总体流程

RPN
RPN在Extractor输出的feature maps的基础之上,先增加了一个3x3卷积,然后利用两个1x1的卷积分别进行二分类(是否为正样本)和位置回归。进行分类的卷积核通道数为9×2(9个anchor,每个anchor二分类,使用交叉熵损失),进行回归的卷积核通道数为9×4(9个anchor,每个anchor有4个位置参数)。
接下来RPN做的事情就是利用(AnchorTargetCreator)将20000多个候选的anchor选出2000个proposal并采样256个positive 进行分类和回归位置loss计算。具体过程如下:
proposal 前向过程中会做 NMS :
- 对所有 anchors 做前背景分类和bbox regression回归(learning offset)
- 对 foreground (iou>0.7) softmax scores由大到小排序anchors,提取 6000/12000(test/train) anchors(已经在上一步进行好了 coord reg)
- 限定超出图像边界的 foreground anchors 为图像边界(防止后续roi pooling时proposal超出图像边界)
- 剔除非常小的foreground anchors
- 进行 NMS(threshold=0.7)
- 提取 NMS 后的前300/2000(test/train) 个 fg anchor 结果作为proposal输出
- proposal 完了,但真的拿去train的box其实是128+128个。
这256个样本的采样过程如下:
- 对于每一个ground truth bounding box (gt_bbox),选择和它重叠度(IoU)最高的一个anchor作为正样本
- 对于剩下的anchor,从中选择和任意一个gt_bbox重叠度超过0.7的anchor,作为正样本,正样本的数目不超过128个(采样,不够的拿负样本填充)。
- 随机选择和gt_bbox重叠度小于0.3的anchor作为负样本。负样本和正样本的总数为256。
对于每个anchor, gt_label 要么为1(前景),要么为0(背景)计算分类损失用的是交叉熵损失,而计算回归损失用的是Smooth_l1_loss(它使得loss对于离群点更为鲁棒,L2的话它对离群点,异常值更敏感,容易发生梯度爆炸). 在计算回归损失的时候,只计算正样本(前景)的损失,不计算负样本的位置损失。
用了几次NMS
Faster R-CNN只用了三次,训练时只用了一次,在RPN;预测时的RPN和最终的结果
RPN中的特征金字塔网络
把特征图弄成多尺度的,然后固定每种特征图对应的anchor尺寸,很有意思。也就是说,作者在每一个金字塔层级应用了单尺度的anchor,{P2, P3, P4, P5, P6}分别对应的anchor尺度为{\(32^2\),\(64^2\) ,\(128^2\) ,\(256^2\),\(512^2\) },当然目标不可能都是正方形,本文仍然使用三种比例{1:2, 1:1, 2:1},所以金字塔结构中共有15种anchors。
Fast R-CNN 中的特征金字塔网络
Fast R-CNN 中很重要的是ROI Pooling层,需要对不同层级的金字塔制定不同尺度的ROI。
ROI Pooling层使用region proposal的结果和中间的某一特征图作为输入,得到的结果经过分解后分别用于分类结果和边框回归。
然后作者想的是,不同尺度的ROI使用不同特征层作为ROI pooling层的输入,大尺度ROI就用后面一些的金字塔层,比如P5;小尺度ROI就用前面一点的特征层,比如P4。那怎么判断ROI改用那个层的输出呢?这里作者定义了一个系数Pk,其定义为:
224是ImageNet的标准输入,k0是基准值,设置为5,代表P5层的输出(原图大小就用P5层),w和h是ROI区域的长和宽,假设ROI是112 * 112的大小,那么,意味着该ROI应该使用P4的特征层。k值应该会做取整处理,防止结果不是整数。
然后,因为作者把conv5也作为了金字塔结构的一部分,那么从前全连接层的那个作用怎么办呢?这里采取的方法是增加两个1024维的轻量级全连接层,然后再跟上分类器和边框回归,认为这样还能使速度更快一些。
Roi Pooling VS. Roi Align
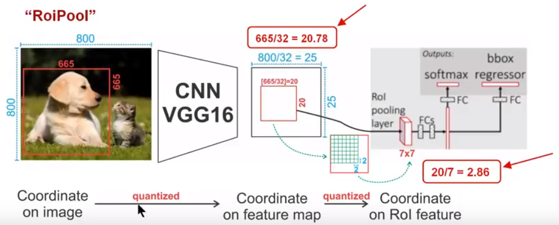
1)Conv layers使用的是VGG16,feat_stride=32(即表示,经过网络层后图片缩小为原图的1/32),原图800800,最后一层特征图feature map大小:2525
2)假定原图中有一region proposal,大小为665665,这样,映射到特征图中的大小:665/32=20.78,即**20.7820.78,如果你看过Caffe的Roi Pooling的C++源码,在计算的时候会进行取整操作,于是,进行所谓的第一次量化,即映射的特征图大小为20*20**
3)假定pooled_w=7,pooled_h=7,即pooling后固定成77大小的特征图,所以,将上面在 feature map上映射的2020的 region proposal划分成49个同等大小的小区域,每个小区域的大小20/7=2.86,即2.862.86,此时,进行第二次量化,故小区域大小变成**22**
4)每个2*2的小区域里,取出其中最大的像素值,作为这一个区域的‘代表’,这样,49个小区域就输出49个像素值,组成7**7大小的feature map
总结,所以,通过上面可以看出,经过两次量化,即将浮点数取整,原本在特征图上映射的2020大小的region proposal,偏差成大小为77的,这样的像素偏差势必会对后层的回归定位产生影响
所以,产生了替代方案,RoiAlign

1)Conv layers使用的是VGG16,feat_stride=32(即表示,经过网络层后图片缩小为原图的1/32),原图800800,最后一层特征图feature map大小:2525
2)假定原图中有一region proposal,大小为665665,这样,映射到特征图中的大小:665/32=20.78,即20.7820.78,此时,没有像RoiPooling那样就行取整操作,保留浮点数
3)假定pooled_w=7,pooled_h=7,即pooling后固定成77大小的特征图,所以,将在 feature map上映射的20.7820.78的region proposal 划分成49个同等大小的小区域,每个小区域的大小20.78/7=2.97,即2.97*2.97
4)假定采样点数为4,即表示,对于每个2.97*2.97的小区域,平分四份,每一份取其中心点位置,而中心点位置的像素,采用双线性插值法进行计算,这样,就会得到四个点的像素值,如下图
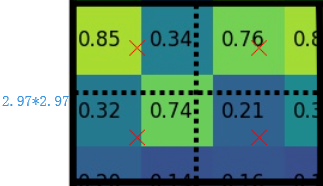
上图中,四个红色叉叉‘×’的像素值是通过双线性插值算法计算得到的
最后,取四个像素值中最大值作为这个小区域(即:2.972.97大小的区域)的像素值,如此类推,同样是49个小区域得到49个像素值,组成77大小的feature map
Roi pooling 和Roi Align 的反传
常规的ROI Pooling的反向传播公式如下:
这里,\(x_i\) 代表池化前特征图上的像素点;\(y_{r,j}\) 代表池化后的第 r 个候选区域的第 j 个点;\(i^*(r,j)\)代表点 \(y_{r,j}\) 像素值的来源(最大池化的时候选出的最大像素值所在点的坐标)。由上式可以看出,只有当池化后某一个点的像素值在池化过程中采用了当前点 \(x_i\) 的像素值(即满足\(i=i^*(r,j)\)),才在 \(x_i\) 处回传梯度。
类比于ROIPooling,ROIAlign的反向传播需要作出稍许修改:首先,在ROIAlign中,\(x_i^*(r,j)\)是一个浮点数的坐标位置(前向传播时计算出来的采样点),在池化前的特征图中,每一个与 **\(x_i^*(r,j)\) 横纵坐标均小于1的点都应该接受与此对应的点 \(y_{r,j}\) 回传的梯度**,故ROI Align 的反向传播公式如下:
上式中,\(d(.)\) 表示两点之间的距离,\(Δh\) 和 \(Δw\) 表示 \(x_i\) 与 \(x_i^*(r,j)\) 横纵坐标的差值,这里作为双线性内插的系数乘在原始的梯度上。