概括
- 针对一些网络在处理point cloud时的缺点,如:不能对点的空间分布进行建模(例如PointNet++,只是能获取局部信息不能得到局部区域之间的空间关系),提出了SO-Net。SO的含义是利用Self-organizing map的Net。
- 结果:它具有能够对点的空间分布进行建模、层次化特征提取、可调节的感受野范围的优点,并能够用于多种任务如重建、分类、分割等等。取得了相似或超过SOTA的性能,因为可并行化和架构简单使得训练速度很快。
- 贡献:
- TODO IDEA:作者发现将CNN直接用于SOM图上性能不升反降,为什么(推测:可能是SOM的2D map并不是保持了原本的空间对应关系,可能nodes之间是乱序的,导致用conv2d时精度反而降低)?
难点
如何对local regions之间的空间关系进行建模?举个例子,即怎么显式地知道region A在region B的左边?
额外的Knowledge
- 该文Related Work里对点云处理的“综述”比较详尽,怒赞!!!
- SOM
思想
- 点云的空间分布编码:使用SOM中nodes自带的拓扑结构实现
- 交叠感受野且可调:使用“point-to-node kNN search”,使得感受野大概率交叠,并且感受野大小受超参数控制。
- 无序化:使用作者提出改进的SOM即“Permutation Invariant SOM”,使得SOM的result对输入数据的顺序弱化至无。
做法
- Permutation Invariant SOM
- Encoder Architecture
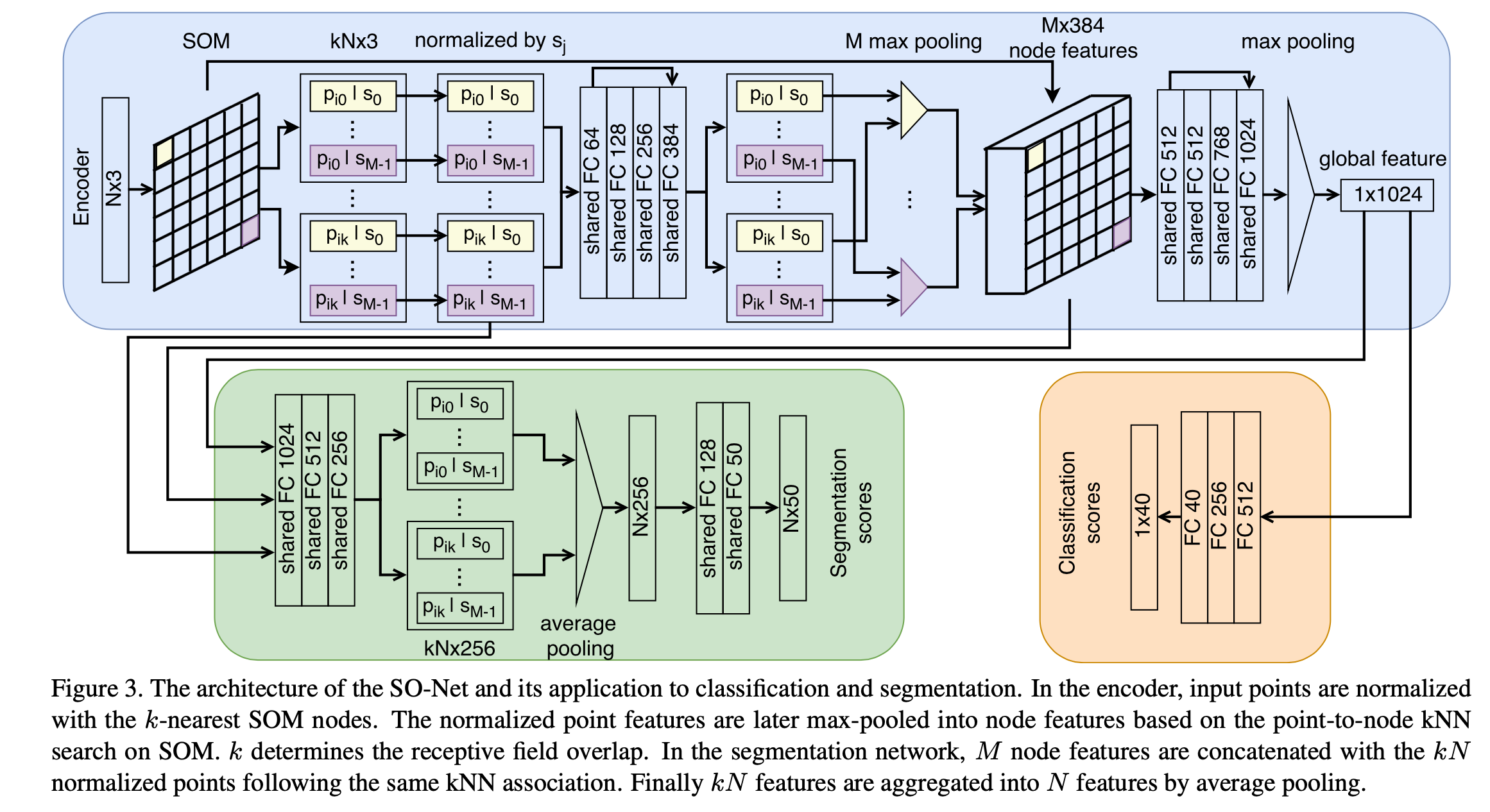
网络结构如上。
总地来说就是,先计算SOM得到\(s_j\),然后计算\(p_{ik}\),接着将\(p_{ik}\)输入MLP得到变换后的\(p_{ik}^l\),接着对\(p_{ik}^l\)作max pooling得到\(s_j^0\),与原本的cancat使得node features“变长”(在图中表示就是那个网格拥有depth了),接着对SOM nodes作MLP再max pooling得到global feature。
segmentation与classification略去不说。
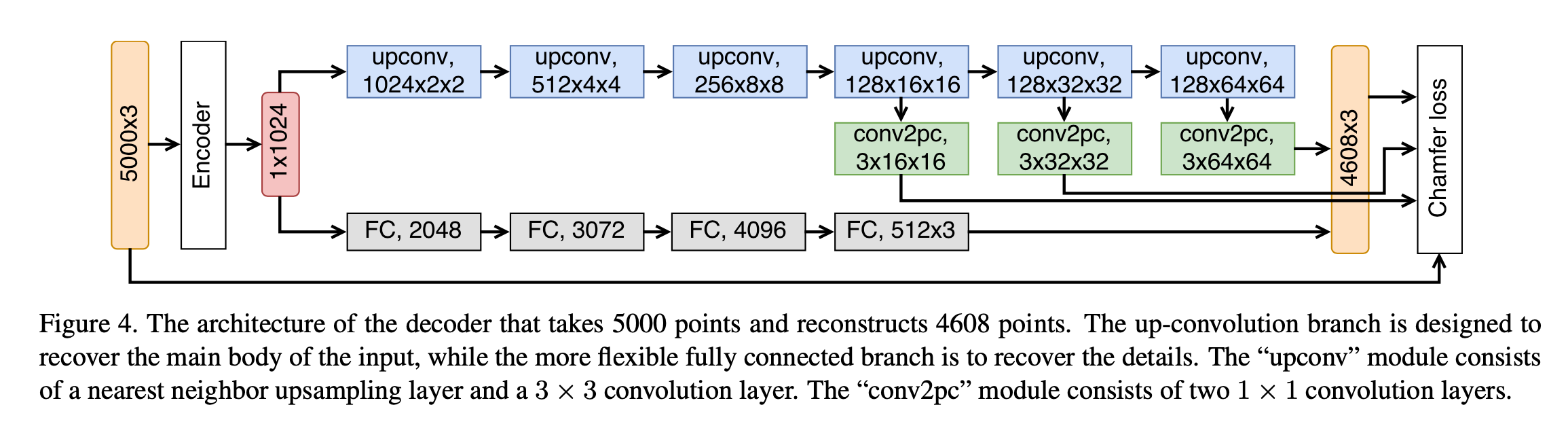
AutoEncoder