简介
CornerNet是密歇根大学Hei Law等人在发表ECCV2018的一篇论文,作者总结目前anchor-based方法存在两个缺点:
- 提取的anchor boxes数量较多,比如DSSD使用40k, RetinaNet使用100k,anchor boxes众多造成anchor boxes正负样本的不均衡;
- anchor boxes需要调整很多超参数,比如anchor boxes数量、尺寸、比率,影响模型的训练和推断速率。
作者的思路其实来源于一篇多人姿态估计的论文"End-to-end learning for joint detection and grouping"。基于CNN的2D多人姿态估计方法,通常有2个思路(Bottom-Up Approaches和Top-Down Approaches):
(1)Top-Down framework,就是先进行行人检测,得到边界框,然后在每一个边界框中检测人体关键点,连接成每个人的姿态,缺点是受人体检测框影响较大,代表算法有RMPE。
(2)Bottom-Up framework,就是先对整个图片进行每个人体关键点部件的检测,再将检测到的人体部位拼接成每个人的姿态,缺点就是可能将检测和拼接分开不是端到端的方法,代表方法就是openpose。
贡献
- 论文的第一个创新是讲目标检测上升到方法论,基于多人姿态估计的Bottom-Up思想,首先同时预测定位框的顶点对(左上角和右下角)热点图和embedding vector,根据embedding vector对顶点进行分组。
- 论文第二个创新是提出了corner pooling用于定位顶点。自然界的大部分目标是没有边界框也不会有矩形的顶点,依top-left corner pooling 为例,对每个channel,分别提取特征图的水平和垂直方向的最大值,然后求和。
- 论文的第三个创新是模型基于hourglass架构,使用focal loss的变体训练神经网络。
Architecture
Overview
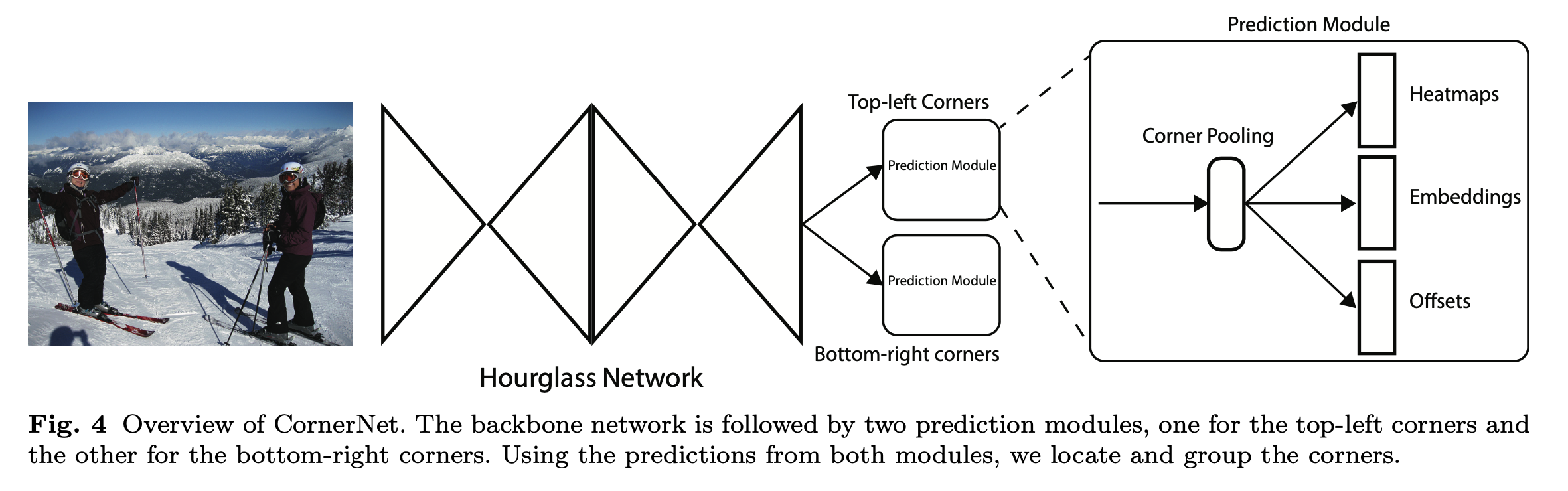
如图 4所示,CornerNet模型架构包含三部分,Hourglass Network,Bottom-right corners&Top-left Corners Heatmaps和Prediction Module。
Hourglass Network是人体姿态估计的典型架构,论文堆叠两个Hourglass Network生成Top-left和Bottom-right corners,每一个corners都包括corners Pooling,以及对应的Heatmaps, Embeddings vector和offsets。embedding vector使相同目标的两个顶点(左上角和右下角)距离最短, offsets用于调整生成更加紧密的边界定位框。
Detecting Corners
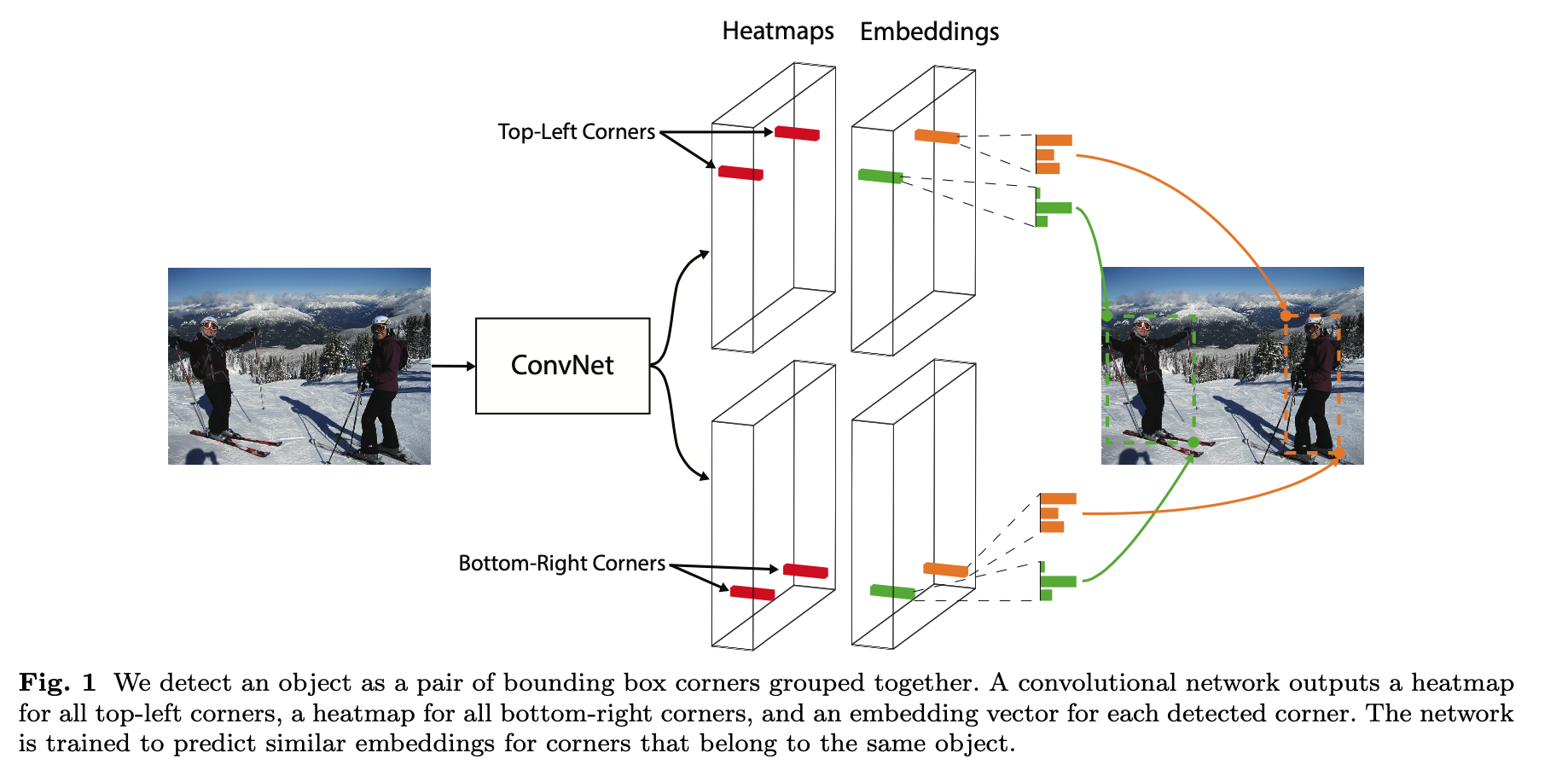
首先预测出两组heatmaps,一组为top-left角点,另一组为bottom-right角点。每组heatmaps有C个通道,表示C个类别,尺寸为HxW。每个通道是一个binary mask,表示一个类的角点位置。

对于每个角点来说,只有一个gt正例位置,其他都为负例位置。训练时,以正例位置为圆心,设置半径为r的范围内,减少负例位置的惩罚(采用二维高斯的形式),如上图所示。
\(p_{cij}\)表示类别为\(c\),坐标是\((i,j)\) 的预测热点图,\(y_{cij}\)表示相应位置的ground-truth,论文提出变体Focal loss表示检测目标的损失函数:
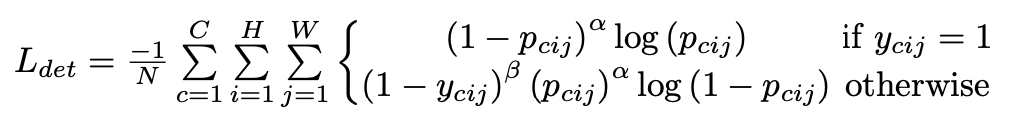
由于下采样,模型生成的热点图相比输入图像分辨率低。论文提出偏移的损失函数,用于微调corner和ground-truth偏移。
其中\(n\) 为下采样尺度。
Grouping Corners
输入图像会有多个目标,相应生成多个目标的左上角和右下角顶点。对顶点进行分组,论文引入 Associative Embedding的思想,模型在训练阶段为每个corner预测相应的embedding vector,通过embedding vector使同一目标的顶点对距离最短,既模型可以通过embedding vector为每个顶点分组。
模型训练\(L_{pull}\) 损失函数使同一目标的顶点进行分组, $L_{push} $ 损失函数用于分离不同目标的顶点。
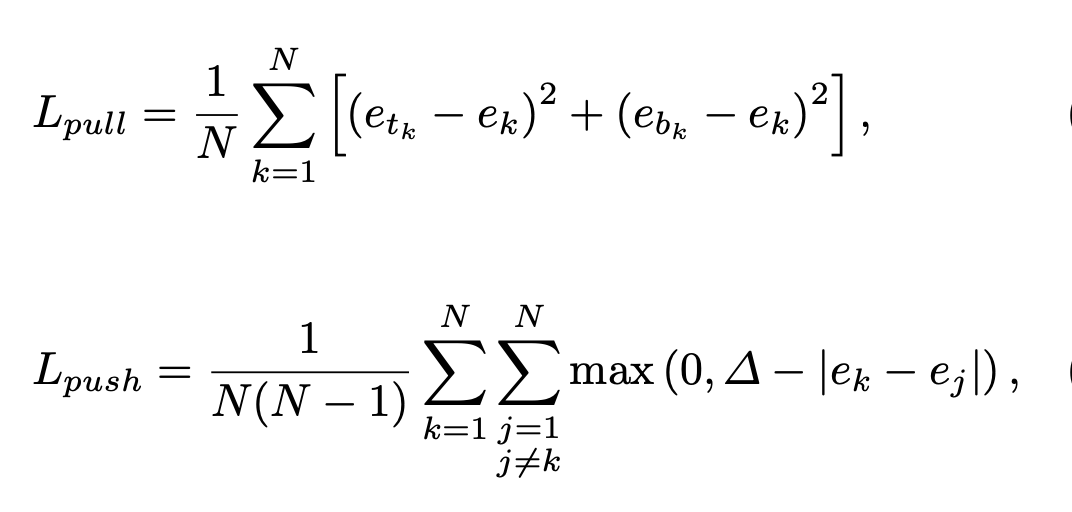
Cornr Pooling

首先看看为什么要引入corner pooling,如图Figure2所示。因为CornerNet是预测左上角和右下角两个角点,但是这两个角点在不同目标上没有相同规律可循,如果采用普通池化操作,那么在训练预测角点支路时会比较困难。考虑到左上角角点的右边有目标顶端的特征信息(第一张图的头顶),左上角角点的下边有目标左侧的特征信息(第一张图的手),因此如果左上角角点经过池化操作后能有这两个信息,那么就有利于该点的预测,这就有了corner pooling。
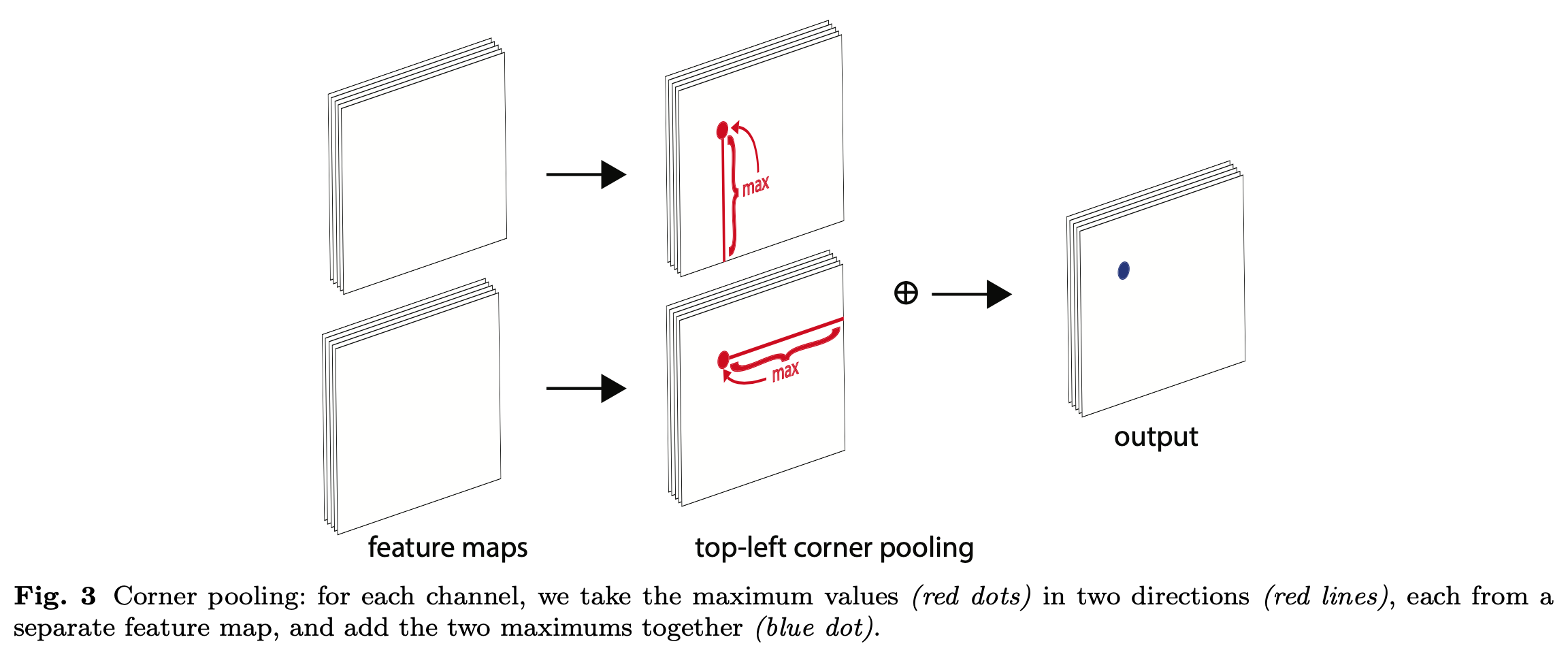
Figure3是针对左上角点做corner pooling的示意图,该层有2个输入特征图,特征图的宽高分别用W和H表示,假设接下来要对图中红色点(坐标假设是\((i,j)\))做corner pooling,那么就计算\((i,j)\)到\((i,H)\)的最大值(对应Figure3上面第二个图),类似于找到Figure2中第一张图的左侧手信息;同时计算\((i,j)\) 到 \((W,j)\) 的最大值(对应Figure3下面第二个图),类似于找到Figure2中第一张图的头顶信息,然后将这两个最大值相加得到\((i,j)\) 点的值(对应Figure3最后一个图的蓝色点)。右下角点的corner pooling操作类似,只不过计算最大值变成从\((0,j)\) 到\((i,j)\) 和从\((i,0)\) 到 \((i,j)\)。
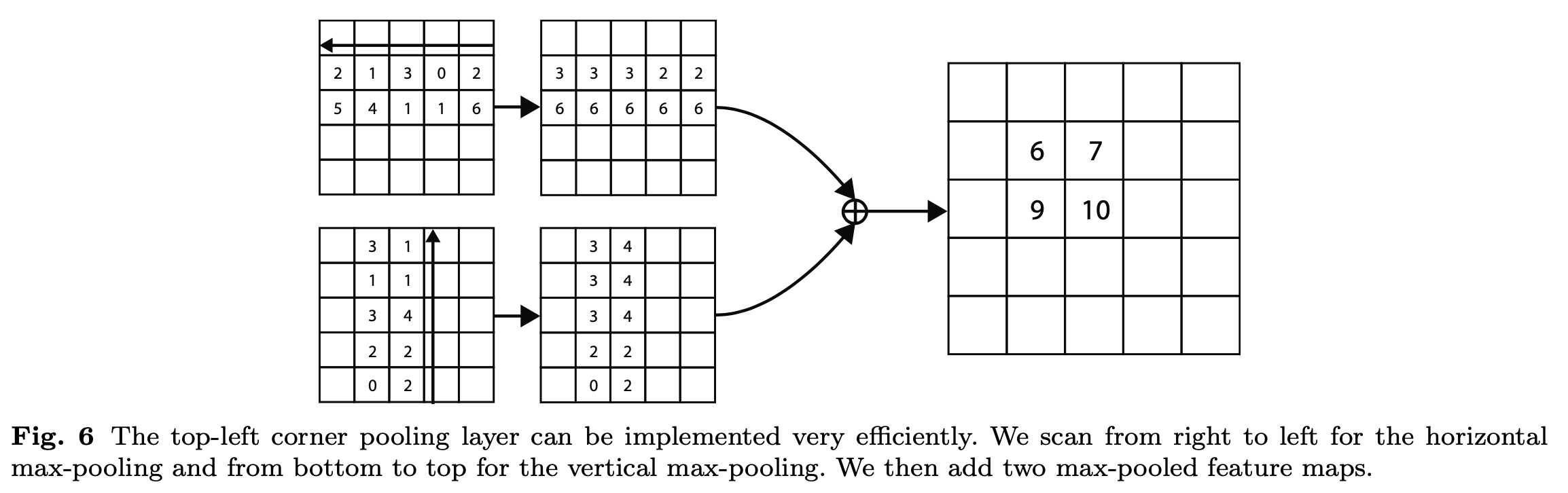
Figure6也是针对左上角点做corner pooling的示意图,是Figure3的具体数值计算例子,该图一共计算了4个点的corner pooling结果。

Figure7是Figure4中预测模块的详细结构,该结构包括corner pooling模块和预测输出模块两部分,corner pooling模块采用了类似residual block的形式,有一个skip connection,虚线框部分执行的就是corner pooling操作,也就是Figure6的操作,这样整个corner pooling操作就介绍完了。