
DeepSeek LLM
代码地址:https://github.com/deepseek-ai/DeepSeek-LLM
背景
量化巨头幻方探索AGI(通用人工智能)新组织“深度求索”在成立半年后,发布的第一代大模型,免费商用,完全开源。作为一家隐形的AI巨头,幻方拥有1万枚英伟达A100芯片,有手撸的HAI-LLM训练框架HAI-LLM:高效且轻量的大模型训练工具。
概述
DeepSeek LLMs,这是一系列在2万亿标记的英语和中文大型数据集上从头开始训练的开源模型
在本文中,深入解释了超参数选择、Scaling Laws以及做过的各种微调尝试。校准了先前工作中的Scaling Laws,并提出了新的最优模型/数据扩展-缩放分配策略。此外,还提出了一种方法,使用给定的计算预算来预测近似的batch-size和learning-rate。进一步得出结论,Scaling Laws与数据质量有关,这可能是不同工作中不同扩展行为的原因。在Scaling Laws的指导下,使用最佳超参数进行预训练,并进行全面评估。
作者还对DeepSeek LLM基础模型进行了SFT和直接偏好优化(DPO),从而创建了DeepSeek Chat模型。
最后,评估结果表明,DeepSeek LLM 67B在各种基准测试中超过了LLaMA-2 70B,特别是在代码、数学和推理领域。此外,开放式评估显示,与GPT-3.5相比,DeepSeek LLM 67B Chat表现出更优越的性能。
模型框架

DeepSeek LLM基本上遵循LLaMA的设计,采用Pre-Norm结构,并使用RMSNorm函数和SwiGLU作为Feed-Forward Network(FFN)的激活函数,中间层维度为8/3 。它还集成了RoPE。为了优化推理成本,67B模型使用分组查询注意力(GQA)而不是传统的多头注意力(MHA)。
在宏观设计方面,DeepSeek LLM略有不同。DeepSeek LLM 7B是一个30层的网络,DeepSeek LLM 67B有95层。这些层调整在保持与其他开源模型参数一致的同时,也有助于优化训练和推理的模型管道划分。
与大多数使用分组查询注意力(GQA)的模型不同,deepseek扩大了67B模型的参数网络深度,而不是常见的拓宽FFN层中间宽度的做法,旨在获得更好的性能。详细的网络规格可以在上表中找到。
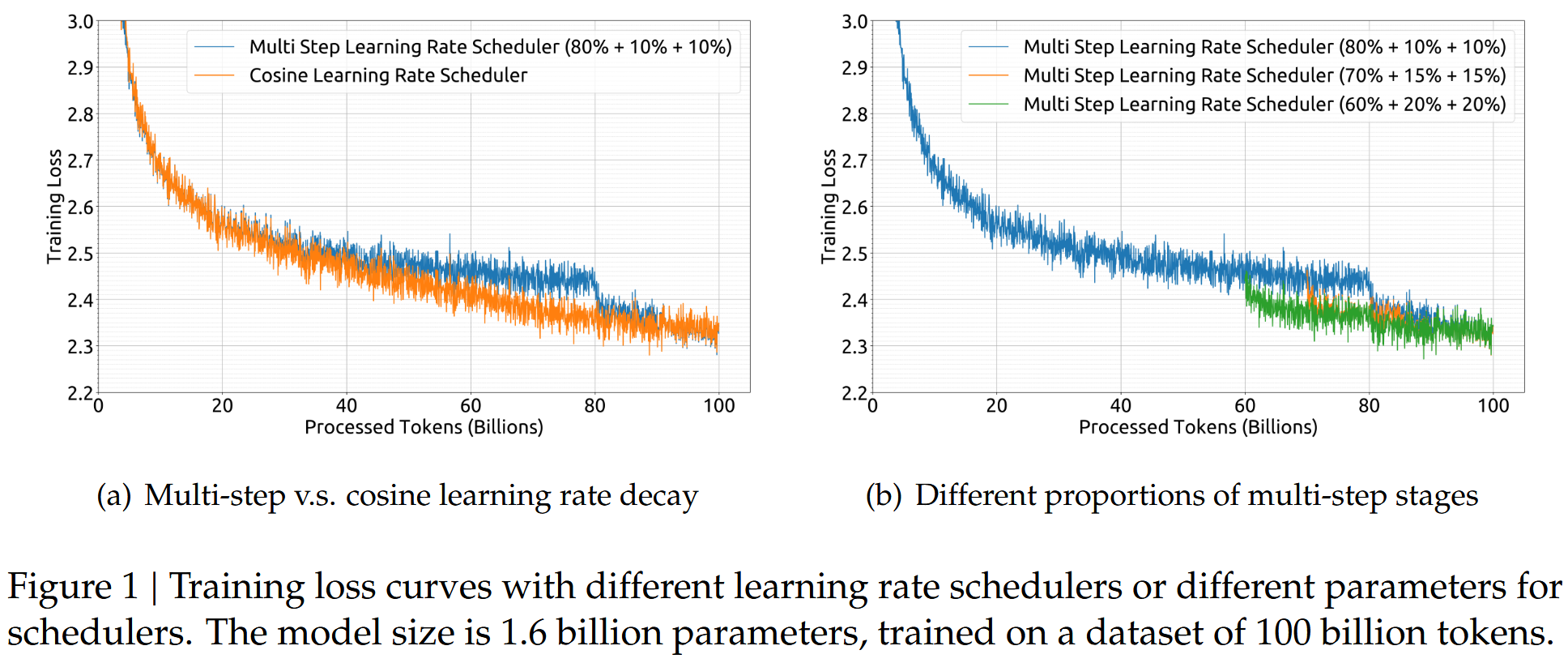
另外作者对比了学习率Multi-Step和Cosin decay的方案,发现两者在最终的表现相差不大,但是在保持模型大小不变的情况下调整训练规模,Multi-Step的方式允许第一阶段的训练重复使用,为连续训练提供了便利。因此,作者选择了多步学习速率调度器作为默认设置。为了平衡持续训练中的重用率和模型性能,作者选择了 80% ,10% 和 10% 的三个阶段训练。
Scalling Laws
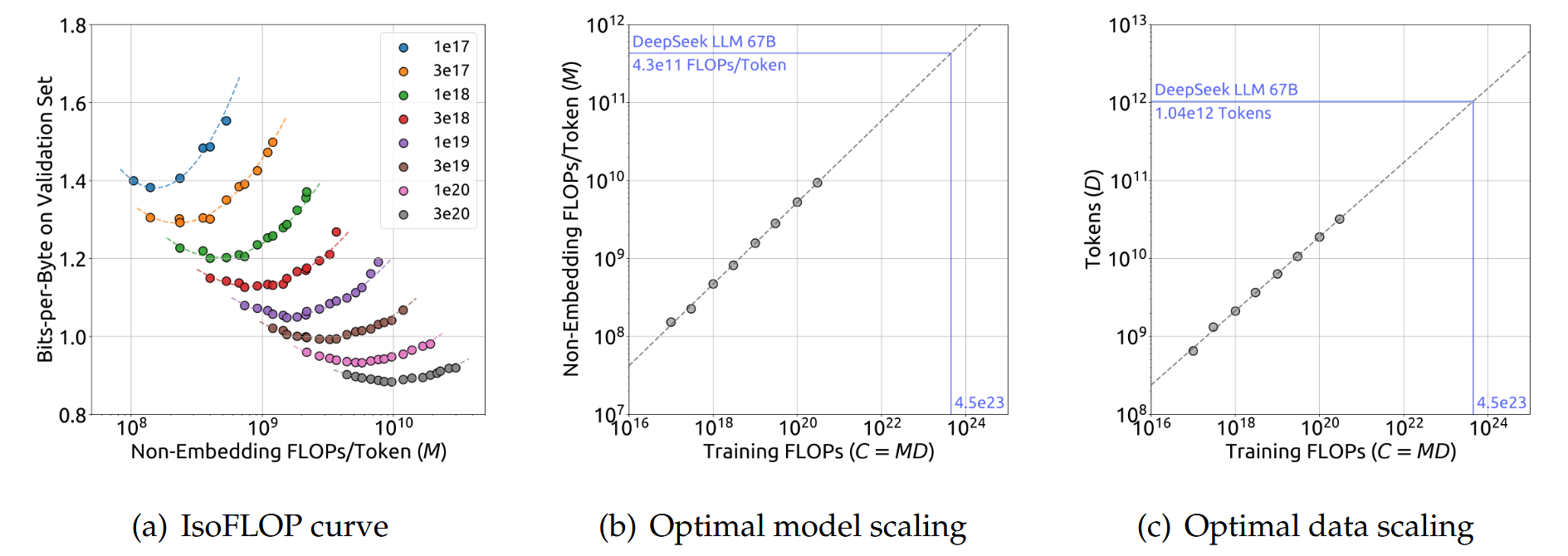
关于缩放定律的研究早于大型语言模型的涌现。缩放定律表明,随着计算预算(C)、模型规模(N)和数据规模(D)的增加,模型性能可以得到可预测的改善。当模型规模由模型参数表示,数据规模由token数表示时,C可以近似为 = 6ND。
为了降低实验成本和拟合难度,采用了Chinchilla中的IsoFLOP profile方法来拟合缩放曲线。为了更准确地表示模型规模,采用了一种新的模型规模表示方法,即非嵌入FLOPs/token-M,替换了先前使用的模型参数N,并将近似计算预算公式C = 6ND替换为更精确的C = MD。实验结果提供了关于最佳模型/数据扩展分配策略和性能预测的见解,并准确地预测了DeepSeek LLM 7B和67B模型的预期性能。
Alignment
收集了大约 150 万个中英文数据,涵盖了范围广泛且无害的主题。有用数据包含 120 万个实例,其中 31.2% 用于一般语言任务,46.6% 用于数学问题,22.2% 用于编码练习。安全数据由 300K 实例组成,涵盖各种敏感主题。
整体对齐流程包含两个阶段。
- SFT:对7B模型进行了4个epoch的微调,但对67B模型只进行了2个epoch的微调,因为观察到67B模型存在严重的过拟合问题。GSM8K和HumanEval在7B模型上得到了持续改进,而67B模型很快达到了上限。7B和67B模型的学习率分别为1e-5和5e-6。
- DPO:为了进一步提高模型的能力,作者使用了DPO算法,该算法被证明是一种简单而有效的LLM对齐方法。根据有用性和无害性构建了DPO训练所需的偏好数据。对于有用性数据,收集了多语言提示,涵盖了创意写作、问答、指令跟随等类别。然后,使用DeepSeek Chat模型作为候选响应生成响应。类似的操作也应用于无害性偏好数据构建。
模型评估
由于模型评估表格很多,这里直接用图大概看下DeepSeek LLM模型的表现
DeepSeek Math
Github: https://github.com/deepseek-ai/DeepSeek-Math
这部分主要介绍了强化部分将PPO改进为GRPO
详细可以参考 : GRPO(Group Relative Policy Optimization)
DeepSeek MoE
MoE for Transformers
首先先回顾下通用的transformer block的计算方式:
其中 \(T\) 表示序列长度(sequence length),\(\text { Self-Att }(·)\)表示自注意力模块(self-attention module),\(FFN(·)\) 表示前馈网络(Feed-Forward Network, FFN),\(\mathbf{u}^{l}{1:T}\in \mathbb{R}^{T\times d}\) 表示第 \(l\) 层注意力模块后所有 token 的隐藏状态(hidden states)。\(\mathbf{h}^{l}{t}\in \mathbb{R}^{d}\) 表示第 \(l\) 个 Transformer block 中第 \(t\) 个 token 的隐藏状态输出。为了简化表示,上面公式忽略了norm操作。
MOE层由多个专家组成,每个专家在结构上与标准FFN相同。然后,每个Token将分配给一个或两个专家。如果 第 \(l\) 层FFN用MOE层代替,则其输出的计算隐藏状态 \(\mathbf{h}^{l}_{t}\) 表示为:
其中, \(N\) 为专家(experts)的总数,\(g_{i,t}\) 为第 \(i\) 个专家的门控值(gate value),表示专家对输入的响应程度,\(s_{i,t}\) 表示输入和专家之间的亲和度(token-to-expert affinity)。\(Topk(\cdot, K)\) 表示从所有专家中选择出与输入亲和度最高的 \(K\) 个专家。\(e^l_i\) 为第 \(l\) 层中,第 \(i\) 个专家的中心值(centroid)。
DeepSeekMoE 结构
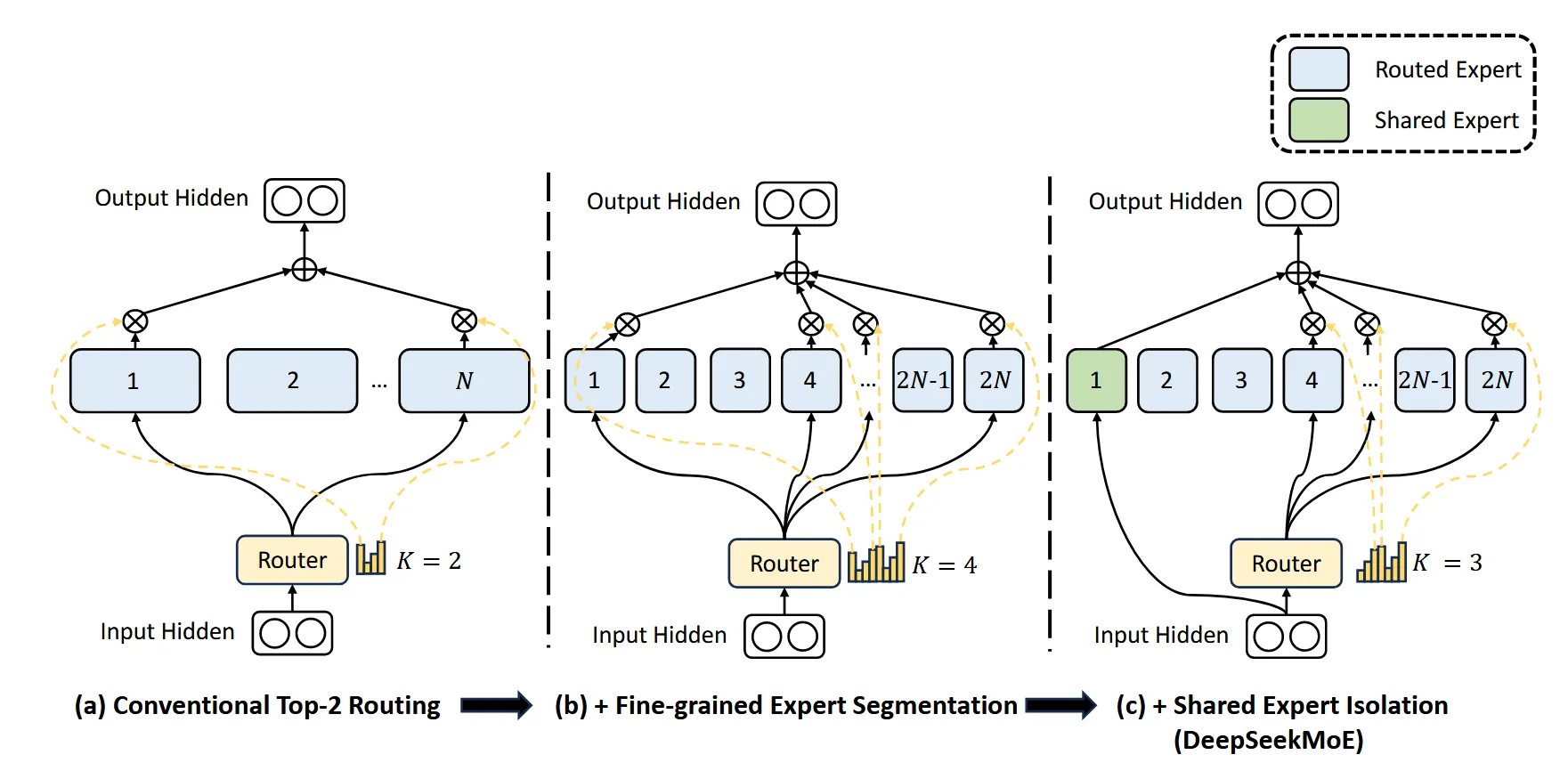
deepseekv1 的MoE主要是为了解决两个问题:
- 知识杂交性:此前很多MoE的工作用到的expert太少(通常是8或者16),导致很多expert不是真正的专家,而是杂糅了各种知识的混合体,所以并不能发挥expert的专业作用;
- 知识冗余性:不同专家训练的token很可能存在共同的知识,导致不同的expert会共享一些共通的知识,从而出现冗余,而模型整体容量有限,冗余就造成MoE模型整体性能下降;
而针对这两个问题,如上图所示,图a表示一个标准的MoE结构,deepseekv1主要做了两个优化。
- Fine-Grained Expert Segmentation
如图b所示,在整体参数量不变的情况下, 将FFN在latent维度切分成更多expert, 同时,保证计算量不变的情况下可以激活更多专家。(整个演变过程有点像conv -> group conv -> depthwise conv)。如下公式所示, deepseek-MoE相当于把expert的个数从 \(N\) 个提升为 \(mN\) 个, 同时激活的专家数量也从 \(k\) 个提升为 \(mk\) 个。
- Shared Expert Isolation
如图c所示,将某些expert抽出来,作为始终激活的专家, 由这些专家去学习共享的知识,从而降低模型整体的冗余。如下公式所示, 始终激活的专家为 \({k}_{s} \)个, 所以需要路由的专家就变成 \({mN} - {k}_{s}\),Topk就变成 \({mk} - {k}_{s} \)。
此外,MoE里遇到的一个通用问题就是负载均衡。主要是两种情况:
- 模型总是选择某些特定的expert,导致其他的大部分专家没有得到充分训练;
- 如果不同的专家位于不同的设备上,通信代价会超过计算瓶颈;
所以针对这两个问题,deepseek又分别设计了Expert-Level Balance Loss 和 Device-Level Balance Loss。
Expert-Level Balance Loss的公式如下,其中 \(N^{'}=mN-k_{s}\) 即去除共建专家之后路由专家的个数, \(K^{'}=mk-k_{s}\) 即激活的路由专家的个数,loss中乘以\(\frac{N^{'}}{K^{'}}\)这个归一化参数,为了保证loss的计算跟专家的数量解耦。
Device-Level Balance Loss的公式如下所示,其核心思想是把expert划分成不同的组,每一组expert在同一个设备上,然后负载均衡在组之间做。
最后还有一个细节,全文中的 \(T\) 即总token数,是一个batch里的总token数。
试验和性能评估
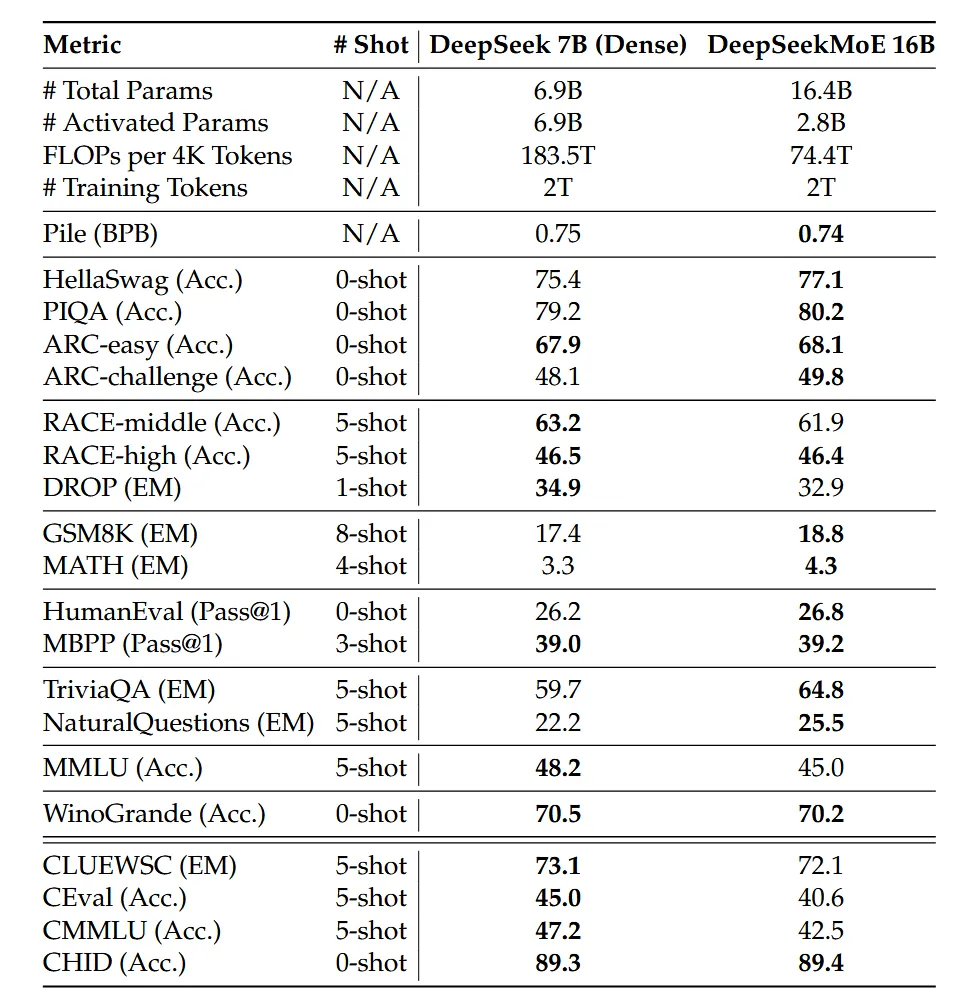
这里只是简单给个MoE 16B模型和Dense7B模型的对比
DeepSeek V2
Github: https://github.com/deepseek-ai/DeepSeek-V2
背景补充
这一节主要将回顾一下一些基础知识,因为DeepSeek-V2的主要创新点在:
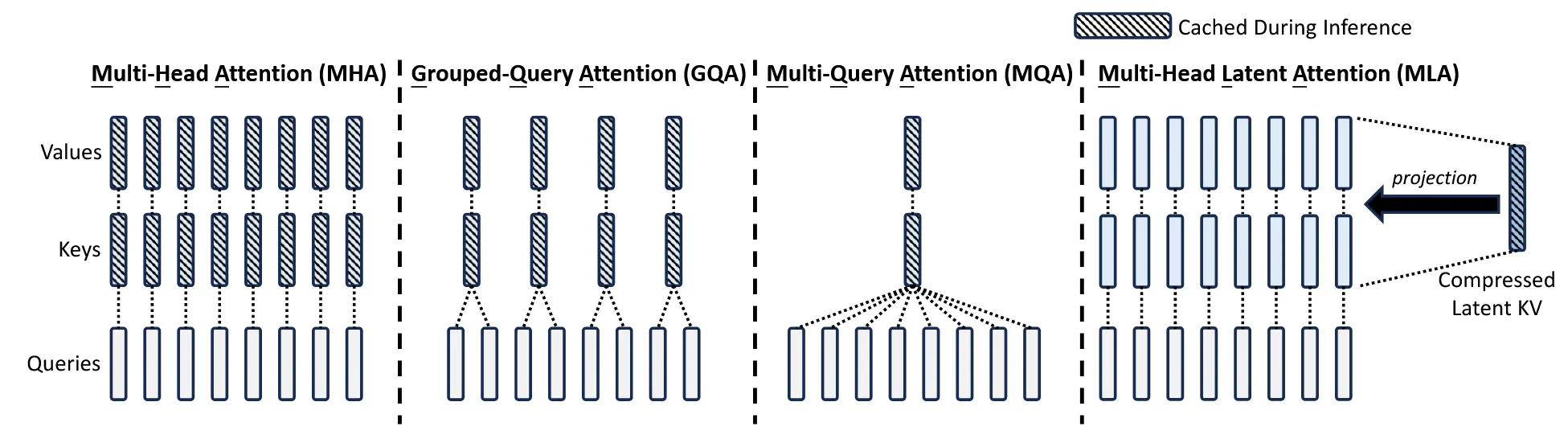
- MLA,即Multi Latent Attention,对传统多头注意力(Multi Head Attention)的改进,降低KV Cache开销。
- DeepseekMOE,改进了传统MOE结构。
所以,这一节将回顾KV Cache和传统MOE结构的基本原理。
KV Cache
KV Cache是大模型标配的推理加速功能,也是推理过程中,显存资源巨大开销的元凶之一。在模型推理时,KV Cache在显存占用量可达30%以上。

目前大部分针对KV Cache的优化工作,主要集中在工程上。比如著名的VLLM,基于paged Attention,最大限度地利用碎片化显存空间,从而提升了空间利用率。
但是这些方案并没有从根本上改变KV Cache占用空间巨大的问题。
我们先来看看KV Cache的基本原理,然后在文章后面详细介绍DeepSeek MLA机制时,再来看DeepSeek-V2是怎么解决这个问题的。
KV Cache基本原理
如果不熟悉Transformer 的生成过程,这部分推荐看看国外博主Jay Alammar的这篇文章:
🔖 https://jalammar.github.io/illustrated-gpt2/
我们先回到Transformer计算Attention的公式,
大模型的推理是一个自回归的过程,即一个从头到尾逐步生成的过程。下一步的输出,取决于上一步。
假如我们需要输出Robot must obey orders这四个字。

模型生成第一步Robot时,会接收一个特殊字符<s>,作为第一步的输入,然后输出Robot。接着将“<s> Robot”作为第二步的输入,生成must,以此类推,直到模型输出遇到最大长度限制,或者输出了停止字符,则停止输出过程。
我们来模拟一个输出过程中每一步全局的Masked Attention的计算过程。这里公式中忽略了 \(\sqrt{d_k}\) 以便展示。
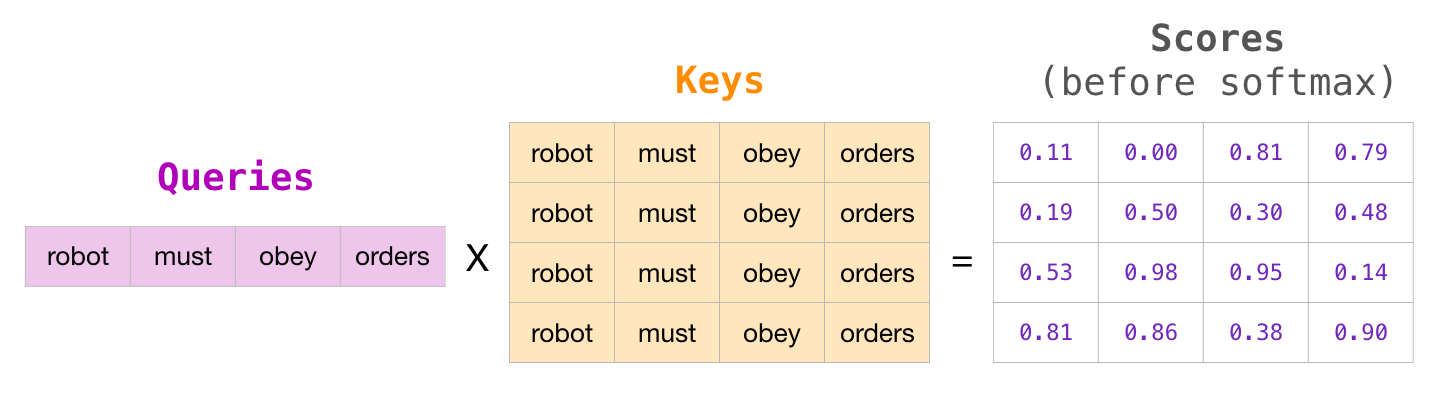
每一行代表一个查询向量与所有键向量的点积,但由于掩码的存在,每个查询只能访问它自己和之前的键(因果关系)。毕竟在生成的过程中,是不能看到后续的值的。
最后输出的softmax结果大概如下:

然后再将这个softmax结果,和对应的\(V\)值进行计算。在这个过程中,上面的矩阵计算,四行的Attention拆解下来如下,
我们可以发现这么一些规律:
- 每一个 \(Att_n\) 的计算,只取决于当前步的 \(Q_n\),不需要以前的 \(Q\)。
- 之前的 \(K\) 和\(V\),在后面会被重复利用。
那么这里就很清楚了,随着生成序列的增加,计算Attention的增多,前面步骤的\(K\)和\(V\)都需要参与后续的计算。
所以我们如果将之前的\(K\)和\(V\)都存储下来,就不用在当前这一步,再重新生成计算一次以前生成过的\(K\)和\(V\)。这就是KV Cache。一种空间换时间的做法。
所以可以看出,随着序列增长,需要存储的 \(K\) 和\(V\)逐渐增多,因此推理中产生的开销也会越大。
Multiple Latent Attention (MLA)
说完了背景知识,KV Cache和MOE,以及它们存在的一些问题。
我们可以来看看DeepSeek-V2对上述两个核心部分到底做了哪些改进。
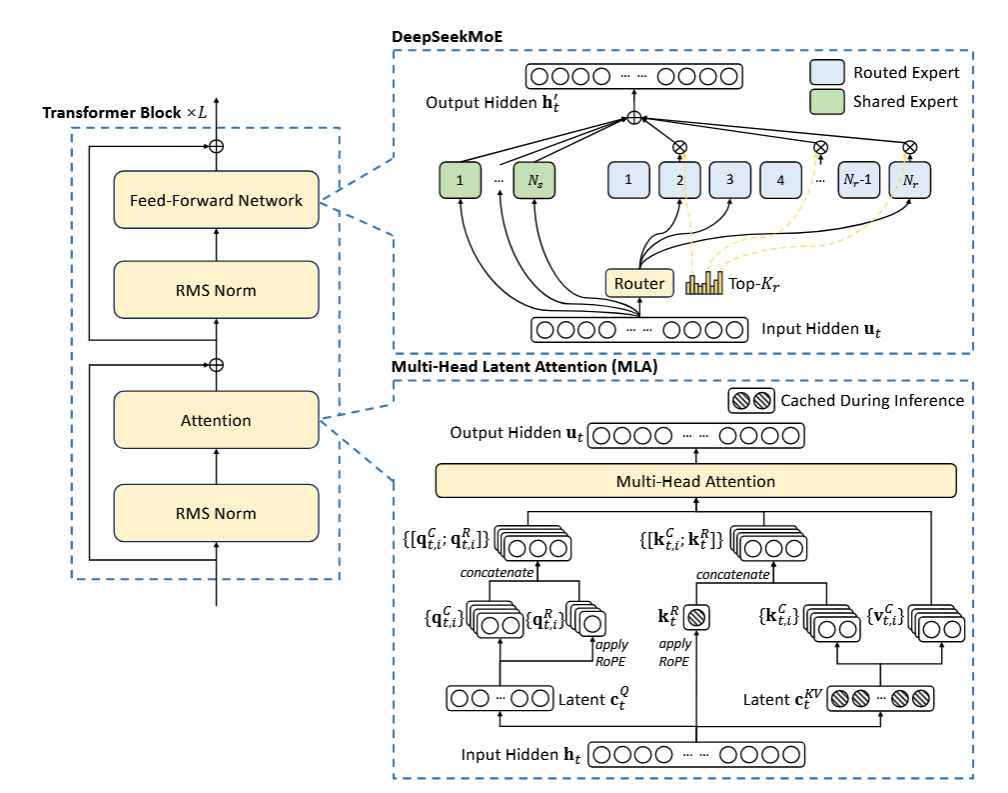
MLA是对传统多头注意力做的改进,其目的有两个:
- 降低推理过程中的KV Cache资源开销。
- 缓解MQA、MGA对性能的损耗。
首先来说第一点,之前介绍KV Cache中,提到每一步都需要将\(K\)和\(V\)缓存下来。假设单个Attention Block块中的多头注意力,有 \(n_h\) 个头,每个\(k\)和\(v\)的维度为\(d_h\),则每一步需要缓存的参数量为\(2n_hd_hl\),\(l\)为block的块数。
因此,MLA立足于在推理中,降低\(n_hd_h\)。对Key和Value进行了一个低秩联合压缩。
简单理解就是,假设有个矩阵的维度是\(n*n\),那么可以将其分解为两个 \(n*d\) 的矩阵相乘,而\(d≪n\) 。这样就降低了存储量。
具体来看看DeepSeek中的具体实现公式:
- \({c}_{t}^{K V}\in R^{d_c}\) 是对Key和Value压缩后的隐向量,通过一个降维映射矩阵 \(W^{DKV}\) 和模型输入 \(h_t\) 得到。\(c_t\) 的维度 \(d_c\),远小于多头key和value的原始维度 \(n_hd_h\)。
- 得到这个 \(c_t\) 后,具体的key和value,由两个对应的升维矩阵 \(W^{U K}\) 和 \(W^{U V}\) 还原。
在推理的过程中,只需要缓存每一步的\({c}_{t}^{K V}\),然后再计算还原回原始的 \(K\) 和 \(V\) 即可。由于 \(c_t\) 的维度远小于\(K\)、\(V\)。因此每一步token的推理产生的缓存由之前的\(2n_hd_hl\),变成\(d_cl\)。
💡 这里其实原文也提到了,在推理的过程中,其实不需要显示的计算 \(\mathbf{k}_{t}^{C}\)和 \(\mathbf{v}_{t}^{C}\),因为在做Attention时,\(W^{U K} \) 会被 \(W^Q\)吸收掉,\(W^{UV}\) 会被\(W^O\)吸收掉,具体来说,
注意力计算可以重写为:\[Attention(Q,K) = softmax(\frac{(W^Qh_t)(W^{UK}c_t^{KV})^T}{\sqrt{d_k}})\]这里可以将 \(W^Q\) 和 \(W^{UK}\) 合并为一个新的矩阵:\[W^{Q'}= W^QW^{UK}\]同理,对于Value部分:\[Output = Attention(Q,K)(W^{UV}c_t^{KV})\]可以将 \(W^O\) 和 \(W^{UV}\) 合并为:\[W^{O'} = W^OW^{UV}\]这样在推理时,我们可以:
1. 预先计算好 \(W^{Q'}\) 和 \(W^{O'}\)
2. 直接用压缩后的 \(c_t^{KV}\) 进行注意力计算
3. 避免了显式计算完整的Key和Value矩阵
这种矩阵吸收不仅节省了计算量,更重要的是配合压缩的 \(c_t^{KV}\),大大减少了KV cache的内存占用。
另外,之前提到KV Cache中,\(Q\)的作用只发生在当下,但是在模型训练的过程中,每个输入的token会通过多头注意力机制生成对应的query、key和value。这些中间数据的维度往往非常高,因此占用的内存量也相应很大。所以论文中也提到,为了降低训练过程中的激活内存activation memory,DeepSeek-V2还对queries进行低秩压缩,即便这并不能降低KV Cache。
对\(Q\)的压缩方式和\(K\)、\(V\)一致。
位置编码解耦
从架构图中发现,DeepSeek-V2的 \(q\) 和 \(k\) 各自都有2个部分。1个部分是刚刚解释过的压缩部分,而另外的1个部分,加上了RoPE位置编码。做了一个位置编码的解耦。
在RoPE的实现中,如果我们要让\(Q\)、\(K\)带上位置信息, 位置编码是通过复数旋转实现的。对于位置 \(m\) 的token,其Query和Key的计算变为:
其中RoPE操作可以表示为一个位置相关的旋转矩阵 \(R_m\):
因此,注意力计算变为:
关键问题在于:每个位置m的RoPE矩阵 \(R_m\) 是不同的, \(R_m\) 位于 \(W^Q\) 和 \(W^{UK}\) 之间, 并且矩阵乘法不满足交换律, 所以我们不能像之前那样简单地将 \(W^Q\) 和 \(W^{UK}\) 合并,因为:
这意味着:我们必须在推理时保持 \(W^Q\) 和 \(W^{UK}\) 分开, 对每个历史token位置都需要重新计算完整的Key, 从而无法利用压缩的 \(c_t^{KV}\) 直接计算注意力,这就失去了MLA的主要优势 - 通过矩阵吸收和KV压缩来提高推理效率。这是RoPE与低秩KV压缩不兼容的根本原因。
为了解决这个问题,Deepseek-V2设计了两个变量用于储存旋转位置编码的信息,将信息存储和旋转编码解耦开
最后将这四个变量分别拼接起来,形成带信息压缩的\(Q\)、\(K\),以及带位置信息的\(Q\)、\(K\),进行最后的计算。
最终,单个Token产生的缓存包含了两个部分,即 \((d_c+d_{h}^{R})l\)。

同时,与GQA和MQA相比,不同于MQA和GQA可能因合并或分组而丢失细节信息,MLA的压缩是基于保持尽可能多的原始信息的前提下进行的。这使得模型在执行注意力操作时,能够利用到更精确的信息,从而提高整体的性能。
DeepSeek MoE(v2)
DeepSeek V2 相对于V1版,对MoE模块主要在负载均衡上做了三方面升级
设备受限的专家路由机制(Device-Limited Routing)
随着LLM的size越来越大,对MoE模型的训练,一般要采用专家并行(expert parallelism)来分布式加载模型,也就是对于网络的一个MoE层的多个专家,分配到多个设备上,来并行训练。由于DeepSeek的MoE是做了细粒度专家的设计,通常专家会很多(V2模型的路由专家数有160个,激活专家6个)。我们知道在MoE层多专家的输入是一样的,由当前层的Self-Attention输出的隐层激活值作为MoE层的输入。如果被激活的专家分布在多个机器上,那么要把输入传输到多机器,势必会带来成倍的通讯成本。
为了解决这个问题,DeepSeekV2 引入了 设备受限的专家路由机制。具体说就是保证每个token的激活专家,最多分布到 \(M\) 个设备上( \(M\) 小于 \(TopK\) ),这样来控制通信成本。具体做法分2步:
- 对于每个token,首先选择门控分数最高的专家所在的 \(M\) 个设备
- 然后把 \(M\) 个设备上的所有专家作为备选集合,选择 \(TopK\) 个专家
DeepSeek实际验证出,当 \(M≥3\) 的时候,这种受限的选 \(TopK\) 的操作,与不受限的全局选 \(TopK \)的操作,模型效果上是大致相当的。所以在V2模型上,DeepSeek选择的 \(TopK=6 \) , \(M=3\)。
增加通信负载均衡loss(Communication Balance Loss )
通过上面设备受限的路由机制可以减轻从输入侧将数据分发到多设备,减少多扇出的通讯量。但是在设备接收侧可能还是会出现集中几个设备的专家被激活的问题,导致通信拥堵的问题。所以V2版模型,相对于V1版增加了个通信负载均衡的loss
其中, \(\mathcal E_i\) 表示第 \(i\) 个设备的一组专家, \(D\) 是设备数, \(M\) 是受限路由的设备数, \(T\) 是一个Batch的token数, \(\alpha3\) 是该辅助loss的超参。公式的计算过程与专家级负载均衡loss过程基本类似。对于 \(f_i^{''}\) 的计算,乘以 \(D\) 和 除以 \(M\) 也是为了保证loss不随设备的增减或限制路由配置而动态变化。
设备受限的专家路由机制和通信负载均衡loss,都是为了解决通信负载平衡的方法。不同的是:
设备受限的专家路由机制是在通信分发端确保分发的一个上限;而通信负载均衡loss是在通信接收端确保接收的平衡,鼓励每个设备接收等量的token。所以通过这两种方法,可以确保设备输入、输出的通信负载均衡。
设备级Token丢弃策略(Token-Dropping Strategy)
虽然多个负载均衡的loss(包括专家,设备,通信)能引导模型做通信和计算的平衡,但并不能严格做到负载均衡。为了进一步做计算的负载均衡。引入了设备级的Token丢弃策略。具体做法:
- 首先对于一个Batch输入token,算出每个设备的平均接收的token量,也就是设备的容量 $C$
- 对于每个设备实际分配的token量 \(T_d\) ,按照路由打分降序排列
- 如果 \(T_d \gt C\) 则将超过容量 \(C\) 的尾部token丢弃掉,不进行专家网络计算。
注:这里的丢弃Token,只是在单MoE层对token不做计算,但这个token会通过残差继续传入上层Transformer网络,参与计算。所以被丢弃的Token依然是有hidden_state表征的,只是这个表征不是专家输出+残差merge的结果,而是只有残差部分的结果。而且多层Transformer MoE的专家是不耦合的,在某些层可能丢弃,在另外一些层参与专家计算。
作者为了保持推理和训练的一致性,在训练阶段也保持有10%的样本是不做Token丢弃的,来保证在推理阶段不做token丢弃的效果。
其他细节
Training and Inference Efficiency
在我们对H800群集的实际训练中,对于每个万亿个Token进行训练,DeepSeek 67B需要300.6k GPU小时,而DeepSeek-V2只需172.8k GPU小时,即稀疏的DeepSeek-V2可以节省42.5%的训练成本。 DeepSeek 67b。
在具有8 H800 GPU的单个节点上,DeepSeek-V2实现了超过每秒50k Token的生成吞吐量,这是DeepSeek 67b的最大生成吞吐量的5.76倍。此外,DeepSeek-V2的及时输入吞吐量超过每秒100K Token。
Alignment
跟V1 相同 后续也用了SFT和强化做align,只不过这里强化用的不是DPO而是 DeepSeek Math中的Group Relative Policy Optimization (GRPO)
DeepSeek V3
github:https://github.com/deepseek-ai/DeepSeek-V3
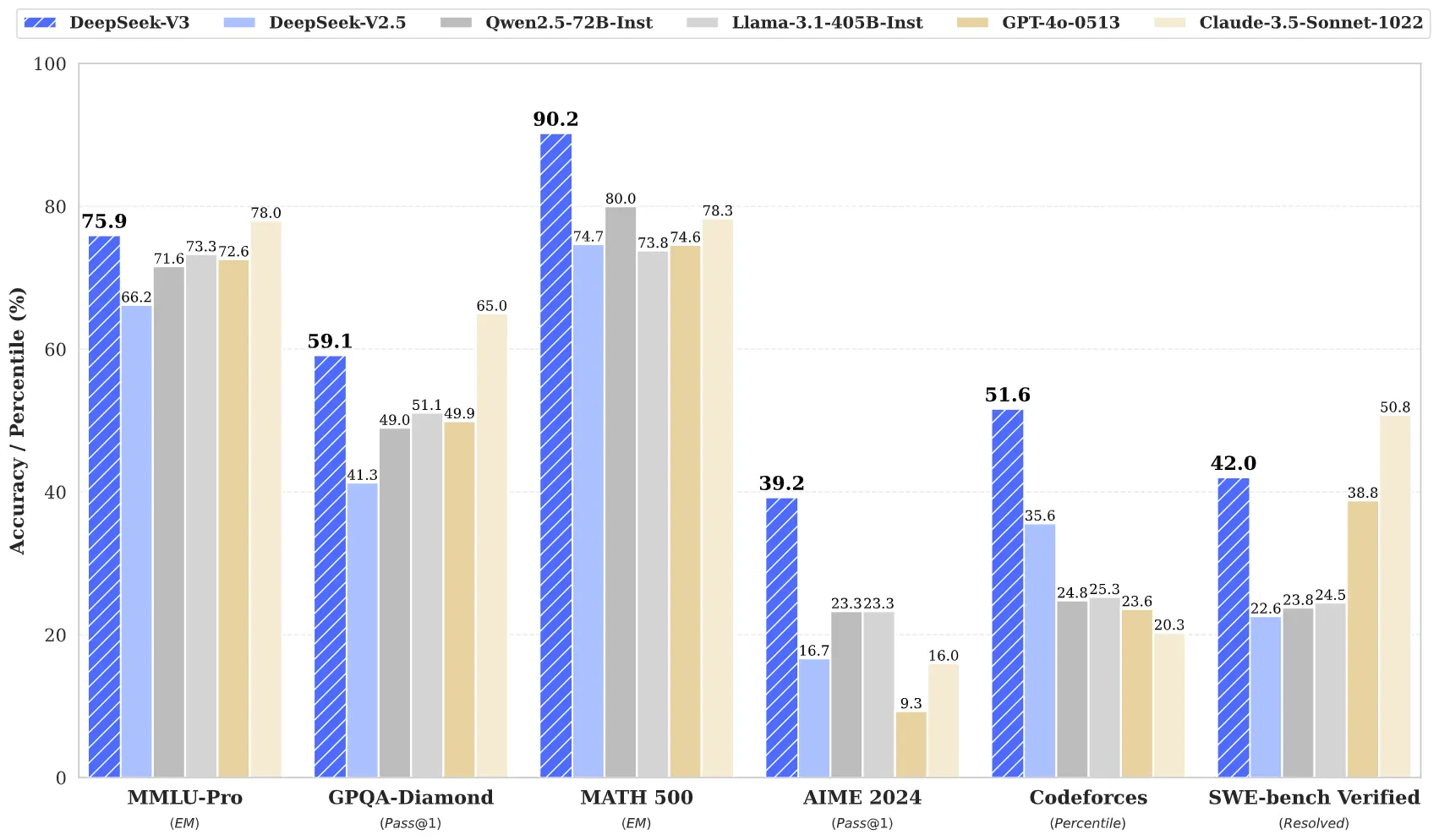
- 整体思路: 在 DeepSeek-V2 的基础上,通过引入新的架构和训练策略,进一步提升模型的性能,同时降低训练成本。
- 核心创新点:
- 无辅助损失的负载均衡策略: 通过引入偏置项动态调整专家负载,避免了传统辅助损失带来的性能损失。
- 多 Token 预测(MTP): 在每个位置预测多个未来的 token,增加训练信号,提高模型的数据效率。
- FP8 混合精度训练框架: 首次验证了 FP8 训练在超大规模模型上的可行性和有效性。
- 高效的训练框架: 通过 DualPipe 算法和优化的通信内核,实现了近乎零开销的跨节点通信。
- 从 DeepSeek-R1 中提炼推理能力: 将 DeepSeek-R1 的推理模式融入 DeepSeek-V3,提高了模型的推理性能。
- 灵感来源:
- 无辅助损失负载均衡: 该策略受到了 Wang et al.(2024a) 的研究启发,旨在最小化负载均衡对模型性能的负面影响。
- 多Token预测: 该策略受到了 Gloeckle et al.(2024) 的启发,旨在通过更密集的训练信号提高模型性能。
- FP8 混合精度训练: 该策略受到了 Dettmers et al.(2022) 等一系列低精度训练研究的启发,旨在加速训练并降低内存占用。
详情可以参考:DeepSeek v3
DeepSeek-R1
github:https://github.com/deepseek-ai/DeepSeek-R1
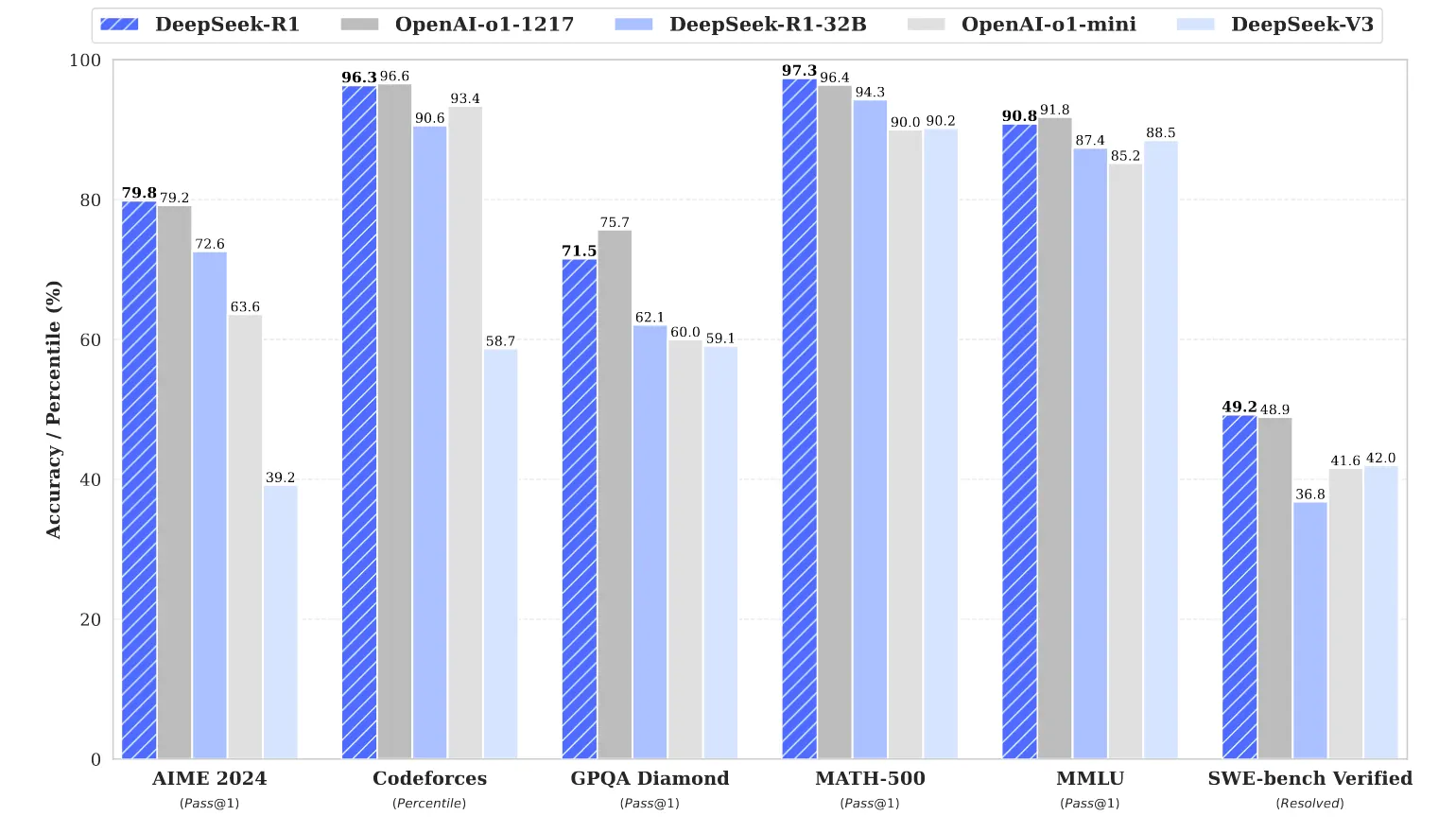
主要介绍了两个模型DeepSeek-R1 Zero 和DeepSeek R1,其中DeepSeek-R1 Zero 基于DeepSeek V3, 完全由大规模的RL(GRPO)的进行训练;而R1是由多个阶段组成 包含SFT和RL,得到的 DeepSeek-R1 模型在性能上与 OpenAI-o1-1217 相当。
详情可以参考:
DeepSeek-v3.2
DeepSeek-V3.2-Exp 是在 DeepSeek-V3.1-Terminus 的基础上通过持续训练引入 DeepSeek Sparse Attention (DSA) 的实验性模型。该模型核心目标是 在不显著牺牲性能的前提下,大幅提升训练与推理中的效率,尤其是应对最长至 128K tokens 的长上下文输入。
- DSA 将主模型的注意力复杂度从 \(\mathcal{O}(L^2) \) 降为 \(\mathcal{O}(Lk) \) ,极大地降低了 长序列上的成本。
- 在 H800 GPU 集群上测试显示,无论是在 prefilling 还是 decoding 阶段,单位 token 成本都有大幅下降。在 128K 长上下文下,单位 token 成本最高下降达 60%~70%。
稀疏注意力 DSA
标准的多头注意力 MHA 的复杂度是 \(\mathcal{O}(L^2) \) ,每个 Query Token 需要和历史的所有 Token 计算 Attention
而在 DeepSeek-v3.1 中采用的是 MLA(Multi-head Latent Attention,多头潜在注意力)结构,如下图所示:
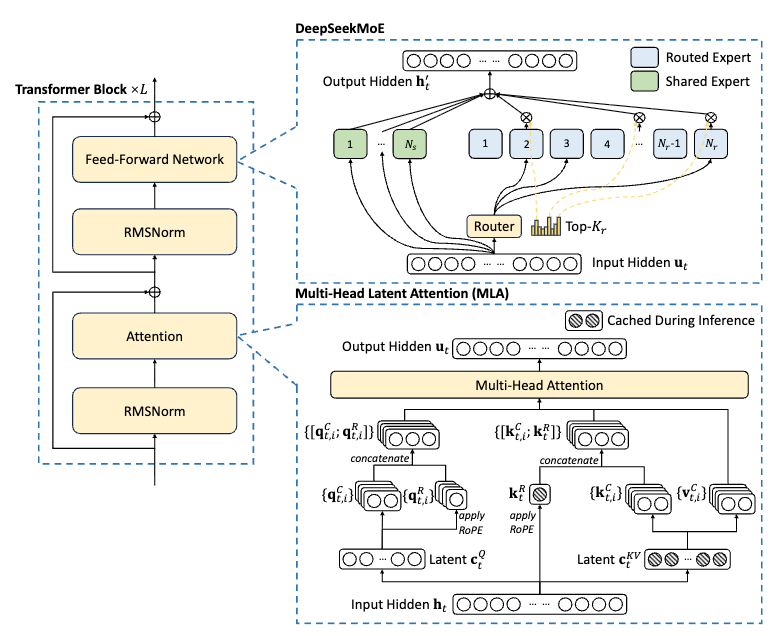
DeepSeek 此前提出的原生稀疏注意力(Native Sparse Attention, NSA)属于一种 Block-wise 的稀疏方案。与之不同,本次的 DSA 采用了一种更细粒度的 Token-wise 稀疏策略。其实现方式是在模型中引入一个轻量级的 Lightning Indexer,专门负责为每个 Query Token 动态地选取 Top-K 个最相关的 Key。
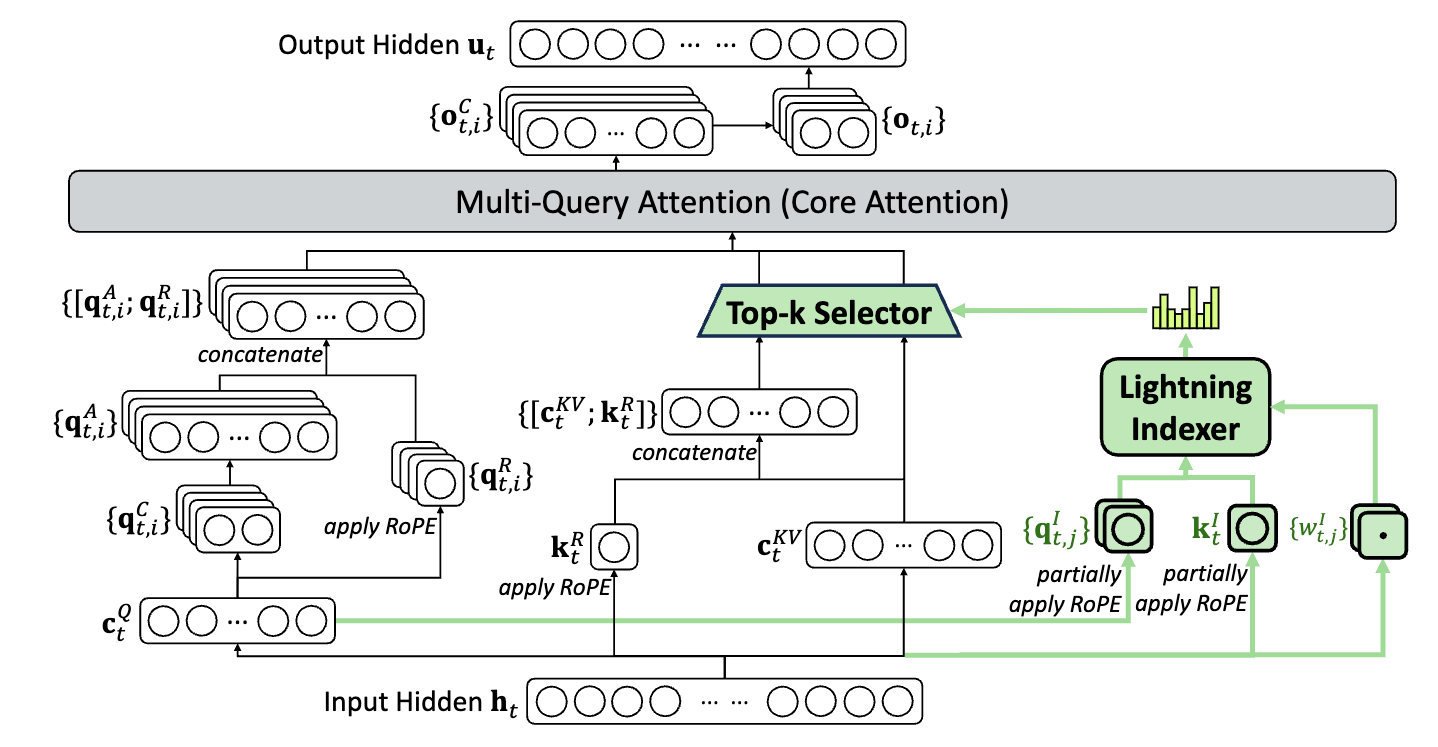
如图 3 所示,DeepSeek-V3.2-Exp 仅在 DeepSeek-V3 的基础上新增了 Lightning Indexer 模块,用于选择参与 Attention 的 Token。
该模块的主要输入是 Q 的低秩矩阵 \(\bm{c}_t^Q\) 与 MLA 的输入矩阵 \(\bm{h}_t\) ,输出则是每个 Token 所对应的 2048 个可参与 Attention 的历史 Token 索引。
被选中的 2048 个 Token 会在 MQA 的 Mask 阶段发挥作用:通过将未选中的位置的 Mask 值设为 INF,在经过 SoftMax 之后,就能有效去除不需要参与 Attention 的 Token。这样实现了高效的稀疏化,显著降低了计算量。
Lightning Indexer:轻量级 KV 选择器
Lightning Indexer是 DSA 的关键组件,用于为每个 query token 选出最相关的 key-value tokens,极大地减少计算量。
对于第 \(t\) 个 query token \(\bm{h}_t \in \mathbb{R}^d \) ,与历史上的每个 token \(\bm{h}_s \in \mathbb{R}^d \) 计算相关性得分:
- \(H^I\) :indexer 头数(固定为 64)
- \(\bm{q}^I_{t,j}\) :第 \(t\) 个 Token 在第 \(j\) 个索引头(Indexer Head)的 Query 向量
- \(\bm{k}^I_s\) :第 \(s\) 个 Token 的 Key 向量。值得注意的是,该 Key 向量只有一个,被所有 64 个索引头共享
- \(\bm{q}^I_{t,j}\) 和 \(\bm{k}^I_s\) 的维度均为 128
- \(w^I_{t,j} \) :可学习的标量权重。
- 使用 ReLU 激活而非 softmax,有利于 吞吐优化(FP8 实现)
从结构上看,Indexer 的 Q/K 计算过程与模型中的 MLA(Multi-head Latent Attention)非常相似,可以看作是一个 "微缩版" 的 MLA(其头数为 64 vs MLA 的 128,头维度为 128 vs MLA 的 576)。其计算量大约仅为 MLA 对应部分的 1/9,实现了高效的 Key 选择。
Fine-Grained Token Selection(细粒度选择)
基于上一步计算出的
\(I_{t,s}\)
,仅选取 top-k 的 key-value 进行 attention 计算:
- \(\bm{c}_s \) :原始 key-value entry
- 从 全序列 token 中选择 top-k 个最相关的 token,用于高效计算 attention 输出。
<br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br><br>训练
不同与NSA的原生训练,DeepSeek-V3.2-Exp的DSA是基于V3.1-Terminus续训的。
Continued Pre-Training
在 DeepSeek-V3.1-Terminus 的基础上,通过两个阶段的训练,将模型从 dense attention 平稳迁移至 DSA 架构下的 sparse attention,且保持性能稳定。
持续预训练包含两个阶段:
- Dense Warm-up Stage
- Sparse Training Stage
两个阶段都使用与 Terminus 相同的 128K 长上下文训练数据。
第一阶段:Dense Warm-up Stage(初始化 Lightning Indexer)
这是一个简短的预热阶段,旨在初始化 Lightning Indexer。在此阶段,模型仍采用原始的 dense attention,同时冻结除 Lightning Indexer 之外的所有参数。训练目标是使 Indexer 的打分输出与主注意力机制中的打分分布保持一致。
具体的:对于第 \(t\) 个query token,首先通过对主注意力的所有头的attention score进行求和。然后在序列维度上进行 L1 归一化,以产生一个目标分布:
Indexer 产生自身的评分 \(I_{t,:}\) ,对其进行 softmax,得到预测分布:
使用
KL 散度
衡量两者之间的差异,作为 Indexer 的训练目标:
在此Warm-up Stage,学习率设为 10⁻³ 。仅训练indexer 1000 步,每步包含 16 个 128K 长度的序列,总计处理 2.1 B tokens。
第二阶段:Sparse Training Stage(引入 Sparse Attention)
在此阶段引入细粒度 token 选择机制,并优化所有模型参数,以使模型适应 DSA 的稀疏模式。在此阶段,仍然保持将indexer输出与主注意力分布对齐,但只考虑被选中的token集 \(S_t = \left\{ s \mid I_{t,s} \in \text{Top-k}(I_{t,:}) \right\}\) :
需要注意的是,将 indexer 的输入从计算图中分离出来,以便进行独立优化。Indexer的训练信号仅来自
\(\mathcal{L}^I\)
,而主模型的优化仅依据语言建模损失。
Sparse Training Stage,学习率设为 7.3 × 10⁻⁶ ,并为每个query token选择2048个 key-value token。同时训练主模型和indexer 15000 步,每步包含 480个128K长度的序列,总计处理 943.7 B tokens。
Post-Training
DeepSeek-V3.2-Exp 的后训练阶段在流程、算法和数据上基本延续了 V3.1-Terminus,但在全程中采用了稀疏注意力机制。其核心方法包括:
- 专家蒸馏(Expert Distillation):针对数学、编程、推理、Agent 等多个专业领域,先分别微调出多个专家模型,然后利用这些专家生成高质量的领域数据,用于蒸馏出一个综合能力更强的统一模型。
- 混合强化学习训练(Mixed RL Training):采用 GRPO(Group Relative Policy Optimization)算法,将推理、Agent 能力和人类偏好对齐等多个目标统一纳入一个强化学习阶段,有效平衡各领域表现,同时避免多阶段训练常见的灾难性遗忘问题。
模型效果评估
多任务 Benchmark 对比
对比了两个模型在多个关键任务上的表现,涵盖 通用能力、搜索 agent、编程、代码 agent 和数学推理 五大类任务。
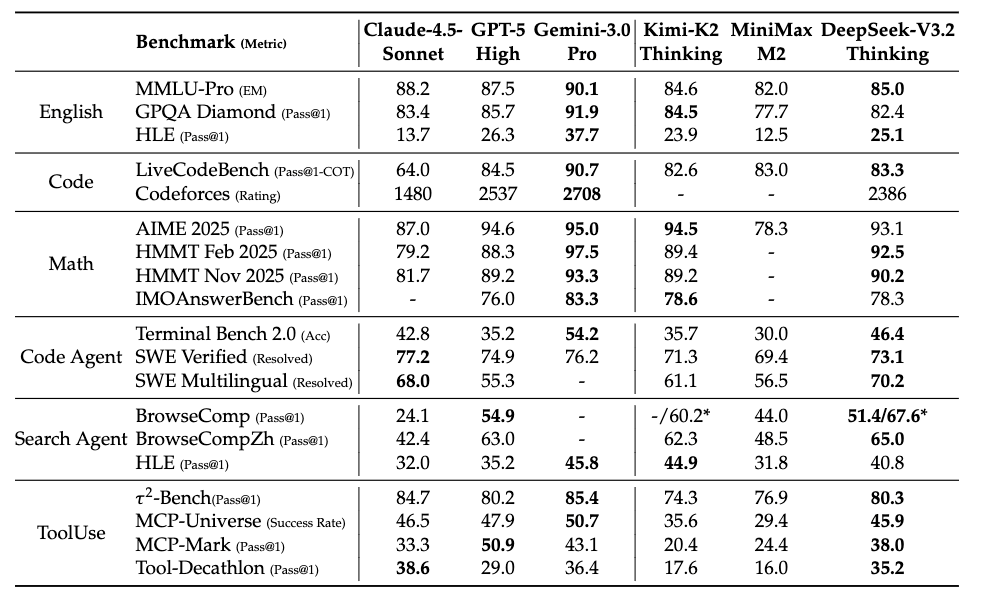
大部分任务持平或略优(如代码、搜索、数学),某些 reasoning-heavy benchmark(如 GPQA、HLE)略降。