Stanford Alpaca
结合英文语料通过Self Instruct方式微调LLaMA 7B
Stanford Alpaca简介
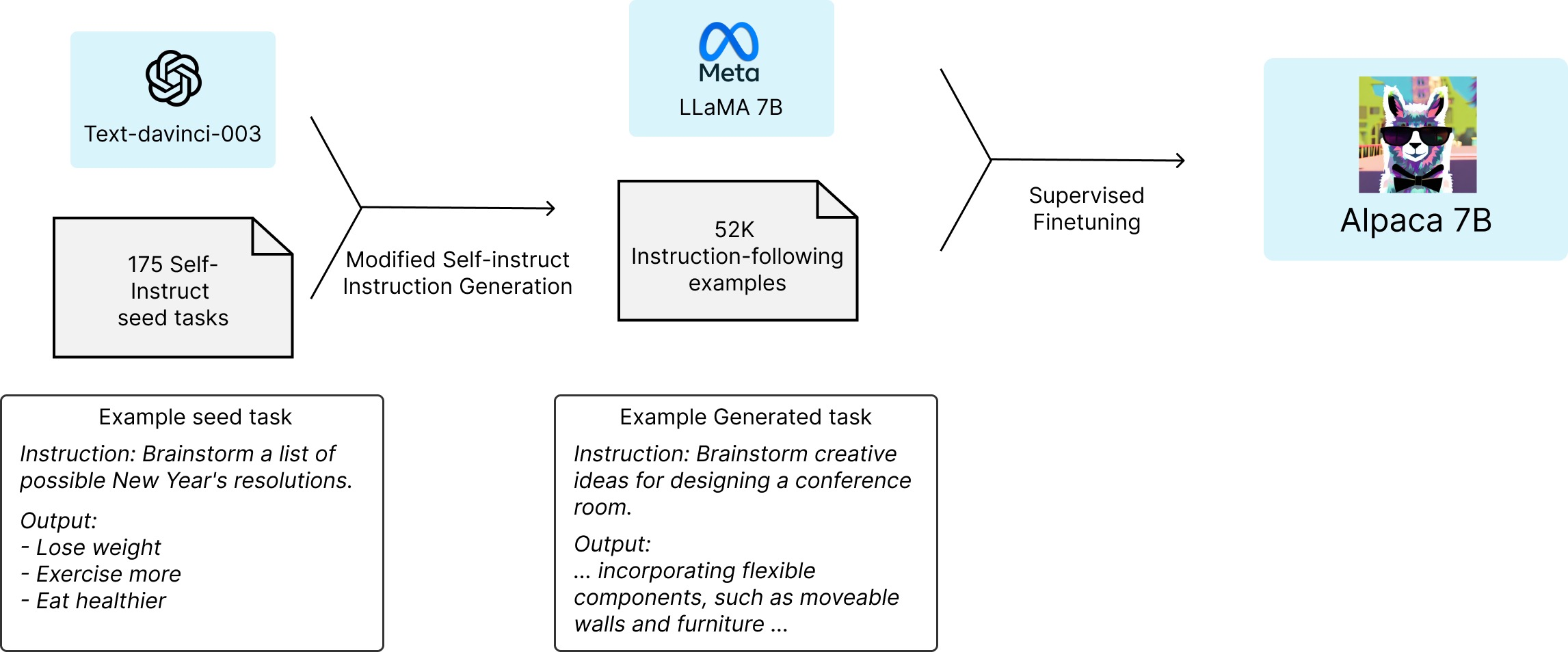
2023年3月中旬,斯坦福的Rohan Taori等人发布Alpaca(中文名:羊驼):号称只花100美元,人人都可微调Meta家70亿参数的LLaMA大模型(即LLaMA 7B),具体做法是通过52k指令数据,然后在8个80GB A100上训练3个小时,使得Alpaca版的LLaMA 7B在单纯对话上的性能比肩GPT-3.5(text-davinci-003),这便是指令调优LLaMA的意义所在
- 论文《Alpaca: A Strong Open-Source Instruction-Following Model》
- GitHub地址:https://github.com/tatsu-lab/stanford_alpaca
- 数据地址 (即斯坦福团队微调LLaMA 7B所用的52K英文指令数据):raw.githubusercontent.com/tatsu-lab/stanford_alpaca/main/alpaca_data.json
有意思的是,后来不断有人把这52K的英文指令数据翻译了下,比如: 单纯翻译的斯坦福52K中文指令数据 斯坦福52K中文指令数据(语句上做了中文表达风格的意译)
这52K数据所对应的alpaca_data.json文件是一个字典列表,每个字典包含以下字段:
- instruction: str,描述了模型应该执行的任务,52K 条指令中的每一条都是唯一的、
- input: str,要么是上下文,要么直接输入(optional context or input for the task),例如,当指令是“总结以下文章”时,输入就是文章,大约 40% 的示例有输入
- output: str,由GPT3.5对应的API即 text-davinci-003生成的指令的答案
self-instruct
什么是self-instruct方式:提示GPT3/GPT3.5/GPT4的API收集数据
而这52K数据是怎么来的呢?实际上,是通过Self-Instruct『Self-Instruct是来自华盛顿大学Yizhong Wang等人于22年12月通过这篇论文《SELF-INSTRUCT: Aligning Language Model with Self Generated Instructions》提出的,这是其论文地址、代码地址』提示GPT3的API拿到的

具体而言,论文中提出
- 人工设计175个任务,每个任务都有对应的{指令 输入 输出/实例}或{指令 输出/实例},将这175个任务数据作为种子集
比如这是斯坦福Alpaca的175个种子数据:github.com/tatsu-lab/stanford_alpaca/blob/main/seed_tasks.jsonl
- 然后提示模型比如GPT3对应的API即 text-davinci-001 (原论文中没用text-davinci-003,because their newer engines are trained with the latest user data and are likely to already see the SUPERNI evaluation set,但实际应用时比如斯坦福Alpaca指定的GPT3.5的API即 text-davinci-003生成指令,包括很快你将看到,23年4月还有微软的研究者指定GPT4的API生成指令),使用种子集作为上下文示例来生成更多新的指令
- 对该模型生成的指令判断是否分类任务
- 使用模型生成实例
- 对上述模型生成的数据{指令 输入 输出/实例}过滤掉低质量或相似度高的
- 将经过过滤和后处理的数据添加到种子池中
一直重复上述2-6步直到种子池有足够多的数据
生成微调LLaMA的52K数据
斯坦福的Alpaca在实际生成52K数据时,在上节self-instruct方式的基础上,还考虑到了多重过滤机制,防止生成过于相似、过长或含有特定关键词的指令,以此保证生成的指令集的质量和多样性,且在每一轮生成指令后,都会保存当前的结果,方便随时跟踪进度,此外,还采用了多进程处理,提高了效率
故最终完整生成52K数据的完整代码如下(来源于:https://github.com/tatsu-lab/stanford_alpaca/blob/main/generate_instruction.py
所以Alpaca,就是花了不到500美元使用OpenAI API生成了5.2万个这样的示例微调LLaMA搞出来的,个人觉得可以取名为 instructLLaMA-7B
这里有个实战的例子可以作为参考:【self-instruct方式生成语料代码实战】
GPT4生成指令数据
值得一提的是,后来23年4月有微软的研究者提示GPT4的API进行指令微调「论文地址:INSTRUCTION TUNING WITH GPT-4、GitHub地址:instruction-Tuning-with-GPT-4、项目地址:使用GPT4进行指令调优」,从而生成以下数据
- English Instruction-Following Data,generated by GPT-4 using Alpaca prompts
这部分数据在项目文件 alpaca_gpt4_data.json 里contains 52K instruction-following data generated by GPT-4 with prompts in Alpaca. This JSON file has the same format as Alpaca data, except the output is generated by GPT-4: instruction: str, describes the task the model should perform. Each of the 52K instructions is unique. input: str, optional context or input for the task. output: str, the answer to the instruction as generated by GPT-4.
- Chinese Instruction-Following Data,即上面英文数据的中文翻译,存储在项目文件alpaca_gpt4_data_zh.json 里
- Comparison Data ranked by GPT-4,训练一个奖励模型
存储在 comparision_data.json 文件里,
该数据用于大规模量化 GPT-4 与我们的指令调整模型(即LLaMA by instruction tuning with GPT4)之间的差距,而缩小与GPT4的差距便是本次指令调优的目标ranked responses from three models, including GPT-4, GPT-3.5 and OPT-IML by asking GPT-4 to rate the quality. user_input: str, prompts used for quering LLMs. completion_a: str, a model completion which is ranked higher than completion_b. completion_b: str, a different model completion which has a lower quality score. Answers on Unnatural Instructions Data,

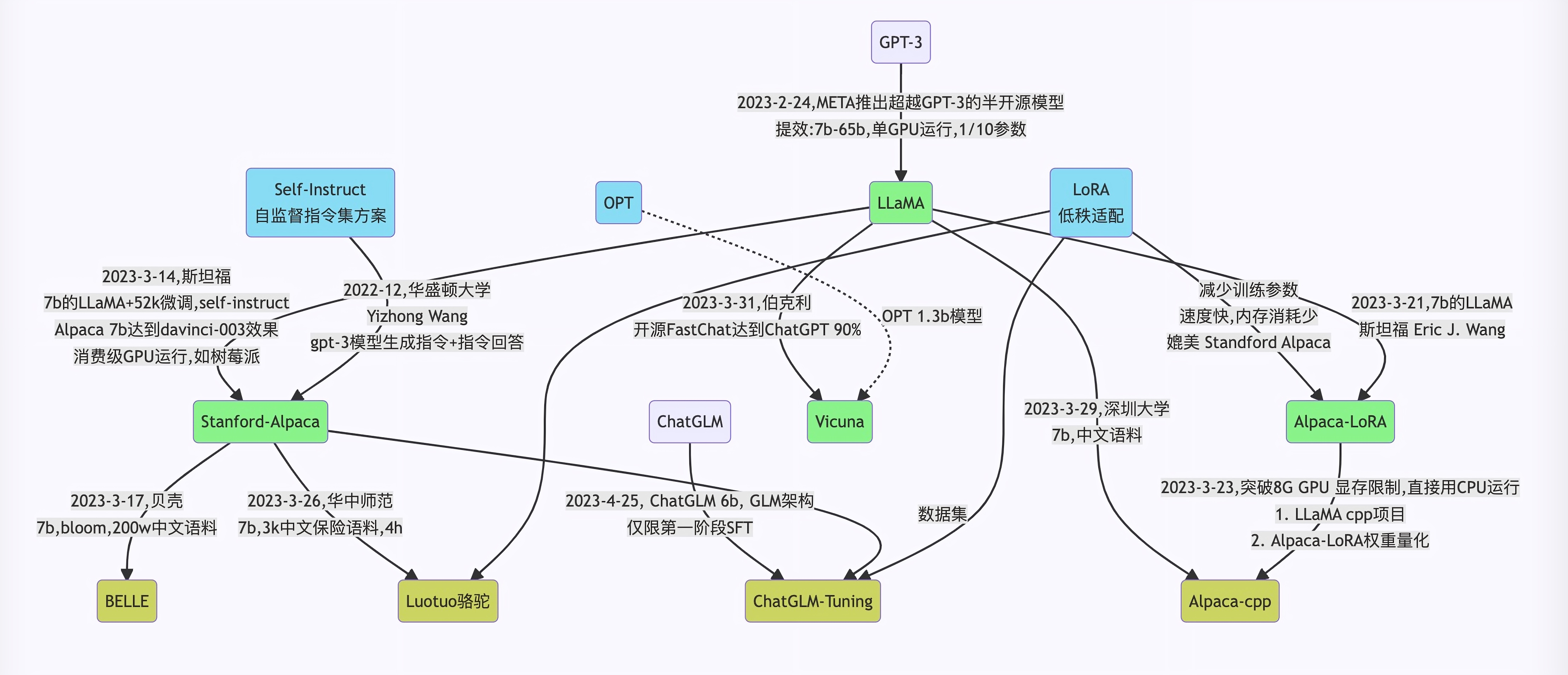
Alpaca所用的self-instruct的影响力:解决一大批模型的数据扩展问题
- self-instruct启发出很多「羊驼类模型」
羊驼率先带动的self-instruct,启发后续很多人/团队也用这个方式去采集『提示ChatGPT API』的数据,比如BELLE、ChatLLaMA、ColossalChat
- 很多「羊驼类模型」的数据被用于微调新一批模型
然后还有一批模型各种叠加组合比如『Alpaca/BELLE』,又用于微调一批批模型
比如ChatDoctor 有用到Alpaca的数据进行微调,再比如有人拿BELLE数据tuning去调chatglm
一下子出来这么新的模型 似乎有点懵,没事,请看下文及下一篇文章娓娓道来..
Vicuna
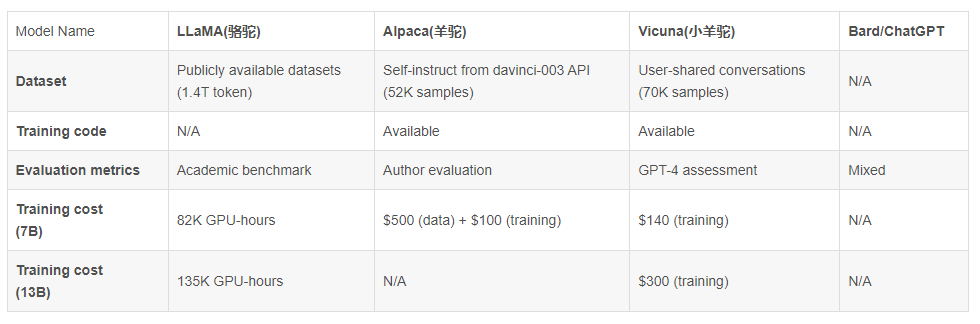
23年3.31日,受 Meta LLaMA 和 Stanford Alpaca 项目的启发,加州大学伯克利分校(UC Berkeley)等大学的研究者根据从 ShareGPT.com (ShareGPT是一个用户可以分享他们的 ChatGPT 对话的网站)收集的用户共享对话微调 LLaMA 推出了Vicuna-13B(中文称小羊驼)
https://github.com/lm-sys/FastChat
在数据规模上,Vicuna从ShareGPT.com 的公共 API 收集了大约 70K 用户共享对话,且为了确保数据质量,原作者们将 HTML 转换回 markdown 并过滤掉一些不合适或低质量的样本。此外,将冗长的对话分成更小的部分,以适应模型的最大上下文长度,并做了以下改进
- 内存优化:为了使 Vicuna 能够理解长上下文,将最大上下文长度从羊驼Alpaca中的 512 扩展到 2048,这大大增加了 GPU 内存需求,对此通过利用梯度检查点和闪存注意力来解决内存压力 (We tackle the memory pressure by utilizing gradient checkpointing and flash attention)
- 多轮对话:调整训练损失以考虑多轮对话,并仅根据聊天机器人的输出计算微调损失
- 通过Spot Instance 降低成本:40 倍大的数据集和 4 倍的训练序列长度对训练费用提出了相当大的挑战。原作者们使用SkyPilot managed spot 来降低成本『SkyPilot是加州大学伯克利分校构建的一个框架,用于在各种云上轻松且经济高效地运行 ML 工作负载』,方法是利用更便宜的spot instances以及auto-recovery for preemptions and auto zone switch
该解决方案将 7B 模型的训练成本从 500 美元削减至 140 美元左右,将 13B 模型的训练成本从 1000 美元左右削减至 300 美元
有两点值得一提的是
- Vicuna的预训练是一天之内通过8个具有 80GB 显存的 A100 GPU 进行训练的,预训练好之后单纯部署的话,Vicuna-13B 需要大约 28GB 的GPU 显存,Vicuna-7B 大约需要14GB GPU显存
- 且Vicuna使用了和Alpaca差不多的超参数

最终通过直接使用GPT4评估之后(基于 GPT-4 的评估框架来自动评估聊天机器人的性能),效果还不错
链家BELLE
Stanford Alpaca的种子任务都是英语,收集的数据也都是英文,因此训练出来的模型未对中文优化。为了提升对话模型在中文上的效果,70 亿参数的中文对话大模型 BELLE『Bloom-Enhanced Large Language model Engine』来了。
https://github.com/LianjiaTech/BELLE
在数据方面,结合以下两方面的数据:
- Alpaca 的 5.2 万条英文数据
- 通过Alpaca的数据收集代码生成的约 100 万条中文数据『也仅使用由 GPT3.5 即模型text-davinci-003 生产的数据,不包含任何其他数据,如果想使用ChatGPT的API比如gpt-3.5-turbo模型,可通过参数控制』
模型训练上,有
- 基于BLOOMZ-7B1-mt优化后的模型:BELLE-7B-0.2M,BELLE-7B-0.6M,BELLE-7B-1M,BELLE-7B-2M
- 基于huggingface的LLaMA实例实现调优的模型:BELLE-LLAMA-7B-2M,BELLE-LLAMA-13B-2M
BLOOM是由HuggingFace于2022年3月中旬推出的大模型,规模最大版本的参数量达到176B(GPT-3是175B),基于从 Megatron-LM GPT-2修改而来的仅解码器 transformer 模型架构
对应的论文为《BLOOM: A 176B-Parameter Open-Access Multilingual Language Model》
此外,这里有篇不错的文章(重点讲了下Megatron-DeepSpeed):千亿参数开源大模型 BLOOM 背后的技术
huggingface.co/blog/zh/bloom-megatron-deepspeed
该项目主要包含以下三部分内容:
- 175 个中文种子任务,斯坦福Alpaca一样,每个任务都包含对应的指令/任务、prompt、输出
zh_seed_tasks.jsonl:样例如下
{ "id": "seed_task_20", "name": "horror_movie_opening",
"instruction": "你需要为一部恐怖电影写一个创意的开场场景。",
"instances": [{"input": "","output":" 太阳已经落山,留下了一个黑暗的小镇。微风吹拂空荡的街道,让每一个冒险走出门外的人感到一阵寒意。唯一的声音是被风吹动的树叶发出的轻微沙沙声。突然,一声令人毛骨悚然的尖叫声划破了寂静,随后是玻璃破碎的声音。一所房子亮起了灯光,可以看到一个人影朝镇中心奔跑。当> 那个人影越来越靠近时,清楚地看到那是一个年轻女子,她浑身血迹斑斑。"}],
"is_classification": false }- prompt_cn.txt: 生成所使用的提示语 0.5M 生成的数据
- 生成数据及其代码沿用 Alpaca 的方式:
默认使用 Completion API,模型 text-davinci-003。如果想使用 Chat API 并使用 gpt-3.5-turbo 模型,可通过参数控制: python generate_instruction.py generate_instruction_following_data \ --api=chat --model_name=gpt-3.5-turbo
输出文件在 Belle.train.json,可以人工筛选后再使用
- 基于 BLOOMZ-7B1-mt 模型和 Belle.train.json 训练模型
Chinese-LLaMA/Chinese-Alpaca
Chinese LLaMA(也称中文LLaMA,有7B和13B两个版本,项目地址),相当于在原版LLaMA的基础上扩充了中文词表并使用了中文数据进行二次预训练,进一步提升了中文基础语义理解能力,同时,在中文LLaMA的基础上,且用中文指令数据进行指令精调得Chinese-Alpaca(也称中文Alpaca,同样也有7B和13B两个版本)
具体而言,主要做了以下三方面的工作
- 词表扩充中文数据
在通用中文语料上训练了基于SentencePiece的20K中文词表并与原版LLaMA模型的32K词表进行合并
排除重复的token后,得到的最终中文LLaMA词表大小为49953
需要注意的是,在fine-tune阶段Alpaca比LLaMA多一个pad token,所以中文Alpaca的词表大小为49954
这么做的主要原因是原版LLaMA模型的词表大小是32K,其主要针对英语进行训练,对多语种支持不是特别理想(可以对比一下多语言经典模型XLM-R的词表大小为250K)。通过初步统计发现,LLaMA词表中仅包含很少的中文字符,所以在切词时会把中文切地更碎,需要多个byte token才能拼成一个完整的汉字,进而导致信息密度降低
代码地址在:https://github.com/ymcui/Chinese-LLaMA-Alpaca/blob/main/scripts/merge_tokenizer/merge_tokenizers.py
- 加入中文数据的预训练
在预训练阶段,使用约20G左右的通用中文语料(与中文BERT-wwm、MacBERT、LERT、PERT中使用的语料一致)在原版LLaMA权重的基础上进一步进行预训练。该过程又分为两个阶段:
第一阶段:冻结transformer参数,仅训练embedding,在尽量不干扰原模型的情况下适配新增的中文词向量
第二阶段:使用LoRA技术,为模型添加LoRA权重(adapter),训练embedding的同时也更新LoRA参数
- 指令精调
指令精调阶段的任务形式基本与Stanford Alpaca相同,训练方案同样采用了LoRA进行高效精调,并进一步增加了可训练参数数量
在prompt设计上,精调以及预测时采用的都是原版Stanford Alpaca不带input的模版。对于包含input字段的数据,采用" f{instruction}+\n+{input} "的形式进行拼接
且指令精调阶段使用了以下数据,其中7B模型约2M数据、13B模型约3M数据。
当然,针对一些任务上效果不好!原作者也给出了几个可能的原因,
- 本身LLaMA对中文支持不是很好,大多数相关衍生工作是直接在原版上进行pretrain/finetune的,而我们采取了更大胆的策略——增加中文词表,可能进一步加剧中文训练不充分的问题,但从长远看是否有利于后续进一步预训练就得靠时间检验了;
- 指令数据的质量有待进一步提升;
- 训练时间、超参等方面还有很大调整空间;
- 没有RLHF;
- 4-bit量化后效果可能会下降,因此可以尝试加载FP16模型,效果相对更好一些(也更慢)