🔖 https://stability.ai/news/stable-diffusion-3-research-paper
概述
SD3 模型与训练策略改进细节
SD3除了将去噪网络从 U-Net 改成 DiT 外,SD3 还在模型结构与训练策略上做了很多小改进:
- 改变训练时噪声采样方法
- 将一维位置编码改成二维位置编码
- 提升 VAE 隐空间通道数
- 对注意力 QK 做归一化以确保高分辨率下训练稳定
本文会简单介绍这些改进。
论文阅读
核心贡献
介绍 Stable Diffusion 3 (SD3) 的文章标题为 Scaling Rectified Flow Transformers for High-Resolution Image Synthesis。与其说它是一篇技术报告,更不如说它是一篇论文,因为它确实是按照撰写学术论文的一般思路,将正文的叙述重点放到了方法的核心创新点上,而没有过多叙述工程细节。正如其标题所示,这篇文章的内容很简明,就是用整流 (rectified flow) 生成模型、Transformer 神经网络做了模型参数扩增实验,以实现高质量文生图大模型。
由于这是一篇实验主导而非思考主导的文章,论文的开头没有太多有价值的内容。从我们读者学习论文的角度,文章的核心贡献如下:
从方法设计上:
- 首次在大型文生图模型上使用了整流模型。
- 用一种新颖的 Diffusion Transformer (DiT) 神经网络来更好地融合文本信息。
-
使用了各种小设计来提升模型的能力。如使用二维位置编码来实现任意分辨率的图像生成。
从实验上: -
开展了一场大规模、系统性的实验,以验证哪种扩散模型/整流模型的学习目标最优。
- 开展了扩增模型参数的实验 (scaling study),以证明提升参数量能提升模型的效果。
整流模型
Rectified Flow 可以参考这里
文章也是通过设计一个通用的Loss 公式(兼顾diffusion和flow matching 等方法):
其中, \({w}_{t} = - \frac{1}{2}{\lambda }_{t}^{\prime }{b}_{t}^{2}\) 时对应于\({\mathcal{L}}_{CFM}\).
对于 Rectified Flow Model , 对应
对应上面公式 1 中 \({w}_{t}^{\mathrm{{RF}}} = \frac{t}{1 - t}\) .
非均匀训练噪声采样
在学习这种生成模型时,会随机采样一个时刻 \(t \in [0, 1]\),并根据公式获取此时刻对应位置在生成路径上的速度(velocity field)。神经网络的任务是学习如何预测这个速度。在生成路径中,靠近起点(目标数据分布)和终点(噪声分布)的区域相对容易学习,因为起点附近数据的结构清晰,终点附近噪声特征简单。而路径的中间部分(即 \(t \approx 0.5\) 的区域)由于数据和噪声的混合程度较高,预测难度更大。因此,为了让模型更好地学习中间部分的生成路径,SD3 使用了一种非均匀采样分布 \(\pi(t)\),对中间的时间点赋予更高的采样概率,从而增强模型在这一部分的学习效果。
如下图所示,SD3 主要考虑了两种公式: mode(左)和 logit-norm (右)。二者的共同点是中间多,两边少。mode 相比 logit-norm,在开始和结束时概率不会过分接近 0。
logit-norm的公式如下所示:
在实际使用中,作者首先从\(u\sim\mathcal{N}(u;m,s)\)采样\(u\),再通过标准logitstic函数生成,下面是对应的mode采样

网络整体架构
以上内容都是和训练相关的理论基础,下面我们来看多数用户更加熟悉的文生图架构。
从整体架构上来看,和之前的 SD 一样,SD3 主要基于隐扩散模型(latent diffusion model, LDM)。这套方法是一个两阶段的生成方法:先用一个 LDM 生成隐空间低分辨率的图像,再用一个自编码器把图像解码回真实图像。
扩散模型 LDM 会使用一个神经网络模型来对噪声图像去噪。为了实现文生图,该去噪网络会以输入文本为额外约束。相比之前多数扩散模型,SD3 的主要改进是把去噪模型的结构从 U-Net 变为了 DiT。
提升自编码器通道数
在当时设计整套自编码器 + LDM 的生成架构时,SD 的开发者并没有仔细改进自编码器,用了一个能把图像下采样 8 倍,通道数变为 4 的隐空间图像。比如输入 \(512 \times 512 \times 3\) 的图像会被自编码器编码成 \(64 \times 64 \times 4\)。而近期有些工作发现,这个自编码器不够好,提升隐空间的通道数能够提升自编码器的重建效果。因此,SD3 把隐空间图像的通道数从 4 改为了 16。
多模态 DiT (MM-DiT)
SD3 的去噪模型是一个 Diffusion Transformer (DiT)。如果去噪模型只有带噪图像这一种输入的话,DiT 则会是一个结构非常简单的模型,和标准 ViT 一样:图像过图块化层 (Patching) 并与位置编码相加,得到序列化的数据。这些数据会像标准 Transformer 一样,经过若干个子模块,再过反图块层得到模型输出。DiT 的每个子模块 DiT-Block 和标准 Transformer 块一样,由 LayerNorm, Self-Attention, 一对一线性层 (Pointwise Feedforward, FF) 等模块构成。
图块化层会把 \(2\times 2\) 个像素打包成图块,反图块化层则会把图块还原回像素。

然而,扩散模型中的去噪网络一定得支持带约束生成。这是因为扩散模型约束于去噪时刻 。此外,作为文生图模型,SD3 还得支持文本约束。DiT 及本文的 MM-DiT 把模型设计的重点都放在了处理额外约束上。
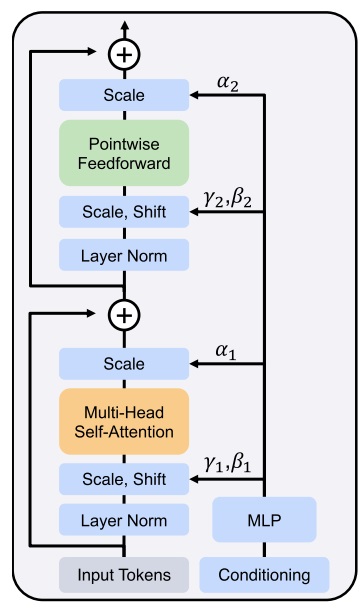
我们先看一下模块是怎么处理较简单的时刻约束的。此处,如下图所示,SD3 的模块保留了 DiT 的设计,用自适应 LayerNorm (Adaptive LayerNorm, AdaLN) 来引入额外约束。具体来说,过了 LayerNorm 后,数据的均值、方差会根据时刻约束做调整。另外,过完 Attention 层或 FF 层后,数据也会乘上一个和约束相关的系数。
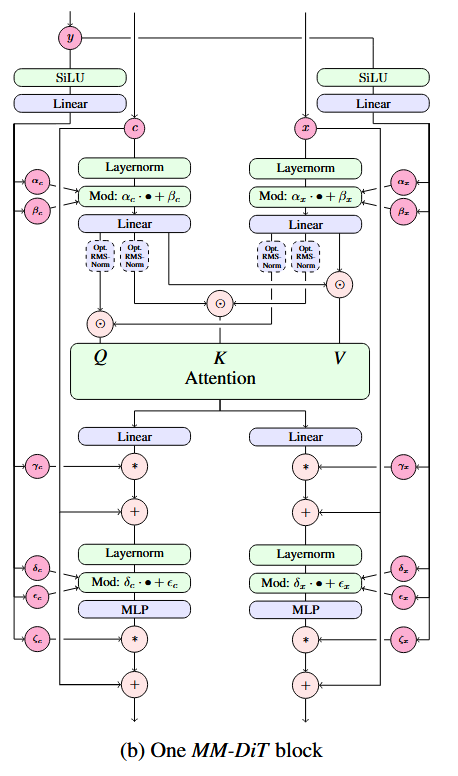
我们再来看文本约束的处理。文本约束以两种方式输入进模型:与时刻编码拼接、在注意力层中融合。具体数据关联细节可参见下图。如图所示,为了提高 SD3 的文本理解能力,描述文本 (“Caption”) 经由三种编码器编码,得到两组数据。一组较短的数据会经由 MLP 与文本编码加到一起;另一组数据会经过线性层,输入进 Transformer 的主模块中。
将约束编码与时刻编码相加是一种很常见的做法。此前 U-Net 去噪网络中处理简单约束(如 ImageNet 类型约束)就是用这种方法。

SD3 的 DiT 的子模块结构图如下所示。我们可以分几部分来看它。先看时刻编码 的那些分支。和标准 DiT 子模块一样, 通过修改 LayerNorm 后数据的均值、方差及部分层后的数据大小来实现约束。再看输入的图像编码 和文本编码 。二者以相同的方式做了 DiT 里的 LayerNorm, FF 等操作。不过,相比此前多数基于 DiT 的模型,此模块用了一种特殊的融合注意力层。具体来说,在过注意力层之前, 和 对应的 会分别拼接到一起,而不是像之前的模型一样, 来自图像, 来自文本。过完注意力层,输出的数据会再次拆开,回到原本的独立分支里。由于 Transformer 同时处理了文本、图像的多模态信息,所以作者将模型取名为 MM-DiT (Multimodal DiT)。
比例可变的位置编码
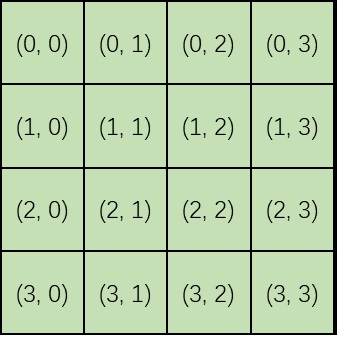
此前多数方法在使用类 ViT 架构时,都会把图像的图块从左上到右下编号,把二维图块拆成一维序列,再用这种一维位置编码来对待图块。

这样做有一个很大的坏处:生成的图像的分辨率是无法修改的。比如对于上图,假如采样时输入大小不是 ,而是 ,那么 号图块的下面就是 而不是 了,模型训练时学习到的图块之间的位置关系全部乱套。
解决此问题的方法很简单,只需要将一维的编码改为二维编码。这样 Transformer 就不会搞混二维图块间的关系了。
SD3 的 MM-DiT 一开始是在 固定分辨率上训练的。之后在高分辨率图像上训练时,开发者用了一些巧妙的位置编码设置技巧,让不同比例的高分辨率图像也能共享之前学到的这套位置编码。详细公式请参见原论文。
训练数据预处理
看完了模块设计,我们再来看一下 SD3 在训练中的一些额外设计。在大规模训练前,开发者用三个方式过滤了数据:
- 用了一个 NSFW 过滤器过滤图片,似乎主要是为了过滤色情内容。
- 用美学打分器过滤了美学分数太低的图片。
- 移除了看上去语义差不多的图片。
虽然开发者们自信满满地向大家介绍了这些数据过滤技术,但根据社区用户们的反馈,可能正是因为色情过滤器过分严格,导致 SD3 经常会生成奇怪的人体。
由于在训练 LDM 时,自编码器和文本编码器是不变的,因此可以提前处理好所有训练数据的图像编码和文本编码。当然,这是一项非常基础的工程技巧,不应该写在正文里的。
用 QK 归一化提升训练稳定度
按照之前高分辨率文生图模型的训练方法,SD3 会先在 的图片上训练,再在高分辨率图片上微调。然而,开发者发现,开始微调后,混合精度训练常常会训崩。根据之前工作的经验,这是由于注意力输入的熵会不受控制地增长。解决方法也很简单,只要在做注意力计算之前对 Q, K 做一次归一化就行,具体做计算的位置可以参考上文模块图中的 “RMSNorm”。不过,开发者也承认,这个技巧并不是一个长久之策,得具体问题具体分析。看来这种 DiT 模型在大规模训练时还是会碰到许多训练不稳定的问题,且这些问题没有一个通用解。
试验
哪种扩散模型训练目标最适合文生图任务?
最后我们来看论文的实验结果部分。首先,为了寻找最好的扩散模型/流匹配模型,开发者开展了一场声势浩大的实验。实验涉及 61 种训练公式,其中的可变项有:
- 对于普通扩散模型,考虑 \(\epsilon\)- 或 \(\mathbf{v}\)-prediction,考虑线性或 cosine 噪声调度。
- 对于整流,考虑不同的噪声调度。
- 对于 EDM,考虑不同的噪声调度,且尽可能与整流的调度机制相近以保证可比较。
在训练时,除了训练目标公式可变外,优化算法、模型架构、数据集、采样器都不可变。所有模型在 ImageNet 和 CC12M 数据集上训练,在 COCO-2014 验证集上评估 FID 和 CLIP Score。根据评估结果,可以选出每个模型的最优停止训练的步数。基于每种目标下的最优模型,开发者对模型进行最后的排名。由于在最终评估时,仍有采样步数、是否使用 EMA 模型等可变采样配置,开发者在所有 24 种采样配置下评估了所有模型,并用一种算法来综合所有采样配置的结果,得到一个所有模型的最终排名。最终的排名结果如下面的表 1 所示。训练集上的一些指标如表 2 所示。
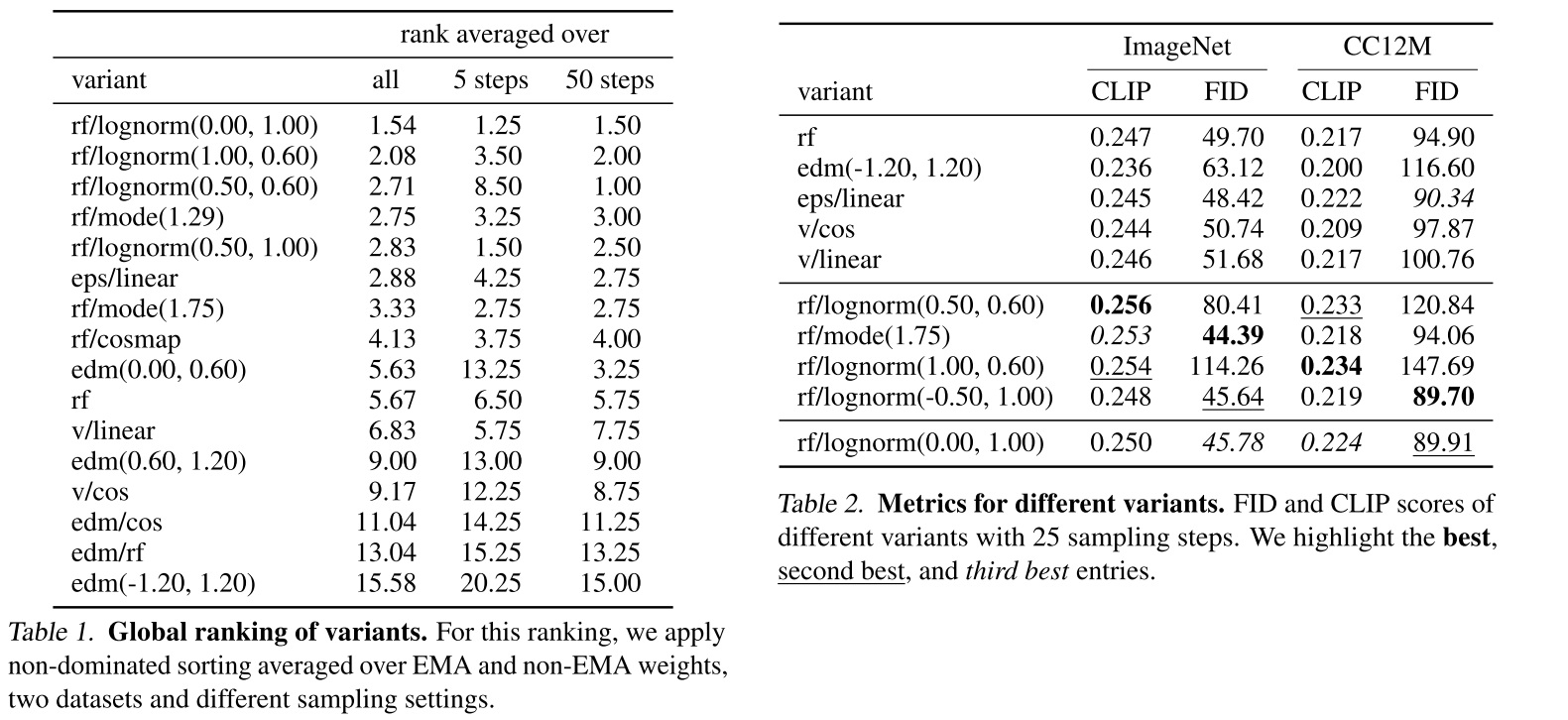
根据实验结果,我们可以得到一些直观的结论:整流领先于扩散模型。惊人的是,较新推出的 EDM 竟然没有战胜早期的 LDM (“eps/linear”)。
当然,我个人认为,应该谨慎看待这份实验结果。一般来说,大家做图像生成会用一个统一的指标,比如 ImageNet 上的 FID。这篇论文相当于是新提出了一种昂贵的评价方法。这种评价方法是否合理,是否能得到公认还犹未可知。另外,想说明一个生成模型的拟合能力不错,用 ImageNet 上的 FID 指标就足够有说服力了,大家不会对一个简单的生成模型有太多要求。然而,对于大型文生图模型,大家更关心的是模型的生成效果,而 FID 和 CLIP Score 并不能直接反映文生图模型的质量。因此,光凭这份实验结果,我们并不能说整流一定比之前的扩散模型要好。
会关注这份实验结果的应该都是公司里的文生图开发者。我建议体量小的公司直接参考这份实验结果,无脑使用整流来代替之前的训练目标。而如果有能力做同等级的实验的话,则不应该错过改良后的扩散模型,如最新的 EDM2,说不定以后还会有更好的文生图训练目标。
参数扩增实验结果
现在多数生成模型都会做参数扩增实验,即验证模型表现随参数量增长而增长,确保模型在资源足够的情况下可以被训练成「大模型」。SD3 也做了类似的实验。开发者用参数 来控制 MM-DiT 的大小,Transformer 块的个数为 ,且所有特征的通道数与 成正比。开发者在 的数据上训练了所有模型 500k 步,每 50k 步在 CoCo 数据集上统计验证误差。最终所有评估指标如下图所示。可以说,所有指标都表明,模型的表现的确随参数量增长而增长。更多结果请参见论文。

Diffusers 源码阅读
测试脚本
我们来阅读一下 SD3 在最流行的扩散模型框架 Diffusers 中的源码。在读源码前,我们先来跑通官方的示例脚本。
由于使用协议的限制,SD3 的环境搭起来稍微有点麻烦。首先,我们要确保 Diffuers 和 Transformers 都用的是最新版本。
pip install --upgrade diffusers transformers
之后,我们要注册 HuggingFace 账号,再在 SD3 的模型网站 https://huggingface.co/stabilityai/stable-diffusion-3-medium 里确认同意某些使用协议。之后,我们要设置 Access Token。具体操作如下所示,先点右上角的 “settings”,再点左边的 “Access Tokens”,创建一个新 token。将这个 token 复制保存在本地后,点击 token 右上角选项里的 “Edit Permission”,在权限里开启 “… public gated repos …”。
最后,我们用命令行登录 HuggingFace 并使用 SD3。先用下面的命令安装 HuggingFace 命令行版。
pip install -U "huggingface_hub[cli]"
再输入 huggingface-cli login,命令行会提示输入 token 信息。把刚刚保存好的 token 粘贴进去,即可完成登录。