the machine predicts any parts of its input for any observed part
这是LeCun在AAAI 2020上对自监督学习的定义,再结合传统的自监督学习定义,可以总结如下两点特征:
- 通过“半自动”过程从数据本身获取“标签”;
- 从“其他部分”预测部分数据。
个人理解,其实任意挖掘对象之间联系、探索不同对象共同本质的方法,都或多或少算是自监督学习的思想。

自监督学习与无监督学习的区别主要在于,无监督学习专注于检测特定的数据模式,如聚类、社区发现或异常检测,而自监督学习的目标是恢复(recovering),仍处于监督学习的范式中。上图展示了三者之间的区别,自监督中的“related information” 可以来自其他模态、输入的其他部分以及输入的不同形式。
Self-Supervised Learning分成两种方法:一种是生成式模型,一种是判别式模型。以输入图片信号为例,生成式模型,输入一张图片,通过Encoder编码和Decoder解码还原输入图片信息,监督信号是输入输出尽可能相似。判别式模型,输入两张图片,通过Encoder编码,监督信号是判断两张图是否相似(例如,输入同一个人的两张照片,判断输入相似,输出1;输入两个人的照片,判断输入不相似,输出0)。
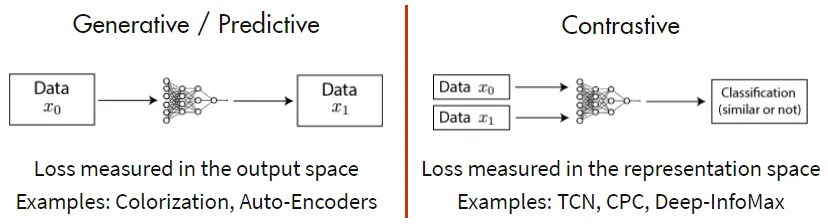
Generative Self-Supervised Learning
Auto-regressive (AR) Model
在自回归模型中,联合分布可以被分解为条件的乘积,每个变量概率依赖于之前的变量:
在自然语言处理中,自回归语言模型的目标通常是最大化正向自回归因子分解的似然。例如 GPT、GPT-2 使用 Transformer 解码器结构进行建模;在计算机视觉中,自回归模型用于逐像素建模图像,例如在 PixelRNN 和 PixelCNN 中,下方(右侧)像素是根据上方(左侧)像素生成的;而在图学习中,则可以通过深度自回归模型来生成图,例如 GraphRNN 的目标为最大化观察到的图生成序列的似然。
自回归模型的优点是能够很好地建模上下文依赖关系。然而,其缺点是每个位置的 token 只能从一个方向访问它的上下文。自回归模型可参考
Auto-encoding (AE) Model
自动编码模型的目标是从(损坏的)输入中重构(部分)输入。标准的自动编码器,首先一个编码器\( h=f_{enc}(x)\) 对输入进行编码得到隐表示 \(h\),再通过解码器 \(x^′=f_{dec}(h)\) 重构输入,目标是使得输入 \(x\) 和 \(x^′\) 尽可能的相近。
Denoising AE,去噪自动编码器
Denoising AE 认为网络生成的表示应该对引入的噪声具有鲁棒性,MLM(masked language model)就可以看作是去噪自动编码器模型,MLM 通过对序列中的 token 随机替换为 mask token,并根据上下文预测它们。同时为了解决下游任务中输入不存在 mask token 的问题,在实际使用中,替换 token 时可以选择以一定概率随机替换为其他单词或是保持不变。与自回归模型相比,在 MLM 模型中,所预测的 token 可以访问双向的上下文信息。然而,MLM 假设预测的 token 是相互独立的。
Variational AE,变分自动编码器
变分自动编码模型假设数据是从潜在变量表示中生成的。给定数据 \(X\),潜在变量 \(Z=\{z_1,z_2,...,z_n\}\) 上的后验分布 \(p(z|x)\) 通过 \(q(z|x)\) 来逼近。根据变分推断:
从自动编码器视角来看,第一项可以看作是正则化项保证后验分布 \(q(z|x)\) 逼近先验分布 \(p(z)\),第二项就是根据潜在变量重构输入的似然。VAE 在图像生成领域中有所应用,代表模型有向量量化 VAE 模型 VQ-VAE,而在图学习领域,则有变分图自动编码器 VGAE。
Hybrid model
结合 AR 模型和 AE 模型的各自优点,MADE 模型对 AE 做了一个简单的修改,使得 AE 模型的参数遵循 AR 模型的约束。具体来说,对于原始的 AE,相邻两层之间的神经元通过 MLPs 完全连接。然而,在 MADE 中,相邻层之间的一些连接被 mask 了,以确保输入的每个维度仅从之前的维度来重构。
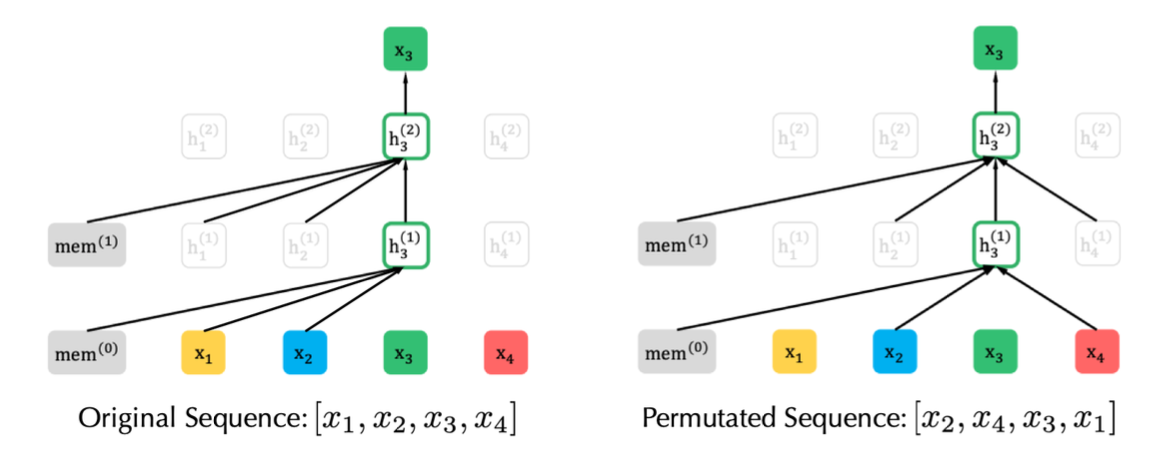
在 NLP 领域中,PLM(Permutation Language Model )模型则是一个代表性的混合方法,XLNet 引入 PLM,是一种生成自回归预训练模型。XLNet 通过最大化因数分解顺序的所有排列的期望似然来实现学习双向上下文关系(见上图)。具体的,假设 \(Z_T\) 是长度为 \(T\) 的所有可能的序列排序,则 PLM 的优化目标为:
实际上,对于每个文本序列,都采样了不同的分解因子。因此,每个 token 都可以从双向看到它的上下文信息。在此基础上,XLNet 还对模型进行了位置重参数化,使模型知道需要预测的位置,并引入了特殊的双流自注意机制来实现目标感知预测。此外,与 BERT 不同的是,XLNet 受到 AR 模型最新改进的启发,提出了结合片段递归机制和相对位置编码机制的 Transformer-XL 集成到预训练中,比 Transformer 更好地建模了长距离依赖关系。
Contrastive Self-supervised Learning
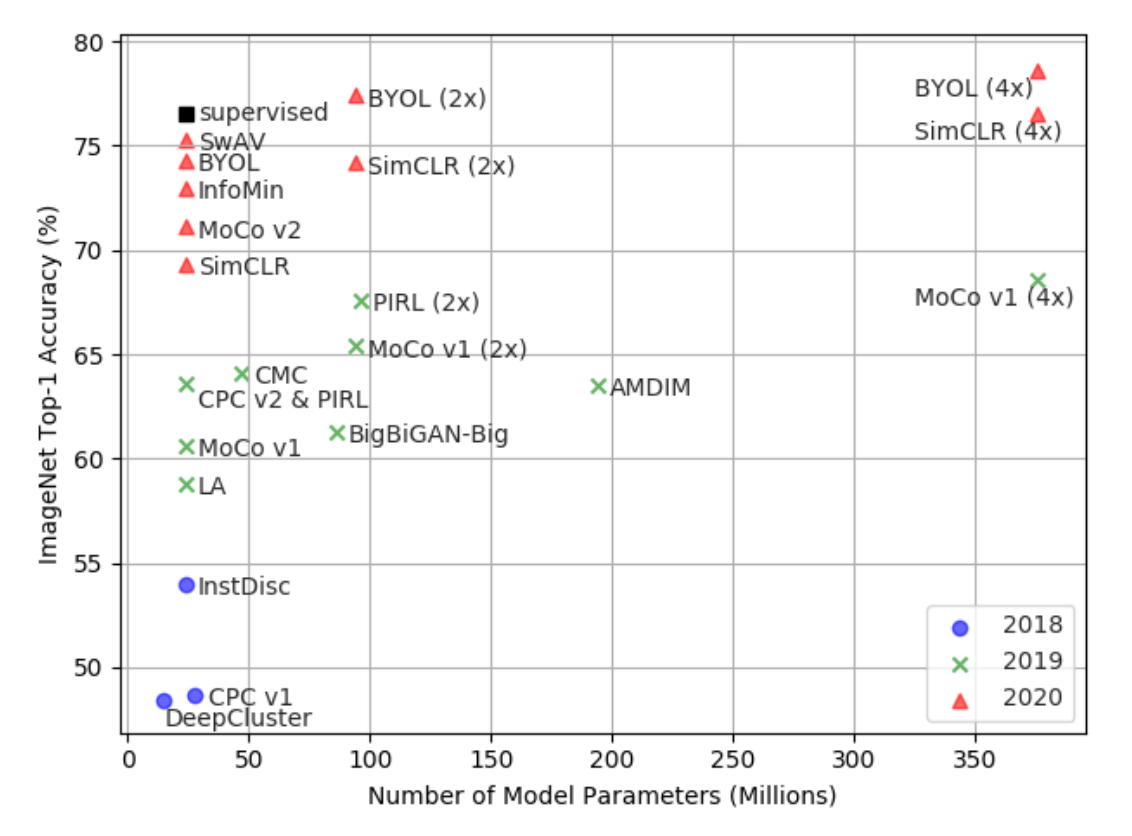
大多数表示学习任务都希望对样本 \(x\) 之间的关系建模。因此长期以来,人们认为生成模型是表征学习的唯一选择。然而,随着 Deep Infomax、MoCo 和 SimCLR 等模型的提出,对比学习(contrastive learning)取得了突破性进展,如下图所示,在 ImageNet 上,自监督模型的 Top-1 准确率已经接近监督方法(ResNet50),揭示了判别式模型的潜力。
对比学习的宗旨在于“learn to compare”,通过设定噪声对比估计(Noise Contrastive Estimation,NCE)来实现这个目标:
其中,\(x^+\)与 \(x\) 相似,而 \(x^−\) 与 x 不相似,\(f\) 是编码器函数(表示学习方程)。相似度量和编码函数可能会根据具体的任务有所不同,但是整体的框架仍然类似。当有更多的不相似样本对时,我们可以得到 InfoNCE:
具体推导可参考:
假定给定的 \((x,x^+)\) 是一对positive pair,比如同一个人的两张照片,同时你还有很多个负样本 ,比如其他人的照片,和x构成 \((x,x^-)\) negative pair。
这里需要一个数学先验知识,a向量与b向量同向,\(a\cdot b=|a||b|\);a向量与b向量垂直,\(a\cdot b=0\);a向量与b向量反向,\(a\cdot b=-|a||b|\)。所以当positive pair的方向尽可能相似,negative pair的方向尽可能不相似时,InfoNCE的值趋近于0。
上面是通过数学公式来理解InfoNCE的行为,下面通过unit hypersphere来理解InfoNCE的行为。
InfoNCE公式可以推导成两个部分,alignment和uniformity。
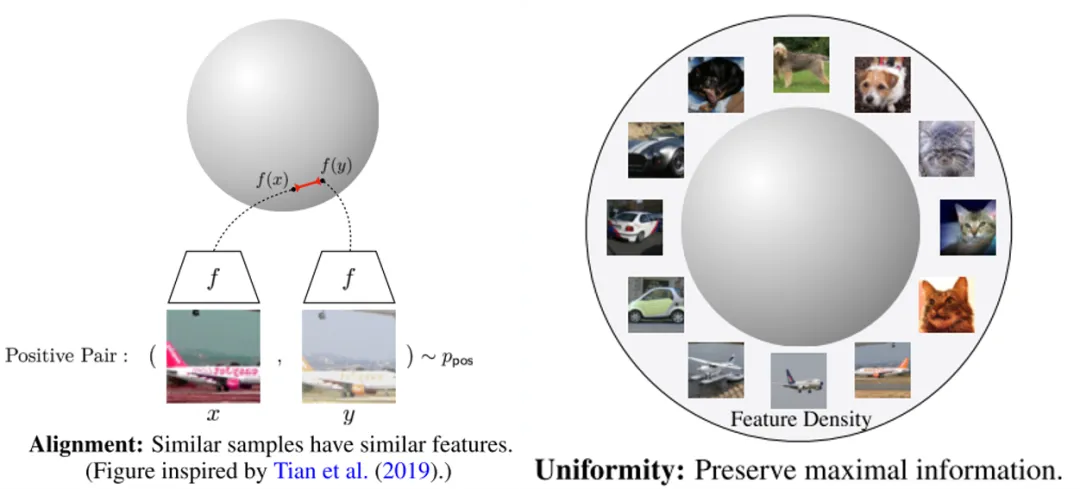
如上图所示,alignment部分只跟positive pair相关,希望positive pair的feature拉近,uniformity部分只跟negative pair相关,希望所有点的feature尽可能均匀分布在unit hypersphere上。
在这里,根据最近的对比学习模型框架,具体可细分为两大类:实例-上下文对比(context-instance contrast)和实例-实例对比(instance-instance contrast)。他们都在下游任务中有不俗的表现,尤其是分类任务。
Context-Instance Contrast
Context-Instance Contrast,又称为 Global-local Contrast,重点建模样本局部特征与全局上下文表示之间的归属关系,其初衷在于当我们学习局部特征的表示时,我们希望它与全局内容的表示相关联,比如条纹与老虎,句子与段落,节点与相邻节点。
这一类方法又可以细分为两大类:预测相对位置(Predict Relative Position,PRP)和最大化互信息(Maximize Mutual Information,MI)。两者的区别在于:1)PRP 关注于学习局部组件之间的相对位置。全局上下文是预测这些关系的隐含要求(例如,了解大象的长相对于预测它头和尾巴的相对位置至关重要);2)MI 侧重于学习局部组件和全局上下文之间的明确归属关系。局部之间的相对位置被忽略。
Predict Relative Position
许多数据蕴含丰富的时空关系,例如下图中,大象的头在其尾巴的右边,而在文本中,“Nice to meet you” 很可能出现在“Nice to meet you, too”的前面。许多模型都把识别其各部分之间的相对位置作为辅助任务(pretext task),下图中,预测两个 patch 之间的相对位置,或是预测图像的旋转角,又或者是“解拼图”。
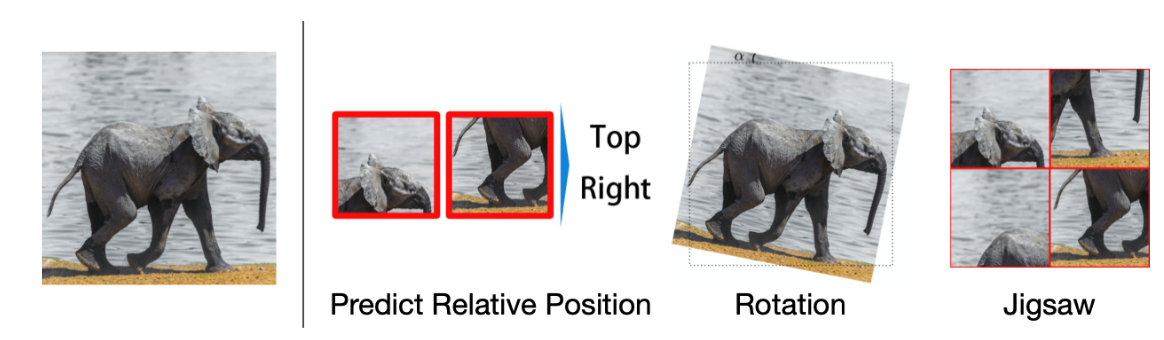
在 NLP 领域中,BERT 率先使用的 NSP(Next Sentence Prediction)也属于类似的辅助任务,NSP 要求模型判断两个句子是否具有上下文关系,然而最近的研究方法证明 NSP 可能对模型没什么帮助甚至降低了性能。为了替换 NSP,ALBERT 提出了 SOP(Sentence Order Prediction)辅助任务,其认为 NSP 中随机采样的句子可能来自不同的文章,主题不同则难度自然很低,而 SOP 中,两个互换位置的句子被认为是负样本,这使得模型将会集中在语义的连贯性学习。
Maximize Mutual Information
MI 类任务利用统计学中的互信息,通常来说,模型的优化目标为:
其中,\(g_i\) 表示表示编码器,\(G_i\) 则表示满足约束的一类编码器,\(I(⋅,⋅)\) 表示对于真实互信息的采样估计。在应用中,MI 计算困难,一个常见的做法是通过 NCE 来最大化互信息 \(I\) 的下界。
Deep Infomax(DIM) 是第一个通过对比学习任务显式建模互信息的算法,它最大化了局部 patch 与其全局上下文之间的 MI。在实际应用中,以图像为例,我们可以把一张狗的图像 \(x\) 编码为 \(f(x)∈R^{M×M×d}\),随后取出一个局部向量 \(v∈R^d\),为了进行实例和上下文之间的对比:
- 首先需要通过一个总结函数(summary function) \(g:R^{M×M×d}→R^d\),来生成上下文向量 \(s=g(f(x))∈R^d\)
- 其次需要一个猫图像作为 \(x^−\),并得到其上下文向量 \(s^−=g(f(x^−))\)
这样就可以得到对比学习的目标函数:
详请参考
Deep Infomax 给出了自监督学习的新范式,这方面工作较有影响力的跟进,最先有在 speech recognition 领域的 CPC 模型,CPC 将音频片段与其上下文音频之间的互信息最大化。为了提高数据利用效率,它需要同时使用几个负的上下文向量,CPC 随后也被应用到图像分类中。
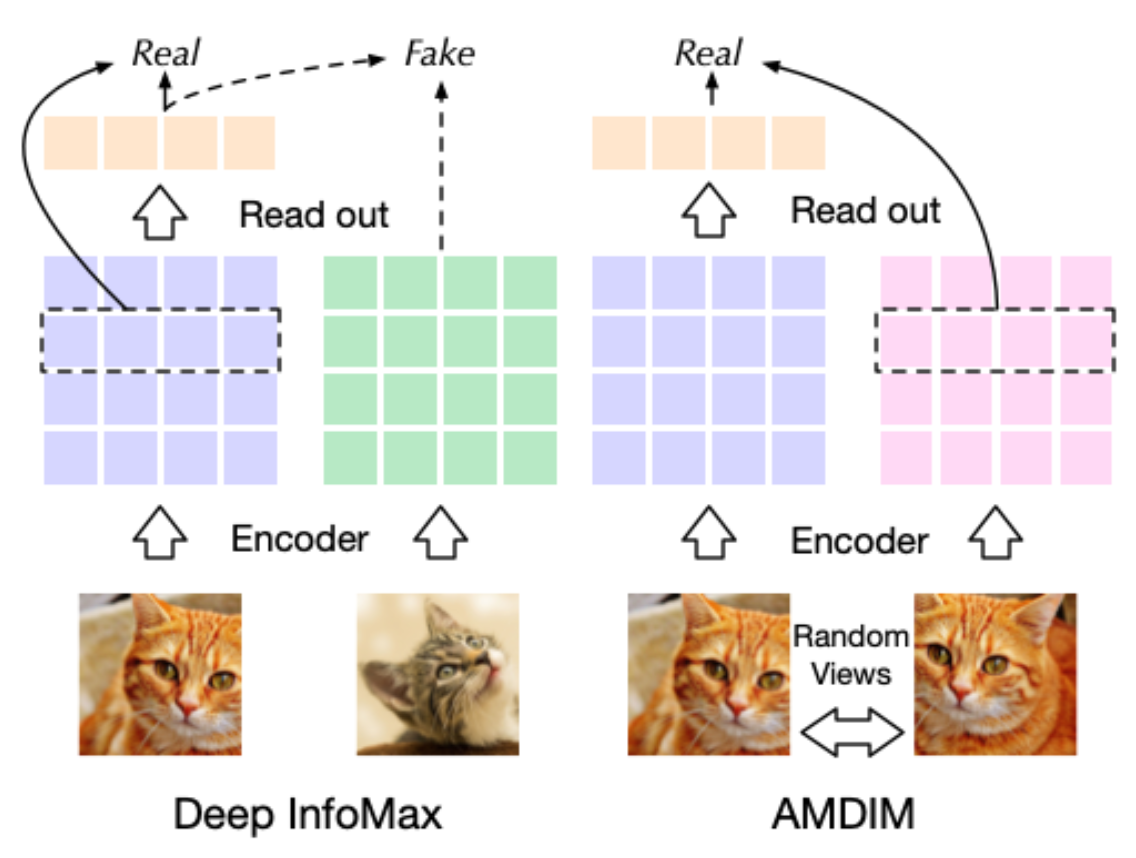
AMDIM 模型提出通过随机生成一张图像的不同 views(截断、变色等)用于生成局部特征向量和上下文向量,其与 Deep Infomax 的对比如下图所示,Deep Infomax 首先通过编码器得到图像的特征图,随后通过 readout(summary function)得到上下文向量,而 AMDIM 则通过随机选择图像的另一个 view 来生成上下文向量。
Instance-Instance Contrast
尽管基于最大化互信息的模型取得了成功,但是一些最近的研究对优化 MI 带来的实际增益表示怀疑。M Tschannen et al.证明基于最大化互信息的模型的成功与 MI 本身联系并不大。相反,它们的成功应该更多地归因于编码器架构和以及与度量学习相关的负采样策略。度量学习的一个重点是在提高负采样效率的同时执行困难样本采样(hard positive sampling),而且它们对于基于最大化互信息的模型可能发挥了更关键的作用。
而最新的相关研究 MoCo 和 SimCLR 也进一步证实了上述观点,它们的性能优于 context-instance 类方法,并通过 instance-instance 级的直接对比,相比监督方法取得了具有竞争力的结果。
Cluster-based Discrimination
instance-instance contrast 类的方法最早的研究方向是基于聚类的方法,DeepCluster 取得了接近 AlexNet 的成绩。图像分类任务要求模型正确地对图像进行分类,并且希望在同一个类别中图像的表示应该是相似的。因此,目标是在嵌入空间内保持相似的图像表示相接近。在监督学习中,这一目标通过标签监督来实现; 然而,在自监督学习中,由于没有标签,DeepCluster 通过聚类生成伪标签,再通过判别器预测伪标签。
最近,局部聚合(Local Aggregation, LA)方法已经突破了基于聚类的方法的边界。LA 指出了 DeepCluster 算法的不足,并进行了相应的优化。首先,在 DeepCluster 中,样本被分配到互斥的类中,而 LA 对于每个样本邻居的识别是分开的。第二,DeepCluster 优化交叉熵的判别损失,而 LA 使用一个目标函数直接优化局部软聚类度量。这两个变化在根本上提高了 LA 表示在下游任务中的性能。
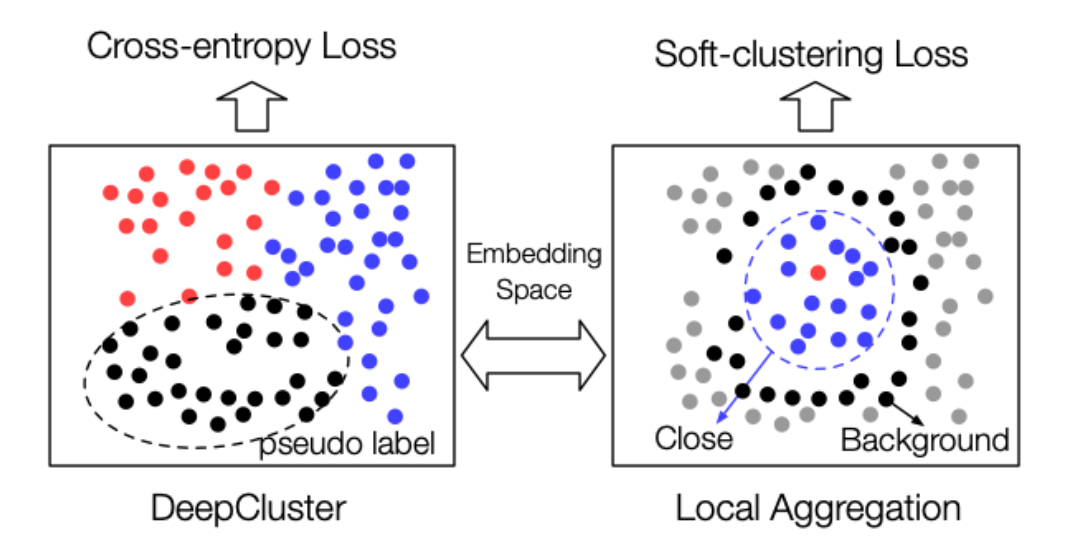
基于聚类的判别也可以帮助预训练模型提升泛化能力,更好地将模型从辅助任务目标转移到实际任务中。传统的表示学习模型只有两个阶段: 一个是预训练阶段,另一个是评估阶段。ClusterFit 在上述两个阶段之间引入了一个与 DeepCluster 相似的聚类预测微调阶段,提高了表示在下游分类评估中的性能。
Instance Discrimination
以实例判别(instance discrimination)作为辅助任务的模型原型是 InstDisc,在其基础之上,CMC 提出将一幅图像的多个不同 view 作为正样本,将另一幅图像作为负样本。在嵌入空间中,CMC 将使一幅图像的多个 view 尽可能靠近,并拉开与其他样本的距离。然而,它在某种程度上受到了 Deep InfoMax 思想的限制,仅仅对每个正样本采样一个负样本。
在 MoCo 中,通过 momentum contrast 进一步发展了实例判别的思想,MoCo 极大的增加了负样本的数量。对于一个给定的图像 \(x\),MoCo 希望通过一个 query encoder \(f_q(⋅)\) 得到一个可以区分于任何其他图像的 instinct 表示 \(q=f_q(x)\)。因此,对于其他图像集中的 \(x_i\),异步更新 key encoder \(f_k(⋅)\) ,并优化下面的目标函数:
其中,\(K\) 表示负样本的数量,这个式子就是 InfoNCE 的一种表达。具体细节参考
PIRL 添加了上述提到的”解拼图“的困难正样本(hard positive example)增强。为了产生一个 pretext-invariant 的表示,PIRL 要求编码器把一个图像和它的拼图作为相似的对。
在 SimCLR 中,作者通过引入 10 种形式的数据增强进一步说明了困难正样本(hard positive example)策略的重要性。这种数据增强类似于 CMC,它利用几个不同的 view 来增加正对。SimCLR 遵循端到端的训练框架,而不是 MoCo 的 momentum contrast,为处理大规模负样本问题,SimCLR 选择将 batch 大小 N 扩展为 8196。具体细节参考