论文介绍了一种新的网络结构用于人体姿态检测,作者在论文中展现了不断重复bottom-up、top-down过程以及运用intermediate supervison(中间监督)对于网络性能的提升,下面来介绍Stacked Hourglass Networks.
简介
理解人类的姿态对于一些高级的任务比如行为识别来说特别重要,而且也是一些人机交互任务的基础。作者提出了一种新的网络结构Stacked Hourglass Networks来对人体的姿态进行识别,这个网络结构能够捕获并整合图像所有尺度的信息。之所以称这种网络为Stacked Hourglass Networks,主要是它长得很像堆叠起来的沙漏,如下图所示:
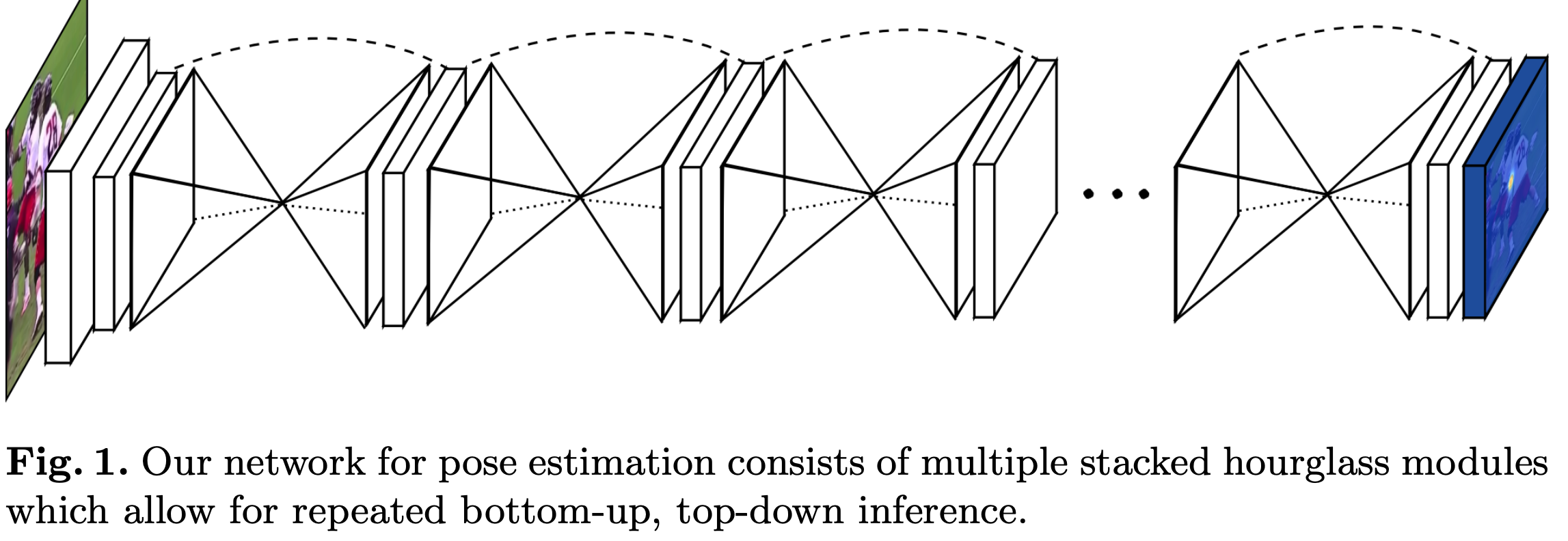
这种堆叠在一起的Hourglass模块结构是对称的,bottom-up过程将图片从高分辨率降到低分辨率,top-down过程将图片从低分辨率升到高分辨率,这种网络结构包含了许多pooling和upsampling的步骤,pooling可以将图片降到一个很低的分辨率,upsampling可以结合多个分辨率的特征。
下面介绍具体的网络结构。
Hourglass Module
Hourglass模块设计的初衷就是为了捕捉每个尺度下的信息,因为捕捉像脸,手这些部分的时候需要局部的特征,而最后对人体姿态进行预测的时候又需要整体的信息。为了捕获图片在多个尺度下的特征,通常的做法是使用多个pipeline分别单独处理不同尺度下的信息,然后再网络的后面部分再组合这些特征,而作者使用的方法就是用带有skip layers的单个pipeline来保存每个尺度下的空间信息。
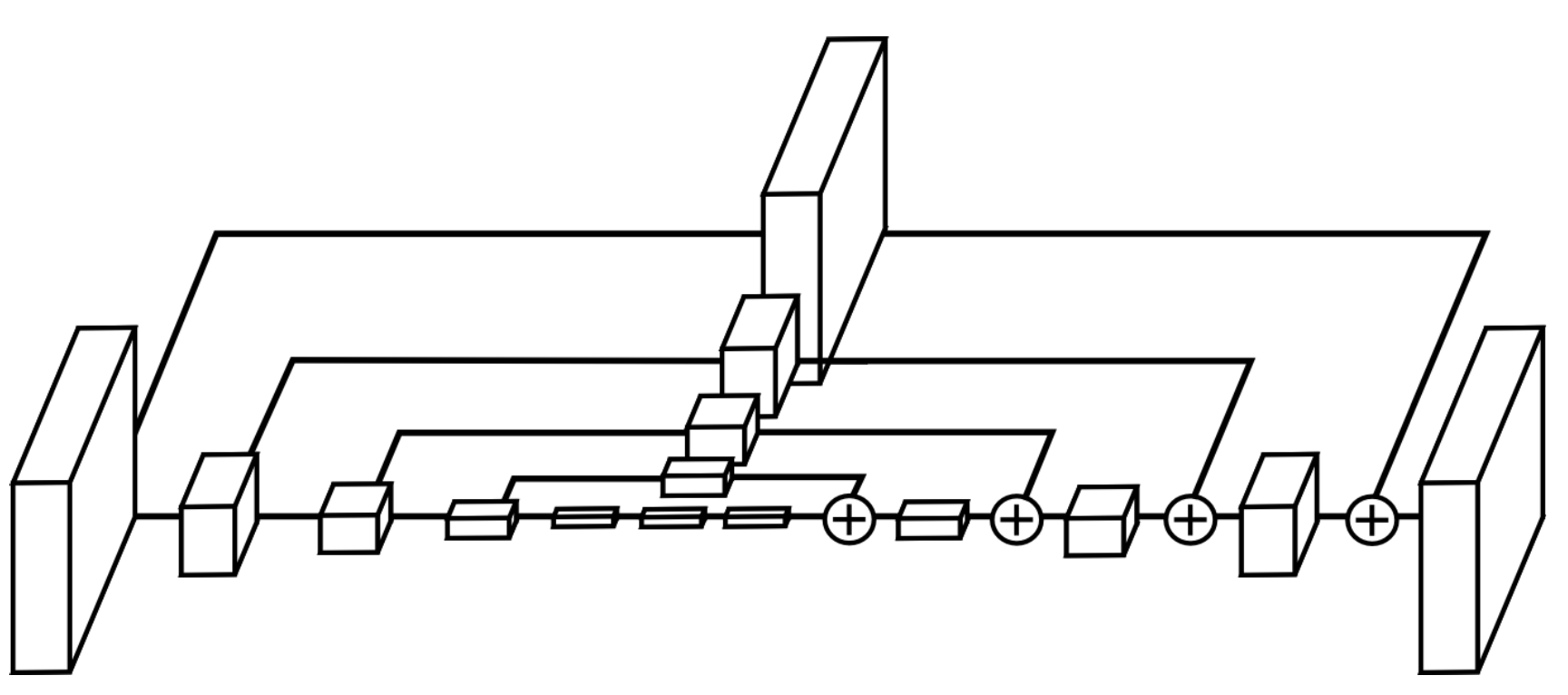
在Hourglass模块中,卷积和max pooling被用来将特征降到一个很低的分辨率,在每一个max pooling步骤中,网络产生分支并在原来提前池化的分辨率下使用更多的卷积,当到达最低的分辨率的时候,网络开始upsample并结合不同尺度下的特征。这里upsample(上采样)采用的方法是最邻近插值,之后再将两个特征集按元素位置相加。
当到达输出分辨率的时候,再接两个1×1的卷积层来进行最后的预测,网络的输出是一组heatmap,对于给定的heatmap,网络预测在每个像素处存在关节的概率。
网络结构
Residual Module
上图中的每个方框都由下面这样的残差块组成:
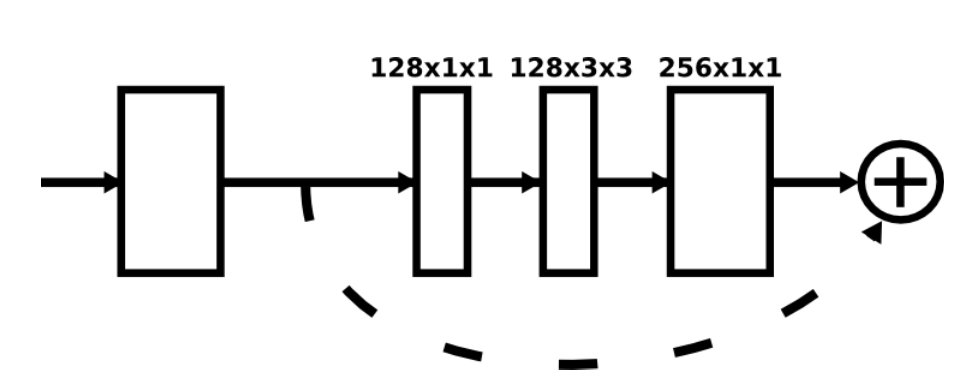
残差结构的代码如下
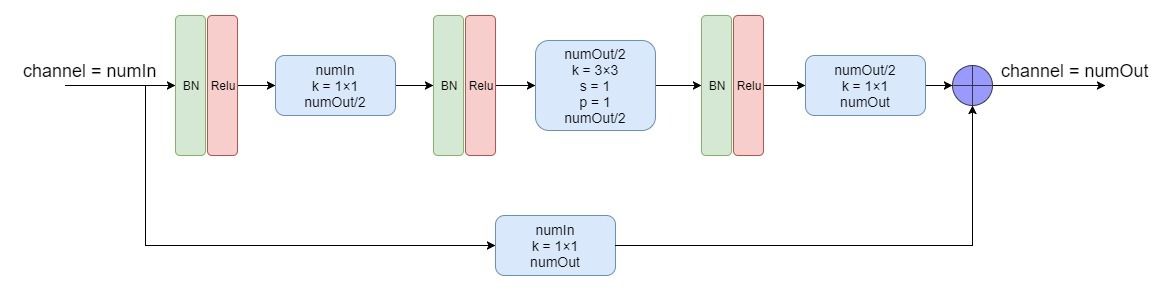
上图的残差块是论文中的原图,描述的不够详细,自己看了下源代码之后,画出了如下图所示的Residual Module:
整体结构
网络输入的图片分辨率为256×256,在hourglass模块中的最大分辨率为64×64,整个网络最开始要经过一个7×7的步长为2的卷积层,之后再经过一个残差块和Max pooling层使得分辨率从256降到64。下面贴出n阶Hourglass代码:
class Hourglass(nn.Module):
def __init__(self, n, f, bn=None, increase=128):
super(Hourglass, self).__init__()
nf = f + increase
self.up1 = Conv(f, f, 3, bn=bn)
# Lower branch
self.pool1 = Pool(2, 2)
self.low1 = Conv(f, nf, 3, bn=bn)
# Recursive hourglass
if n > 1:
self.low2 = Hourglass(n-1, nf, bn=bn)
else:
self.low2 = Conv(nf, nf, 3, bn=bn)
self.low3 = Conv(nf, f, 3)
self.up2 = nn.UpsamplingNearest2d(scale_factor=2)
def forward(self, x):
up1 = self.up1(x)
pool1 = self.pool1(x)
low1 = self.low1(pool1)
low2 = self.low2(low1)
low3 = self.low3(low2)
up2 = self.up2(low3)
return up1 + up2
整体网络代码如下
def __init__(self, nstack, inp_dim, oup_dim, bn=False, increase=128, **kwargs):
super(PoseNet, self).__init__()
self.pre = nn.Sequential(
Conv(3, 64, 7, 2, bn=bn),
Conv(64, 128, bn=bn),
Pool(2, 2),
Conv(128, 128, bn=bn),
Conv(128, inp_dim, bn=bn)
)
self.features = nn.ModuleList( [
nn.Sequential(
Hourglass(4, inp_dim, bn, increase),
Conv(inp_dim, inp_dim, 3, bn=False),
Conv(inp_dim, inp_dim, 3, bn=False)
) for i in range(nstack)])
self.outs = nn.ModuleList([Conv(inp_dim, oup_dim, 1, relu=False, bn=False) for i in range(nstack)] )
self.merge_features = nn.ModuleList([Merge(inp_dim, inp_dim) for i in range(nstack-1)])
self.merge_preds = nn.ModuleList([Merge(oup_dim, inp_dim) for i in range(nstack-1)] )
self.nstack = nstack
self.myAEloss = AEloss()
self.heatmapLoss = HeatmapLoss()
def forward(self, imgs):
x = imgs.permute(0, 3, 1, 2)
x = self.pre(x)
preds = []
for i in range(self.nstack):
feature = self.features[i](x)
preds.append(self.outs[i](feature))
if i != self.nstack - 1:
x = x + self.merge_preds[i](preds[-1]) + self.merge_features[i](feature)
return torch.stack(preds, 1)图中的4阶Hourglass Module就是前面讲的4阶Hourglass Module,可以看到整个网络还是挺庞大的,图中的渐变红色块就是加入了中间监督的地方,即在此处使用loss函数,下面讲一下中间监督。
注意,上面的整体网络结构图中中间监督的地方输出的通道数为16是针对于MPII Human Pose这个数据集,因为该数据集将人体划分为16个关节点,具体参见人体姿态估计数据集整理(Pose Estimation/Keypoint)
Intermediate Supervision
作者在整个网络结构中堆叠了许多hourglass模块,从而使得网络能够不断重复自底向上和自顶向下的过程,作者提到采用这种结构的关键是要使用中间监督来对每一个hourglass模块进行预测,即对中间的heatmaps计算损失。
关于中间监督的位置,作者在文中也进行了讨论。大多数高阶特征仅在较低的分辨率下存在,除非发生上采样时才出现。如果在网络进行上采样后进行监督,则无法在更大的全局上下文中重新评估这些特征;最终,作者将中间监督设计在如下图所示位置:
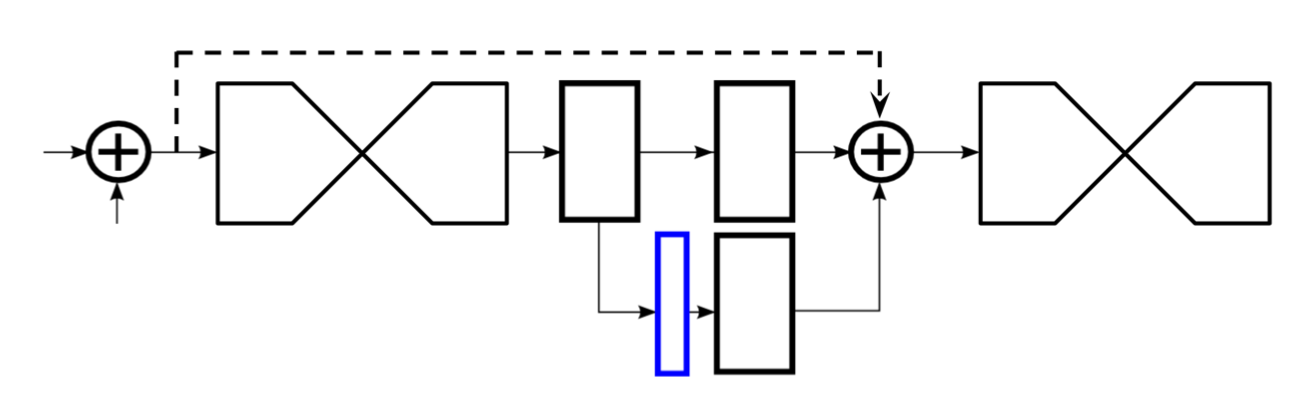
在整个网络中,作者共使用了8个hourglass模块,需要注意的是,这些hourglass模块的权重不是共享的,并且所有的模块都基于相同的ground truth添加了损失函数。