹配信号提取:让query和doc在这一步就开始进行交互,得到两者的基础匹配信号,如图4.2中的蓝色圆圈所示
- 信号聚合(aggregation):对应于representation learning中的匹配层,这里也叫匹配层,由于前一步已经进行了query和doc的交互,信号更加丰富,在后面介绍的模型中可以发现匹配层这里也会比表示学习的网络结构设计变化要丰富很多
由于从一开始就让query和doc进行交互。因此,基于match function learning的匹配模型也称为交互匹配模型。
基于word level匹配度矩阵的模型
基于match function learning的模型和representation learning的模型最大的区别是让query和doc提前进行交互,因此很多模型的工作就是关于如何设计query和doc的交互上。一种很直观的思路就是,让query和doc两段文本里面每个word两两进行交互,在word level级别建立匹配度矩阵。本章在原始slides上的基础上加了aNMM模型,虽然听名字是attention-based的,但其区别于CNN的position-aware提出的value-aware思路个人觉得还是值得研究下的。
ARC-II模型
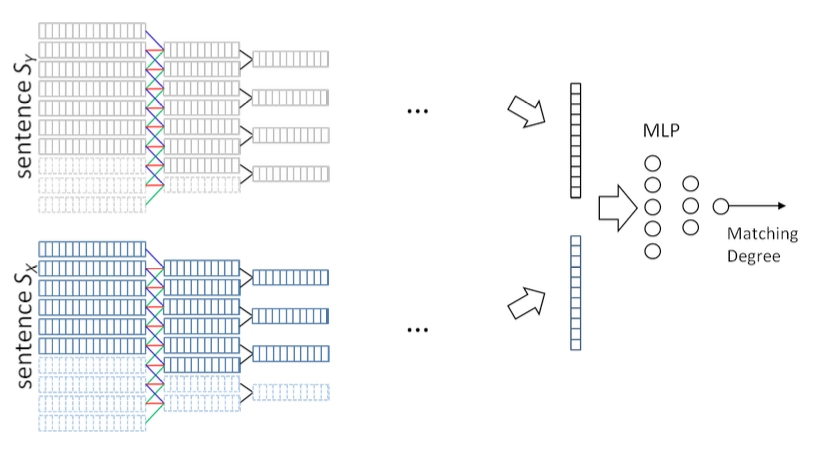
ARC-II全称Architecture-II,和ARC-I出自2015年华为的同一篇paper,属于交互学习的模型。ARC-I直到最后的全连接层进行匹配之前,query和doc两段文本都是没有任何交互的,大家都在各自学习各自的表示。而ARC-II模型属于交互学习的模型,通过对query中的word进行n-gram的卷积提取,以及doc中的word进行卷积提取,然后各自卷积后得到的词向量进行pairwise计算,得到一个匹配度矩阵,整体框架如图4.3所示。
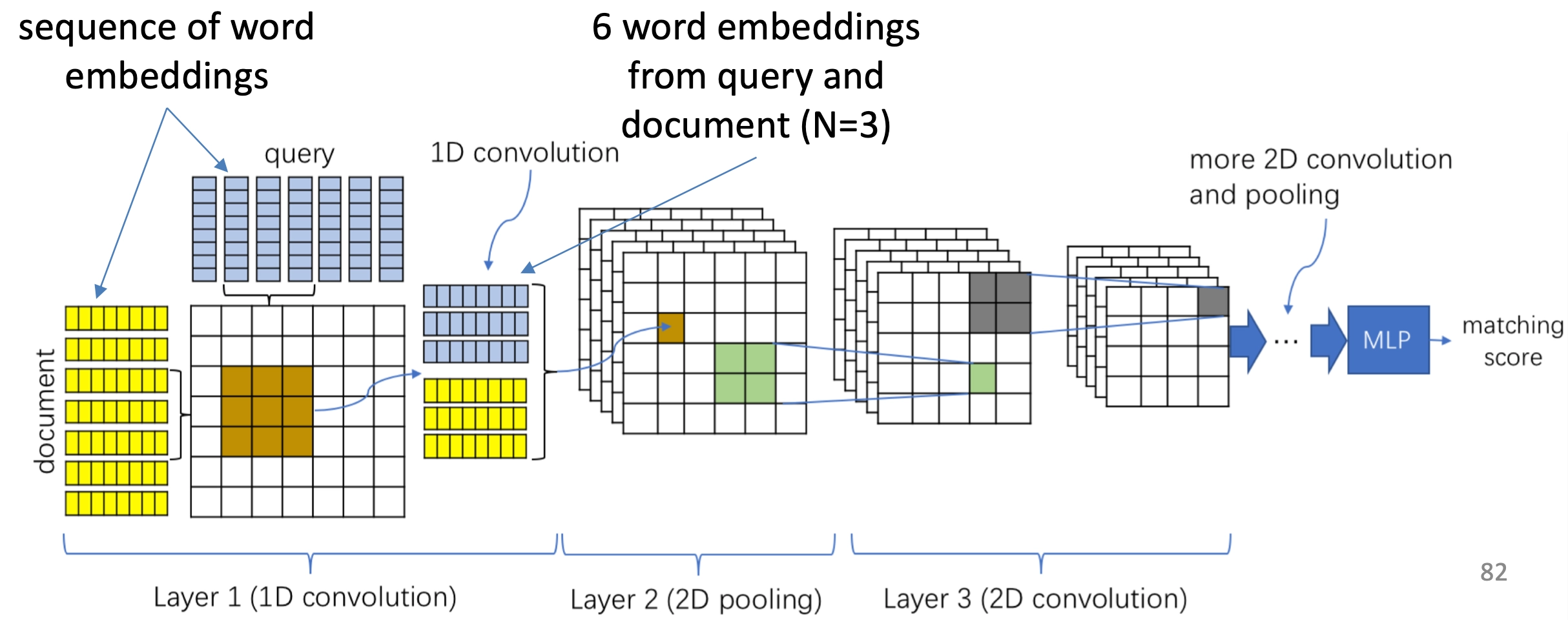
在提取匹配度矩阵过程中,核心有3层:一维卷积层、二维卷积层和二维池化层
- 一维卷积层
假设query和doc的长度都是N,我们把整个过程想象类比成二维图像,让query和doc的每个word两两组成一个N*N的矩阵,query是列,doc是行。其中每个word的embedding维度是\(D_e\)。
用一个\(3*3\)的卷积核在这个\(N*N\)的矩阵上进行扫描,每次横向扫描3个格子,纵向扫描3个格子,代表在query和doc上对应的3个相邻的词,总共取到6个词进行concat,可以得到一个\(6D_e\)的矩阵,卷积核大小也为\(6D_e\),两者进行点乘相加得到一个值。这样扫描完整个\(N*N\)矩阵就可以得到一个二维的矩阵feature map。使用多个卷积核,就可以得到多个二维矩阵feature map。
通过这种trigram的方法(每次取3个词)的交互,可以得到query和doc中任意3个相邻的word组成的短语的交互关系,因此交互级别属于phrase级别的。
对于query句子\(S_X\)中的第\(i\)个word,和doc句子\(S_Y\)中的第\(j\)个word,卷积后的表示为
注意到第一层的元素\(z_{i,j}^{(0)}\)相当于将输入\(x\)和\(y\)的向量concat了起来,embedding 维度为\(D_e\),n-gram的滑动窗口为\(k_1\)(在示意图中为3)
整个过程query和doc的信息都是独立计算后concat的,称为一维卷积。
- 2维池化层
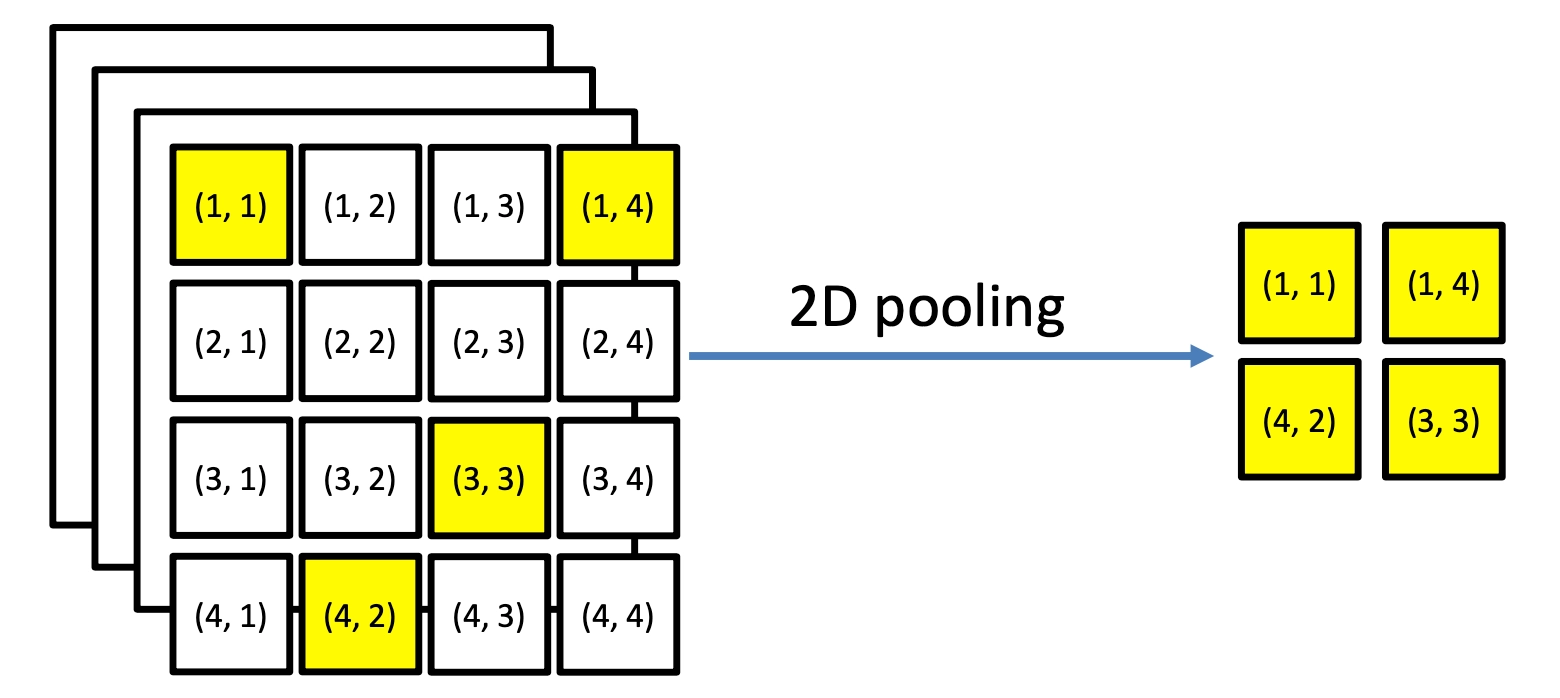
一维卷积层保留了query和doc中每个词的原始信息。在2维的池化层作用是用一个\(2*2\)的卷积核,用max-pooling得到这4个二维空间的最大值
- 2维卷积层
前面通过一维卷积层和max pooling后得到的是2维的匹配矩阵,接着的操作可以类比于图像,在二维的平面上进行多层的卷积-池化-卷积-池化…的操作了。
2维卷积层之后可以叠加多个卷积和池化的操作,最后再通过全连接MLP输出最终的匹配分数。损失函数使用pairwise loss
在整个2维卷积和池化过程,可以发现word的顺序关系是有所保留的,如图4.4所示的2维度池化过程,max pooling选择的黄色方块保留了原始的order信息。
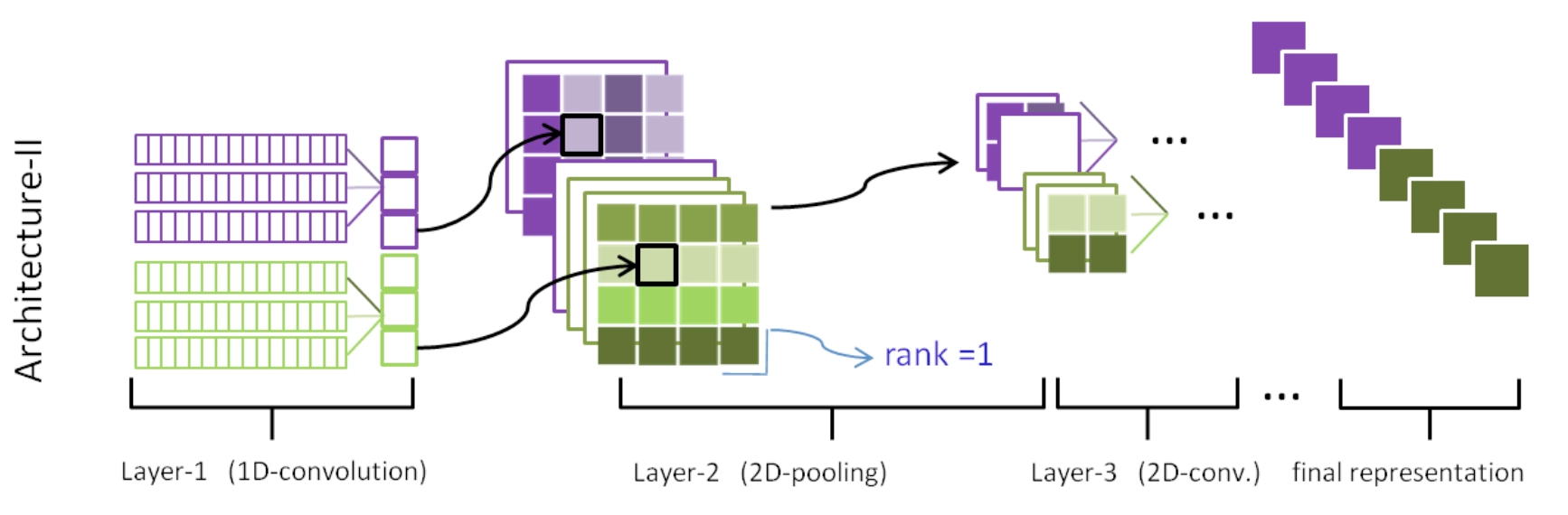
另外一个角度,我们可以看到其实ARC-I是ARC-II的特殊情况,如下图4.5所示
总接下ARC-II模型特点:
- 对比ARC-I,在一开始就引入了query和doc两段文本的匹配矩阵,提前得到两者的交互信息,对信息匹配的捕捉能力更强,并且卷积和池化过程保留了次序的信息
- 虽然引入了query和doc的匹配矩阵,但是匹配矩阵的计算是按照每个句子的n-gram后的word embedding计算,只有phrase level的匹配信号而没有更细粒度的word level的匹配信号,因而丢失了原始精确匹配和泛化匹配的信息。
MatchPyramid模型
前面提到的ARC-II模型引入了匹配矩阵,但是匹配的粒度是n-gram后提取各自的word embedding进行计算,并不是word-level级别的。而MatchPyramid模型的提出灵感源于CV领域里的图像识别。在此之前,文本匹配的维度是一维的(TextCNN为代表的word embedding);而图像是二维平面的,显然信息更加丰富。2016年的AAAI上中科院提出了基于word-level级别交互的矩阵匹配思想,用一个二维矩阵来代表query和doc中每个word的交互,相比于更高level的匹配如ARC-II的phrase level(n-gram)信息能捕捉更精细的匹配信息,属于真正word level的匹配度矩阵,整体框架如图4.6所示
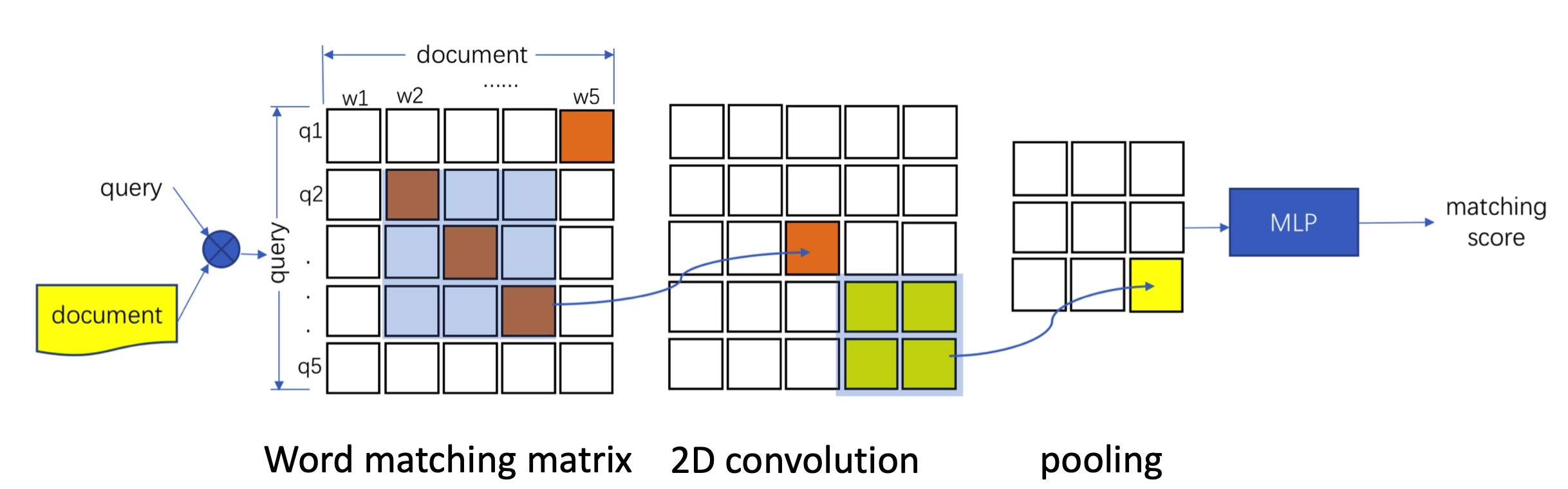
以下图两个例子说明下word-level的匹配以及phrase-level的匹配的不同

对于word-level的匹配能捕捉到更细粒度的信息,例如绿色方框中能捕捉到famous对应popular以及Chinese对应China这样的匹配信息。
对于phrase-level的短语匹配又可以分为n-gram有序的短语,以及n-term无序的短语。图4.7显示的是trigram也就是3个词一个窗口,同颜色的方框是匹配的。对于n-term的匹配,方框中第一个句子中的“down the ages”和第二个句子中的”down the ages”是匹配的。对于n-gram的匹配,橙色方框中第一个句子中的”noodles and dumplings”和第二个句子中的”dumplings and noodles”通过3-gram后打乱了词序信息后是匹配的。
整个MatchPyramid模型框架如图4.8所示
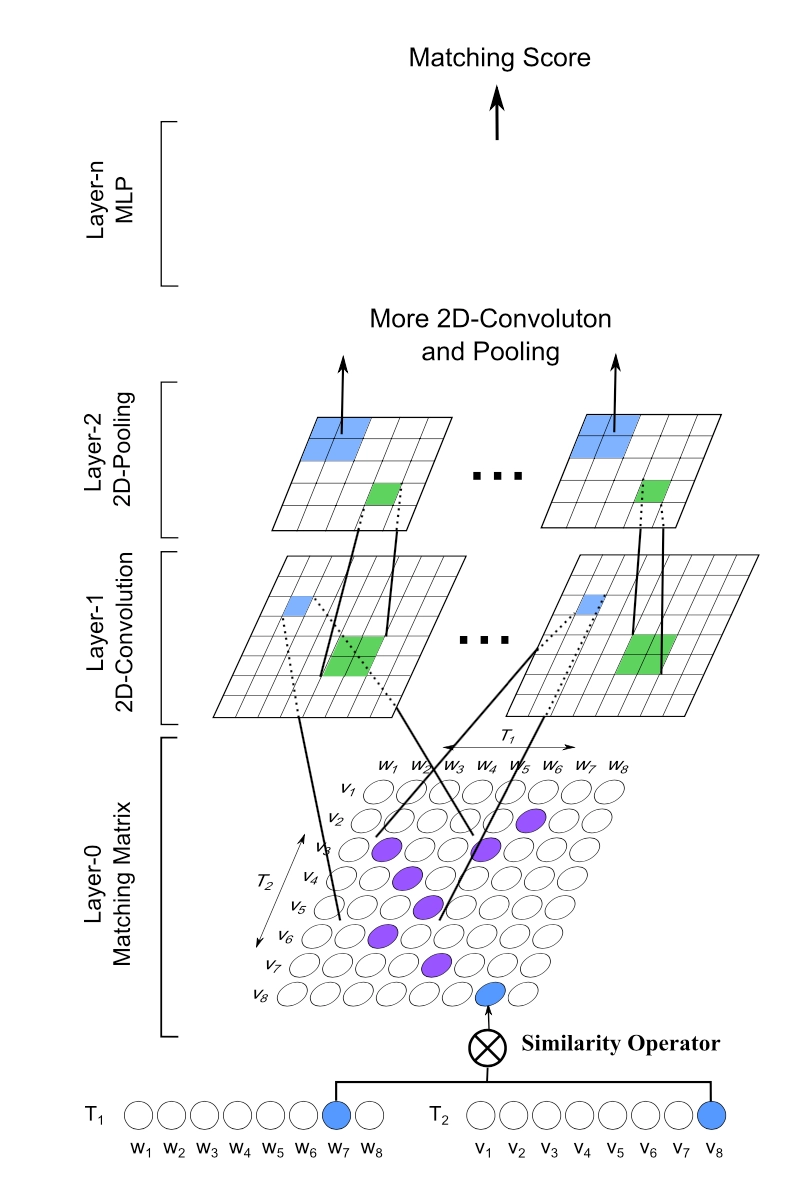
因此,文中的关键在于如何构建query和doc中word级别的匹配信息,整体框架可以分为3层,匹配矩阵层、2维卷积层、2维池化层,后续卷积和池化可以持续进行叠加。
- 匹配矩阵层
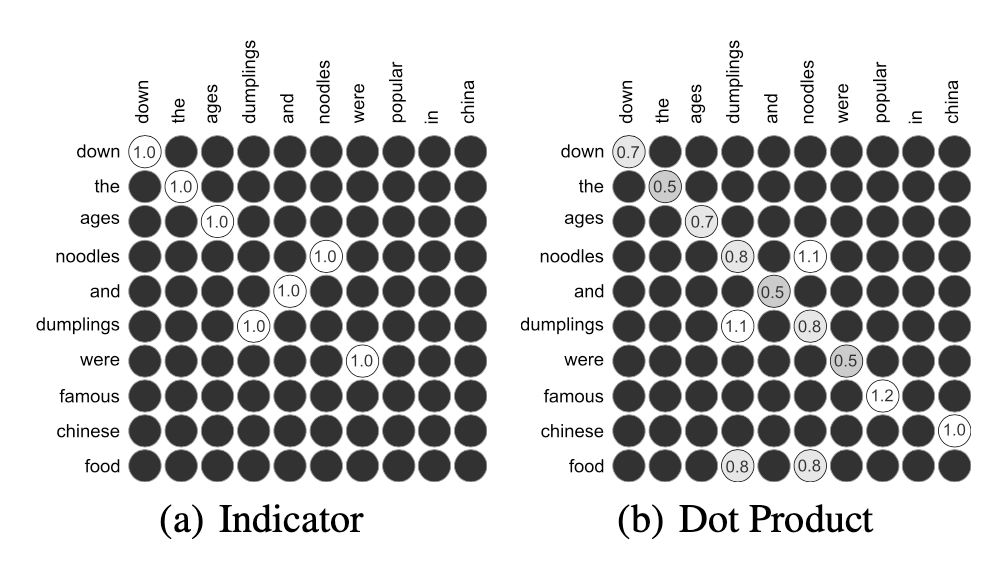
匹配矩阵的构造是MatchPyramid模型的核心关键。用\(M\) 矩阵代表query和doc的匹配,\(M_{ij}\)为矩阵的第\(i\)行第\(j\)列,表示第一个句子query中第\(i\)个单词和第二个句子doc中第\(j\)个单词的交互。这里对于Mij如何构造,有3种方法,indicator、cosine以及dot product,分别如下
- indicator match
0-1匹配矩阵,只有两个word完全相同才等于1,否则为0,相当于是精确匹配
- cosine match
将每个word用glove预训练得到的词向量,两两计算cosine相似度
- dot product match
将每个word用glove预训练得到的词向量,两两计算向量点积
图4.9显示了indicator和dot product两种,黑色部分是0;dot product或者cosine对比indicator能捕获到更多的泛化信息,例如在indicator对于famous和popular的匹配分数是0,而用dot product得到两者的匹配分数是1.2
- 二维卷积层
以第一层为例,通过一个\(r_k * r_k\)的卷积核提取二维匹配矩阵的信息,相当于是提取query和doc在各自连续\(r_k\)个word的信息交互
- 二维池化层
还是以第一层的池化层为例,在\(d_k*d_k^{'}\)的kernel下用max-pooling求最大值
以下这张图展示了MatchPyramid模型和图像识别中一些相似的匹配过程
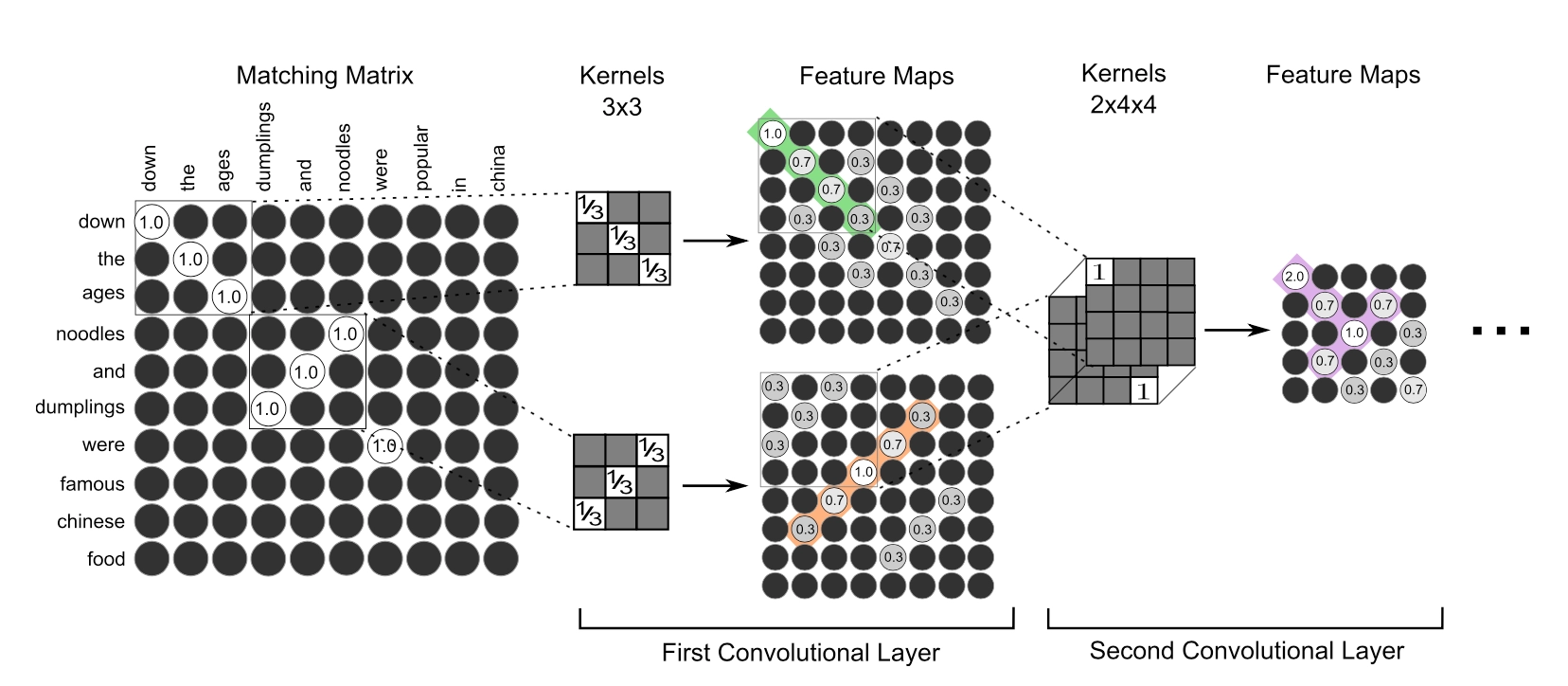
图4.10 左边用indicator match得到两个句子的相似匹配矩阵,相当于是精准匹配,第一层卷积层通过上下两个对角线以及反对角线的卷积核之后,可以得到两个feature map,第一个feature map的绿色部分和第二个feature map的橙色线条类似于图像识别中的边缘检测。通过第二层的卷积核之后,可以得到右侧的feature map中的紫色的“T-type”的part,这一部分类比于图像识别中的motifs(part)识别。
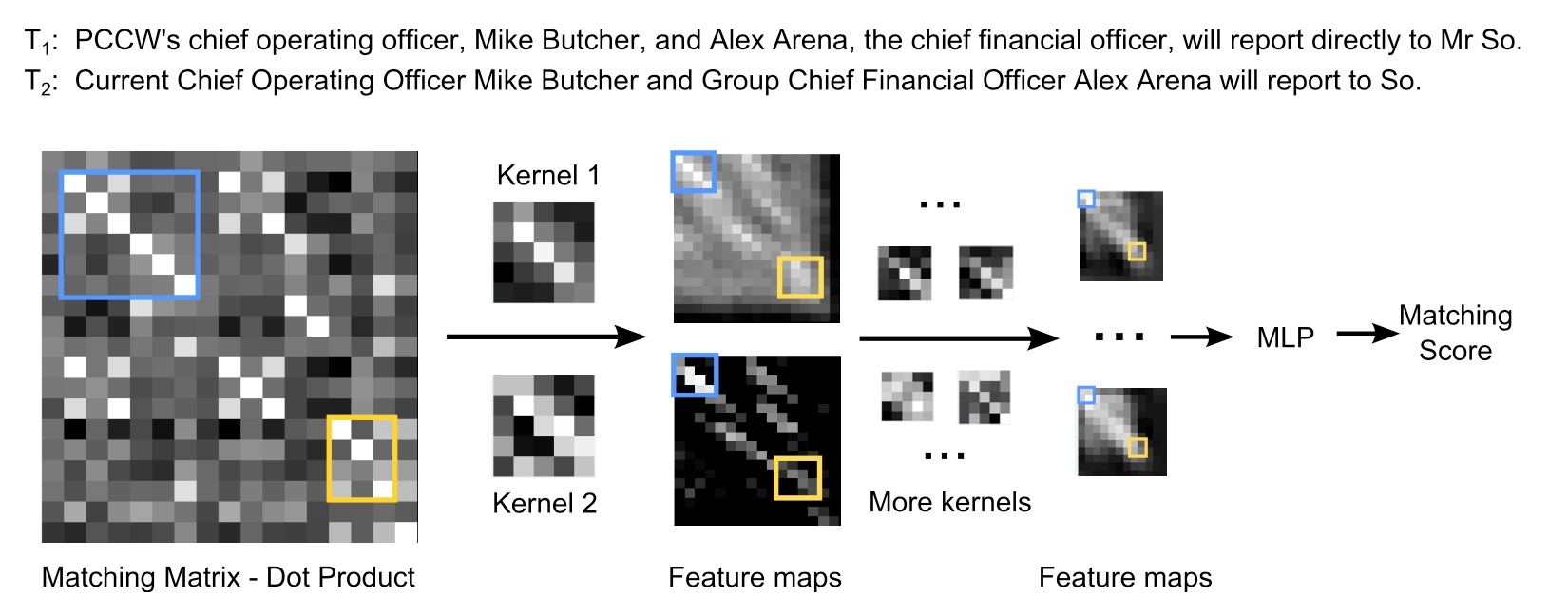
总结MatchPyramid模型的特点:
- 比起ARC-II模型通过n-gram得到的word embedding进行相似度计算,MatchPyramid模型在匹配矩阵的计算上做得更加精细,关注的是原始word级别的交互
- 对于query和doc之间每个word的两两交互提出了3中方法,包括精确匹配的indicator计算,两个word完全相同为1否则为0;以及语法相似度的匹配,包括cosine以及dot product,关注的是更泛化的匹配
- 整个过程和图像识别以及人类的认知一样,word-level的匹配信号,类比图像中的像素特征;phrase-level的匹配信号,包括n-gram有序的phrase以及n-term无序的phrase,类比图像中的边缘检测;到sentence-level的匹配信号,类比图像中的motifs检测
Match-SRNN模型
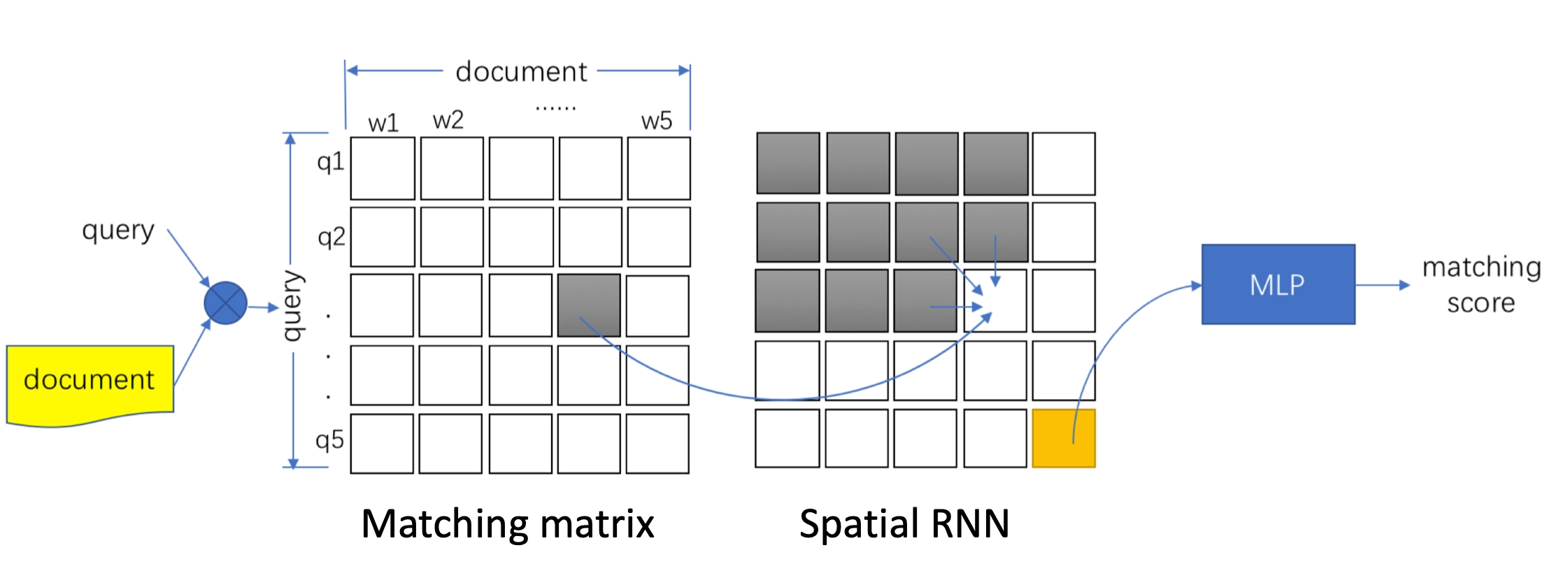
IJCAI2016上提出了一种空间相关RNN(Spatial RNN),全称Match-SRNN模型来拟合交互矩阵,类似于一种动态规划的思路,query和doc的交互矩阵中每个位置的值由不仅由当前两个word的交互值得到,还由其前面(左、上、以及左上三个位置)的值决定,模型整体框架如图4.12所示
首先,对于输入的两个文本query和doc的表示\(s1\)和\(s2\),分别由\(m\)和\(n\)个词组成的词向量组成。
- 匹配矩阵层
整个模型可以分为3个部分,分别是query和doc的匹配矩阵层、本文的核心Spatial RNN层以及最终的输出层。
对query中的\(m\)个term,以及doc中的\(n\)个term两两计算匹配分数得到初始的匹配矩阵,一般来说可以用cosine或者dot product来表达其匹配分数(MatchPyramid)。论文中作者提到为了更好的捕捉关系,引入了neural tensor network来拟合两者关系,具体有3个参数向量, \(T^{[1:c]}\)代表的是层数为c的tensor向量,\(W\)为线型参数,维度和embedding size一致,而\(b\)为bias。
这一步其实对本文的核心模块是独立的,实际中也可以从简单的cosine、dot product甚至是indicator的直接先做计算,没有更多参数学习。
- Spatial RNN
第一步得到了query和doc的原始匹配矩阵之后,作者使用了Spatial RNN的网络结构来进一步提取得到query和doc两段文本的关系。对于query中第\(i\)个term以及doc中的第\(j\)个term用\(s_{ij}\)表示,它的值由其左边、上边、左上3个相邻的元素的函数所决定,表示如下
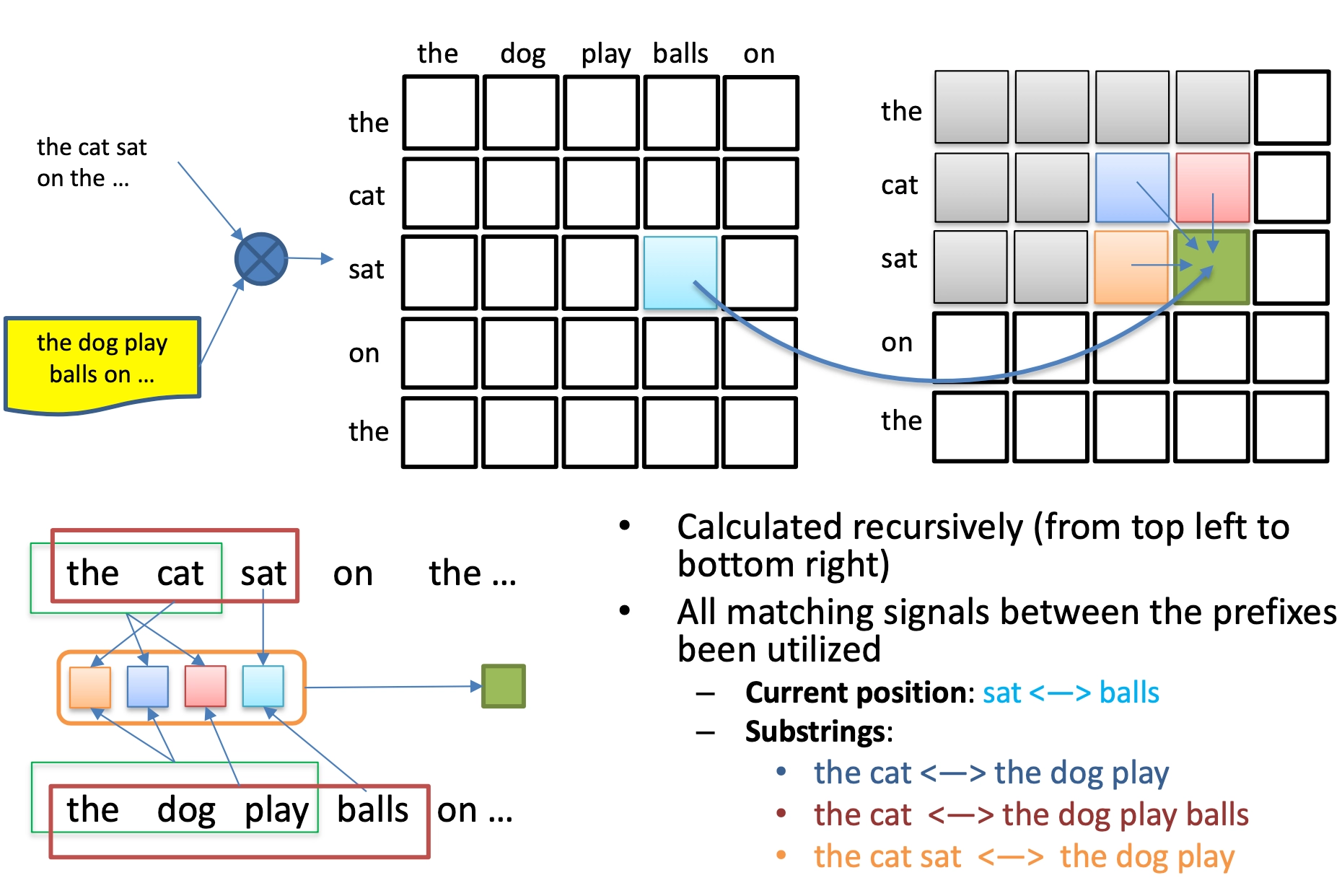
给定两个句子s1=”The cat sat on the mat”, s2=”The dog played balls on the floor.”
该公式是整个Spatial RNN的理解关键,结构和动态规划很像,以图4.13为例来直观理解整个过程。
公式中的\(f\)是拟合的函数,可以采用多种时序相关的模型去拟合,比如RNN, LSTM,GRU等,作者在文中提到最终用的是GRU。在原始的GRU公式中,关键的是两个门reset gate \(z\)以及 update gate\( r\),表达如图所示
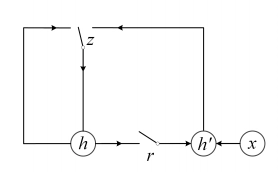
其中\(h_{t-1}\)表示句子中第\(t-1\)个单词的隐层输出,\(z\)表示的是update gate,控制\(h_{t-1}\)中有多少比例能够更新当前时刻的信息;\(r\)表示的是reset gate,控制着储存在cell中的信息;\(W(z)\),\(U(r)\),\(W(r)\), \(U(r)\),\(W\),\(U\)为GRU中学要学习的模型参数
可以发现原始的GRU的更新门z只有一个。而在Match-SRNN模型中,匹配矩阵是二维的,每个元素\((i,j)\)的表达式是由3项组成的,分别是 \((i-1,j)\), \((i,j-1)\),\((i-1,j-1)\),因此,论文中用了4个更新门\(z\),分别表示为\(z_l\),\(z_t\),\(z_d\)以及\(z_i\)。三个reset门\(r_i\), \(r_l\),\(r_d\)示意图如图4.15所示
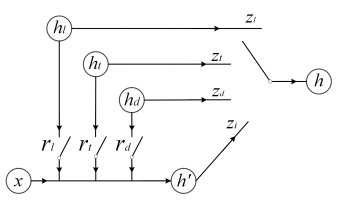
4个update gate以及3个reset gate最终的表达如下
其中的softmax by row表达如下
- 输出层
从上一层SRNN层提取得到query s1和doc s2的交互矩阵后,要得到最终的match score就简单了,论文使用了简单的线性函数去拟合
其中\(W\)和\(b\)为待学习的线性参数,通过训练得到。因为是相关性的rank问题,论文使用的是pairwise loss
总结Match-SRNN模型的特点:
- 对比MatchPyramid模型,query和doc的匹配分数,使用neural tensor network结构,引入了参数得到初始匹配矩阵,更复杂的结构捕捉信息更精准
- 引入了Spatial RNN来进一步得到匹配矩阵,每个元素\((i, j)\)的值除了当前的匹配sij值,还由其左\((i-1, j)\)、上\((i, j-1)\)、左上,\((i-1, j-1)\)三个元素决定,通过网络结构f进行拟合
- 上述的网络结构f采用的2D-GRU,对比常规的1D-GRU,最大的特点是有4个update gate以及3个reset gate。
MV-LSTM模型
AAAI2016年提出的MV-LSTM模型,用双向LSTM来对两段文本query和doc进行编码,然后将LSTM的每个隐层输出进行归一化后作为query和doc每个term的输出,并对这些term计算得到不同维度的匹配度矩阵。由于采用双向LSTM的编码,以及不同的匹配度矩阵计算方法,作者认为这是个Multi-View的过程,能够捕捉到每个term在不同的语境下的表示,整体过程如图4.16所示
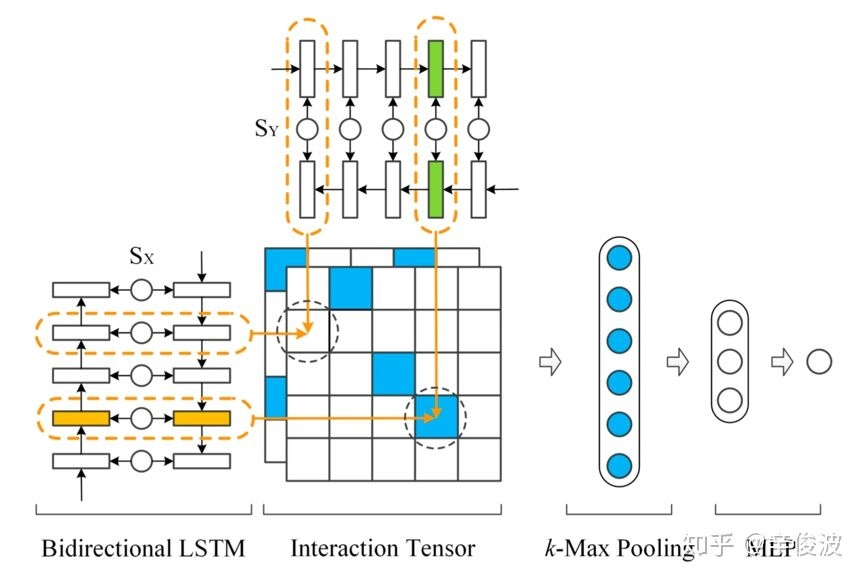
整个模型可以分为3部分:(1)query和doc各自的LSTM编码;(2)query和doc的匹配矩阵;(3)匹配信号融合
- LSTM编码
对于给定的句子\(S=(x_0,x_1,x_2,…,x_T)\),MV-LSTM模型使用双向的LSTM进行编码,对于每个单词\(x_t\)(在query或者doc中的第t个term),用LSTM隐层的输出\(h_t\)作为其表示,由于是双向,因此将两个方向的输出进行concat
- 匹配矩阵计算
上一步通过Bi-LSTM得到query和doc的表示SX和SY,对于SX中每个term,以及SY中每个term的交互可以得到匹配度矩阵。同样的,在这里作者提出了3种不同的计算方法
- cosine相似度
query中的term u以及doc中的term v,计算cosine相似度
- 双线性bilinear
通过引入待训练参数M进行映射
- Tensor layer
这一步的过程和CNTN模型一样
- 匹配信号融合
从上一步可以得到query和doc的匹配度矩阵,在这一步对匹配信号进行融合得到最终的匹配分数。
- k-max pooling
在计算两段文本的匹配过程中,一般来说整个匹配分都是由匹配矩阵中的特定匹配信号决定的,在论文中作者使用了k-max pooling进行这种匹配信号的提取。假设\(k=1\)代表的是最佳匹配信号,也就是整个匹配信号中最大的值才会被选择;对于\(k>1\),代表的是选择匹配信号最大值的top k
- MLP
通过k-max pooling提取匹配信号后接着就是用简单的全连接网络\(f\)后得到r,再经过线性映射得到最终的匹配分数s
总结整个MV-LSTM模型过程如下:
- 用双向LSTM对query和doc进行编码,得到的每个term的隐层前向和后向输出concat起来,作为该term的表示;
- 对query和doc上一步得到的每个term两两计算匹配分数,文中提到了cosine、双线性以及tensor layer这3种计算方法,由于网络参数的不断加大,拟合精确度和复杂度也依次提升
- 对前一步得到的匹配度矩阵,先是用k-max pooling提取,然后用MLP后输出最终的匹配分数
aNMM模型
CIKM2016年提出的attention based Neural Matching Model,简称aNMM模型,原文主要解决QA匹配问题,模型同样可以应用在query和doc中两段文本的匹配关系设计中。前面讲到的ARC-II模型以及MatchPyramid在匹配矩阵后,都用到CNN的卷积层做n-gram的提取。而CNN卷积的基本思想,是不同位置的word是共享权重。而在aNMM模型中,作者认为不同位置的word在卷积核中共享权重是不合理的,因此提出了基于value的共享权重方法。根据共享权重的组数不同,论文提出了两种模型,aNMM-1模型和aNMM-2模型。
aNMM-1模型
按照模型结构可以分为3层,输入层、value share层以及attention层
- input encode层
对于给定的问题query \(q\),以及对应的文档\(a\),\(q\)由m个word组成,\(a\)由n个word组成,通过word embedding得到\(q\)和\(a\)各自的embedding矩阵。让\(q\)和\(a\)的word两两求cosine相似度,可以得到一个\(M*N\)的匹配矩阵\(P\),里面的每个元素\(P_j\),\(i\)代表的是\(q\)中的第\(j\)个term,以及\(a\)中第\(i\)个term的相似度。
- Value share层
从匹配矩阵中P提取到的不同q和a的匹配分数存在一个问题,就是给定一个query,不同doc长度是不同的,得到的匹配矩阵的大小也不同。因此需要有个机制将其映射到定长的维度中去方便后续网络处理。
这里很容易想到CV领域里的CNN网络结构,通过卷积和池化的方法进行维度的压缩。在图像领域CNN之所以能够奏效,很大程度在于图像本身的局部关系,也就是CNN的权重是position-shared的。如图4.17所示是个\(3*1\)的卷积核,相同颜色的边共享权重,所有同个位置的边共享相同的权重,在途中分别是红色、蓝色和绿色
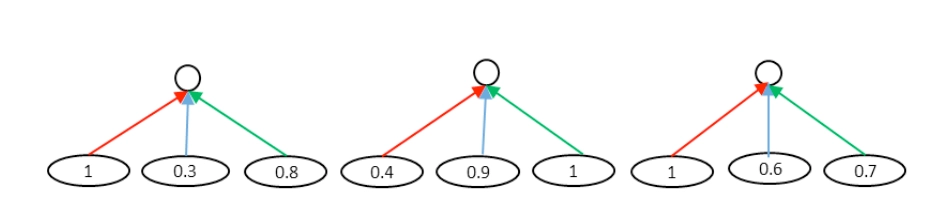
但是在NLP领域的文本匹配问题上,query和doc的匹配term可能出现在任意位置上,并不一定是强位置关联的。在前面得到的query-doc匹配矩阵\(P\)中,不同的匹配分数值对最终结果的共享程度是不同的,相同权重的对结果的共享应该一致,因此作者提出了一种value-shared的权重方法,如图4.18所示。
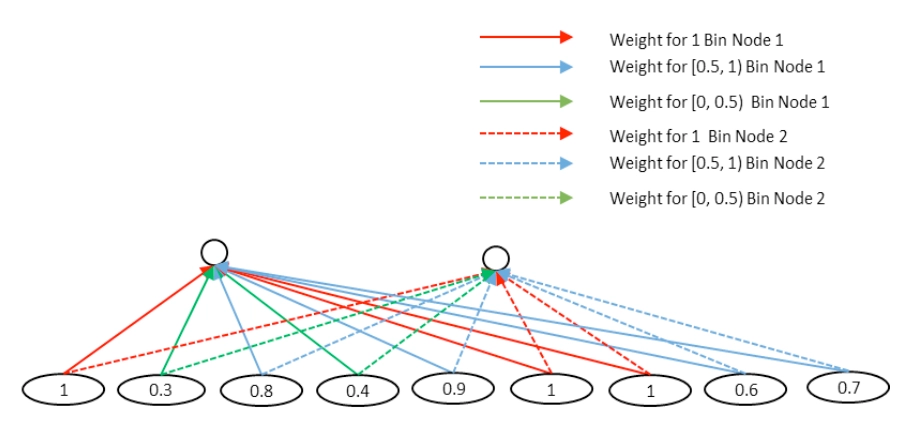
为了方便说明,在图中将区间分成3个桶,[0,0.5],[0.5,1],[1,1]。其中实线部分表示上面第一个结点node1的参数,虚数部分表示第二个结点node2的参数。同样的,相同线型和颜色的表示共享权重。权重等于1的3个结点用红色共享权重,权重小于0.5的两个结点0.3和0.4用绿色共享权重,权重大于等于0.5小于1的4个节点(0.8、0.9、0.6、0.7)共享权重。
由于匹配矩阵\(P\)中每个元素的值都是在-1到1之间(cosine取之范围)。因此在实际模型中作者将取值范围区间按照0.1进行分桶,总共有21个分桶,落到相同的分桶区间的value是共享权重的。通过这样的方式,可以将匹配矩阵转为相同的维度,不管输入矩阵的维度大小,隐层节点的个数都是固定的。
假设后续隐层的维度为\(K+1\),另\(x_{jk}\)表示问题\(q\)中第\(j\)个term,在第\(k\)个分桶节点上的所有匹配信号值,那么隐层第\(j\)个节点则为这\(K+1\)个分桶的加权求和:
- attention层
经过前面两层网络,对于每个query-doc对,都可以计算得到一个\(M*1\)的向量,向量的每个元素都表示doc与当前query中M个term中每个term的相似度。
作者在论文中引入了参数向量\(v\),维度和\(P\)一致,来对问题中的每个term求点积映射得到每个term的权重并做softmax归一化,然后和前面得到的每个隐层节点\(h_j\)相乘,得到最终的匹配分数\(y\)
aNMM-2模型
相比于anmm-1的改进在于,对于value-share权重网络,anmm-1只有一个。而类比于CNN的卷积层有多个filter,anmm-2提出来可以有\(k\)个value-share权重网络,表示权重网络的组数,整体网络结构如图4.19所示。
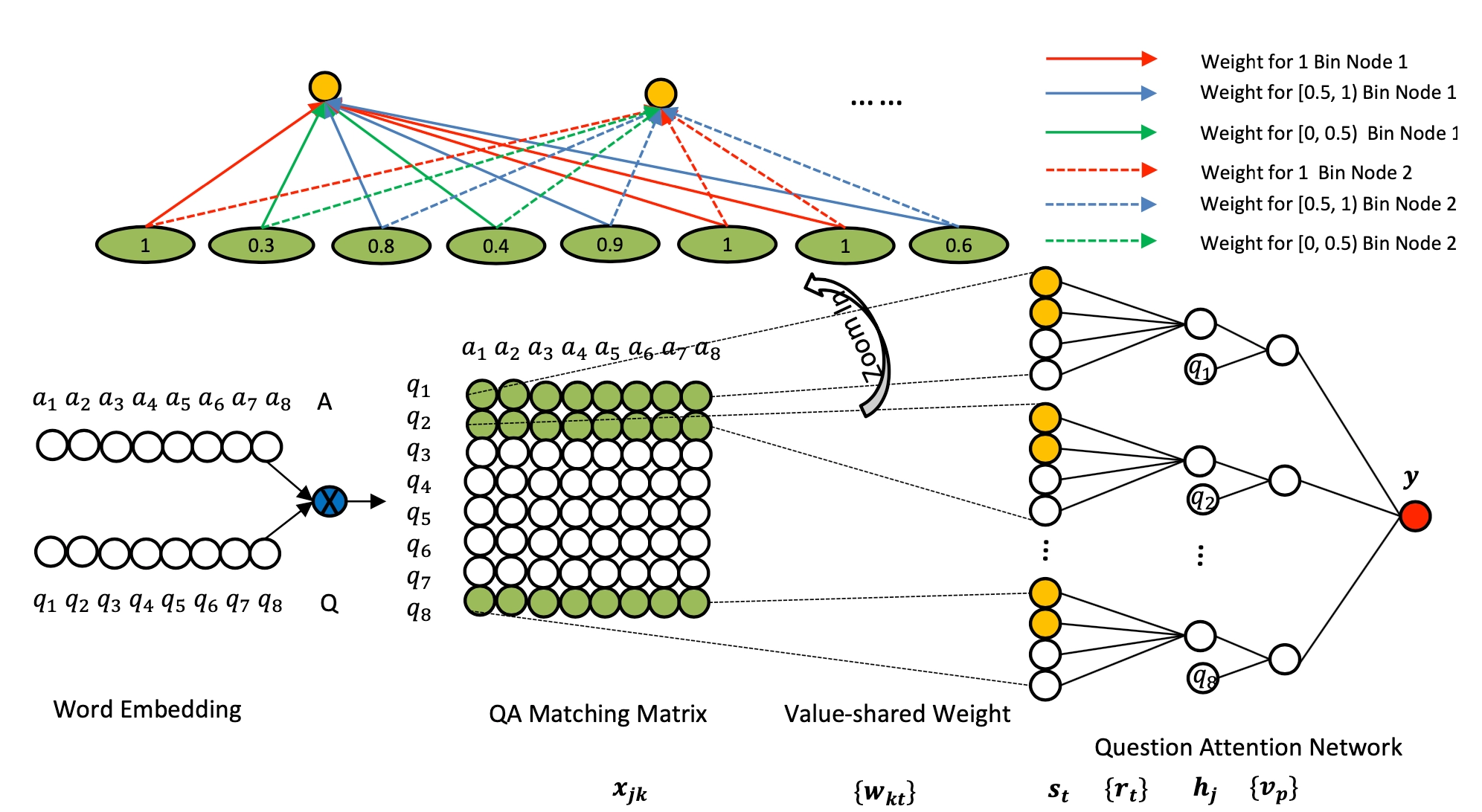
总结来说,aNMM模型结构框架主要的创新点在于:
- 借鉴了CNN模型中相同位置共享权重(position-shared weight)的思想,认为QA匹配问题(可以扩展到其他的query和doc的两段文本匹配问题)不应该是同位置共享,而应该是相同的匹配值共享权重(value-shared weight),从而起到pooling的作用,保证隐层个数都相同
- 类比CNN的多个filter思路,共享权值网络也可以有多层。
基于attention的模型
基于word level的匹配度矩阵可以说是整个基于match function learning模型的标配组件,而这有这种low level的匹配矩阵信息基本是不够的,在当前attention机制在整个NLP领域随处可见的情况下,attention也基本成了后续众多模型的标配组件之一。除了徐君老师的slides里的DecAtt模型,本章也加入了近两年在各大主会&文本比赛里比较流行的十几个模型,如BiMPM、ESIM、DIIN等。
ABCNN模型
前面讲的基于CNN的匹配模型如ARC-II,CNN-DSSM模型在匹配的时候使用了在图像和文本领域都大放异彩的CNN模块,2015年的ACL上在此基础上又加入了近年来在CV和NLP也同样无处不在的attention模块,Attention-Based CNN模型,简称ABCNN用来做query和doc的文本匹配。
语义匹配vs相关匹配
ad-hoc: TREC刚开始的时候只有两个任务,ad hoc和routing。前者类似于图书馆里的书籍检索,即书籍库(数据库)相对稳定不变,不同用户的查询要求是千变万化的。这种检索就称为ad hoc。基于Web的搜索引擎也属于这一类。后者的情况与前者相对,用户的查询要求相对稳定。在routing中,查询常常称为profile,也就是通常所说的兴趣,用户的兴趣在一段时间内是稳定不变的,但是数据库(更确切的说,是数据流)是不断变化的。ad hoc和routing代表了IR的两个不同研究方向。前者的主要研究任务包括对大数据库的索引查询、查询的扩展等等;而后者的主要任务不是索引,而是对用户兴趣的建模,即如何对用户兴趣建立合适的数学模型。
ad-hoc检索中的文本匹配与其他NLP任务之间存在一些差异。许多NLP任务中的匹配,例如释义识别,问答和自动对话,主要涉及语义匹配,即识别语义,推断两段文本之间的语义关系。在这些语义匹配任务中,这两个文本通常是同质的,并且由一些自然语言句子组成,例如问题/答案句子或对话。为了推断自然语言句子之间的语义关系,语义匹配强调了以下三个因素:
- 相似度匹配信号:与精确匹配信号相比,捕获单词,短语和句子之间的语义相似性/相关性非常重要或至关重要。例如,在释义识别中,需要识别两个句子是否用不同的表达来表达相同的含义。在自动对话中,人们寻求在语义上找到与前一个对话相关的正确响应,这可能不会在它们之间共享任何常见的单词或短语。
- 组合意义:由于语义匹配中的文本通常由具有语法结构的自然语言句子组成,因此基于这种语法结构来使用句子的组合意义比将它们视为一组词/一个词序列更为有益。例如,在问题回答中,大多数问题都有明确的语法结构,可以帮助确定反映问题所在的构成意义。
- 全局匹配要求:语义匹配通常将两个文本作为一个整体来处理,以推断它们之间的语义关系,从而产生全局匹配要求。这部分与以下事实相关:语义匹配中的大多数文本具有有限的长度,因此主题范围集中。例如,如果整个含义相同,则两个句子被认为是释义,并且一个好的答案完全回答了这个问题。
相反,ad-hoc检索中的匹配主要是关于相关性匹配,即,给定特定查询,计算文档相关性。在此任务中,查询通常是短的并且基于关键字,而文档的长度可以变化很大,从数十个单词到数千甚至数万个单词。为了估计查询和文档之间的相关性,相关性匹配主要关注以下三个因素:
- 精确匹配信号:虽然术语不匹配是ad-hoc检索中的一个关键问题,并且已经使用不同的语义相似性信号进行了解决,但是由于现代搜索引擎中的索引和搜索范例,文档中的术语与查询中术语的精确匹配仍然是ad-hoc检索中最重要的信号。
- 查询术语重要性:由于查询主要是简短的,基于关键词,而在ad-hoc检索中没有复杂的语法结构,因此考虑术语重要性很重要,而查询术语之间的组成关系通常是操作搜索中简单的“和”关系。例如,给定查询“比特币新闻”,相关文档应该是关于“比特币”和“新闻”,其中“比特币”一词比“新闻”更重要,因为描述“比特币”其他方面的文件比描述其他事物“新闻”的文件更具相关性。在文献中,已有许多关于检索模型的正式研究表明术语歧义的重要性。
- 不同的匹配要求:在ad-hoc检索中,相关文档可能很长,并且文档中有关于文档长的不同假设,导致不同的匹配要求。特别是,“详细程度假设”假设一个长文档就像一个简短的文档,涵盖了相似的范围,但有更多的单词。在这种情况下,如果我们假设短文档具有集中主题,则相关性匹配可能是全局的。相反,“范围假设”假设一个长文档由许多连接在一起的无关短文档组成。通过这种方式,相关性匹配可以发生在相关文档的任何部分中,并且我们不要求整个文档与查询相关。