精排是用pointwise方式对商品的CTR/CVR进行预估,旨在建模s=f(user, query, item, context) ,对候选商品进行打分。但有些情况下仅有精排还存在不足之处,如:
1、即使对单个商品进行打分,资源效率限制下,上千候选的精排有时也无法落地更加复杂的模型;
2、pointwise模式的打分无法从候选列表整体或上下文实时反馈角度出发进行排序;
3、直接使用精排分排序无法满足特殊整体性排序需求,如常见的搜索结果的多样性(如价格、地域、品牌、风格等属性的打散)、发现性、异质内容的混排调控(如商品、内容、广告等物料的混排)、流量调控等。
相应地,从以上三点出发,本文从“更加精准打分”、“关注序和上下文”、“特殊需求重排”三方面梳理重排的一般方法:
更加精准打分
重排的第一种动机是精排后更加精准的打分,实现这个目标有几种常见的思路:1、减少排序候选,使用计算复杂度更高的模型,如使用长序列建模,复杂网络结构的排序建模等;2、增加链路实效性,如模型实时(online learning)[1]、特征实时等;3、多目标ensemble,手拍权重,或自动学习多个目标(CTR/CVR等)权重,如[2]使用贝叶斯优化方法进行在线超参数学习。此外还有个性化权重学习,如以点击或成交为目标,使得不同用户或搜索词ensemble权重不一。
值得一提的是,上述1、2在计算资源足够的情况下,这里的重排也普遍下沉,成为精排。
关注序和上下文
相比更加精准的打分,“关注序和上下文特征”可以说是重排更具特色的地方。而对此部分,这里主要从传统LTR流、生成、强化学习等三个方向介绍:
LTR
Learning-to-rank (LTR)顾名思义,是通过机器学习技术解决item排序问题,经典的LTR算法分为Point-Wise, Pair-Wise, List-Wise三类。其中Point-Wise模型将rank问题看作是每个item的分类或回归问题,在前文粗排、精排的预估模型都可以视作此类方法。
Pairwise模型则将原问题转化为pair对的内部排序问题,对正样本对<query, +item>,和负样本<query, -item>,不关心score(query, +item)和score(query, -item)的打分是多少,只要score(positive pair)-score(negative pair)的分数足够大即可。如比较早的RankNet[3],使用logistic函数来建模+item好于-item的概率 ,并使用交叉熵来对目标进行拟合。而近些日子,hinge loss和triple loss等对比学习loss成了类似目标的主流。另一个比较经典的LambdaRank,则在RankNet思想基础上引入NDCG目标,更好地贴近信息检索中的评价指标,而LambdaMart进一步与GBDT融合,则是另一种实现方式(也可以看作Listwise方法)。
List-wise模型则更进一步直接对序列进行优化,考虑给定查询下的文档集合的整体,建模商品序列的整体信息和对比信息。

如最简单的ListNet[5],同样套用交叉熵loss:

其中Eq.(3)为: ,loss函数:
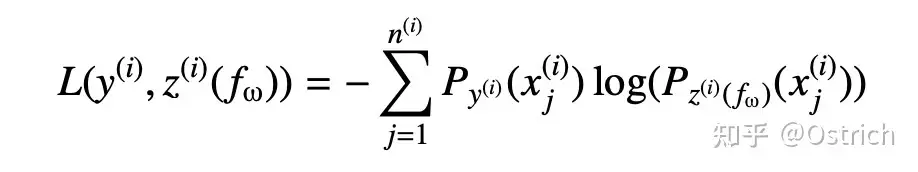
而 。可以看到ListNet和RankNet十分相似,不一样在于前者将一个list作为一个样本,后者以pair对为样本;前者使用listwise loss而后者使用pairwise loss。再仔细一看,listwise loss和大火的Contrastive Learning中InfoNCE loss也是基本一致。另外一些典型的工作如MIRNN [6]、DLCM[7]、PRM [8]则分别通过 DNN、RNN、Self-Attention来做List encoder提取上述score list。
生成&强化
即是使用List-Wise方法得到的候选序列,可以从list维度考虑排序,但在最终得到序列时也是逐个使用贪心方法选择候选item,还是不能做到充分上下文感知以及从整体("长期")收益的序列生成。而序列生成方法和强化重排则致力于此,如Seq2Slate [9] 和MIRNN [6] 都通过 RNN 来提取序列信息,再通过 Attention 或者 Pointer-network等方式来从输入商品列表中一步步地生成最终推荐列表。
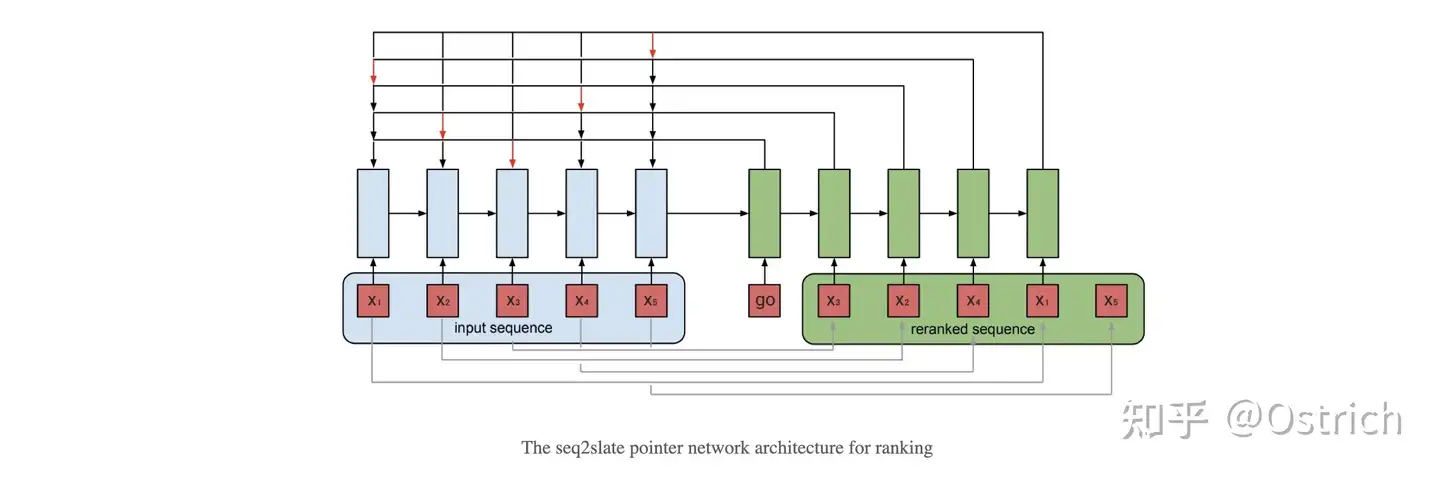
另一方面,组合候选优化Exact-K [10] 、SLATEQ[11]则使用强化学习方法,注重于直接对序列整体收益进行建模。还有很多丰富多样的生成&强化重排方法,篇幅原因这里不展开介绍。
特殊需求重排
除了上述以效率为目标的重排,在搜索系统中还有很多其他特殊需求的重排,这里主要介绍常见的多样性、混排、流量调控等方法。
多样性
提到多样性,自然会想到推荐领域的两大经典算法MMR(Maximal Marginal Relevance)[12]、DPP(Determinantal Point Process)。以MMR最大边际相关性算法为例,其目标为保持关联性的同时,减小排序结果的冗余,也常用于文本摘要生成:
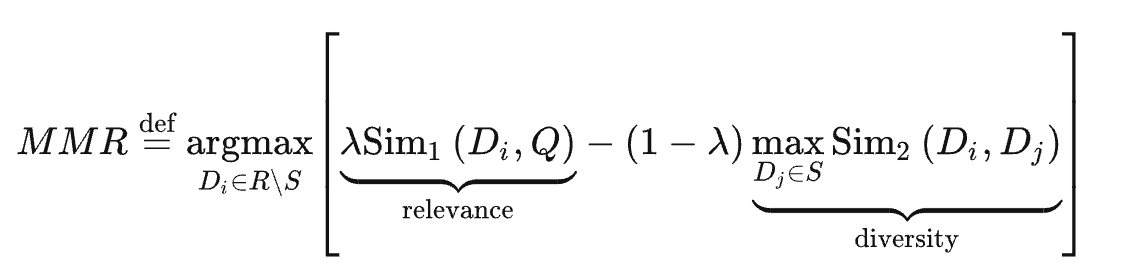
其中 为用户query, 为推荐列表, 为正在生成中的候选集合,R\S为 中未被选中集合, 为超参数用以调节权重。
从MMR公式看,前项为query和当前待排item的相关性,后项为当前item与已生成候选集合中item的最大相关性值,并使用 来调节相关性与多样性的权重。实践过程中,则是采用遍历+贪心的思路生成最终候选序列。
话说回来,搜索场景中的多样性往往要求没那么高(或者说早期没那么高),更多的只是要求有限维度下的多样打散,如:同屏卖家打散、同描述、同首图打散等,这点通过规则即可搞定,MMR、DPP等则属于是牛刀。
混排
另一种重排为异质内容的混排,如在商品列表中插入广告、视频/图文内容、主题聚合等。比较强势的方式是定坑插入,如隔5个商品插入一个异质内容,各类型内容内部顺序不变;而定坑有时不是全局最优的排序方法,因此另一种则是完全混排方式,这时问题转化为多目标问题,就又可以借鉴上述参考LTR、多样性打散等思路进行方案设计。
流量调控
相比混排,流量调控可以看作是精确到单次pv的更细粒度重排策略,如常见的内容冷启动、新卖家冷启动、买卖家结构调控、曝光保量等问题都可以看作是流量调控维度的重排(当然,流量调控只是实现方式的一种)。而对于流量调控的常规方法详细的介绍后续会单开章节介绍,这里先不赘述。
小结
重排的流水账这里为止,事实上,很多时候以效率为目标的重排常是根据现实情况选择是否深挖,很多复杂的模型相信大多数场景并没必要一定进行尝试;反倒是更加简单的,如多样性、混排等特殊重排需求策略在搜索场景中不可或缺。