简介
"Anchor-free"(无锚点)是一种目标检测方法,与传统的使用锚框(anchor boxes)的方法(例如Faster R-CNN)不同。在传统方法中,锚框是预先定义的、具有不同尺寸和长宽比的矩形区域,用于捕捉不同尺寸和形状的目标。而在"anchor-free"方法中,不再使用锚框,而是直接预测目标的位置和形状,通常使用网络输出的热图和偏移信息。
以下是对"anchor-free"方法的一些关键理解点:
无需预定义锚框: 在传统目标检测方法中,需要事先定义和生成一组锚框,这可能需要大量的人工工作。而在"anchor-free"方法中,不再需要锚框,模型可以自动学习目标的位置和形状。
直接位置和形状回归: "anchor-free"方法通过输出的热图来表示目标的存在概率,并使用偏移信息来定位目标的中心和形状。这些热图和偏移信息通常通过卷积神经网络预测。
适用于不规则目标: 传统的锚框在捕捉不规则形状的目标时可能会有困难,而"anchor-free"方法可以更好地适应不规则目标的检测。
减少计算复杂性: 由于不需要生成大量锚框,"anchor-free"方法可能减少了计算复杂性,这对于实时目标检测任务很有帮助。
端到端训练: 通常,"anchor-free"方法可以实现端到端训练,模型可以直接从原始数据中学习目标检测任务,而不需要额外的处理。
一些常见的"anchor-free"目标检测方法包括CenterNet、CornerNet和Center-KeypointNet等。这些方法在不同的场景和应用中都取得了很好的效果,特别是在需要高效目标检测的任务中。但需要注意,每种方法的性能和适用性会根据具体情况有所不同,因此在选择目标检测方法时需要考虑任务的要求。
另一方面,基于锚框的方法涉及生成一组预定义的锚框(例如R-CNN中的RPN或SSD中的prior box),并根据这些锚框与真实框之间的差异进行位置回归。
引入锚框的方法具有以下优点:
- 它显著减少了计算复杂性,并将提案的数量控制在可管理的范围内,以便进行后续的计算和筛选。
- 通过调整不同的锚框设置,可以覆盖尽可能多的物体,并为不同的任务设置不同的锚框尺度范围。
- 由于锚框的尺度是人工定义的,物体的定位是通过锚框的回归来实现的,仅计算偏移量而不是精确位置,大大降低了优化的难度。
然而,基于锚框的方法也有一些局限性:
- 许多在Faster R-CNN之后发表的论文表明,通过使用更多不同尺寸和长宽比的锚框以及采用各种训练技巧,可以获得更好的结果。然而,通过增加计算能力来改进网络的方法往往难以在实际应用中实施(模型速度和大小)。
- 锚框的设置需要手动调整大量参数,并且离散的锚框尺度设置可能导致某些物体无法与任何锚框匹配,导致遗漏检测。
相比之下,基于锚框的方法需要生成一组预定义的锚框,并通过锚框与真实框之间的差异进行位置回归。基于锚框的方法可以显著减少计算复杂性,并调整锚框设置以适应不同尺度的物体。然而,基于锚框的方法需要手动调整参数,并且可能遗漏检测某些物体。
以下是一些"anchor-free"目标检测方法的简介:
- DenseBox: 使用单个FCN进行目标检测,通过多任务引入landmark localization来提升性能。
- CornerNet: 基于关键点的目标检测方法,通过预测物体的角点来实现检测。
- CenterNet: 基于物体中心点的目标检测方法,通过预测物体的中心点来实现检测。
- FCOS: 一种自适应正负anchor选择的目标检测方法。
- ATSS: 另一种自适应正负anchor选择的目标检测方法。
每种方法在不同场景和应用中取得了良好的效果,但具体选择哪种方法需要根据任务需求进行考虑。
请注意,以上内容仅为简要介绍,具体细节和性能可能因具体方法和实验设置而有所不同。更多详细信息可以参考各个方法的论文和相关资料。
Anchor-free工作
DenseBox
两点贡献:
- 证明单个FCN可以检测出遮挡严重、不同尺度的目标。
- 通过多任务引入landmark localization,能进一步提升性能。
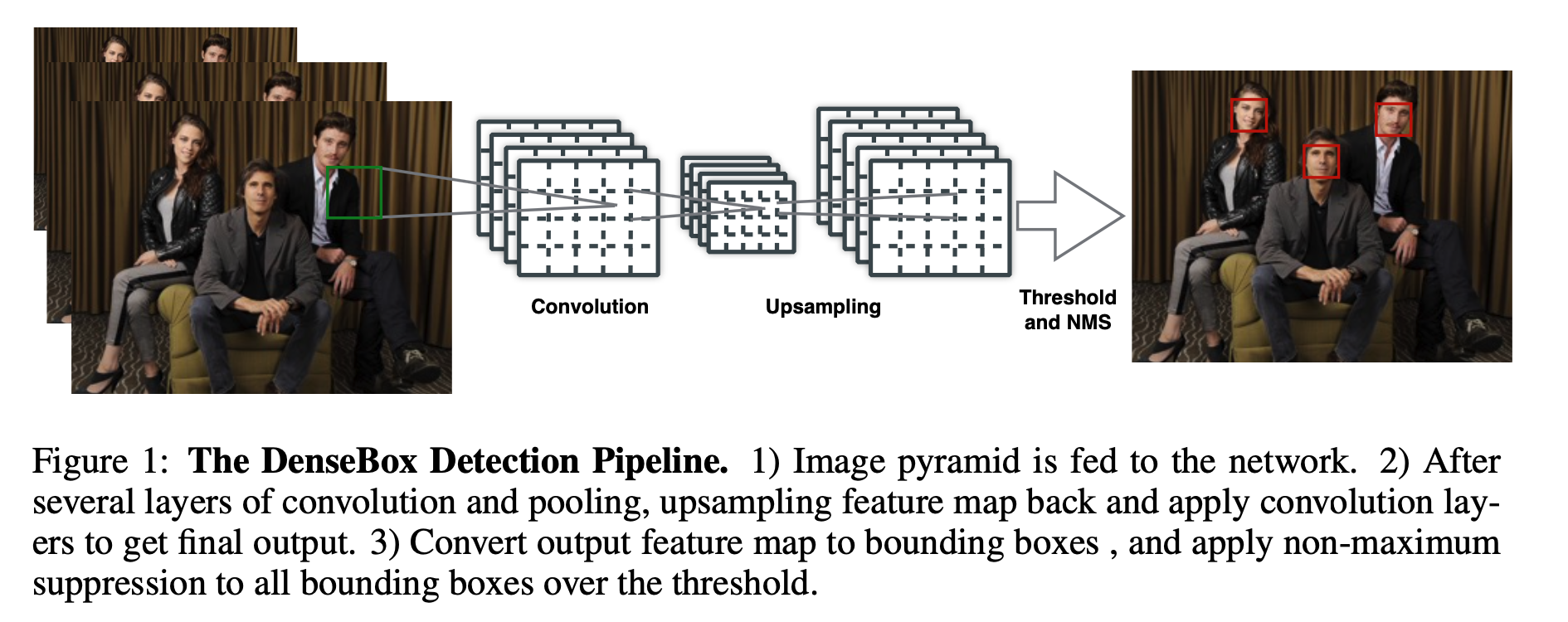
如图1所示,单个FCN同时产生多个预测bbox和置信分数的输出。测试时,整个系统将图片作为输入,输出5个通道的feature map。每个pixel的输出feature map得到5维的向量,包括一个置信分数和bbox边界到该pixel距离的4个值。最后输出feature map的每个pixel转化为带分数的bbox,然后经过NMS后处理。
Ground Truth Generation

如果直接使用整幅图片进行训练的话,会在反向传播时浪费大量时间,于是使用了一种策略,对输入图片进行裁剪包含人脸和丰富背景的patches(目标检测的数据增强),在训练阶段,这些patches被裁剪后resize到240x240,其中人脸区域大约50像素。因此最后的输出为60x60且5通道的张量,因此Ground Truth在构建时,也得是60x60x5的张量,其人脸区域由一个以人脸bounding box的中心为圆心且半径为0.3倍(paper setting)的bounding box size的圆形区域确定,这个东西与segmentation类似。现在看来思想很超前!
在GT的第一个通道,我们用0来进行初始化,如果包含在正样本区域,那么就设置为1。其他的4个通道由该像素点与box的左上角和右下角的距离来确定。对于多张人脸,如果他们落在patch center的一定范围内,那么这些人脸就是正样本,其余的均为负样本。
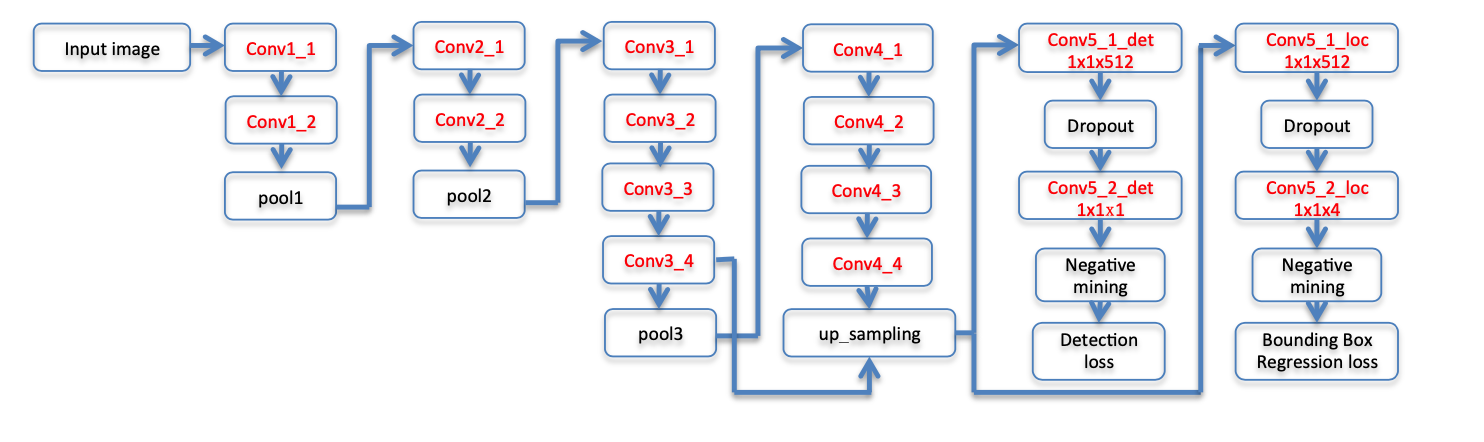
模型结构
使用了VGG19,由于进行了上采样,所以总体图像尺寸降了4倍!
Keypoint-based
CenterNet
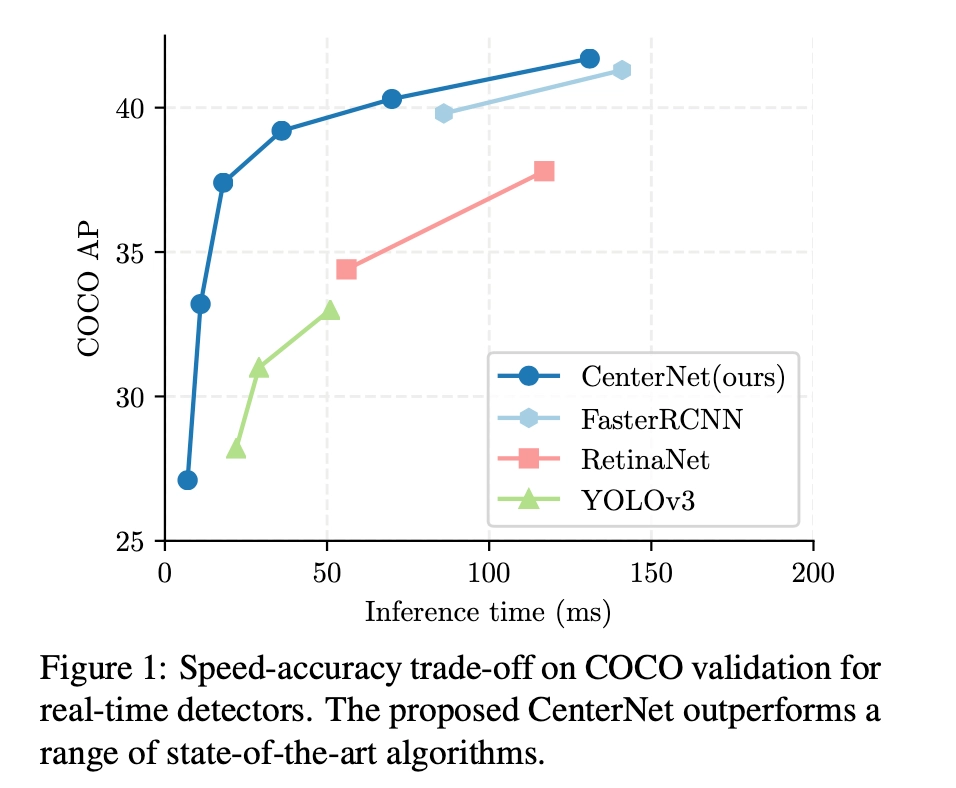
anchor-free目标检测属于anchor-free系列的目标检测,相比于CornerNet做出了改进,使得检测速度和精度相比于one-stage和two-stage的框架都有不小的提高,尤其是与YOLOv3作比较,在相同速度的条件下,CenterNet的精度比YOLOv3提高了4个左右的点。
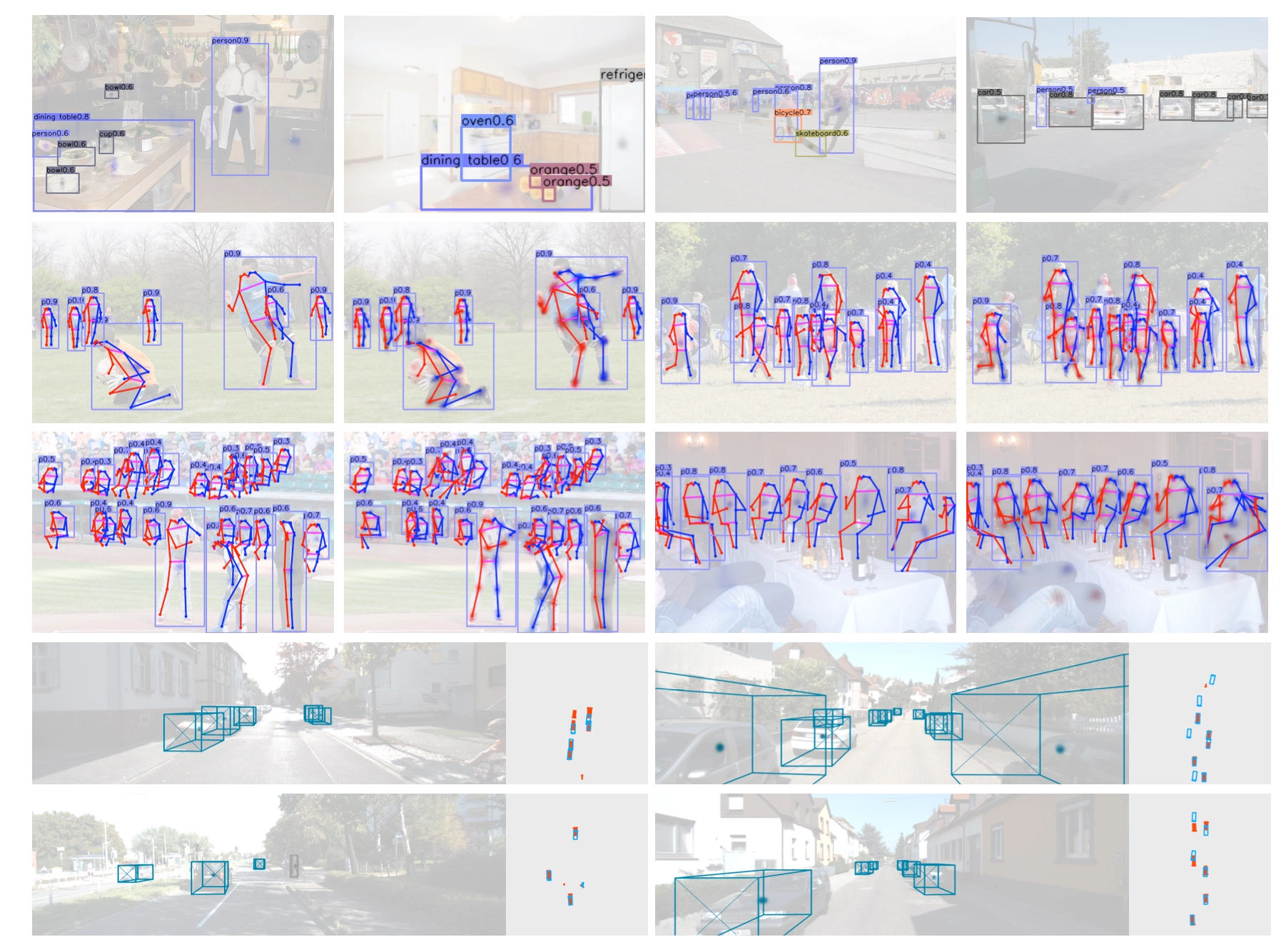
CenterNet不仅可以用于目标检测,还可以用于其他的一些任务,如肢体识别或者3D目标检测等等。
那CenterNet相比于之前的one-stage和two-stage的目标检测有什么特点?
- CenterNet的“anchor”仅仅会出现在当前目标的位置处而不是整张图上撒,所以也没有所谓的box overlap大于多少多少的算positive anchor这一说,也不需要区分这个anchor是物体还是背景 - 因为每个目标只对应一个“anchor”,这个anchor是从heatmap中提取出来的,所以不需要NMS再进行来筛选
- CenterNet的输出分辨率的下采样因子是4,比起其他的目标检测框架算是比较小的(Mask-Rcnn最小为16、SSD为最小为16)。
总体来说,CenterNet结构优雅简单,直接检测目标的中心点和大小,是真anchor-free。
PS:其实本篇所说的CenterNet的真实论文名称叫做 objects as points,因为也有一篇叫做CenterNet: Keypoint Triplets for Object Detection 的论文与这篇文章的网络名称冲突了,所以以下所说的CenterNet是指 objects as points。
网络结构与前提条件
接下来说一下正式进入篇章之前的一些前提知识。
论文中CenterNet提到了三种用于目标检测的网络,这三种网络都是编码解码(encoder-decoder)的结构:
- Resnet-18 with up-convolutional layers : 28.1% coco and 142 FPS
- DLA-34 : 37.4% COCOAP and 52 FPS
- Hourglass-104 : 45.1% COCOAP and 1.4 FPS
每个网络内部的结构不同,但是在模型的最后都是加了三个网络构造来输出预测值,默认是80个类、2个预测的中心点坐标、2个中心点的偏置。
用官方的源码(使用Pytorch)来表示一下最后三层,其中hm为heatmap、wh为对应中心点的width和height、reg为偏置量,这些值在后文中会有讲述。
(hm): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 80, kernel_size=(1, 1), stride=(1, 1))
)
(wh): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 2, kernel_size=(1, 1), stride=(1, 1))
)
(reg): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace)
(2): Conv2d(64, 2, kernel_size=(1, 1), stride=(1, 1))
)前提条件
附一张检测的效果图:

我们该如何检测呢?
首先假设输入图像为\(I\in R^{W\times H\times 3}\),其中 \(W\) 和 \(H\) 分别为图像的宽和高,然后在预测的时候,我们要产生出关键点的热点图(keypoint heatmap):\(\hat{Y}\in [0,1]^{\frac{W}{R}\times \frac{H}{R}\times C}\),其中\(R\) 为输出对应原图的步长,而\(C\)是在目标检测中对应着类别数,如在COCO目标检测任务中,这个\(C\)的值为80,代表当前有80个类别。
插一段官方代码,其中\(R\)就是self.opt.down_ratio也就是4,代表下采样的因子。
# 其中input_h和input_w为512,而self.opt.down_ratio为4,最终的output_h为128
# self.opt.down_ratio就是上述的R即输出对应原图的步长
output_h = input_h // self.opt.down_ratio
output_w = input_w // self.opt.down_ratio这样,\(\hat{Y}_{x,y,c}=1\)就是一个检测到物体的预测值,对于\(\hat{Y}_{x,y,c}=1\),表示对于类别\(c\),在当前\((x,y)\)坐标中检测到了这种类别的物体,而\(\hat{Y}_{x,y,c}=0\)则表示当前当前这个坐标点不存在类别为\(c\)的物体。在整个训练的流程中,CenterNet学习了CornerNet的方法。对于每个标签图(ground truth)中的某一
\(C\)类,我们要将真实关键点(true keypoint)\(p\in R^2\) 计算出来用于训练。对于下采样后的坐标,我们设为
其中\(R\) 是上文中提到的下采样因子4。所以我们最终计算出来的中心点是对应低分辨率的中心点。
然后我们利用 \(Y\in [0,1]^{\frac{W}{R}\times\frac{H}{R}\times C}\) 来对图像进行标记,在下采样的[128,128]图像中将ground truth point以 \(Y\in [0,1]^{\frac{W}{R}\times\frac{H}{R}\times C}\)的形式,用一个高斯核
来将关键点分布到特征图上,其中 \(\sigma_p\)是一个与目标大小(也就是w和h)相关的标准差。如果某一个类的两个高斯分布发生了重叠,直接取元素间最大的就可以。
这么说可能不是很好理解,那么直接看一个官方源码中生成的一个高斯分布[9,9]:

每个点\(Y\in [0,1]^{\frac{W}{R}\times\frac{H}{R}\times C}\) 的范围是0-1,而1则代表这个目标的中心点,也就是我们要预测要学习的点。
损失函数
重点看一下中心点预测的损失函数
其中 \(\alpha\) 和 \(\beta\) 是Focal Loss的超参数, \(N\) 是图像 \(I\) 的的关键点数量,用于将所有的positive focal loss标准化为1。在这篇论文中 \(\alpha\) 和 \(\beta\) 分别是2和4。这个损失函数是Focal Loss的修改版,适用于CenterNet。
这个损失也比较关键,需要重点说一下。和Focal Loss类似,对于easy example的中心点,适当减少其训练比重也就是loss值,当 \(Y_{xyc}=1\) 的时候, \((1-\hat{Y}_{xyc})^\alpha\) 就充当了矫正的作用,假如 \(\hat{Y}_{xyc}\)接近1 的话,说明这个是一个比较容易检测出来的点,那么 \((1-\hat{Y}_{xyc})^\alpha\) 就相应比较低了。而当 \(\hat{Y}_{xyc}\)接近0的时候,说明这个中心点还没有学习到,所以要加大其训练的比重,因此 \((1-\hat{Y}_{xyc})^\alpha\) 就会很大, \(\alpha\) 是超参数,这里取2。
再说下另一种情况,当 \(otherwise\) 的时候,这里对实际中心点的其他近邻点的训练比重(loss)也进行了调整,首先可以看到 \((\hat{Y}_{xyc})^\alpha\),因为当 \(otherwise\) 的时候 \((\hat{Y}_{xyc})^\alpha\) 的预测值理应是0,如果不为0的且越来越接近1的话,\((\hat{Y}_{xyc})^\alpha\) 的值就会变大从而使这个损失的训练比重也加大;而 \((1-Y_{xyc})^\beta\) 则对中心点周围的,和中心点靠得越近的点也做出了调整(因为与实际中心点靠的越近的点可能会影响干扰到实际中心点,造成误检测),因为 \(Y_{xyc}\) 在上文中已经提到,是一个高斯核生成的中心点,在中心点 \(Y_{xyc}=1\),但是在中心点周围扩散 \(Y_{xyc}\) 会由1慢慢变小但是并不是直接为0,类似于上图,因此 \((1-Y_{xyc})^\beta\),与中心点距离越近,\(Y_{xyc}\) 越接近1,这个值越小,相反则越大。那么 \((1-Y_{xyc})^\beta\) 和 \((1-\hat{Y}_{xyc})^\alpha\)是怎么协同工作的呢?
简单分为几种情况:
- 对于距离实际中心点近的点,\(Y_{xyc}\) 值接近于1 ,例如 \(Y_{xyc}=0.9\) ,但是预测出来这个点的值,\(\hat{Y}_{xyc}\) 比较接近1,这个显然是不对的,它应该检测到为0,因此用 \((\hat{Y}_{xyc})^\alpha\)惩罚一下,使其LOSS比重加大些;但是因为这个检测到的点距离实际的中心点很近了,检测到的 \(\hat{Y}_{xyc}\) 接近1也情有可原,那么我们就同情一下,用 \((1-Y_{xyc})^\beta\) 来安慰下,使其LOSS比重减少些。
- 对于距离实际中心点远的点,\(Y_{xyc}\) 值接近0,例如\(Y_{xyc}=0.1\) ,如果预测出来这个点的值 \(\hat{Y}_{xyc}\) 比较接近1,肯定不对,需要用 \((\hat{Y}_{xyc})^\alpha\) 惩罚(原理同上),如果预测出来的接近0,那么差不多了,拿 \((\hat{Y}_{xyc})^\alpha\) 来安慰下,使其损失比重小一点;至于 \((1-Y_{xyc})^\beta\) 的话,因为此时预测距离中心点较远的点,所以这一项使距离中心点越远的点的损失比重占的越大,而越近的点损失比重则越小,这相当于弱化了实际中心点周围的其他负样本的损失比重,相当于处理正负样本的不平衡了。
- 如果结合上面两种情况,那就是:\((1-\hat{Y}_{xyc})^\alpha\) 和 \((\hat{Y}_{xyc})^\alpha\) 来限制easy example导致的gradient被easy example dominant的问题,而 \((1-Y_{xyc})^\beta\) 则用来处理正负样本的不平衡问题(因为每一个物体只有一个实际中心点,其余的都是负样本,但是负样本相较于一个中心点显得有很多)。
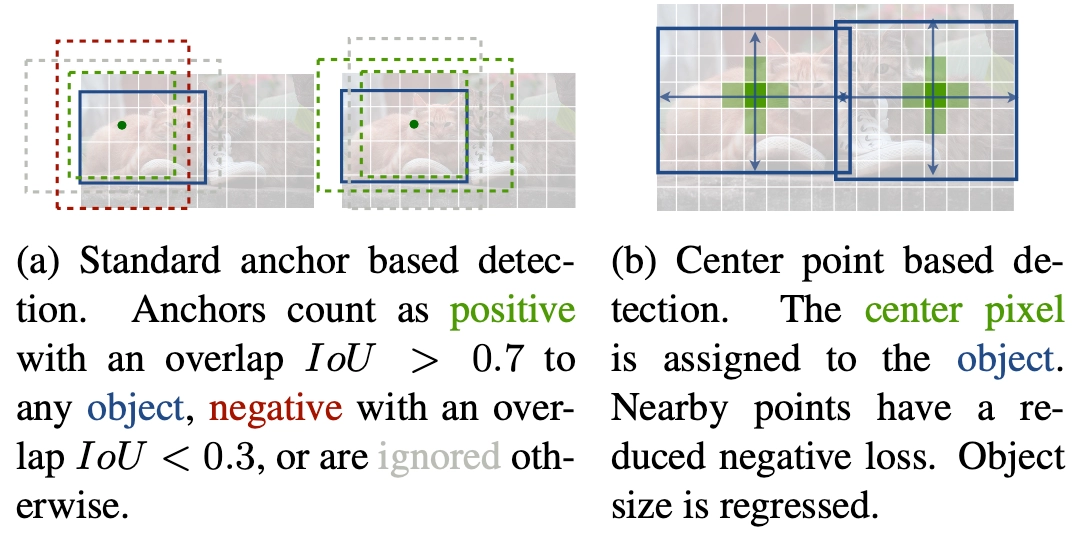
另外看一下官方的这张图可能有助于理解:传统的基于anchor的检测方法,通常选择与标记框IoU大于0.7的作为positive,相反,IoU小于0.3的则标记为negative,如下图a。这样设定好box之后,在训练过程中使positive和negative的box比例为1:3来减少negative box的比例(例如SSD没有使用focal loss)。
而在CenterNet中,每个中心点对应一个目标的位置,不需要进行overlap的判断。那么怎么去减少negative center pointer的比例呢?CenterNet是采用Focal Loss的思想,在实际训练中,中心点的周围其他点(negative center pointer)的损失则是经过衰减后的损失(上文提到的),而目标的长和宽是经过对应当前中心点的w和h回归得到的:
目标中心的偏置损失
因为上文中对图像进行了\(R=4\) 的下采样,这样的特征图重新映射到原始图像上的时候会带来精度误差,因此对于每一个中心点,额外采用了一个 local offset:\(\hat{O}\in\mathcal{R}^{\frac{W}{R}\times\frac{H}{R}\times 2}\)去补偿它。所有类\(c\)
的中心点共享同一个 offset,这个偏置值(offset)用 L1 loss 来训练:
上述公式直接看可能不是特别容易懂,其实\(\frac{p}{R}\)是原始图像经过下采样得到的,对于[512,512]的图像如果\(R=4\)的话那么下采样后就是[128,128]的图像,下采样之后对标签图像用高斯分布来在图像上撒热点,怎么撒呢?首先将box坐标也转化为与[128,128]大小图像匹配的形式,但是因为我们原始的annotation是浮点数的形式(COCO数据集),使用转化后的box计算出来的中心点也是浮点型的,假设计算出来的中心点是[98.97667,2.3566666]。
但是在推断过程中,我们首先读入图像[640,320],然后变形成[512,512],然后下采样4倍成[128,128]。最终预测使用的图像大小是[128,128],而每个预测出来的热点中心(headmap center),假设我们预测出与实际标记的中心点[98.97667,2.3566666]对应的点是[98,2],坐标是\((x,y)\),对应的类别是\(c\),等同于这个点上\(\hat{Y}_{xyc}=1\),有物体存在,但是我们标记出的点是[98,2],直接映射为[512,512]的形式肯定会有精度损失,为了解决这个就引入了\(L_{off}\) 偏置损失。
式子中 \(\hat{O}_{\widetilde{p}}\) 是我们预测出来的偏置,而 \((\frac{p}{R}-\widetilde{p})\) 则是在训练过程中提前计算出来的数值,在官方代码中为:
# ct 即 center point reg是偏置回归数组,存放每个中心店的偏置值 k是当前图中第k个目标
reg[k] = ct - ct_int
# 实际例子为
# [98.97667 2.3566666] - [98 2] = [0.97667, 0.3566666]reg[k]之后与预测出来的reg一并放入损失函数中进行计算。注意上述仅仅是对某一个关键点位置\(\widetilde{p}\) 来计算的,计算当前这个点的损失值的时候其余点都是被忽略掉的。
到了这里我们可以发现,这个偏置损失是可选的,我们不使用它也可以,只不过精度会下降一些。
目标大小的损失
我们假设\((x_1^{(k)},y_1^{(k)},x_2^{(k)},y_2^{(k)})\) 为目标 \(k\),所属类别为\(c_k\),它的中心点为
我们使用关键点预测\(\hat{Y}\) 去预测所有的中心点。然后对每个目标\(k\) 的 size 进行回归,最终回归到
这个值是在训练前提前计算出来的,是进行了下采样之后的长宽值。为了减少回归的难度,这里使用\(\hat{S}\in\mathcal{R}^{\frac{W^{'}}{R}\times\frac{H^{'}}{R}\times 2}\) 作为预测值,使用L1损失函数,与之前的\(L_{off}\) 损失一样:
整体的损失函数为物体损失、大小损失与偏置损失的和,每个损失都有相应的权重。
在论文中\(\lambda_{size}=0.1\),然后\(\lambda_{off}=1\),论文中所使用的backbone都有三个head layer,分别产生[1,80,128,128]、[1,2,128,128]、[1,2,128,128],也就是每个坐标点产生\(C+4\)个数据,分别是类别以及、长宽、以及偏置。
推断阶段
在预测阶段,首先针对一张图像进行下采样,随后对下采样后的图像进行预测,对于每个类在下采样的特征图中预测中心点,然后将输出图中的每个类的热点单独地提取出来。具体怎么提取呢?就是检测当前热点的值是否比周围的八个近邻点(八方位)都大(或者等于),然后取100个这样的点,采用的方式是一个3x3的MaxPool,类似于anchor-based检测中nms的效果。
这里假设\(\hat{p}_c\) 为检测到的点,
代表 \(c\) 类中检测到的一个点。每个关键点的位置用整型坐标表示 \((x_i,y_i)\) ,然后使用 \(\hat{Y}_{x_iy_ic}\) 表示当前点的confidence,随后使用坐标来产生标定框:
其中\((δ\hat{x}_i,δ\hat{y}_i) = \hat{O}_{\hat{x}_i,\hat{y}_i}\) 是当前点对应原始图像的偏置点,\((\hat{w}_i,\hat{h}_i)=\hat{S}\hat{x}_i,\hat{y}_i\) 代表预测出来当前点对应目标的长宽。
下图展示网络模型预测出来的中心点、中心点偏置以及该点对应目标的长宽:

那最终是怎么选择的,最终是根据模型预测出来的 \(\hat{Y}\) 值,也就是当前中心点存在物体的概率值,代码中设置的阈值为0.3,也就是从上面选出的100个结果中调出大于该阈值的中心点作为最终的结果。
gt设计
gt的编码基本与模型输出基本一致,就是将中心点坐标、检测框长宽、检测框坐标补偿均生成二维图像。但是里面有一些小细节,需要解释一下。
- ground truth的维度
gt的维度大小不等于输入图像,而是等于输入图像除以下采样因子,也就是说,如果输入图像维度为640480,下采样因子为4,中心点坐标为(123,123),那么gt的维度即为160120,中心点坐标为(30,30),补偿值为(123-(30*4))/4=0.75。
- 中心点heatmap的设计
我们应该如何设计中心点的heatmap?我们能想到的最平凡的方法就是生成一个二维矩阵,除了关键点坐标位置上的数值为1,其他均为0。但是这会出现一个问题,就是某些关键点附近的点,只要不是关键点本身,值都为0,那么在算loss的时候模型都会对他进行惩罚。这不是我们想看到的,因为即使他并不是恰好是关键点坐标,但只要离关键点足够近,依然是可以接受的。
因此我们想到了第二种方法,关键点附近的某个圆内,值均为1,其他均为0。这样做的目的是,我们将与关键点周围某个“可以接受的范围内”的点,均看作关键点的,在算loss的时候不进行惩罚。但是这样做依然会出现问题,比如距离关键点1个像素位的点,与距离关键点10个像素位的点,有可能数值均为1,那么均不会被惩罚,但是我们希望模型的输出尽可能地接近关键点。
最终我们采取的方法是在关键点周围生成高斯圆。也就是生成一个中心值为1,随着距离中心越来越远,数值越来越小的圆。这个圆的数值服从二维离散高斯分布。但是这里面牵扯到一个参数的选取,那就是方差/标准差,也可以认为是这个圆的半径大小,因为两者是等价的。具体公式可以参考[7]。原理简单来说就是遵从“检测框越大,圆半径越大”原则进行设计。
具体方法可以描述为,通过不断平移gt检测框,计算IoU,寻找IoU大于某个阈值的边界情况下的检测框顶点值,这些边界情况的顶点值距离原检测框对应顶点值的距离,就可以认为是该圆半径,从而计算出高斯圆所需要的方差值。
- wh、offset heatmap的设计
对于wh、offset,在训练时并没有设计成heatmap,而是分别设计成了维度为(max_obj, 2)的张量,也可以看作是一个二元组列表,但列表最大长度被限制为了max_obj,其中第k个元素即为第k个物体中心点对应的长宽(或者是横纵坐标的offset)。这么做的目的主要是为了省内存,因为ground truth中只有关键点位置的(而非高斯圆内所有点)长宽、offset参与loss的计算,绝大部分区域不参与计算,因此不需要设计成heatmap来占用内存。
但这里有个问题,我们如何记住wh列表中第k个元素对应的中心点(i.e. 第k个物体的中心点)的坐标是什么呢?因此作者引入了另一个列表,代码中定义为ind,这个列表中的元素均为标量(i.e. 坐标编码),第k个元素的坐标是通过下式编码的:
其中 \(x_k, y_k\) 表示第k个物体的中心点坐标,input_w表示ground truth的宽度(如本节开头说的160)。这个公式其实非常简单,就是把160*120的特征图拉成一条线,上式就是求出了原图中的每个位置在拉成线后的index,因此保证了编码的唯一性,也就是说一旦得到这个编码,我们就可以知道第k个物体中心点的坐标,也就可以将第k个w、h、offset对应起来,从而计算损失。
有人可能会问,为什么要有max_obj这个超参数?这是为了训练的统一性,举例,如果没有这个超参数,一张图上5个物体,另一张图上12个物体,那么我们的wh张量的维度就会分别是(5,2)与(12,2),无法保证统一,也就无法合成batch。
另外,我们在对中心点坐标及补偿进行gt编码时,是除以了下采样因子,也就是这些值都是在“输出空间”(e.g. 160120)里的,但对w、h进行编码时,不需要除以下采样因子,只需要将“输入空间”(e.g. 640480)中的数值填入相应位置即可。
CornerNet
CornerNet是密歇根大学Hei Law等人在发表ECCV2018的一篇论文,作者总结目前anchor-based方法存在两个缺点:
- 提取的anchor boxes数量较多,比如DSSD使用40k, RetinaNet使用100k,anchor boxes众多造成anchor boxes正负样本的不均衡;
- anchor boxes需要调整很多超参数,比如anchor boxes数量、尺寸、比率,影响模型的训练和推断速率。
作者的思路其实来源于一篇多人姿态估计的论文"End-to-end learning for joint detection and grouping"。基于CNN的2D多人姿态估计方法,通常有2个思路(Bottom-Up Approaches和Top-Down Approaches):
- Top-Down framework,就是先进行行人检测,得到边界框,然后在每一个边界框中检测人体关键点,连接成每个人的姿态,缺点是受人体检测框影响较大,代表算法有RMPE。
- Bottom-Up framework,就是先对整个图片进行每个人体关键点部件的检测,再将检测到的人体部位拼接成每个人的姿态,缺点就是可能将检测和拼接分开不是端到端的方法,代表方法就是openpose。
贡献
- 论文的第一个创新是讲目标检测上升到方法论,基于多人姿态估计的Bottom-Up思想,首先同时预测定位框的顶点对(左上角和右下角)热点图和embedding vector,根据embedding vector对顶点进行分组。
- 论文第二个创新是提出了corner pooling用于定位顶点。自然界的大部分目标是没有边界框也不会有矩形的顶点,依top-left corner pooling 为例,对每个channel,分别提取特征图的水平和垂直方向的最大值,然后求和。
- 论文的第三个创新是模型基于hourglass架构,使用focal loss的变体训练神经网络。
Architecture
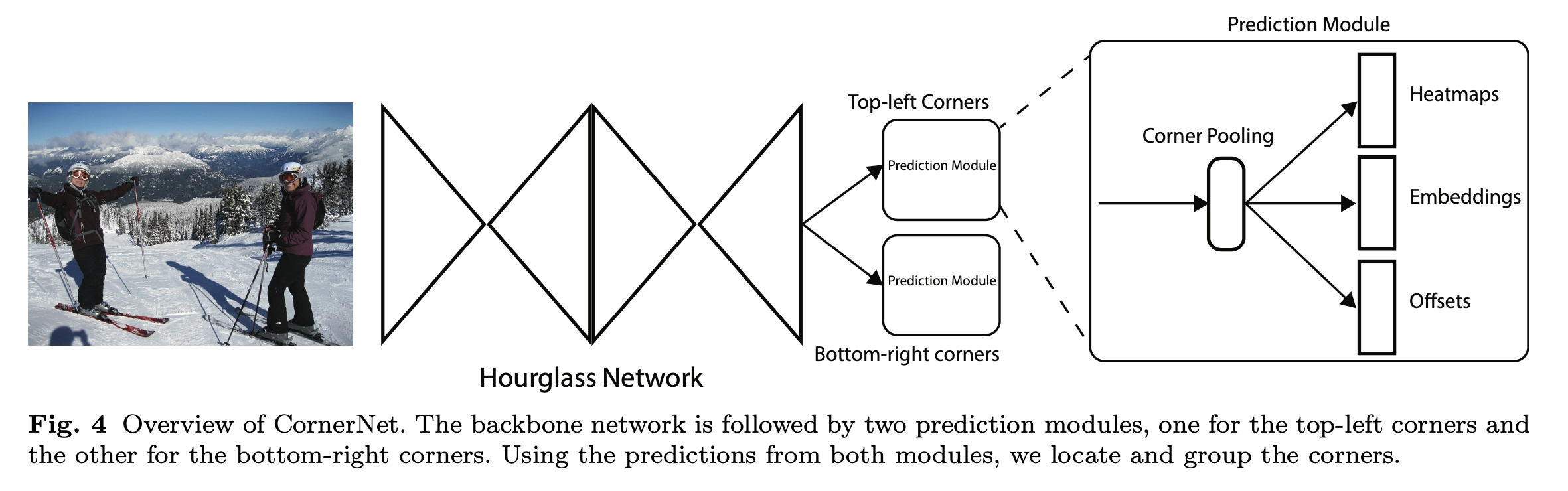
如上图所示,CornerNet模型架构包含三部分,Hourglass Network,Bottom-right corners&Top-left Corners Heatmaps和Prediction Module。
Hourglass Network是人体姿态估计的典型架构,论文堆叠两个Hourglass Network生成Top-left和Bottom-right corners,每一个corners都包括corners Pooling,以及对应的Heatmaps, Embeddings vector和offsets。embedding vector使相同目标的两个顶点(左上角和右下角)距离最短, offsets用于调整生成更加紧密的边界定位框。
Detecting Corners
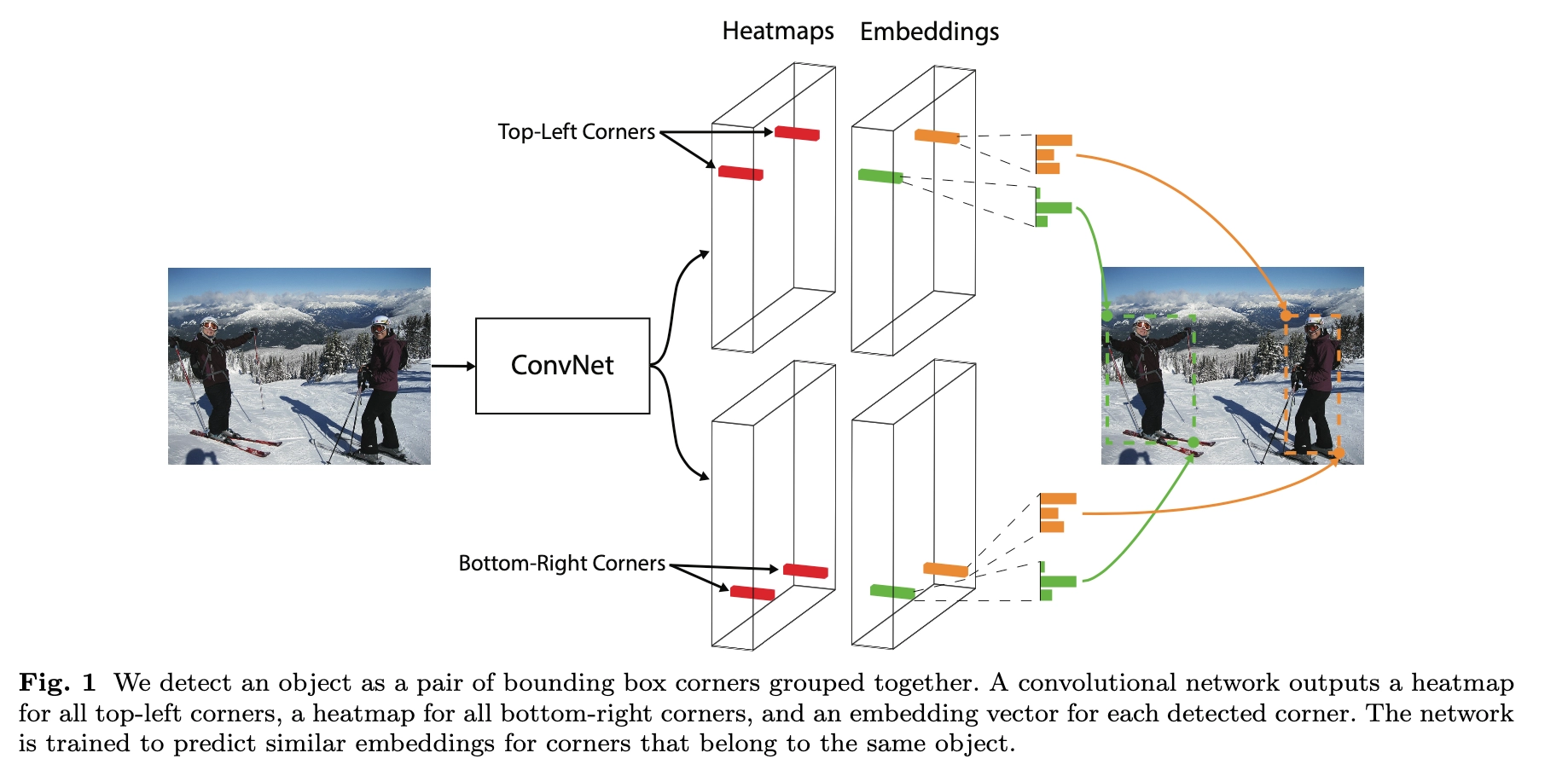
首先预测出两组heatmaps,一组为top-left角点,另一组为bottom-right角点。每组heatmaps有\(C\)个通道,表示\(C\)个类别,尺寸为\(H\times W\)。每个通道是一个binary mask,表示一个类的角点位置。

对于每个角点来说,只有一个gt正例位置,其他都为负例位置。训练时,以正例位置为圆心,设置半径为r的范围内,减少负例位置的惩罚(采用二维高斯的形式),如上图所示。
\(p_{cij}\)表示类别为\(c\),坐标是\((i,j)\) 的预测热点图,\(y_{cij}\)表示相应位置的ground-truth,论文提出变体Focal loss表示检测目标的损失函数:
由于下采样,模型生成的热点图相比输入图像分辨率低。论文提出偏移的损失函数,用于微调corner和ground-truth偏移。
其中\(n\) 为下采样尺度。
Grouping Corners
输入图像会有多个目标,相应生成多个目标的左上角和右下角顶点。对顶点进行分组,论文引入 Associative Embedding的思想,模型在训练阶段为每个corner预测相应的embedding vector,通过embedding vector使同一目标的顶点对距离最短,既模型可以通过embedding vector为每个顶点分组。
模型训练\(L_{pull}\) 损失函数使同一目标的顶点进行分组, \(L_{push} \) 损失函数用于分离不同目标的顶点。
Cornr Pooling

首先看看为什么要引入corner pooling,如图Figure2所示。因为CornerNet是预测左上角和右下角两个角点,但是这两个角点在不同目标上没有相同规律可循,如果采用普通池化操作,那么在训练预测角点支路时会比较困难。考虑到左上角角点的右边有目标顶端的特征信息(第一张图的头顶),左上角角点的下边有目标左侧的特征信息(第一张图的手),因此如果左上角角点经过池化操作后能有这两个信息,那么就有利于该点的预测,这就有了corner pooling。
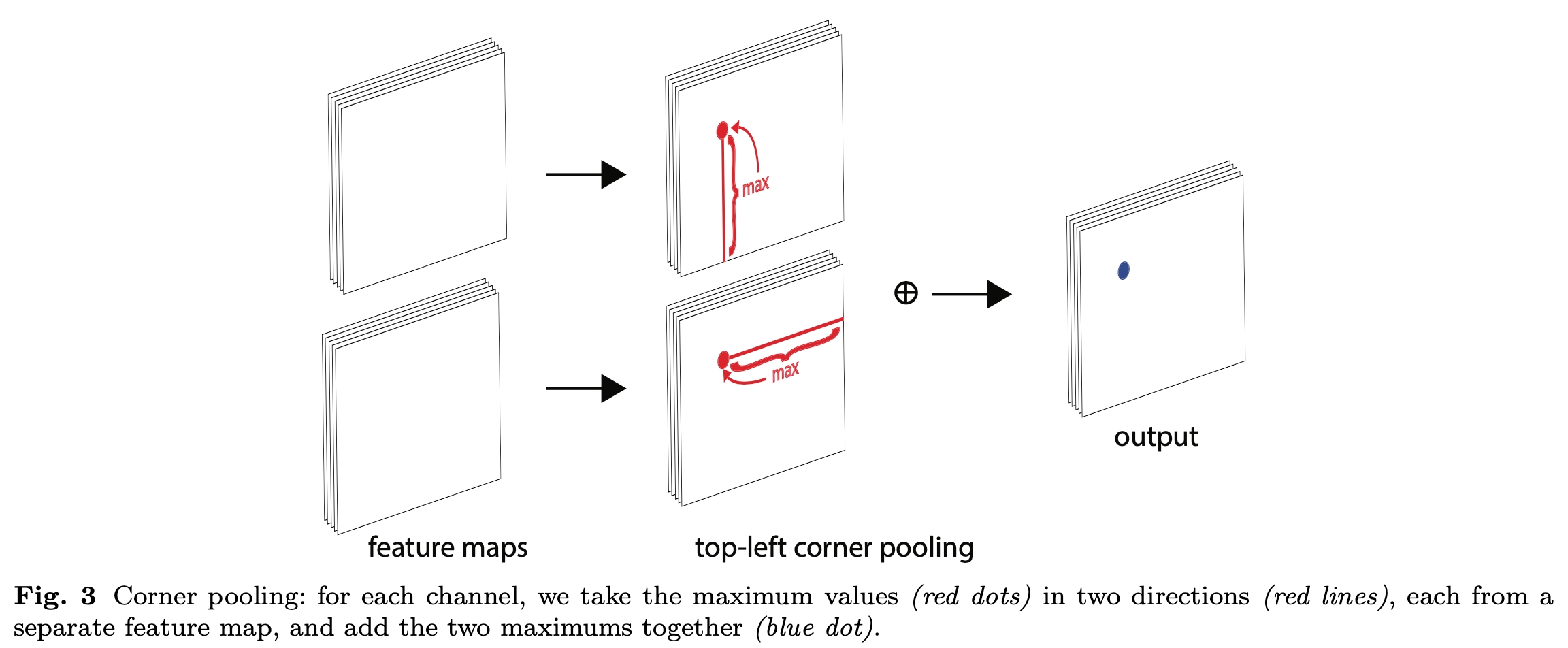
Figure3是针对左上角点做corner pooling的示意图,该层有2个输入特征图,特征图的宽高分别用W和H表示,假设接下来要对图中红色点(坐标假设是\((i,j)\))做corner pooling,那么就计算\((i,j)\)到\((i,H)\)的最大值(对应Figure3上面第二个图),类似于找到Figure2中第一张图的左侧手信息;同时计算\((i,j)\) 到 \((W,j)\) 的最大值(对应Figure3下面第二个图),类似于找到Figure2中第一张图的头顶信息,然后将这两个最大值相加得到\((i,j)\) 点的值(对应Figure3最后一个图的蓝色点)。右下角点的corner pooling操作类似,只不过计算最大值变成从\((0,j)\) 到\((i,j)\) 和从\((i,0)\) 到 \((i,j)\)。
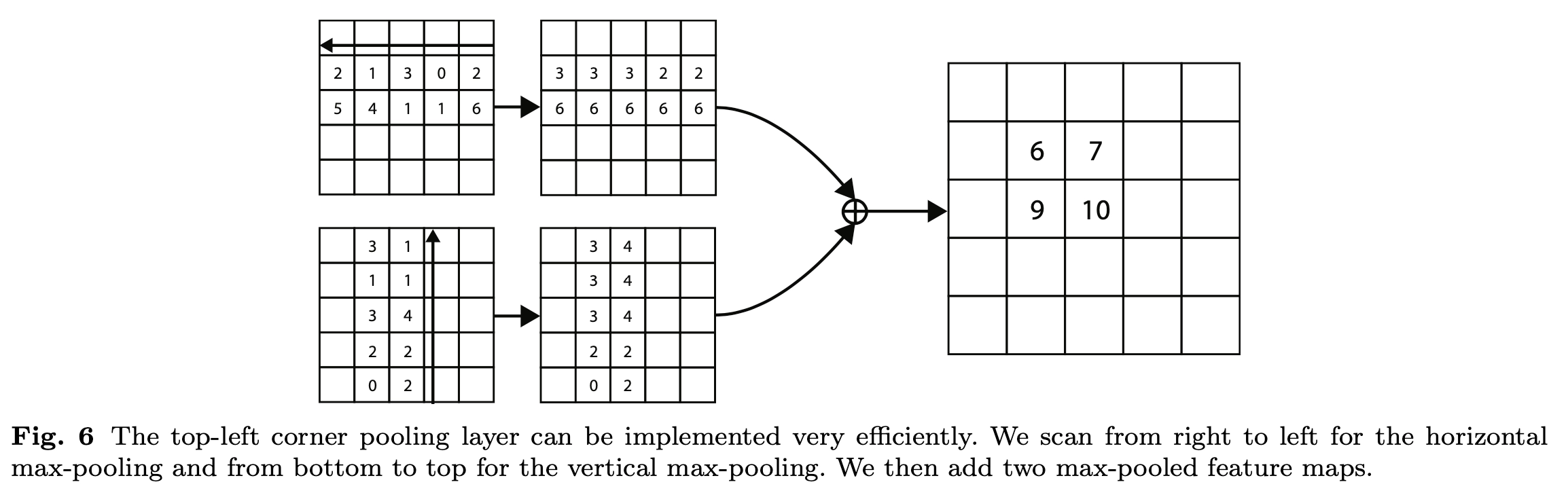
Figure6也是针对左上角点做corner pooling的示意图,是Figure3的具体数值计算例子,该图一共计算了4个点的corner pooling结果。
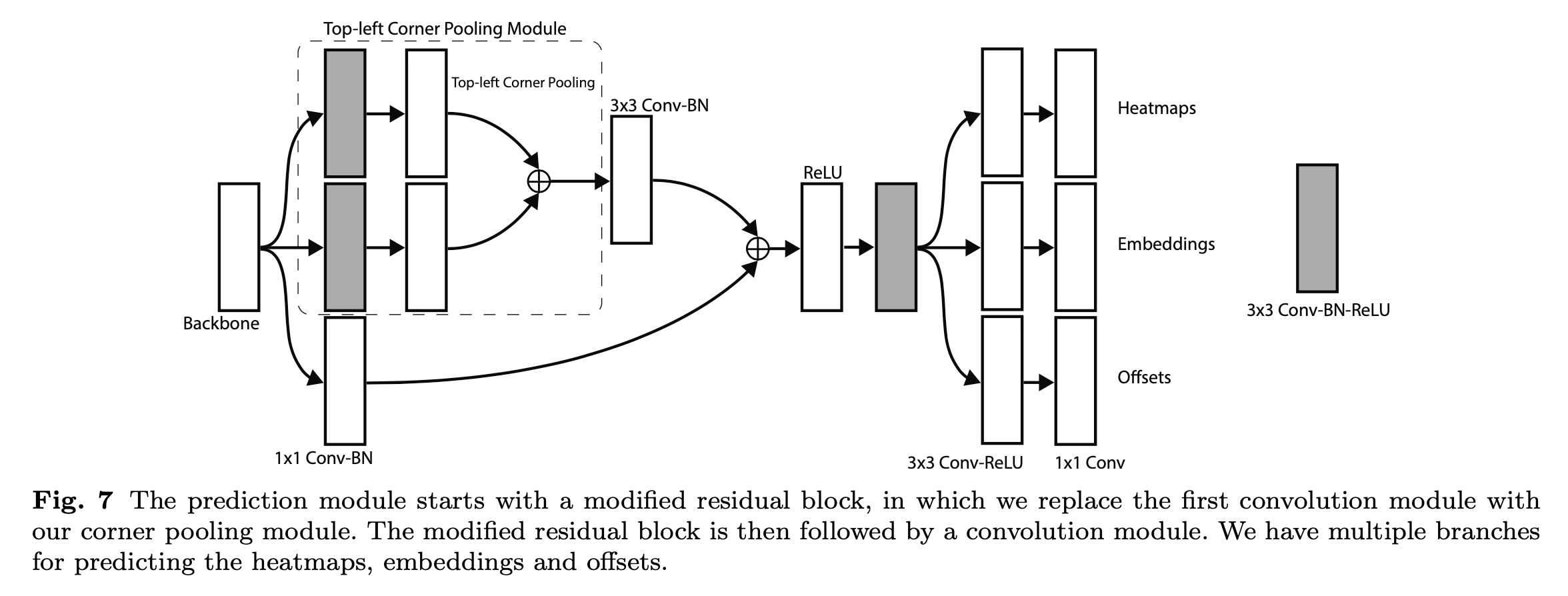
Figure7是Figure4中预测模块的详细结构,该结构包括corner pooling模块和预测输出模块两部分,corner pooling模块采用了类似residual block的形式,有一个skip connection,虚线框部分执行的就是corner pooling操作,也就是Figure6的操作,这样整个corner pooling操作就介绍完了。
RetinaNet
FCOS
先要明确的知道,FCOS是一个基于FCN(全卷积网络用于目标检测)、一阶段(one stage)、anchor free、proposal free、参考语义分割思想 实现的逐像素目标检测的模型。
简要介绍下FCOS几个核心点:
- FCOS方法借鉴了FCN的思想,对 feature map 上每个特征点做回归操作,预测四个值 , 分别代表特征点到Ground Truth Bounding box上、下、左、右边界的距离。
- 特征点映射会原图后对应多个GT Bounding box,无法准确判断原图像素所属类别,因此模型引入 FPN 结构,利用不同的层来处理不同尺寸的目标框。
- 远离目标中心点可能会产生劣质预测结果,为了增强中心点选取的准确性,模型引入了Center-ness layer。
- 损失函数由三个部分构成:分类损失focal loss;回归损失iou loss;center-ness损失 BCE。
Anchor-based 方法的缺点
在前些时候主流的目标检测论文研究大多都是anchor-base,我们熟知的就有SSD、YOLOV2、YOLOV3、Faster-R-CNN、Mask-R-CNN(啥都能做。。),而且准确率最高的大多都是这类anchor-base的模型。
但是anchor-base也有不少缺陷:
- anchor-base模型的检测性能一定程度上依赖于anchor的设计,anchor的基础尺寸、长宽比、以及每一个特征点对应的anchor数目等。比如Faster提出的基准anchor大小16,3种倍数[8, 16, 32] 以及三种比例,共9种anchor。
- 设定好anchor了只能说是匹配到大部分目标,对于那些形变较大的目标检测起来还是比较困难,尤其是小目标(小目标识别已经是一个研究方向了)。同时这也一定程度上限制了模型的泛化能力。
- 为了取得较好的召回率(将负例识别为正例的概率越小,Recall越大),那就需要为每个特征点安排更密集的anchor,假如我们为了性能同时考虑形如FPN这样的多尺度结构,在前向推演以及NMS等操作时,显存以及CPU消耗很大。
- 在这些放置的更密集的anchor中,大多数anchor属于负样本,这样也造成了正负样本之间的不均衡。(Faster好像各选128 positive / negtive 作为训练anchor,不过肯定不是随机挑选的)。
这里讲一些我在实际论文和项目中的感觉啊,基于anchor-base的模型就单说准确率来说已经很高了,但是相对的FPS会低一些,可是!!现实中的项目包括各种制造厂、车载设备、道路设备最终都是需要集成到板端的,现在你搞了密集anchor,在前向推演以及NMS等操作耗时太长,必然不能满足需求。从研究论文角度来讲,anchor-base的门槛已经很高了。。所以大家都开始转战anchor-free,而且还取得了不错的成效,有些想法很棒。
模型结构
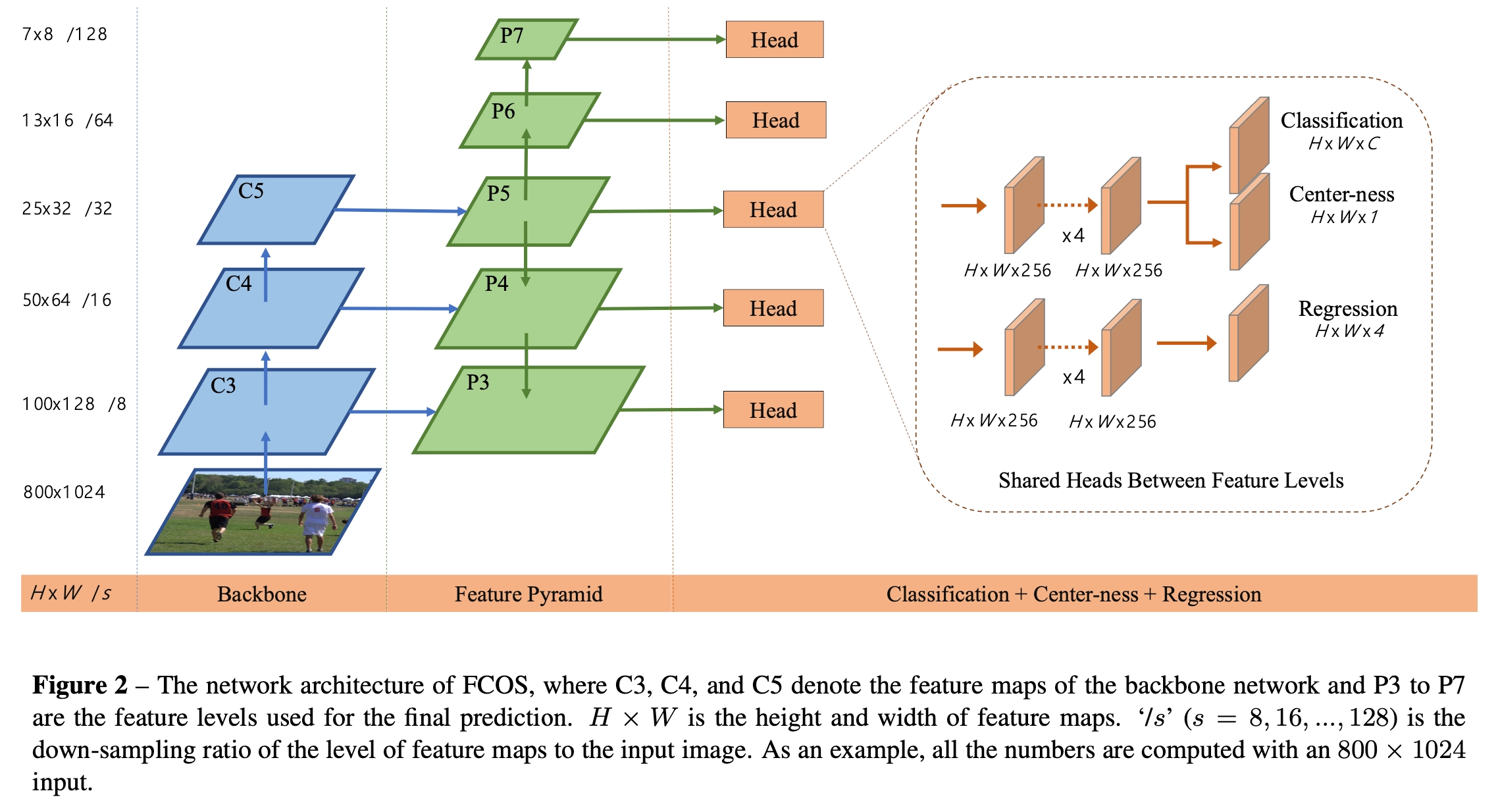
和语义分割相同,检测器直接将位置作为训练样本而不是anchor。具体的,每一个feature map上的特征点都是一个样本,但是在回归之前要映射回原图进行正负样本的判断,映射回原图后的点如果在某一个GT Bounding box内,则对应的特征点是正样本,类别就是Bounding box内目标的类别;否则,负样本。
FPN结构及作用
本文将 feature map 上每一个特征点作为样本,当落在多个GT Bounding box内,论文称这样的特征点为 "模糊样本"(ambiguous sample),那么模糊样本应该回归的边界框对应哪个GT Bounding box?
本文是这样抉择的:(1)引入FPN结构实现多级预测(2)在多级预测筛选后如果某一个特征点还是匹配多个GT Bounding box,这种情况简单的选择面积更小的GT Bounding box作为该特征点的回归目标。
当然模糊样本的出现,还是会干扰当前像素属于哪一类的判断。
本文通过多层级feature map的预测(引入FPN,{P3,P4,P5,P6,P7})来解决模糊样本的问题,说实话这一块其实不是很好懂,我最开始就很疑惑引入了多层级feature map,再把每一级feature map的特征点映射回原图,最后回归岂不是增加了冲突的次数以及计算量?
但是后来仔细看了论文以及查看了很多博客之后,发现FCOS其实是使用不同层级的 feature map 检测不同尺寸的目标(如果是anchor-base的话,这一块难道不就是不同层级的feature map设置不同大小的anchor尺寸吗?),为了实现这样的需求就需要引入一个阈值,该阈值限制不同层级特征回归预测一定范围内尺寸的目标。
Center-ness
在引入FPN结构实现多层级feature map预测后,在性能方面 FCOS 仍与 anchor-base 的模型存在一定差距。这是由于距离目标中心较远的位置预测出大量低质量的Bounding box造成的,简单点说就是某一个层级的特征点映射到原图上的点位于真实GT Bounding box的边缘或者位于距离box目标中心较远的位置,因此模型在学习和预测的时候可能认为这个点不属于它本该对应的目标,但这样造成的结果就是本该回归目标是某一个GT Bounding box的特征点预测出了一个新的box,而这个box没有特别大的意义(并不完全正确,也可以这么理解,本该归类为某一个目标的特征点错误预测成了其它类)。
解决这个问题,核心在于让模型学习到“中心度”,也可以理解成哪些点才是目标最可能的中心点(反向告诉某些特征点,它不是中心点,预测的box没有特别大的意义,这样就抑制了低质量box的产生)。

为了剔除远离目标中心的低质量预测bbox,作者提出了添加center-ness分支,和分类分支并行。
开根号使center-ness衰退缓慢。center-ness范围为0-1之间,通过BCE训练。测试时,最终分数由center-ness预测结果和分类分数乘积得到。
模型最终的目的是输出一组置信度高的box和类别,因此后续使用NMS进行筛选,我们知道NMS是需要一组置信度得分的,那么这个置信度得分如何计算那?是的。。就是模型的输出的 Final置信度 = (类别概率)* (对应的center-ness),根据公式我们可以发现 center-ness 可以看做是一个注意力机制(加权),让模型更加关注那些距离真实目标中心点近的预测box,即使距离中心点远的的点 类别概率得分很高,因为center-ness的存在也能抑制该点的置信度,仍会被NMS筛除。
损失函数
虽然很传统但是还是有所区别:
分类损失:舍弃了softmax,改为对head输出的classification(\(H * W * C\))每一个通道(每一个通道代表一种类别)分别使用sigmoid函数,然后使用 Focal loss。这样做的好处,在我的理解中是为了保留类别之间的关联特性。
回归损失:IOU Loss,仅对那些有意义的特征点进行回归计算。有意义是什么意思那?其实就是先将特征点映射回原图,看看原图上对应的点在不在某一个GT Bounding box里面,不在就是负样本,也就是;如果在一个或多个box里面,则根据FPN不同层级feature map 能够回归的范围阈值筛除不符合条件的box,然后继续重复上述步骤判断该特征点是否有意义。
center-ness的损失:BCE损失(二值交叉熵),我很奇怪,这部分并没有体现在上面那个公式里面,不过肯定是有的。
补充一些细节
在引入FPN的同时还引入一些改变,FCOS在不同的特征层级之间共享head(共享的是结构/权重共享,代码中详看 cls_tower和bbox_tower )。但是不同的特征层级需要回归不同的大小范围(例如,P3的大小范围是[0,64],P4的大小范围是[64,128],因此对于不同的特征层级使用相同的head是不合理的。因此,论文中不再使用标准的exp(x),而是使用\(\exp(s_i * x)\),其中可训练标量 \(s_i\) 被用来自动调整不同层级特征的指数函数的基数,从而稍微提高了检测性能(在下面代码中si首次出现在__init__()函数的最后)。
VarifocalNet
目标检测中NMS需要依据候选检测目标的排序来进行筛选框,如果分类得分较低,但是定位框准确会导致在NMS中将该bbox框被排除掉,因此这个排序的可靠性就非常重要。之前的工作主要采用IOU分支(IOU-Net)与Centerness得分(FCOS)来作为大量候选检测的排序依据。
然而,本文认为这些方法可以有效缓解分类得分和物体定位精度之间的不对齐问题。 但是,它们是次优解的,因为将两个不完善的预测相乘可能会导致排名依旧变差,作者经过试验表明,通过这种方法实现的性能上限非常有限。 此外,增加一个额外的网络分支来预测定位分数并不是一个很好的解决方案,并且会带来额外的计算负担。
基于上述分析,作者提出:不采用预测一个额外的定位精确度得分(IOU-aware Centerness),而是将其merge进分类得分中。即预测一个可以同时代表目标存在和定位精度的定位感知或者IOU感知的分类得分。
Motivation
为了探索出候选框质量的排序依据和性能上限,本文以FCOS+ATSS为baseline,利用NMS之前的目标对应的gt真实值替换预测的分类得分,位置偏移和Centerness得分,并进行AP性能评估。 对于分类概率向量,有两种实现方法,在其gt标签位置的元素替换为一个1的数值,或者替换为预测框与gt框的IOU值。 除了gt真值之外,本文还考虑用gt IoU代替Centerness得分。

如表1中所示,看一下具体实验结果:
- baseline + centerness AP得分39.2
- baseline + centerness替换为gt_centerness,39.2->41.1
- baseline + centerness替换为gt_iou,39.2->43.5
这表明使用预测的IoU得分与分类得分的乘积对检测进行排序肯定无法带来显著的性能提升。centerness得分同样道理 - baseline+gt_bbox,39.2->56.1,这里直接把所有的groudtruth bbox放进候选检测?不是很懂
- baseline+gt_cls,即将gt位置的分类标签设置为1,这时候是否使用centerness将有明显区别,43.1 vs 58.1
- baseline+gt_cls_iou,将于gt的iou替换为5中的gt_cls,作为分类得分。直接74.7AP,加上centerness反而会降低到67.4AP
以上实验对比,具有更高IOU的候选检测是高质量的检测结果,这些结果表明IOU感知的排序策略(IACS)是最有效的选择方案。
网络结构
IACS – IoU-Aware Classification Score
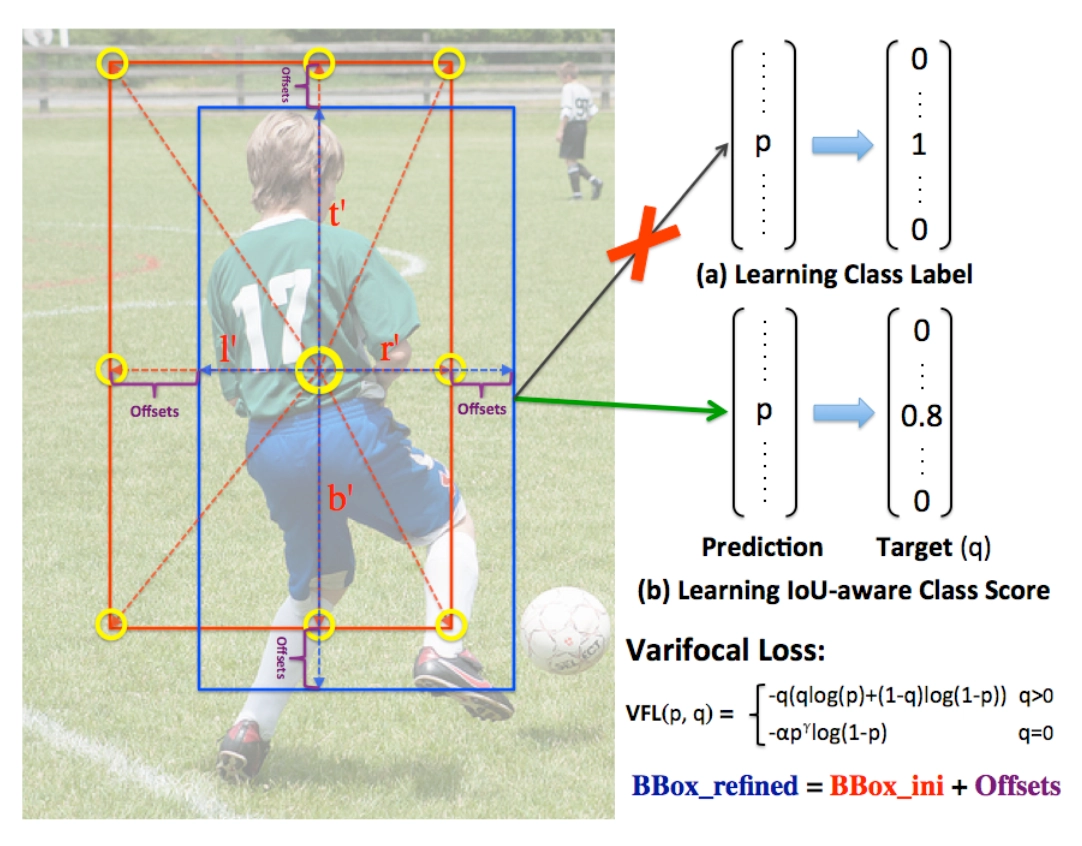
IACS定义为分类得分向量的标量元素,其中ground-truth类标签位置的值为预测边界框与其ground truth之间的IoU,其他位置为0。如上图所示,不是学习预测一个bounding box的类标签(a),而是学习IoU-aware分类得分(IACS)作为检测分数,融合了目标存在置信度和定位精度(b)。也就是motivation中实验分析的结果。
Varifocal Loss
Focal loss定义:
其中\(\alpha\) 是前景背景的损失权重,\((1-p)^{\gamma}\)和\(p^{\gamma}\)是不同样本的权重,难分样本的损失权重会增大。当训练一个密集的物体检测器使连续的IACS回归时,本文从focal loss中借鉴了样本加权思想来解决类不平衡问题。 但是,与focal loss同等对待正负样本的损失不同,本文选择不对称地对待它们。varifocal loss定义如下:
其中p是预测的IACS得分,q是目标IoU分数。 对于训练中的正样本,将q设置为生成的bbox和gt box之间的IoU(gt IoU),而对于训练中的负样本,所有类别的训练目标q均为0。
Varifocal Loss会预测Iou-aware Cls_score(IACS)与分类两个得分,通过\(p^{\gamma}\) 来有效降低负样本损失的权重,正样本选择不降低权重(因为与负样本相比,正样本已经算是稀有样本了)。此外,通过q(Iou感知得分)来对Iou高的正样本损失加大权重,相当于将训练重点放在高质量的样本上面。
Star-Shaped Box Feature Representation
在FCOS中,bbox与以往的(x,y,w,h)的box特征表达区域不同,预测出由(l’,t’,r’,b’)编码的4D向量,这表示从位置(x,y)到左,上,右和下侧边界框的距离。
再联想Deformable卷积的形式,FCOS的这种bbox编码方式可以很自然的与之结合,具体来说就是:选择以下九个采样点: (x,y),(x-l’,y),(x,y-t’),(x + r’,y),(x,y + b’),(x-l’,y-t’),(x + l’,y-t’),(x-l’,y + b’)和(x + r’,y + b ')。 然后将这九个位置映射到特征图上,并通过可变形卷积对投影点处的特征进行卷积以表示边界框。 由于这些点是手动选择的,因此没有额外的预测负担,因此这种新的表示形式具有很高的计算效率。
这种有效的星形边界框特征表示法,用于预测IACS。 它使用9个固定采样点的特征(图1中的黄色圆圈)来表示具有可变形卷积的边界框。 这种新的表示形式可以捕获包围盒的几何信息及其附近的上下文信息,这对于编码预测的bbox与gt box之间的不对齐问题是至关重要的.
Bounding Box Refinement
对于最初回归的边界框(l’,t’,r’,b’),首先提取星形表示形式对其进行编码。 然后,我们学习四个距离缩放因子(\(\Delta l,\Delta t, \Delta r, \Delta b\))来缩放距离矢量。最终表示为\((l, t, r, b) = (∆l×l’, ∆t×t’, ∆r×r’, ∆b×b’)\)
ATSS
由于FPN和Focal loss 的加入,anchor-free模型变得越来越多。在仔细比对了anchor-based和anchor-free目标检测方法后,结合实验结果,论文认为两者的性能差异主要来源于正负样本的定义,假如训练过程中使用相同的正负样本,两者的最终性能将会相差无几。
作者将目前的Anchor-free分为两个大类:
- keypoint-based methods:以CornerNet和ExtremeNet为代表,首先定位几个预定义或自学习的关键点,然后限制物体的空间范围;
- center-based methods:以FCOS和Foveabox为代表,使用物体的中心点或区域定义基准点,然后预测从该点到物体边界的四个距离。
为此,论文提出ATSS( Adaptive Training Sample Selection)方法,基于GT的相关统计特征自动选择正负样本,能够消除anchor-based和anchor-free算法间的性能差异论文的主要贡献如下:
- 指出anchor-free和anchor-based方法的根本差异主要来源于正负样本的选择
- 提出ATSS( Adaptive Training Sample Selection)方法来根据对象的统计特征自动选择正负样本
- 证明每个位置设定多个anchor是无用的操作
- 不引入其它额外的开销,在MS COCO上达到SOTA
Difference Analysis of Anchor-based and Anchor-free Detection
论文选取anchor-based方法RetinaNet和anchor-free方法FCOS进行对比,差异主要有以下3点:
- RetinaNet在特征图上每个点铺设多个anchor,而FCOS在特征图上每个点只铺设一个中心点,这是数量上的差异。
- RetinaNet基于anchor和GT之间的IoU和设定的阈值来确定正负样本,而FCOS通过GT中心点和铺设点之间的距离和尺寸来确定正负样本。这1点可以从下图的对比中看到,牛这张图像中蓝色框和点表示GT,红色框表示RetinaNet铺设的anchor,红色点表示FCOS铺设的点,左右两边类似表格上的数值表示最终确定的正负样本,0表示负样本,1表示正样本。
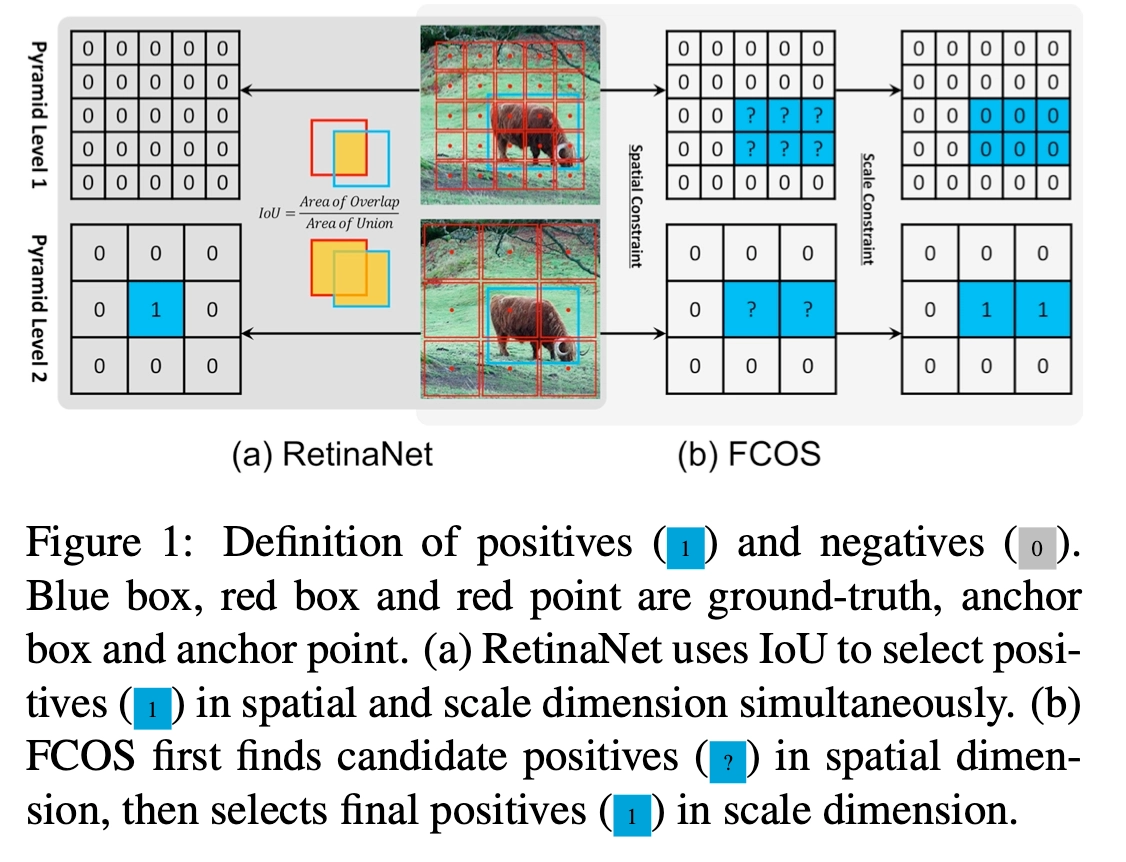
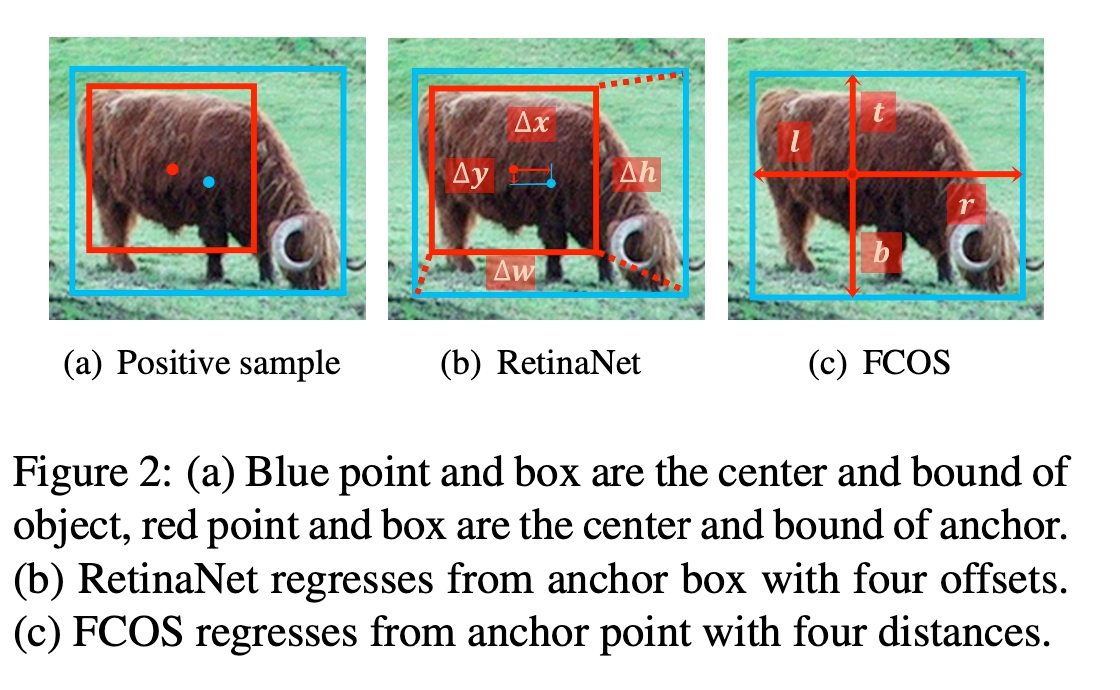
- RetinaNet通过回归矩形框的2个角点偏置进行预测框位置和大小的预测,而FCOS是基于中心点预测四条边和中心点的距离进行预测框位置和大小的预测。这点可以从下图的对比中看到,蓝色框和点表示GT,红色框表示RetinaNet的正样本,红色点表示FCOS的正样本。
Inconsistency Removal
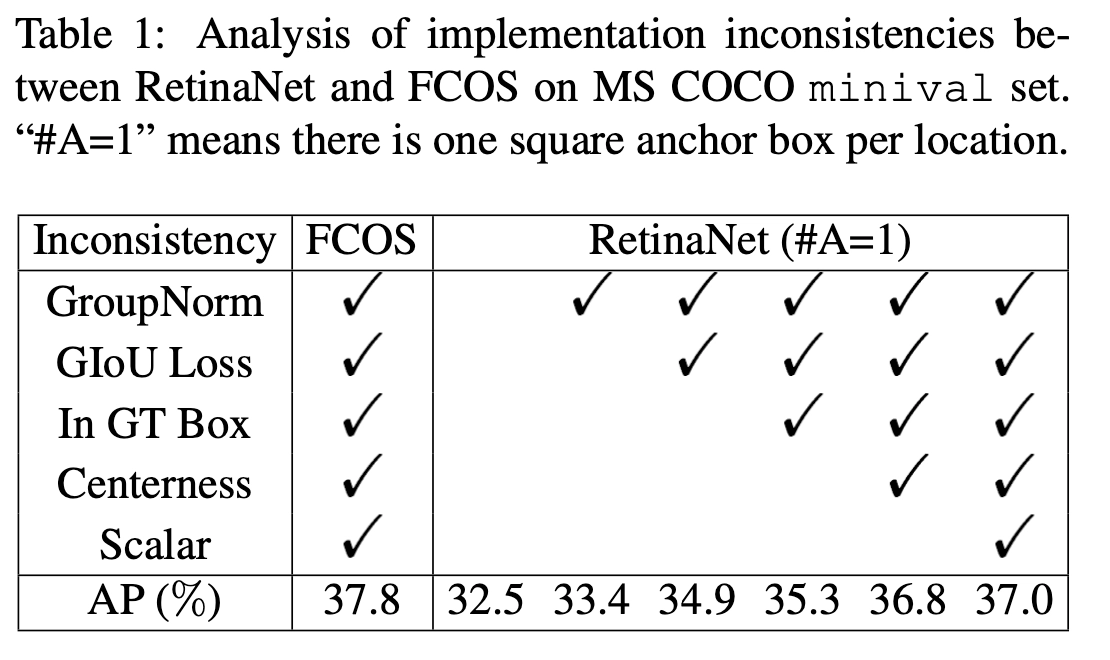
由于FCOS加入了很多trick,这里将RetinaNet与其进行对齐,包括GroupNorm、GIoU loss、限制正样本必须在GT内、Centerness branch以及添加可学习的标量控制FPN的各层的尺寸。结果如表1,最终的RetinaNet仍然与FCOS有些许的性能差异,但在实现方法上已经基本相同了
Essential Difference
所以接下来作者对剩余的0.8mAP差异进行了分析,做了Table2这个实验。这个表格可以这样看:

按行看,Intersection over Union这一行的两个数值表示RetinaNet和FCOS都采用基于IoU方式确定正负样本,二者的mAP基本没有差别;同样Spatial and Scale Constraint这一行的两个数值表示RetinaNet和FCOS都采用基于距离和尺寸方式确定正负样本,二者的mAP也是一样。所以结论就是:回归方式的不同并不是造成FCOS和RetinaNet效果差异的原因,也就是前面说的第2点差异是不影响的。
按列看,Box这一列的两个数值表示将RetinaNet的正负样本确定方式从IoU换成和FCOS一样的基于距离和尺寸,那么mAP就从37.0上升到37.8;同样Point这一列的两个数值表示将FCOS的正负样本确定方式从基于距离和尺寸换成和RetinaNet一样的基于IoU,那么mAP就从37.8降为36.9。所以结论就是:如何确定正负样本才是造成FCOS和RetinaNet效果差异的原因,也就是前面说的第3点差异才是根源。
Adaptive Training Sample Selection
从论文开始到目前为止的实验对比和分析都是步步紧扣,答案也随之浮出水面,接下来就是论文的第2大部分内容,也就是提出ATSS来确定正负样本,不过这部分给我的感觉没有前面的实验对比来得有说服力。ATSS本身没有太复杂的内容,如Algorithm 1所示,第3到6行是根据anchor和GT的中心点距离选出候选正样本,每层K个;第7行是计算IoU;第8行到第15行是先计算IoU的均值和标准差从而得到阈值,然后根据阈值进行正负样本确定。

ATSS的思想主要考虑了下面几个方向:
- Selecting candidates based on the center distance between anchor box and object
在RetinaNet中,anchor box与GT中心点越近一般IoU越高,而在FCOS中,中心点越近一般预测的质量越高
- Using the sum of mean and standard deviation as the IoU threshold
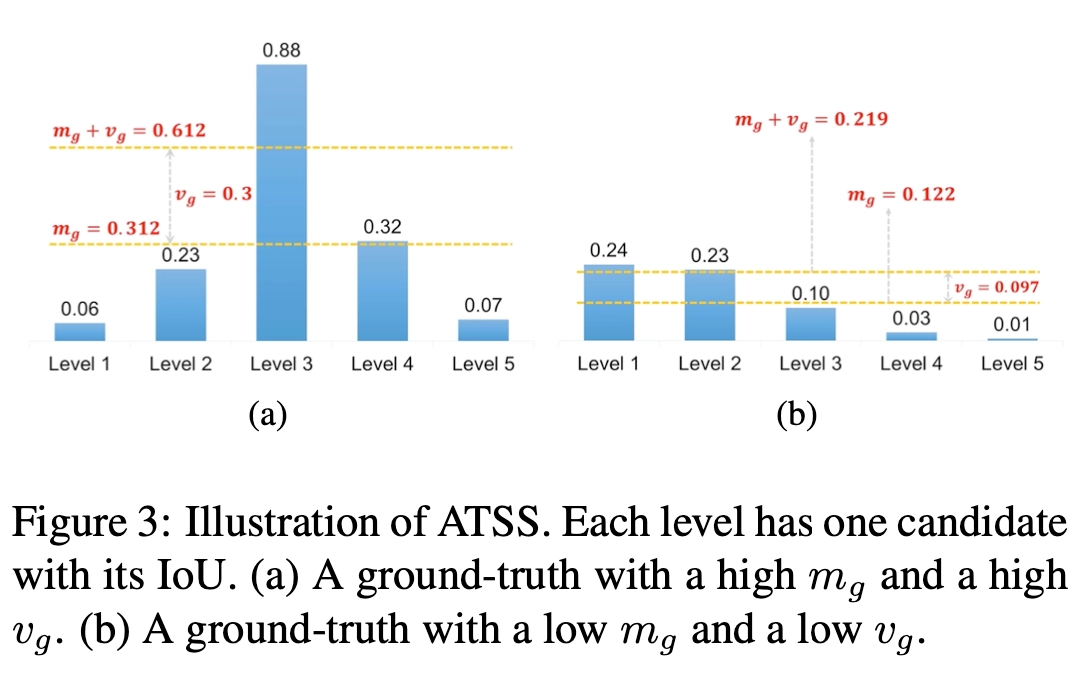
均值\(m_g\) 表示预设的anchor与GT的匹配程度,均值高则应当提高阈值来调整正样本,均值低则应当降低阈值来调整正样本。标准差\(v_g\) 表示适合GT的FPN层数,标准差高则表示高质量的anchor box集中在一个层中,应将阈值加上标准差来过滤其他层的anchor box,低则表示多个层都适合该GT,将阈值加上标准差来选择合适的层的anchor box,均值和标准差结合作为IoU阈值能够很好地自动选择对应的特征层上合适的anchor box
- Limiting the positive samples’ center to object
若anchor box的中心点不在GT区域内,则其会使用非GT区域的特征进行预测,这不利于训练,应该排除
- Maintaining fairness between different objects
根据统计原理,大约16%的anchor box会落在\([m_g+v+g,1]\),尽管候选框的IoU不是标准正态分布,但统计下来每个GT大约有\(0.2*kL\) 个正样本,与其大小和长宽比无关,而RetinaNet和FCOS则是偏向大目标有更多的正样本,导致训练不公平.
- Keeping almost hyperparameter-free
ATSS仅有一个超参数\(k\),后面的使用会表明ATSS的性能对k不敏感,所以ATSS几乎是hyperparameter-free的