简介
🔖 https://internvl.github.io/blog/2024-12-05-InternVL-2.5/
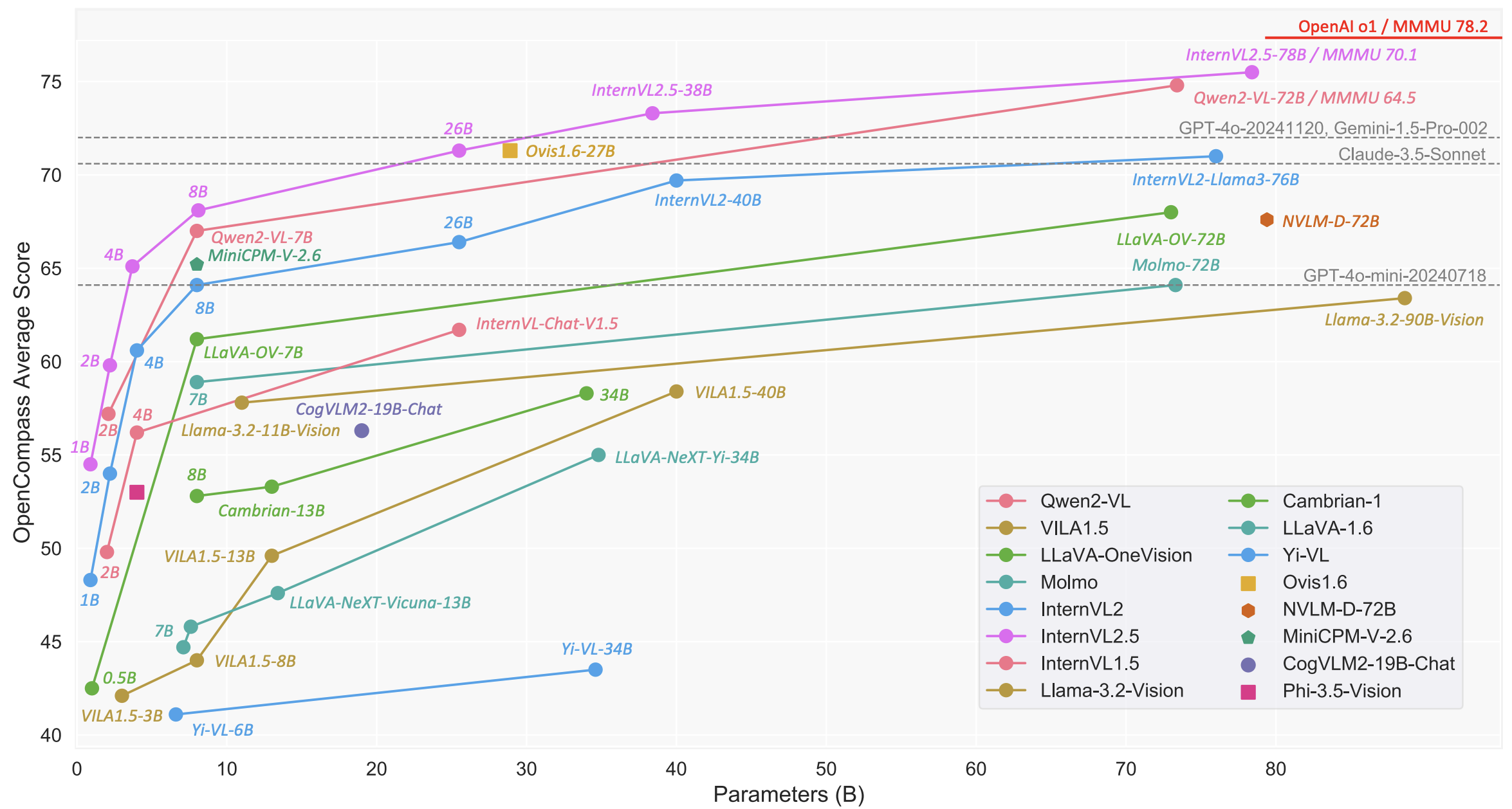
上海人工智能实验室 推出的InternVL系列 在24年12月推出了InternVL2.5,模型整体上性能看起来不错。
模型结构
模型结构还是继承自InternVL1.5 没什么大的改动。
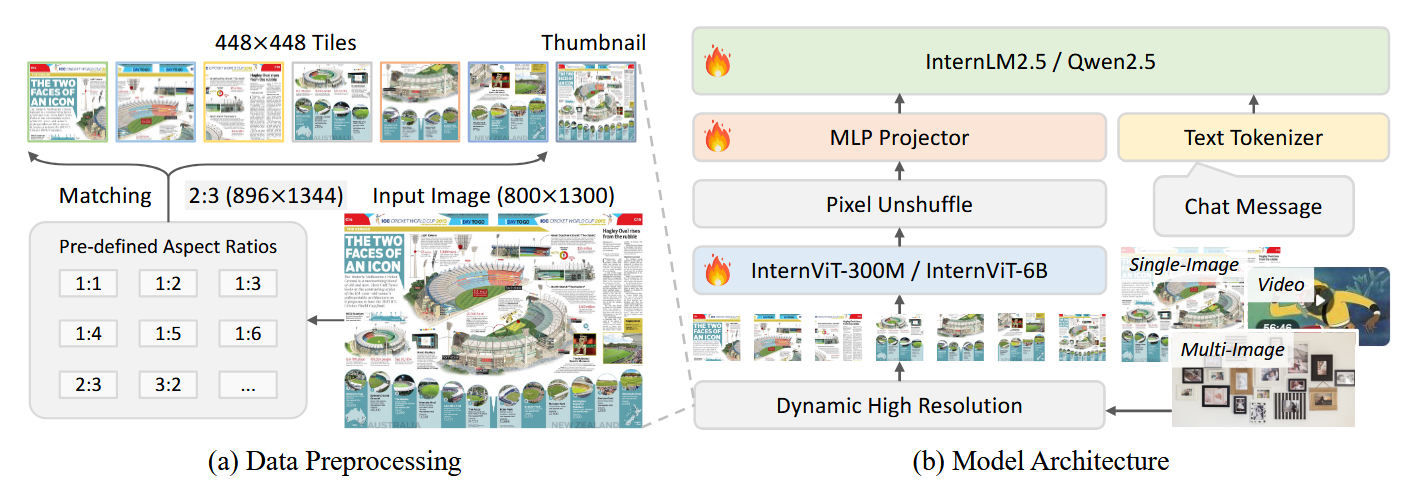
整个模型包含几个部分
- 较大的视觉encoder:InternViT-300M/InternViT-6B
- MLP projector
- LLM
训练策略
阶段训练
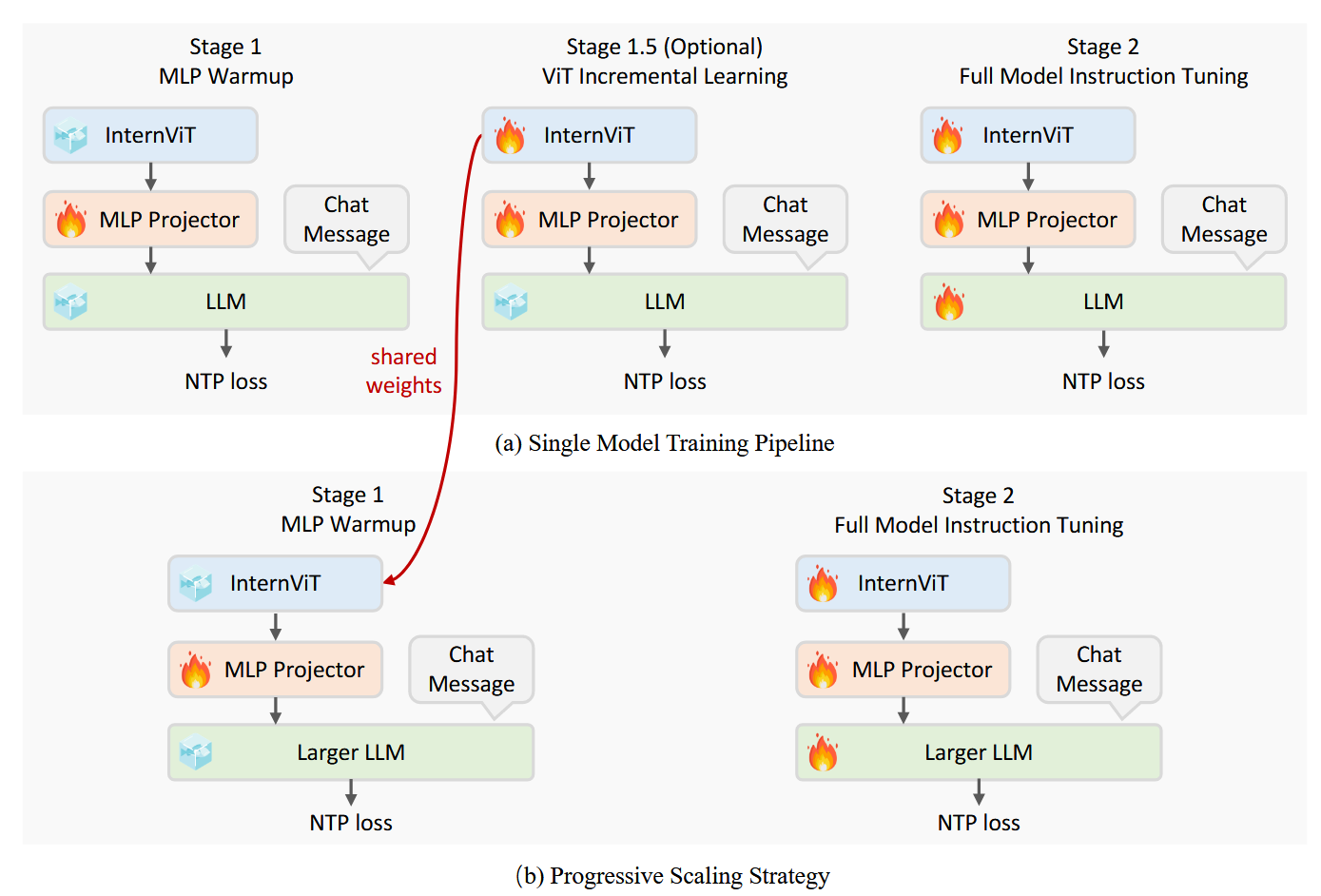
训练分为3个stage:
- Stage 1: MLP Warmup: 只训练MLP Projector,对齐语言和视觉特征。采用NTP Loss(Next Token Prediction Loss), 并采用了一个相对较大的学习率来加速模型对齐;
- Stage 1.5: ViT Incremental Learning (Optional):此阶段的目的是增强视觉编码器提取视觉特征的能力,使其能够捕获更全面的信息,特别是对于在 Web 规模数据中相对较少的领域,比如OCR和数学等,并使用较低的学习率以防止灾难性遗忘,确保编码器不会丢失以前学习的功能;
- Stage 2: Full Model Instruction Tuning:全参训练
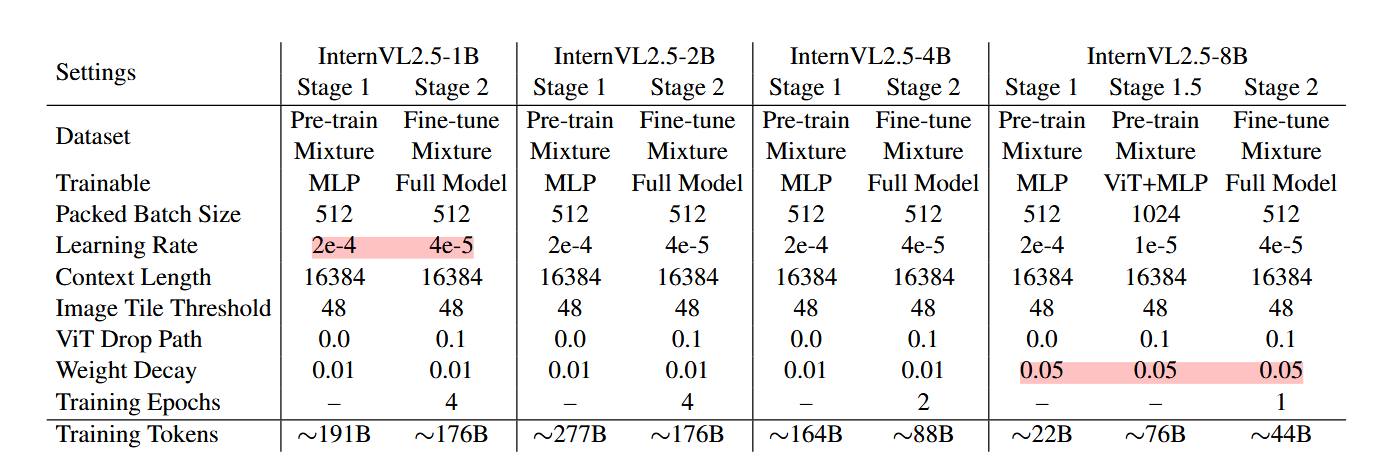
Progressive Scaling Strategy
如上面模型训练图 ,作者提出了一种渐进式缩放策略,以有效地将视觉编码器(例如 InternViT)与 LLM 对齐。之前在 InternVL 1.5 和 2.0 的训练中采用了类似的策略,但这次我们将该方法正式化为明确定义的方法。
该策略采用分阶段训练方法,从较小、资源高效的 LLM 开始,然后逐步扩展到更大的 LLM。这种方法源于我们的观察,即使 ViT 和 LLM 使用 NTP 损失进行联合训练,由此产生的视觉特征也是其他 LLM 可以轻松理解的可泛化表示。
具体来说,在阶段 1.5 中,InternViT 与较小的 LLM(例如 20B)一起训练,专注于优化基本视觉能力和跨模态对齐。此阶段避免了与直接使用大型 LLM 进行训练相关的高计算成本。使用共享权重机制,经过训练的 InternViT 可以很容易地转移到更大的 LLM(例如 72B),而无需重新训练。因此,在训练更大的模型时,可以跳过阶段 1.5(见表 3),因为早期阶段优化的 InternViT 模块被重用。这不仅加快了训练速度,还确保了视觉编码器的学习表示得到保留并有效地集成到更大的模型中。 通过采用这种渐进式扩展策略,我们实现了可扩展的模型更新,而成本通常只是大规模 MLLM 训练成本的一小部分。例如,Qwen2-VL [246] 累计处理 1.4 万亿个代币,而 InternVL2.5-78B 仅接受约 1200 亿个代币的训练,不到 Qwen2-VL 的十分之一。这种方法在资源受限的环境中被证明特别有利,因为它可以最大限度地重用预先训练的组件,最大限度地减少冗余计算,并能够有效地训练能够解决复杂视觉语言任务的模型。
Training Enhancements
这里主要是采用了两个特别的data augmentation
- Random JPEG Compression.为了避免在训练过程中过度拟合并提高模型的实际性能,我们应用了一种保留空间信息的数据增强技术:JPEG 压缩。具体来说,应用质量级别在 75 到 100 之间的随机 JPEG 压缩来模拟 Internet 来源图像中常见的退化。这种增强提高了模型对噪点、压缩图像的鲁棒性,并通过确保在各种图像质量下实现更一致的性能来增强用户体验。
- Loss Reweighting. Token Averaging 和 Sample Averaging 是两种广泛应用的 NTP 损失加权策略。Token Averaging计算所有token的平均 NTP 损失,这可能导致梯度偏向于具有更多token的response; 而 Sample Averaging 首先在样本内部平均,这样可以防止长序列样本在整体损失中占据过大权重, 再对所有样本求平均, 但是会使得模型偏向于选择更短的response。这些策略可以用统一的格式表示:
数据
Multimodal Data Packing
为了提高训练效率,减少padding数量, 作者将训练数据重新整合,整合策略可以氛围四个阶段:
- 选择阶段 (Select)
- 搜索阶段 (Search)
- 打包阶段 (Pack)
- 维护阶段 (Maintain)
Data Filtering Pipeline
作者认为,虽然传统观点认为大规模数据集中的微小噪声可以忽略不计,但研究结果表明并非如此:即使是极小一部分噪声样本也会降低 MLLM 的性能和用户体验。所以作者构建了一系列的过滤和清洗数据的pipeline,具体来说
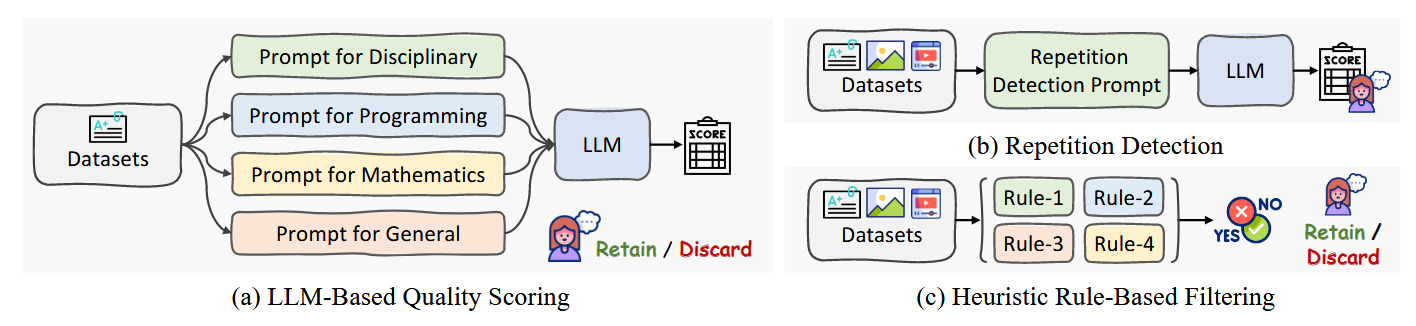
- Pure Text data: 对于纯文本数据,作者设计了三种过滤方式
- multimodal data:多模态也用了类似的策略,具体来说:
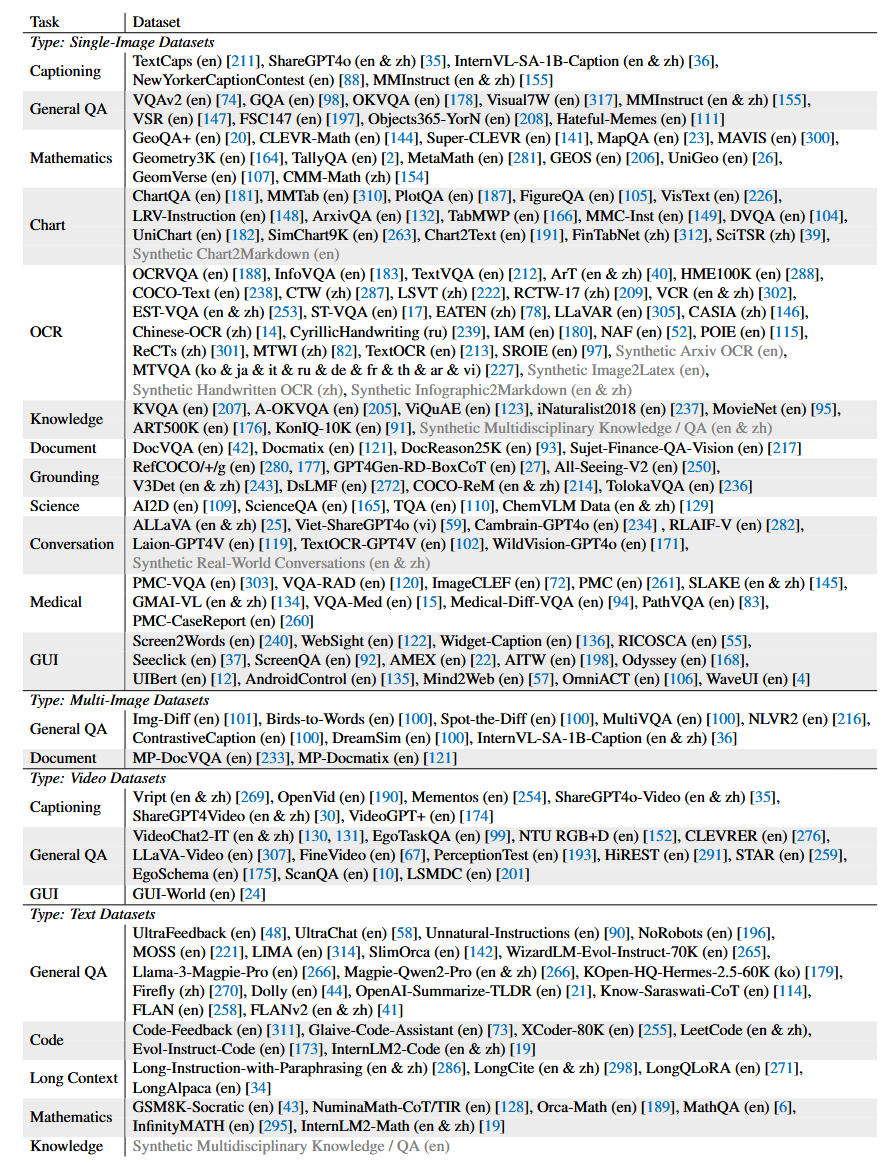
Pre-training Data Mixture
数据集类别包含:
- captioning
- general QA
- mathematics
- charts
- OCR
- knowledge
- grounding
- documents
- conversation
- medical
- GUI tasks

Fine-tuning Data Mixture
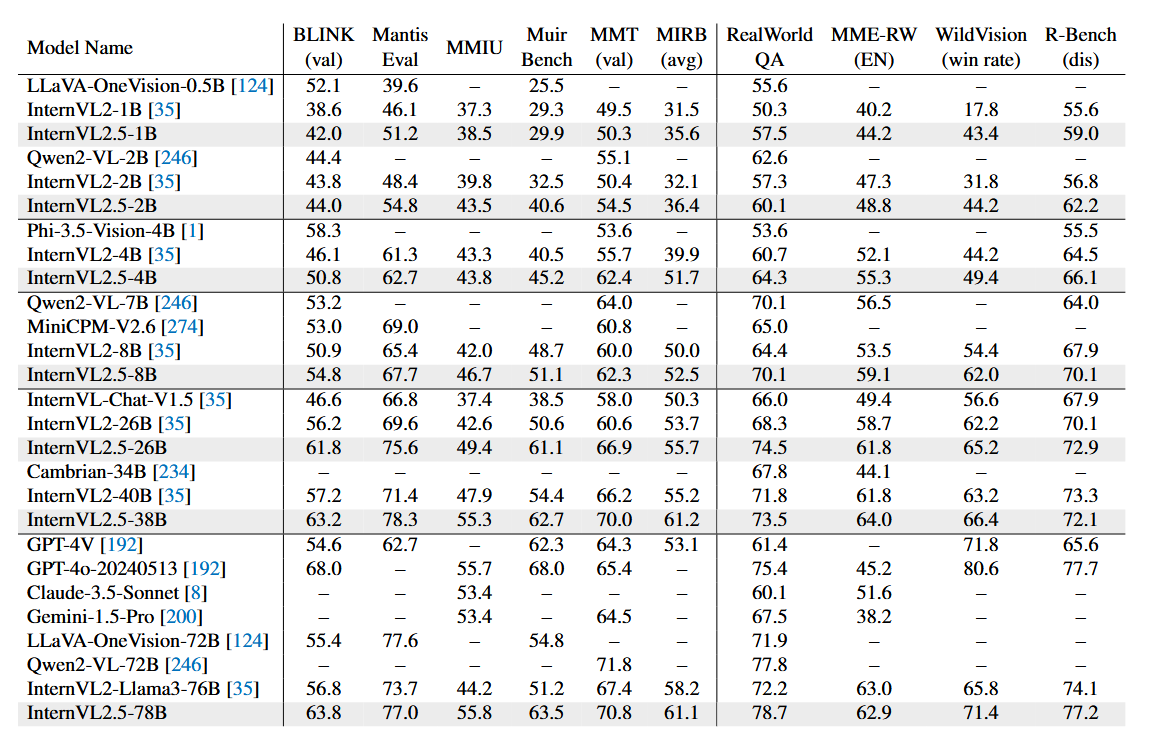
主要性能
multimodal reasoning and mathematical performance
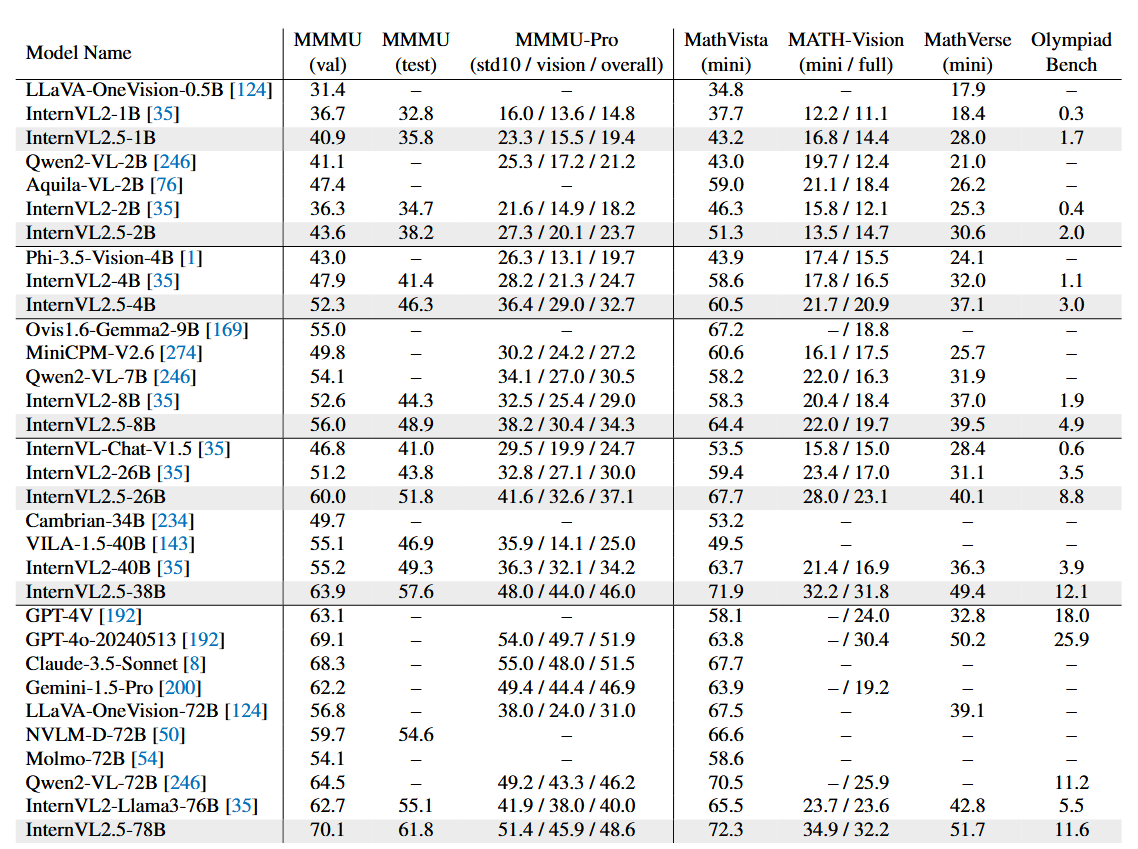
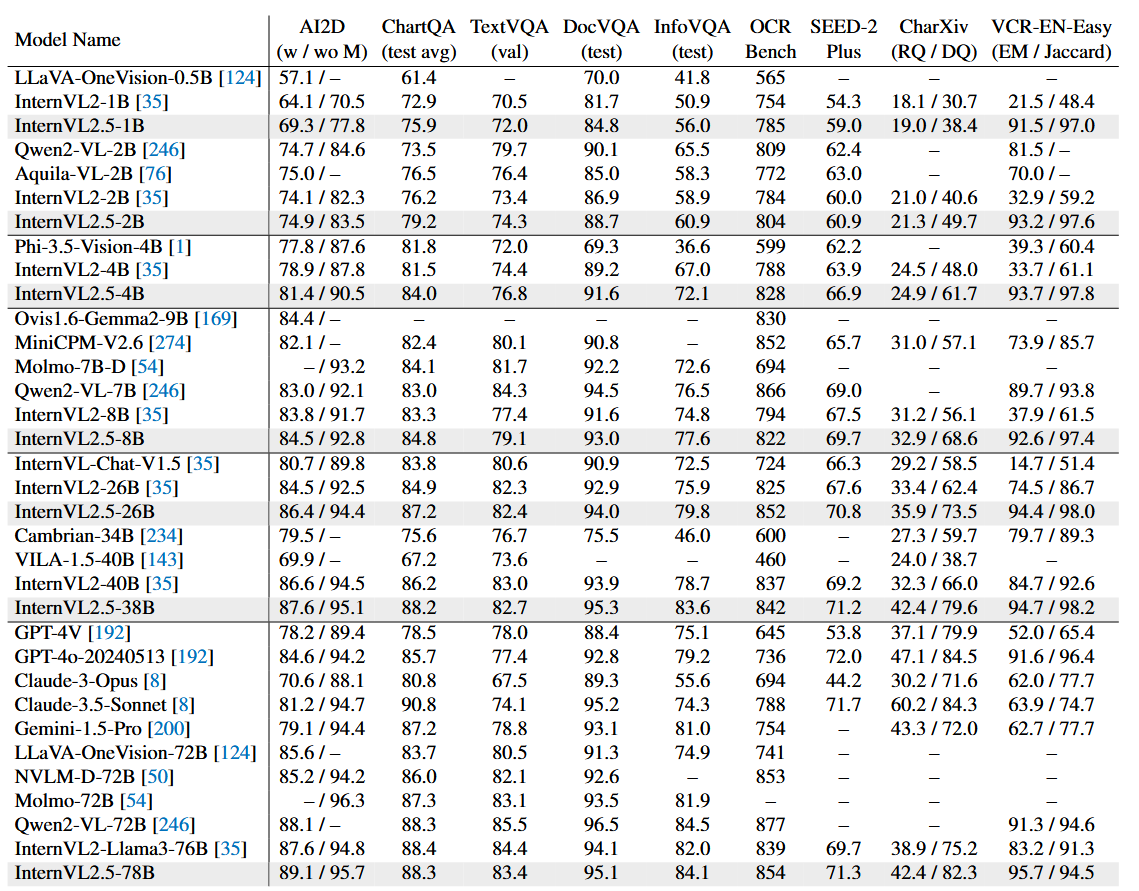
OCR, chart, and document understanding performance
real-world understanding performance