BERT 方法回顾
在 大规模预训练模型BERT 里面我们介绍了 BERT 的自监督预训练的方法,BERT 可以做的事情也就是Transformer 的 Encoder 可以做的事情,就是输入一排向量,输出另外一排向量,输入和输出的维度是一致的。那么不仅仅是一句话可以看做是一个sequence,一段语音也可以看做是一个sequence,甚至一个image也可以看做是一个sequence。所以BERT其实不仅可以用在NLP上,还可以用在CV里面。所以BERT其实输入的是一段文字,如下图所示。
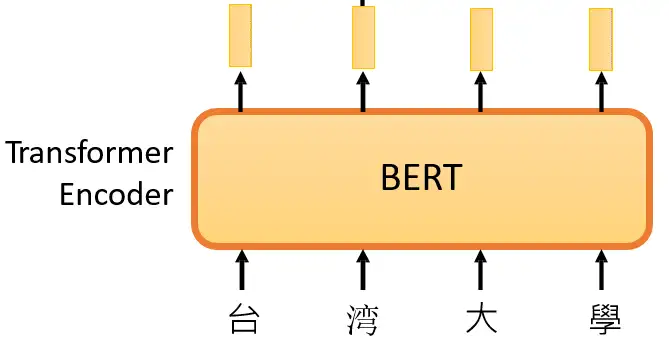
接下来要做的事情是把这段输入文字里面的一部分随机盖住。随机盖住有 2 种,一种是直接用一个Mask 把要盖住的token (对中文来说就是一个字)给Mask掉,具体是换成一个特殊的字符。另一种做法是把这个token替换成一个随机的token。

具体BERT详情可以参考:大规模预训练模型BERT
BERT 可以直接用在视觉任务上吗?
上面的 BERT 都是在 NLP 任务上使用,因为 NLP 任务可以把每个词汇通过 Word2Vec 自动转化成一个固定大小的 token,我们随机盖住一些 token,让模型根据这个不完整的句子来预测被盖住的 token 是什么。那么一个自然而然的问题是:对于图片来讲,能否使用类似的操作呢?
第1个困难的地方是:视觉任务没有一个大的词汇表。在 NLP 任务中,假设我们盖住词汇 "湾",那么就想让模型根据这个不完整的句子来预测被盖住的 token 是 "湾",此时我们有个词汇表,比如这个词汇表一共有8个词,"湾" 是第3个,则 "湾" 这个 token 的真值就是 \(GT=[0,0,1,0,0,0,0,0] \),只需要让模型的输出和这个 GT 越接近越好。
但是 CV 任务没有这个词汇表啊,假设我盖住一个 patch,让模型根据这个不完整的 image 来预测被盖住的 patch 是什么。那么对应的这个 GT 是什么呢?
BEIT 通过一种巧妙的方式解决了这个问题。
假设这个问题可以得到解决,我们就能够用 masked image modeling 的办法 (和BERT类似,盖住图片的一部分之后预测这部分) 训练一个针对图片的预训练模型,这个预训练模型就也可以像 BERT 一样用在其他各种 CV 的下游任务中啦。
BEIT 原理分析
论文名称:BEIT: BERT Pre-Training of Image Transformers
论文地址:https://arxiv.org/pdf/2106.08254.pdf
本文提出的这个方法叫做 BEIT,很明显作者是想在 CV 领域做到和 NLP 领域的BERT一样的功能。训练好的 BERT 模型相当于是一个 Transformer 的 Encoder,它能够把一个输入的 sentence 进行编码,得到一堆 tokens。比如输入 "台湾大学",通过 BERT 以后会得到4个 tokens。并且这4个 tokens 也结合了sentence 的上下文。
那 BEIT 能不能做到类似的事情呢?,即能够把一个输入的 image 进行编码,得到一堆 vectors,并且这些个 vectors 也结合了 image 的上下文。答案是肯定的。BEIT 的做法如下:
在 BEIT 眼里,图片有 2 种表示的形式:
image → image patches | visual tokens
在预训练的过程中,它们分别被作为模型的输入和输出,如下图所示。
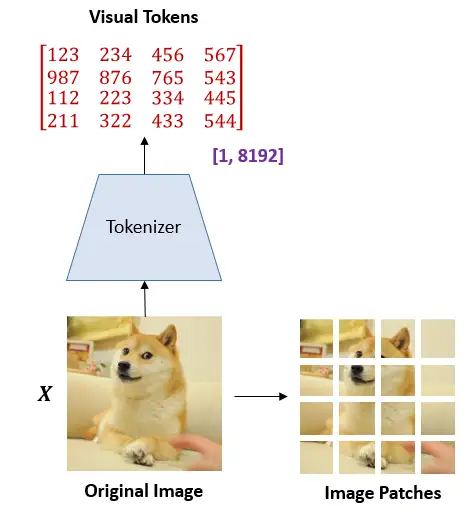
BEIT的结构可以看做2部分,分别是:
- BEIT Encoder
- dVAE
BEIT Encoder 类似于 Transformer Encoder,是对输入的 image patches 进行编码的过程,dVAE 类似于 VAE,也是对输入的 image patches 进行编码的过程,具体会在下面分别详细介绍。
图片表示为 image patches
将图片表示为 image patches 这个操作和 Vision Transformer 对图片的处理手段是一致的。首先把 \(x\in\mathcal{R^{H\times W\times C}}\) 的图像分成 \(N=HW/P^2\) 个展平的2D块 \(x^p\in\mathcal{R}^{N\times(P^2C)}\)。
式中,\(C\)是 channel 数, \((W,H)\) 是输入的分辨率, \((P,P)\) 是块大小。每个 image patch 会被展平成向量并通过线性变换操作 (flattened into vectors and are linearly projected)。这样一来,image 变成了一系列的展平的2D块的序列,这个序列中一共有\(N=HW/P^2\)个展平的2D块,每个块的维度是\((P^2C)\)。
实作时 \(P=16,H=W=224\) ,和 ViT 一致。
问:image patch 是个扮演什么角色?
答:image patch 只是原始图片通过 Linear Transformation 的结果,所以只能保留图片的原始信息 (Preserve raw pixels)。
将图片表示为 visual tokens
这一步是啥意思呢?BEIT的一个通过 dVAE 里面一个叫做 image tokenizer 的东西,把一张图片\(x\in\mathcal{R^{H\times W\times C}}\) 变成离散的 tokens \(z=[z_1,...,z_N]\in \mathcal{V}^{h\times w}\) 。字典 \(\mathcal{V}=\{1,...,|\mathcal{V}|\}\) 包含了所有离散 tokens 的索引 (indices)。
要彻底理解如何将图片表示为 visual tokens,那就得先从 VAE 开始讲起了,VAE的详情可以参考:VAE 变分自编码器
BEIT 里的 VAE:tokenizer 和 decoder
如果了解了 VAE 模型的训练过程,那么我们回到之前的问题上面,BEIT 是如何将图片表示为 visual tokens的呢?
具体而言,作者训练了一个 discrete variational autoencoder (dVAE)。训练的过程如下图所示。读者可以仔细比较一下这个 dVAE 和VAE 的异同,dVAE 虽然是离散的 VAE,但它和 VAE 的本质还是一样的,都是把一张图片通过一些操作得到隐变量,再把隐变量通过一个生成器重建原图。下表就是一个清晰的对比,我们可以发现:
- VAE使用的均值方差拟合神经网络得到隐变量。
- dVAE使用Tokenizer得到隐变量。
- VAE使用生成器重建原图。
- dVAE使用Decoder重建原图。
model | 得到隐变量的模块 | 重建原图的模块 |
|---|---|---|
VAE | 均值方差拟合神经网络 | 生成器 |
dVAE | Tokenizer | Decoder |
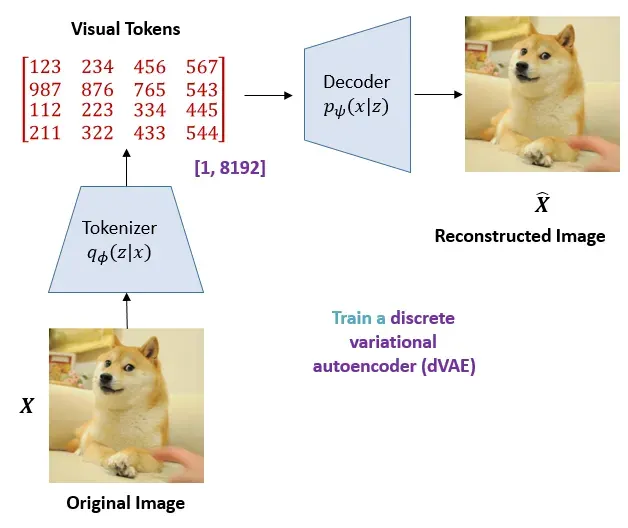
所以dVAE中的Tokenizer就相当于是VAE里面的均值方差拟合神经网络,dVAE中的Decoder就相当于是VAE里面的生成器。
所以,dVAE 的训练方式其实可以和 VAE 的一模一样。
问:这里的 visual token 具体是什么形式的?
答:作者把一张 \(224×224\) 的输入图片通过 Tokenizer 变成了 \(14×14\) 个 visual token,每个 visual token 是一个位于\([1,8192]\)之间的数。就像有个 image 的词汇表一样,这个词汇表里面有 8192 个词,每个 \(16×16\) 的image patch会经过 Tokenizer 映射成 \(|\mathcal{V}|\) 里面的一个词。因为 visual token 是离散的数,所以优化时没法求导,所以作者采用了 gumbel softmax 技巧,想详细了解 gumbel softmax trick 的同学可以参考下面的链接:
BEIT 的 Backbone:Image Transformer
BEIT 的总体结构如下图所示,BEIT 的 Encoder 结构就是 Transformer 的 Encoder,模型架构是一样的。图片在被分成 \(N=HW/P^2\) 个展平的2D块 \(\color{orange}{x^{p} \in \mathbb{R}^{N \times (P^2 C)}}\)之后,通过线性变换得到 \(\bm{E} x^{p}_{i}\) ,其中 \(\bm{E} \in \mathbb{R}^{(P^2 C) \times D}\) 。在concat上一个 special token [S]。这里作者还给输入加上了 1D 的位置编码 \(\bm{E} _{pos} \in \mathbb{R}^{N \times D}\) ,所以总的输入张量可以表示为:
输入 BEIT 的 Encoder (就是 Transformer 的 Encoder) 之后,张量依次通过 L 个 Encoder Block:
式中 \(l=1,2,...,L\) 。最后一层输出 \( \bm{H}^{L} = [ \bm{h}^{L}_{\texttt{[S]}}, \bm{h}^{L}_{1}, \dots, \bm{h}^{L}_{N} ] \) 作为 image patches 的 encoded representations, \(\bm{h}^{L}_{i}\) 代表第 \(i\) 个 image patch的编码表示。
类似 BERT 的自监督训练方式:Masked Image Modeling
至此,我们介绍了 BEIT 的两部分结构:
- BEIT Encoder
- dVAE
下面就是 BEIT 的训练方法了。既然BEIT 是图像界的 BERT 模型,所以也遵循着和 BERT 相似的自监督训练方法。
让 BERT 看很多的句子,随机盖住一些 tokens,让 BERT 模型预测盖住的tokens是什么,不断计算预测的 token 与真实的 token 之间的差异,利用它作为 loss 进行反向传播更新参数,来达到 Self-Supervised Learning 的效果。
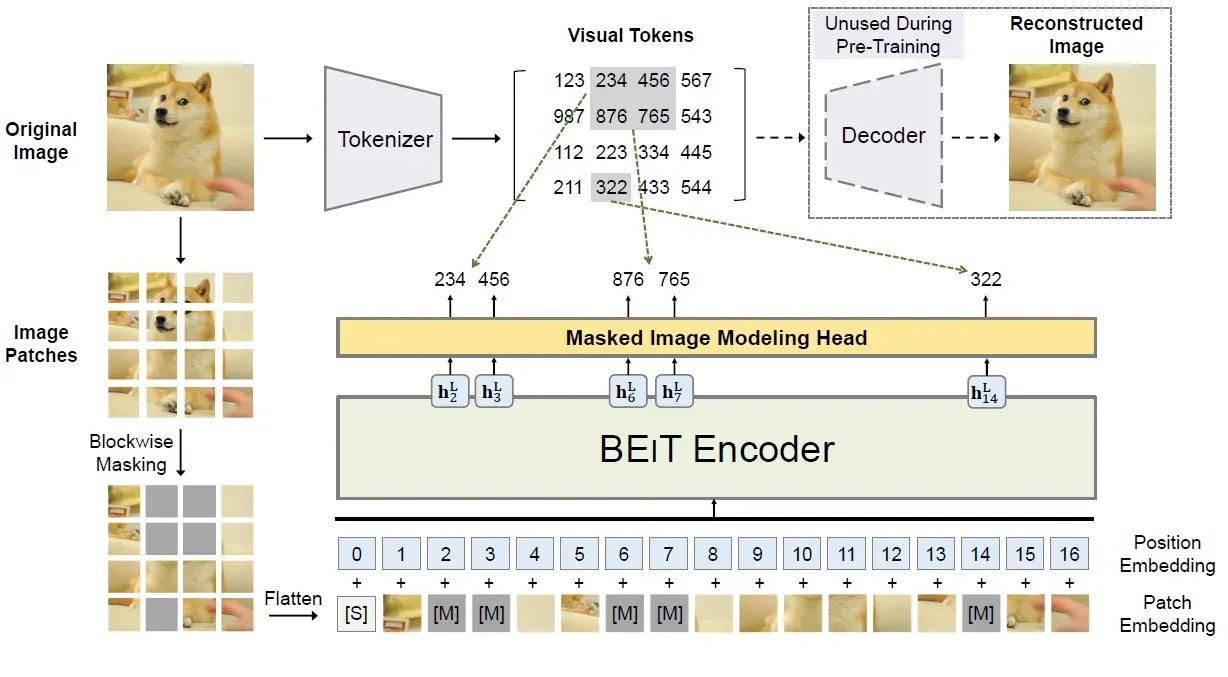
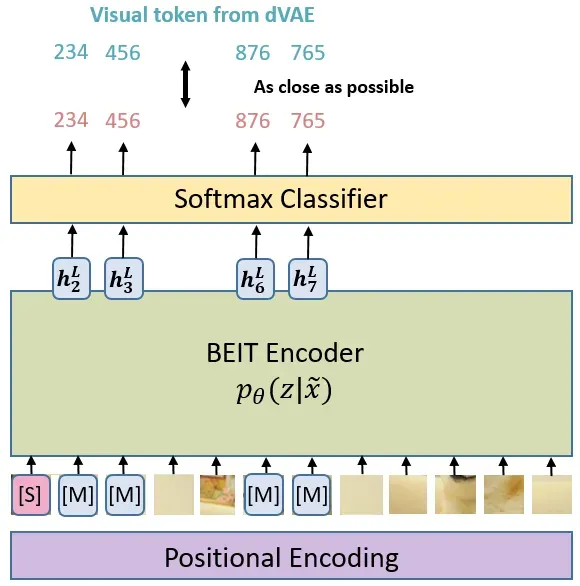
BEIT 使用了类似 BERT 的自监督训练方式:Masked Image Modeling,如上图所示,即:
让 BEIT 看很多的图片,随机盖住一些 image patches,让 BEIT 模型预测盖住的patches是什么,不断计算预测的 patches 与真实的 patches 之间的差异,利用它作为 loss 进行反向传播更新参数,来达到 Self-Supervised Learning 的效果。
具体做法是:
- 给定输入图片 \(\bm{x}\) 。
- 将其patchify变成 \(N\) 个 image patches \(\{\bm{x}^{p}_{i}\}_{i=1}^{N} \) 。
- 把它变成 \(N\) 个 visual tokens \(\{z_{i}\}_{i=1}^{N}\) 。
- 随机盖住40% 的 image patches,盖住的位置可以表示为 \(\mathcal{M} \in \{1,\dots,N\}^{0.4 N}\)。
- 把盖住的这40%的image patches 替换成可学习的编码 \(\bm{e}_{\texttt{[m]}} \in \mathbb{R}^{D}\) 。
- 现在这个输入的 image patches 就可以表示成: \(x^{\mathcal{M}} = \{ \bm{x}^p_i : i \notin \mathcal{M} \}_{i=1}^N \bigcup \{ \bm{e}_{\texttt{[M]}} : i \in \mathcal{M} \}_{i=1}^N\)
- 把这个\(x^{\mathcal{M}}\)通过\(L\)层的 BEIT Encoder,得到 \( \{ \bm{h}^{L}_{i} \}_{i=1}^{N}\) ,表示输入image patches的编码表示。
- 盖住的位置的输出\(\{\bm{h}^{L}_{i} : i \in \mathcal{M} \}_{i=1}^{N} \) 去通过一个分类器,去预测盖住的这个 patch的相应的 visual token,\(\color{teal}{p_{\text{MIM}}( z' | x^{\mathcal{M}} )} = \text{softmax}{z'} (\bm{W}{c} \bm{h}^{L}{i} + \bm{b}{c})\) 。式中 \(x^{\mathcal{M}}\)是盖住之后的所有 image patches, \( \bm{W}_{c} \in \mathbb{R}^{|\mathcal{V}| \times D},\bm{b}_{c} \in \mathbb{R}^{|\mathcal{V}|} \) ,这里 \(|\mathcal{V}| =8192\) ,\(D \)是模型的 Embedding dimension。
- BERT 的训练目标是最小化计算预测的 token 与真实的 token 之间的差异,所以BEIT的目标也是最小化计算预测的 token 与真实的 token 之间的差异。那其实还不完全一致,在 BEIT 里面,假设我盖住第 \(i \)个patch,毫无疑问它对应的 visual token 应该是 \(z_i \),这时候我希望 Encoder 输出的第\( i\) 个位置的东西通过分类器之后是 \(z_i \)的概率最大,即:
式中,\( D\) 是全部的无标签训练数据, \(\mathcal{M}\) 是随机盖住的位置, \(x^{\mathcal{M}}\) 是盖住以后的corrupted image。
上式是什么意思呢? \(i \in \mathcal{M}\) 就是对盖住的每个 patches,BEIT 的 Encoder 在这个位置的输出 \(\bm{h}^{L}_{i}\) 通过线性分类器 \( \text{softmax}_{z'} (\bm{W}_{c} \bm{h}^{L}_{i} + \bm{b}_{c}) \) 之后得到预测的 visual token 与真实 patches 对应的 visual token 越接近越好,如下图所示。
问:真实 patches 对应的 visual token 是怎么得到的呢?
答:训练一个 dVAE,其中的 Tokenizer 的作用就是把 image patches 编码成 visual tokens,通过 Tokenizer 来实现。
下面的问题是如何随机盖住40% 的 image patches?
BEIT 并不是完全随机地盖住40%,而是采取了 blockwise masking 的方法,如下图所示。
就是每次循环先通过 Algorithm 1计算出 \(s,r,a,t \),然后盖住 \(i\in[t,t+a),j\in[l,l+b) \)的部分,直到盖住的部分超过了 40% 为止。

BEIT 的目标函数:VAE 视角
下面的问题是:BEIT 具体是取去优化什么目标函数呢?
回顾VAE 模型的总的损失函数为:
式中,紫色部分 \(\color{purple}{-logq(x|z)}\) 就是重构损失 \(\color{purple}{D(\tilde X_{k},X_{k})^{2}}\) ,红色部分 \(\color{crimson}{KL(p(z|x)||q(z))}\) 就是均值方差拟合网络的输出分布 \(p(Z|X)\)接近标准正态分布 \(N(0,I)\) 的这部分。
- dVAE 模型通过 Tokenizer 把 input image 变成一些 visual tokens,这个过程可以用 \(\color{darkgreen}{q_{\phi}(z|x)}\) 来表示。
- 通过 Decoder 把 visual tokens 重建成 reconstructed image,这个过程可以用 \(\color{darkgreen}{p_{\psi}(x|z)}\) 来表示。
- BEIT的 Encoder 也把 masked image 变成 visual tokens,这个过程可以用 \(\color{darkgreen}{p_{\theta}(z|\tilde x)}\) 来表示。
那么 \(\color{darkgreen}{p(x | \tilde{x})}\) 代表什么含义呢?
因为 \(\tilde{x}\) 代表 masked image, \(x \)代表 original image,所以 \(\color{darkgreen}{p(x | \tilde{x})}\) 代表给定一张masked image,能够重建回原图的概率,且对于 \(\color{darkgreen}{p(x | \tilde{x})}\) 我们有evidence lower bound (ELBO):
在 上式中也标出了重构损失 Visual Token Reconstruction。传统 VAE 的重构损失 (Reconstruction loss) \(\color{purple}{D(\tilde X_{k},X_{k})^{2}}\) 在 dVAE 里面可以写成:
所以整个优化过程分为2步:
第1步是去优化这个重构损失 (Reconstruction loss),就是更新 Tokenizer 和 Decoder 的参数,同时保持 BEIT的 Encoder 参数不变。
\[E_{z_i\sim q_{\phi}( \mathbf{z}|x_i)}[\log p_{\psi}(x_i|z_i)] \]第2步是去优化 BEIT 的 Encoder 参数,让预测的 visual token 与真实 patches 对应的 visual token 越接近越好,同时保持 Tokenizer 和 Decoder 的参数不变。
\[\log p_{\theta}(\hat{z}_i | \tilde{x}_i)\]
所以总的优化目标可以写成:
上式就是 BEIT 的总目标函数,使用 Gradient Ascent 更新参数。
所以,BEIT 遵循 BERT 的训练方法,让 BEIT 看很多的图片,随机盖住一些 image patches,让 BEIT 模型预测盖住的 patches 是什么,不断计算预测的 patches 与真实的 patches 之间的差异,进行反向传播更新参数,来达到 Self-Supervised Learning 的效果。
不同的是,BERT 的 Encoder 输入是 token,输出还是 token,让盖住的 token 与输出的预测 token 越接近越好;而 BEIT 的 Encoder 输入是 image patches,输出是 visual tokens,让盖住的位置输出的 visual tokens 与真实的 visual tokens 越接近越好。真实的 visual tokens 是通过一个额外训练的 dVAE 得到的。
BEIT 的架构细节和训练细节超参数
BEIT Encoder 的具体架构细节:12层 Transformer,Embedding dimension=768,heads=12,FFN expansion ratio=4,Patch Size=16,visual token总数,即词汇表大小 \(|\mathcal{V}| =8192\) 。Mask 75个 patches,一个196个,大约占了40%。
BEIT Encoder 的具体训练细节:在 ImageNet-1K上预训练。
BEIT 在下游任务 Fine-tuning
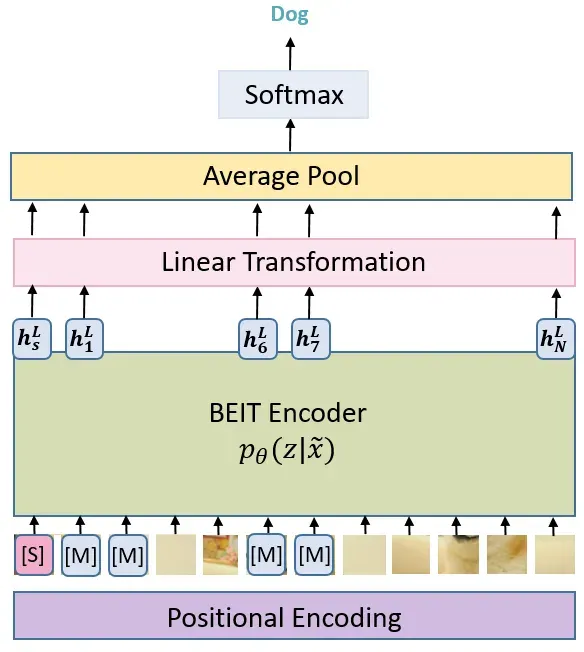
使用 Self-Supervised Learning 预训练完的 BEIT,作者展示了在2种下游任务上微调的结果,分类和分割。这里只以分类为例展示做法。以分类为例如下图所示,我们拿着训练好的 BEIT Encoder,给它添加一个 分类层 (Linear Transformation),池化层 (Avg),和激活函数,我们只微调分类层 (Linear Transformation),池化层 (Avg),和激活函数的参数,Encoder的参数保持不变 BEIT 在下游任务 Fine-tuning
实验
分类实验
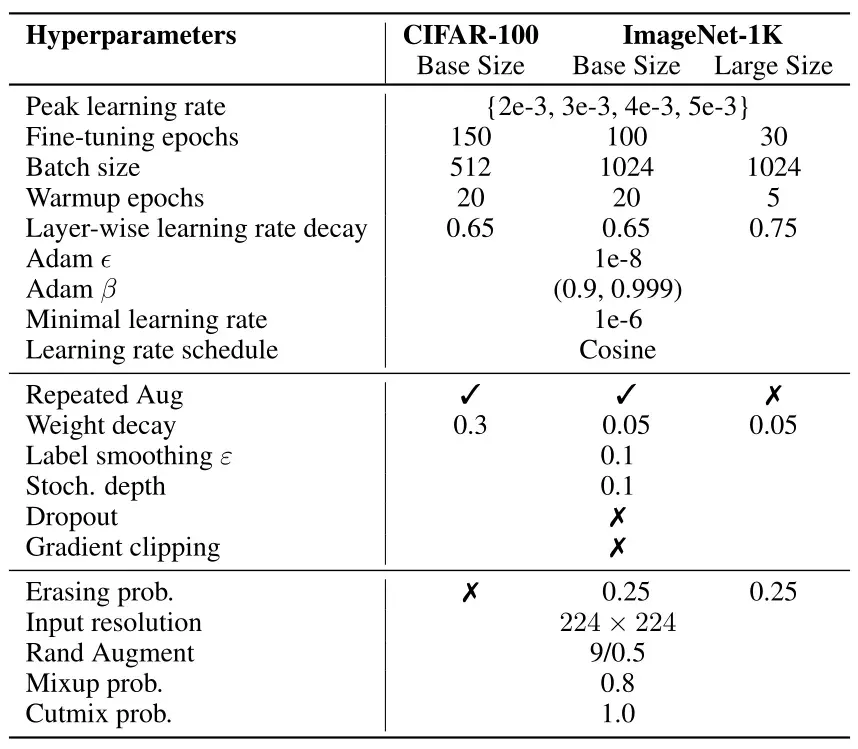
BEIT 实验的具体做法遵循BEIT 在下游任务 Fine-tuning的做法,展示的都是预训练模型在具体小数据集上面 Fine-tune之后得到的结果。分类实验在CIFAR-10和ImageNet这两个数据集上进行,超参数设置如下图所示:
下图是实验在CIFAR-10和ImageNet这两个数据集上的性能以及与其他模型的对比。所有的模型大小都是 "base" 级别。 与随机初始化训练的模型相比,作者发现预训练的BEIT模型在两种数据集上的性能都有显著提高。值得注意的是,在较小的CIFAR-100数据集上,从头训练的ViT仅达到48.5%的准确率。相比之下,通过Pre-train的帮助,BEIT达到了90.1%。结果表明,BEIT可以大大降低有标签数据 (labeled data) 的需求。BEIT还提高了ImageNet上的性能。
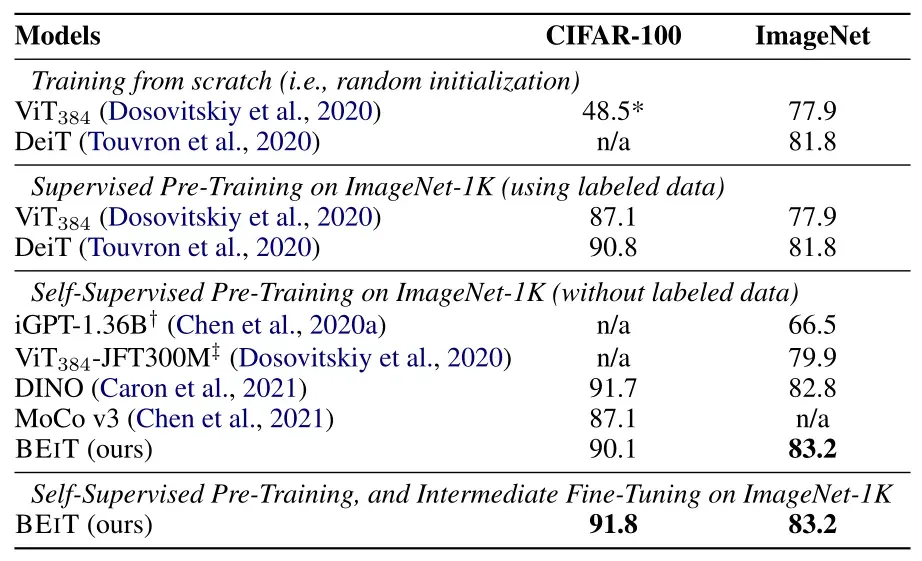
此外,作者将BEIT与21年几个最先进的 Transformer 自监督方法进行比较,如 DINO 和 MoCo v3 (这2个模型也会在这个系列中解读)。我们提出的方法在ImageNet微调上优于以往的模型。BEIT在ImageNet上的表现优于DINO,在CIFAR-100上优于MoCo v3。此外,作者评估了我们提出的方法与 Intermediate Fine-tuning。换句话说,我们首先以自监督的方式对BEIT 进行预训练,然后用标记数据在 ImageNet 上对预训练的模型进行 Fine-tune。结果表明,在ImageNet上进行 Intermediate Fine-tuning 后获得额外的增益。
问:上图中的 Supervised Pre-Training on ImageNet 和 Supervised Pre-Training, and Intermediate Fine-tuning on ImageNet有什么区别?
答:二者都是使用全部的 ImageNet-1K 数据集。前者是只训练分类器的参数,而 BEIT 预训练模型参数不变。后者是既训练分类器的参数,又微调 BEIT 预训练模型参数。
作者也在 \(384×384\) 高分辨率数据集上面作 Fine-tune 了 10个epochs,同时patch的大小保持不变,也就是用了序列长度增加了。 结果如下图21所示,在ImageNet上,更高的分辨率可以提高1个点的。更重要的是,当使用相同的输入分辨率时,用 ImageNet-1K 进行预训练的BEIT-384 甚至比使用 ImageNet-22K 进行监督预训练的 ViT-384 表现更好。
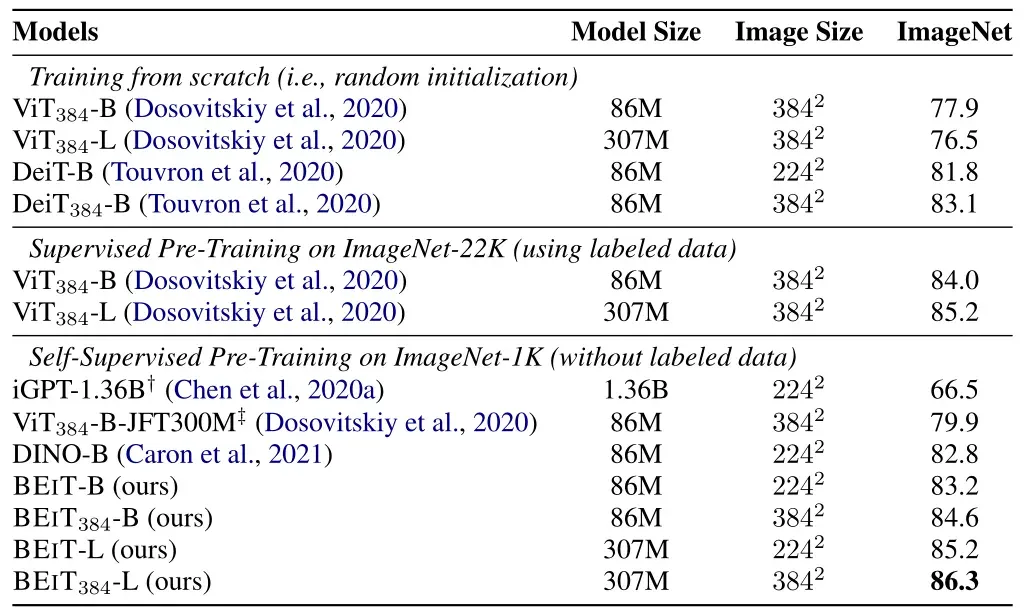
作者进一步扩大了 BEIT 的规模 (扩大到与 ViT-L 相同)。如上图所示,在ImageNet上,从头开始训练时,ViT-384-L 比 ViT-384差。结果验证了 Vision Transformer 模型的 data hungry 的问题。解决方法就是用更大的数据集 ImageNet-22K,用了以后 ViT-384-L 最终比ViT-384 涨了1.2个点。相比之下,BEIT-L比 BEIT 好2个点,BEIT-384-L 比 BEIT-384 好1.7个点,说明大数据集对BEIT的帮助更大。
对比实验:
消融实验分别是在ImageNet (分类) 和 ADE20K (分割) 任务上进行的,自监督方式训练 epochs是300。
- 第1个探索Blockwise masking的作用。Blockwise masking 指的是图17的方法,发现它在两种任务中都是有利的,特别是在语义分割上。
- 第2个探索 recover masked pixels的作用,recover masked pixels指的是盖住一个 image patch,BEIT 的 Encoder 模型不输出visual token,而是直接进行 pixel level的回归任务,就是直接输出这个 patch,发现这样也是可以的,只是精度稍微变差了。这说明预测 visual tokens 而不是直接进行 pixel level的回归任务才是 BEIT 的关键。
- 第3个探索 1,2 的结合方案,去掉Blockwise masking,以及直接进行 pixel level的回归任务,这个性能是最差的。
- 第4个探索不进行自监督预训练,即直接恢复100%的image patches,性能也会下降。

下图是BEIT模型不同reference points的attention map,可视化的方法是拿出BEIT的最后一个layer,假定一个参考点,随机选定它所在的patch,比如是第57个patch,然后把attention map的第57行拿出来,代表这个第57号patch attend to所有patch的程度,再reshape成正方形就得到了下图。
可以发现仅仅是预训练完以后,BEIT 就能够使用 self-attention 来区分不同的语义区域。 这个性质表明了为什么 BEIT 能够帮助下游任务的原因。通过BEIT获得的这些知识有可能提高微调模型的泛化能力,特别是在小数据集上。


总结
BEIT 遵循 BERT 的训练方法,让 BEIT 看很多的图片,随机盖住一些 image patches,让 BEIT 模型预测盖住的patches是什么,不断计算预测的 patches 与真实的 patches 之间的差异,利用它作为 loss 进行反向传播更新参数,来达到 Self-Supervised Learning 的效果。
不同的是,BERT 的 Encoder 输入是 token,输出还是 token,让盖住的 token 与输出的预测 token 越接近越好;而 BEIT 的 Encoder 输入是 image patches,输出是 visual tokens,让盖住的位置输出的 visual tokens 与真实的 visual tokens 越接近越好。真实的 visual tokens 是通过一个额外训练的 dVAE 得到的。