主要目标 —抽烟打电话(吃东西喝水) 睡觉 遗落 宠物,活体 —不好做 危险动作 成员属性(穿着 表情 配饰 年龄)婴儿座椅 安全带 哭闹 OMS数据构建 多轮对话QA 问题列表设计(第一版) prompt 中文 英文 以多轮对话的形式询问大模型来生成对应数据, 问题:占用token数量比较大,速度较慢 问题列表设计(第二版) 获取数据逻辑为: 模型生成—人工标注—模型生成, 三个阶段 第一阶段,可以用项目SDK或者已知的SOTA模型做一些检测和深度预测的工作 第二阶段, 基于模型生成的数据做人工修正和标注,这部分主要是构建分类性质的问题(比如常见物体的检测以及对应的属性和类别), 可以作为专家库信息,来辅助后面的模型生成准确的数据 第三阶段,基于已有的专家信息做辅助生成多轮QA数据,这里需...
Large Model
2025-04-17

模型概述 KimiVL 是一个高效的开源混合专家视觉语言模型(VLM),它提供先进的多模态推理、长上下文理解和强大的代理能力,同时在语言解码器中仅激活 2.8B 参数(KimiVLA3B)。该模型在多种挑战性任务中表现出色,包括一般用途的视觉语言理解、多轮代理任务、大学水平的图像和视频理解、OCR、数学推理和多图像理解等. 模型架构 KimiVL 的架构由三个主要部分组成: MoE语言模型 Moonlight MoE language model with only 2.8B activated (16B total) parameters 视觉模型 400M nativeresolution MoonViT vision encoder. MLP Projector MoonViT: 原生...
Large Model
2025-04-03

项目: 🔖 https://llavavl.github.io/ github: 一句话优点: 1、极大简化了VLM的训练方式:Pretraining + Instruction Tuning 2、训练量得到简化:1M量级数据+ 8卡A100 → 一天完成训练 LLaVA LLaVA是2023的连续工作,包含了LLaVA 1.0, 1.5, 1.6几个版本(后续会有更多),也是2023年多模态领域妥妥的顶流。发表9个月620的stars,GitHub超过12K的stars。 LLaVA它的网络结构简单、微调成本比较低,任何研究组、企业甚至个人都可以基于它构建自己的领域的多模态模型。 非常建议对多模态大模型感兴趣的朋友关注LLaVA这篇工作。 简介 LLaVA通过使用机器生成的指令遵循数据对大...
Large Model
2025-03-23
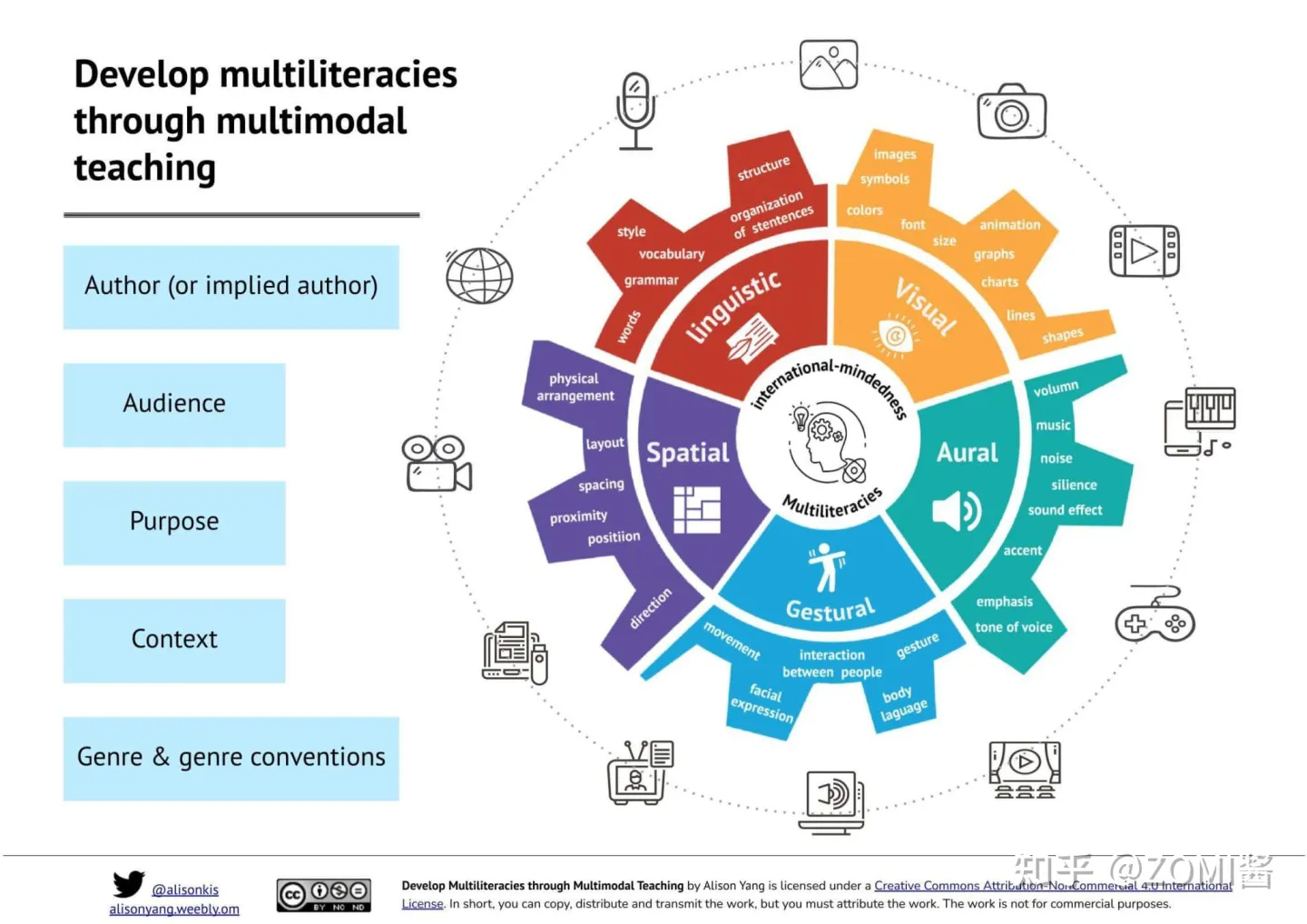
多模态 模态(modal)是事情经历和发生的方式,我们生活在一个由多种模态(Multimodal)信息构成的世界,包括视觉信息、听觉信息、文本信息、嗅觉信息等等,当研究的问题或者数据集包含多种这样的模态信息时我们称之为多模态问题,研究多模态问题是推动人工智能更好的了解和认知我们周围世界的关键。 通常主要研究模态包括"3V":即Verbal(文本)、Vocal(语音)、Visual(视觉)。 多模态发展历史 实际上,多模态学习不是近几年才火起来,而是近几年因为深度学习使得多模态效果进一步提升。下面梳理一下从1970年代起步,多模态技术经历的4个发展阶段,在2012后迎来 Deep Learning 阶段,在2016年后进入目前真正的多模态阶段。 第一阶段为基于行为的时代(1970s until...
Large Model
2025-03-23
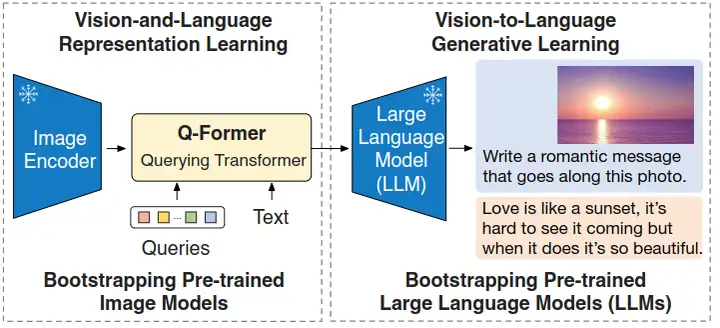
总结 BLIP2 是一种多模态 Transformer 模型,主要针对以往的视觉语言预训练 (VisionLanguage Pretraining, VLP) 模型端到端训练导致计算代价过高的问题。 所以,如果能够使用预训练好的视觉模型和语言模型,我把参数冻结,应该能够节约不少的计算代价。 BLIP2 就是这样,这个工作提出了一种借助现成的冻结参数的预训练视觉模型和大型语言模型的,高效的视觉语言预训练方法。 但是,简单的冻结预训练好的视觉模型的参数或者语言模型的参数会带来一个问题:就是视觉特征的空间和文本特征的空间,它不容易对齐。那么为了解决这个问题,BLIP2 提出了一个轻量级的 Querying Transformer,该 Transformer 分两个阶段进行预训练。第一阶段从冻结的视...
Large Model
2025-01-21
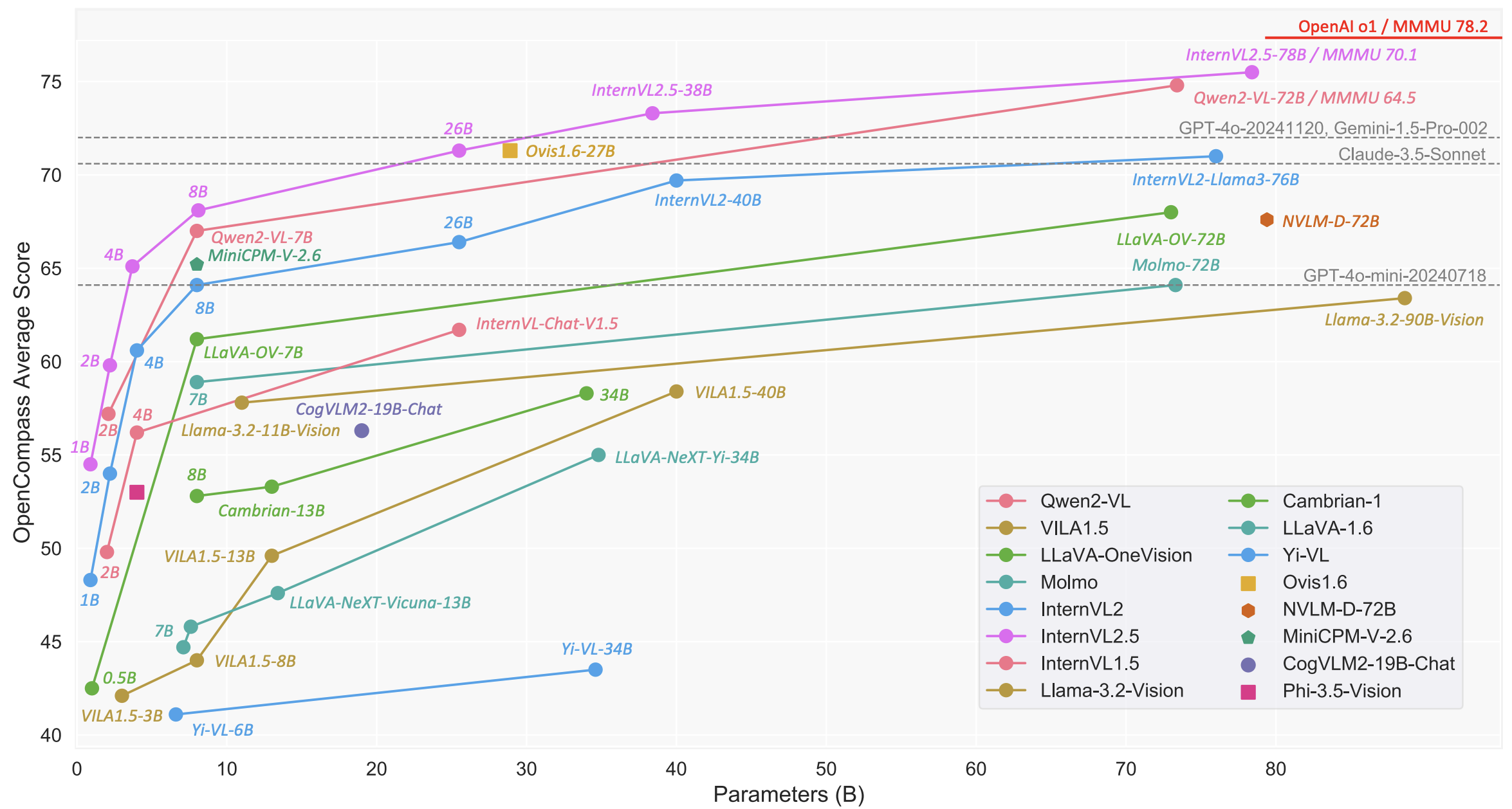
简介 🔖 https://internvl.github.io/blog/20241205InternVL2.5/ 上海人工智能实验室 推出的InternVL系列 在24年12月推出了InternVL2.5,模型整体上性能看起来不错。 模型结构 模型结构还是继承自InternVL1.5 没什么大的改动。 整个模型包含几个部分 较大的视觉encoder:InternViT300M/InternViT6B MLP projector LLM 训练策略 阶段训练 训练分为3个stage: Stage 1: MLP Warmup: 只训练MLP Projector,对齐语言和视觉特征。采用NTP Loss(Next Token Prediction Loss), 并采用了一个相对较大的学习率来加速模...
Large Model
2025-01-02

这是OpenCompass的offitial ranking 榜单 🔖 https://rank.opencompass.org.cn/home MMBench 鉴于现行评测方式所存在的问题,我们重新定义了一套针对当前多模态大模型的评测流程——MMBench。其主要包含两个方面: 自上而下的能力维度设计,根据定义的能力维度构造了一个评测数据集 引入 ChatGPT,以及提出了 CircularEval 的评测方式,使得评测的结果更加稳定 Paper 链接: 🔖 https://arxiv.org/pdf/2307.06281 github: 数据集 数据集构造 主要目的是对模型的各种能力进行全方位的考察,所以我们自上而下定义了三级能力维度 (L1L3), 第一级维度(L1)包含感知与推理两项...
Large Model
2025-01-02
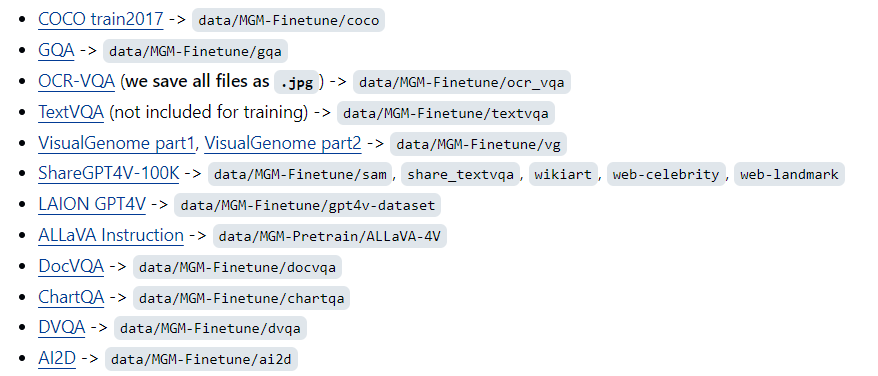
训练数据 Pretrain 558K Llava pretrain imagetext pair 695K ALLaVA dataset FineTuning Pretrain and Finetune 代码 参数 [代码] 首先使用transformers.HfArgumentParser类解析命令行参数,该类的作用是将命令行参数解析为dataclass对象。dataclass是Python3.7中引入的一个新特性,通过dataclass可以方便地定义一个类,并且可以自动实现__init__、__repr__等方法 [代码] 然后通过parser.parse_args_into_dataclasses()方法解析命令行参数,并将解析结果保存到model_args、data_args和tra...
Large Model
2025-01-02

简介 该工作建立了一个GCG(Grounded Conversation Generation )的数据集和对应多模态大模型,与之前的工作主要的区别在于针对输入图像,可以生成grounding pixellevel理解的语言对话,如下图示例所示: Model Automated Dataset Annotation Pipeline level 1: Object locatlization and attributes 1. Landmark Categorization 基于LLaVA模型对图像做场景的分类, 包含主要场景和细粒度场景。就是对数据集整体做一个大的类别标签和子类别标签,做场景的划分 [代码] 2. Depth Map Estimation 通过MiDaS v3.1 一个单目...