旋转式位置编码(ROPE)
原始的Sinusoidal位置编码总的感觉是一种“想要成为相对位置编码的绝对位置编码”。一般来说,绝对位置编码具有实现简单、计算速度快等优点,而相对位置编码则直接地体现了相对位置信号,跟我们的直观理解吻合,实际性能往往也更好。由此可见,如果可以通过绝对位置编码的方式实现相对位置编码,那么就是“集各家之所长”、“鱼与熊掌兼得”了。Sinusoidal位置编码隐约做到了这一点,但并不够好。
本文将会介绍我们自研的Rotary Transformer(RoFormer)模型,它的主要改动是应用了笔者构思的“旋转式位置编码(Rotary Position Embedding,RoPE)”,这是一种配合Attention机制能达到“绝对位置编码的方式实现相对位置编码”的设计。而也正因为这种设计,它还是目前唯一一种可用于线性Attention的相对位置编码。
RoFormer:https://github.com/ZhuiyiTechnology/roformer
基本思路
在之前的文章《让研究人员绞尽脑汁的Transformer位置编码》中我们就简要介绍过RoPE,当时称之为“融合式”,本文则更加详细地介绍它的来源与性质。在RoPE中,我们的出发点就是“通过绝对位置编码的方式实现相对位置编码”,这样做既有理论上的优雅之处,也有实践上的实用之处,比如它可以拓展到线性Attention中就是主要因为这一点。
为了达到这个目的,我们假设通过下述运算来给 \(𝑞,𝑘\) 添加绝对位置信息:
也就是说,我们分别为\(𝑞,𝑘\) 设计操作\(\boldsymbol{f}(\cdot, m),\boldsymbol{f}(\cdot, n)\),使得经过该操作后,\(\tilde{\boldsymbol{q}}_m,\tilde{\boldsymbol{k}}_n\) 就带有了位置 \(𝑚,𝑛\) 的绝对位置信息。Attention的核心运算是内积,所以我们希望的内积的结果带有相对位置信息,因此假设存在恒等关系:
所以我们要求出该恒等式的一个(尽可能简单的)解。求解过程还需要一些初始条件,显然我们可以合理地设\(\boldsymbol{f}(\boldsymbol{q}, 0)=\boldsymbol{q}\) 和 \(\boldsymbol{f}(\boldsymbol{k}, 0)=\boldsymbol{k}\)。
求解过程
同上一篇思路一样,我们先考虑二维情形,然后借助复数来求解。在复数中有\(\langle\boldsymbol{q},\boldsymbol{k}\rangle=\text{Re}[\boldsymbol{q}\boldsymbol{k}^*]\),\(Re[]\) 代表复数的实部,所以我们有
简单起见,我们假设存在复数 \(𝑔(𝑞,𝑘,𝑚−𝑛)\),使得 \(\boldsymbol{f}(\boldsymbol{q}, m)\boldsymbol{f}^*(\boldsymbol{k}, n) = \boldsymbol{g}(\boldsymbol{q},\boldsymbol{k},m-n)\),然后我们用复数的指数形式,设
那么代入方程后就得到方程组
对于第一个方程,代入 \(𝑚=𝑛\) 得到
最后一个等号源于初始条件\(\boldsymbol{f}(\boldsymbol{q}, 0)=\boldsymbol{q}\) 和 \(\boldsymbol{f}(\boldsymbol{k}, 0)=\boldsymbol{k}\)。所以现在我们可以很简单地设\(R_f (\boldsymbol{q}, m)=\Vert \boldsymbol{q}\Vert, R_f (\boldsymbol{k}, m)=\Vert \boldsymbol{k}\Vert\),即它不依赖于 \(𝑚\)。至于第二个方程,同样代入 \(𝑚=𝑛\) 得到
这里的 \(\Theta (\boldsymbol{q}),\Theta (\boldsymbol{k})\) 是 \(𝑞,𝑘\) 本身的幅角,最后一个等号同样源于初始条件。根据上式得到 \(\Theta_f (\boldsymbol{q}, m) - \Theta (\boldsymbol{q}) = \Theta_f (\boldsymbol{k}, m) - \Theta (\boldsymbol{k})\),所以 \(\Theta_f (\boldsymbol{q}, m) - \Theta (\boldsymbol{q})\) 应该是一个只与 \(𝑚\) 相关、跟 \(𝑞\) 无关的函数,记为 \(𝜑(𝑚)\),即 \(\Theta_f (\boldsymbol{q}, m) = \Theta (\boldsymbol{q}) + \varphi(m)\)。接着代入 \(𝑛=𝑚−1\),整理得到
即\(\{𝜑(𝑚)\}\) 是等差数列,设右端为 $𝜃 $ ,那么就解得 \(\varphi(m)=m\theta\) 。
编码形式
综上,我们得到二维情况下用复数表示的RoPE:
根据复数乘法的几何意义,该变换实际上对应着向量的旋转,所以我们称之为“旋转式位置编码”,它还可以写成矩阵形式:
由于内积满足线性叠加性,因此任意偶数维的RoPE,我们都可以表示为二维情形的拼接,即
也就是说,给位置为 𝑚 的向量 \(𝑞\) 乘上矩阵\(\boldsymbol{\mathcal{R}}_m\)、位置为 𝑛 的向量 𝑘 乘上矩阵 \(\boldsymbol{\mathcal{R}}_n\),用变换后的 \(\boldsymbol{Q},\boldsymbol{K}\) 序列做Attention,那么Attention就自动包含相对位置信息了,因为成立恒等式:
值得指出的是,\(\boldsymbol{\mathcal{R}}_m\) 是一个正交矩阵,它不会改变向量的模长,因此通常来说它不会改变原模型的稳定性。
由于\(\boldsymbol{\mathcal{R}}_m\) 的稀疏性,所以直接用矩阵乘法来实现会很浪费算力,推荐通过下述方式来实现RoPE:
其中\(\otimes\) 是逐位对应相乘,即Numpy、Tensorflow等计算框架中的∗ 运算。从这个实现也可以看到,RoPE可以视为是乘性位置编码的变体。
远程衰减
可以看到,RoPE形式上和Sinusoidal位置编码有点相似,只不过Sinusoidal位置编码是加性的,而RoPE可以视为乘性的。在\(𝜃_𝑖\) 的选择上,我们同样沿用了Sinusoidal位置编码的方案,即 \(\theta_i = 10000^{-2i/d}\),它可以带来一定的远程衰减性。
具体证明如下:将 𝑞,𝑘 两两分组后,它们加上RoPE后的内积可以用复数乘法表示为
记 \(h_i = \boldsymbol{q}_{[2i:2i+1]}\boldsymbol{k}_{[2i:2i+1]}^*, S_j = \sum\limits_{i=0}^{j-1} e^{\text{i}(m-n)\theta_i}\),并约定 \(h_{d/2}=0,S_0=0\),那么由 Abel变换(分部求和法)可以得到:
所以
因此我们可以考察 \(\frac{1}{d/2}\sum\limits_{i=1}^{d/2} |S_i|\) 随着相对距离的变化情况来作为衰减性的体现,Mathematica代码如下:
d = 128;
\[Theta][t_] = 10000^(-2*t/d);
f[m_] = Sum[
Norm[Sum[Exp[I*m*\[Theta][i]], {i, 0, j}]], {j, 0, d/2 - 1}]/(d/2);
Plot[f[m], {m, 0, 256}, AxesLabel -> {相对距离, 相对大小}]
结果如下图:

从图中我们可以可以看到随着相对距离的变大,内积结果有衰减趋势的出现。因此,选择\(\theta_i = 10000^{-2i/d}\),确实能带来一定的远程衰减性。当然,同上一篇文章说的一样,能带来远程衰减性的不止这个选择,几乎任意的光滑单调函数都可以,这里只是沿用了已有的选择而已。笔者还试过以 \(\theta_i = 10000^{-2i/d}\) 为初始化,将\(𝜃_𝑖\)视为可训练参数,然后训练一段时间后发现 \(θ_i\) 并没有显著更新,因此干脆就直接固定\(\theta_i = 10000^{-2i/d}\)了。
线性场景
最后,我们指出,RoPE是目前唯一一种可以用于线性Attention的相对位置编码。这是因为其他的相对位置编码,都是直接基于Attention矩阵进行操作的,但是线性Attention并没有事先算出Attention矩阵,因此也就不存在操作Attention矩阵的做法,所以其他的方案无法应用到线性Attention中。而对于RoPE来说,它是用绝对位置编码的方式来实现相对位置编码,不需要操作Attention矩阵,因此有了应用到线性Attention的可能性。
关于线性Attention的介绍,这里不再重复,有需要的读者请参考《线性Attention的探索:Attention必须有个Softmax吗?》。线性Attention的常见形式是:
其中 \(𝜙,𝜑\) 是值域非负的激活函数。可以看到,线性Attention也是基于内积的,所以很自然的想法是可以将RoPE插入到内积中:
但这样存在的问题是,内积 \([\boldsymbol{\mathcal{R}}_i\phi(\boldsymbol{q}_i)]^{\top} [\boldsymbol{\mathcal{R}}_j\varphi(\boldsymbol{k}_j)]\) 可能为负数,因此它不再是常规的概率注意力,而且分母有为0的风险,可能会带来优化上的不稳定。考虑到 \(\boldsymbol{\mathcal{R}}_i,\boldsymbol{\mathcal{R}}_j\) 都是正交矩阵,它不改变向量的模长,因此我们可以抛弃常规的概率归一化要求,使用如下运算作为一种新的线性Attention:
也就是说,RoPE只插入分子中,而分母则不改变,这样的注意力不再是基于概率的(注意力矩阵不再满足非负归一性),但它某种意义上来说也是一个归一化方案,而且也没有证据表明非概率式的注意力就不好(比如 Nyströmformer 也算是没有严格依据概率分布的方式构建注意力),所以我们将它作为候选方案之一进行实验,而我们初步的实验结果显示这样的线性Attention也是有效的。
此外,笔者在《线性Attention的探索:Attention必须有个Softmax吗?》中还提出过另外一种线性Attention方案:\(\text{sim}(\boldsymbol{q}_i, \boldsymbol{k}_j) = 1 + \left( \frac{\boldsymbol{q}_i}{\Vert \boldsymbol{q}_i\Vert}\right)^{\top}\left(\frac{\boldsymbol{k}_j}{\Vert \boldsymbol{k}_j\Vert}\right)\),它不依赖于值域的非负性,而RoPE也不改变模长,因此RoPE可以直接应用于此类线性Attention,并且不改变它的概率意义。
模型开源
RoFormer的第一版模型,我们已经完成训练并开源到了Github中:
RoFormer:https://github.com/ZhuiyiTechnology/roformer
简单来说,RoFormer是一个绝对位置编码替换为RoPE的WoBERT模型,它跟其他模型的结构对比如下:
在预训练上,我们以WoBERT Plus为基础,采用了多个长度和batch size交替训练的方式,让模型能提前适应不同的训练场景:
从表格还可以看到,增大序列长度,预训练的准确率反而有所提升,这侧面体现了RoFormer长文本语义的处理效果,也体现了RoPE具有良好的外推能力。在短文本任务上,RoFormer与WoBERT的表现类似,RoFormer的主要特点是可以直接处理任意长的文本。下面是我们在 CAIL2019-SCM 任务上的实验结果:
其中--后面的参数是微调时截断的maxlen,可以看到RoFormer确实能较好地处理长文本语义,至于设备要求,在24G显存的卡上跑maxlen=1024,batch_size可以跑到8以上。目前中文任务中笔者也就找到这个任务比较适合作为长文本能力的测试,所以长文本方面只测了这个任务,欢迎读者进行测试或推荐其他评测任务。
当然,尽管理论上RoFormer能处理任意长度的序列,但目前RoFormer还是具有平方复杂度的,我们也正在训练基于线性Attention的RoFormer模型,实验完成后也会开源放出,请大家期待。
在LLAMA中的实现
# 生成旋转矩阵
def precompute_freqs_cis(dim: int, seq_len: int, theta: float = 10000.0):
# 计算词向量元素两两分组之后,每组元素对应的旋转角度\theta_i
freqs = 1.0 / (theta ** (torch.arange(0, dim, 2)[: (dim // 2)].float() / dim))
# 生成 token 序列索引 t = [0, 1,..., seq_len-1]
t = torch.arange(seq_len, device=freqs.device)
# freqs.shape = [seq_len, dim // 2]
freqs = torch.outer(t, freqs).float() # 计算m * \theta
# 计算结果是个复数向量
# 假设 freqs = [x, y]
# 则 freqs_cis = [cos(x) + sin(x)i, cos(y) + sin(y)i]
freqs_cis = torch.polar(torch.ones_like(freqs), freqs)
return freqs_cis
# 旋转位置编码计算
def apply_rotary_emb(
xq: torch.Tensor,
xk: torch.Tensor,
freqs_cis: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
# xq.shape = [batch_size, seq_len, dim]
# xq_.shape = [batch_size, seq_len, dim // 2, 2]
xq_ = xq.float().reshape(*xq.shape[:-1], -1, 2)
xk_ = xk.float().reshape(*xk.shape[:-1], -1, 2)
# 转为复数域
xq_ = torch.view_as_complex(xq_)
xk_ = torch.view_as_complex(xk_)
# 应用旋转操作,然后将结果转回实数域
# xq_out.shape = [batch_size, seq_len, dim]
xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(2)
xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(2)
return xq_out.type_as(xq), xk_out.type_as(xk)
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.wq = Linear(...)
self.wk = Linear(...)
self.wv = Linear(...)
self.freqs_cis = precompute_freqs_cis(dim, max_seq_len * 2)
def forward(self, x: torch.Tensor):
bsz, seqlen, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(batch_size, seq_len, dim)
xk = xk.view(batch_size, seq_len, dim)
xv = xv.view(batch_size, seq_len, dim)
# attention 操作之前,应用旋转位置编码
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
# scores.shape = (bs, seqlen, seqlen)
scores = torch.matmul(xq, xk.transpose(1, 2)) / math.sqrt(dim)
scores = F.softmax(scores.float(), dim=-1)
output = torch.matmul(scores, xv) # (batch_size, seq_len, dim)
# ......
这里举一个例子,假设 batch_size=10, seq_len=3, d=8,则调用函数 precompute_freqs_cis(d, seq_len) 后,生成结果为:
In [239]: freqs_cis
Out[239]:
tensor([[ 1.0000+0.0000j, 1.0000+0.0000j, 1.0000+0.0000j, 1.0000+0.0000j],
[ 0.5403+0.8415j, 0.9950+0.0998j, 0.9999+0.0100j, 1.0000+0.0010j],
[-0.4161+0.9093j, 0.9801+0.1987j, 0.9998+0.0200j, 1.0000+0.0020j]])
以结果中的第二行为例(对应的 m = 1),也就是:
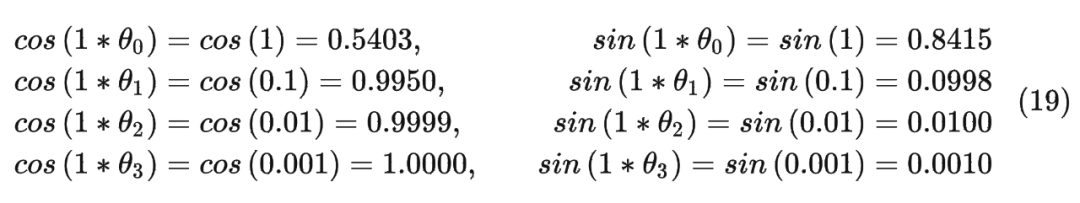
注意:在代码中是直接用 freqs_cis[0] * xq_[0] 的结果表示第一个 token 对应的旋转编码。其中将原始的 query 向量 转换为了复数形式。
这里为什么可以这样计算?
主要是利用了复数的乘法性质。
我们首先来复习一下复数乘法的性质:
因此要计算:
可以转化为计算:
小结
本文介绍了我们自研的旋转式位置编码RoPE以及对应的预训练模型RoFormer。从理论上来看,RoPE与Sinusoidal位置编码有些相通之处,但RoPE不依赖于泰勒展开,更具严谨性与可解释性;从预训练模型RoFormer的结果来看,RoPE具有良好的外推性,应用到Transformer中体现出较好的处理长文本的能力。此外,RoPE还是目前唯一一种可用于线性Attention的相对位置编码。
2D-ROPE
Transformer模型在视觉领域也大火,各种Vision Transformer(ViT)层出不穷,于是就有了问题:二维情形的RoPE应该是怎样的呢?乍一看上去,这个似乎应该只是一维情形的简单推广,但其中涉及到的推导和理解却远比我们想象中复杂,本文就对此做一个分析,从而深化我们对RoPE的理解。
二维RoPE
什么是二维位置?对应的二维RoPE又是怎样的?它的难度在哪里?在这一节中,我们先简单介绍二维位置,然后直接给出二维RoPE的结果和推导思路,在随后的几节中,我们再详细给出推导过程。
二维位置
在NLP中,语言的位置信息是一维的,换句话说,我们需要告诉模型这个词是句子的第几个词;但是在CV中,图像的位置信息是二维的,即我们需要告诉模型这个特征是在第几行、第几列。这里的二维指的是完整描述位置信息需要两个数字,并不是指位置向量的维数。
有读者可能想:简单展平后当作一维的处理不行吗?确实不大行,比如一个 \(h\times h\) 的feature map,位置 \((x,y)\) 展平后就变成了\(xh + y\),而位置 \((x+1,y)\) 和 \((x,y+1)\) 展平后就分别变成了\(xh+y+h\) 和 \(xh+y+1\),两者与 \(xh + y\) 的差分别是 \(h\) 和 \(1\)。然而,按照我们直观的认识,\((x+1,y)\)、\((x,y+1)\) 它们与 \((x,y)\) 的距离应该是一样的才对,但是展平后却得到了不一样的 \(h\) 和 \(1\),这未免就不合理了。
所以,我们需要专门为二维情形设计的位置编码,不能简单地展平为一维来做。
标准答案
经过后面的一番推导,得到二维RoPE的一个解为: