简介
EfficientNet源自Google Brain的论文EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. 从标题也可以看出,这篇论文最主要的创新点是Model Scaling. 论文提出了compound scaling,混合缩放,把网络缩放的三种方式:深度、宽度、分辨率,组合起来按照一定规则缩放,从而提高网络的效果。EfficientNet在网络变大时效果提升明显,把精度上限进一步提升,成为了当前最强网络。EfficientNet-B7在ImageNet上获得了最先进的 84.4%的top-1精度 和 97.1%的top-5精度,比之前最好的卷积网络(GPipe, Top-1: 84.3%, Top-5: 97.0%)大小缩小8.4倍、速度提升6.1倍。
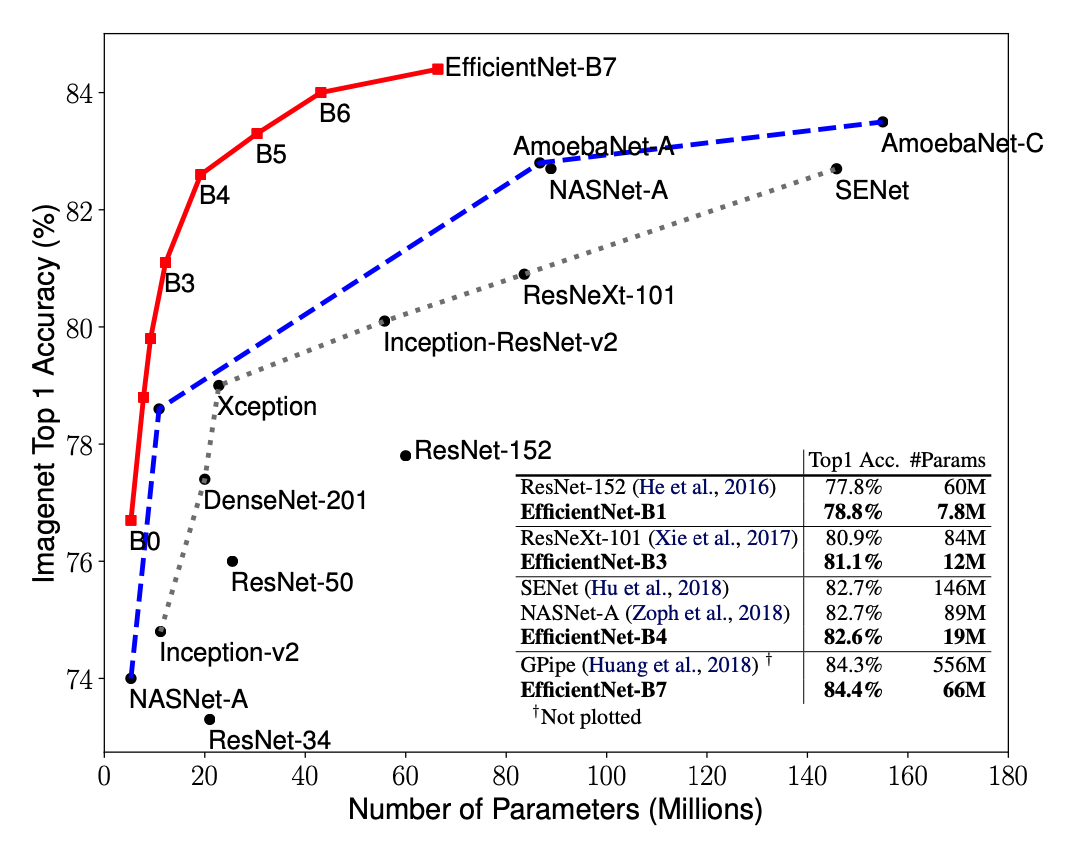
EfficientNet的主要创新点并不是结构,不像ResNet、SENet发明了shortcut或attention机制,EfficientNet的base结构是利用结构搜索搜出来的,然后使用compound scaling规则放缩,得到一系列表现优异的网络:B0~B7. 下面两幅图分别是ImageNet的Top-1 Accuracy随参数量和flops变化关系图,可以看到EfficientNet饱和值高,并且到达速度快。

原理
增加网络参数可以获得更好的精度(有足够的数据,不过拟合的条件下),例如ResNet可以加深从ResNet-18到ResNet-200,GPipe将baseline模型放大四倍在ImageNet数据集上获得了84.3%的top-1精度。增加网络参数的方式有三种:深度、宽度和分辨率。
深度是指网络的层数,宽度指网络中卷积的channel数(例如wide resnet中通过增加channel数获得精度收益),分辨率是指通过网络输入大小(例如从112x112到224x224)
直观上来讲,这三种缩放方式并不不独立。对于分辨率高的图像,应该用更深的网络,因为需要更大的感受野,同时也应该增加网络宽度来获得更细粒度的特征。
之前增加网络参数都是单独放大这三种方式中的一种,并没有同时调整,也没有调整方式的研究。EfficientNet使用了compound scaling方法,统一缩放网络深度、宽度和分辨率。
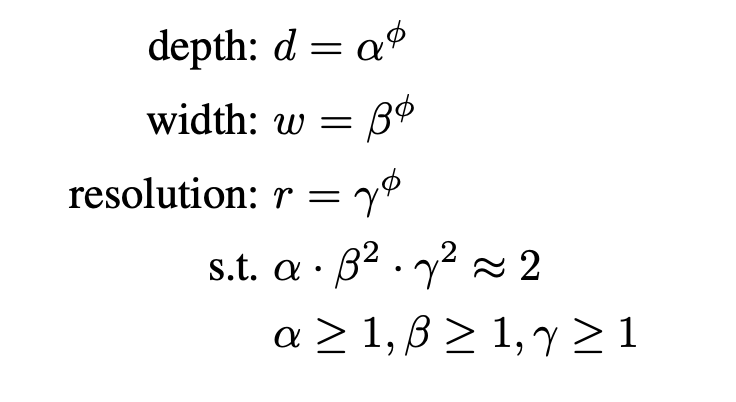
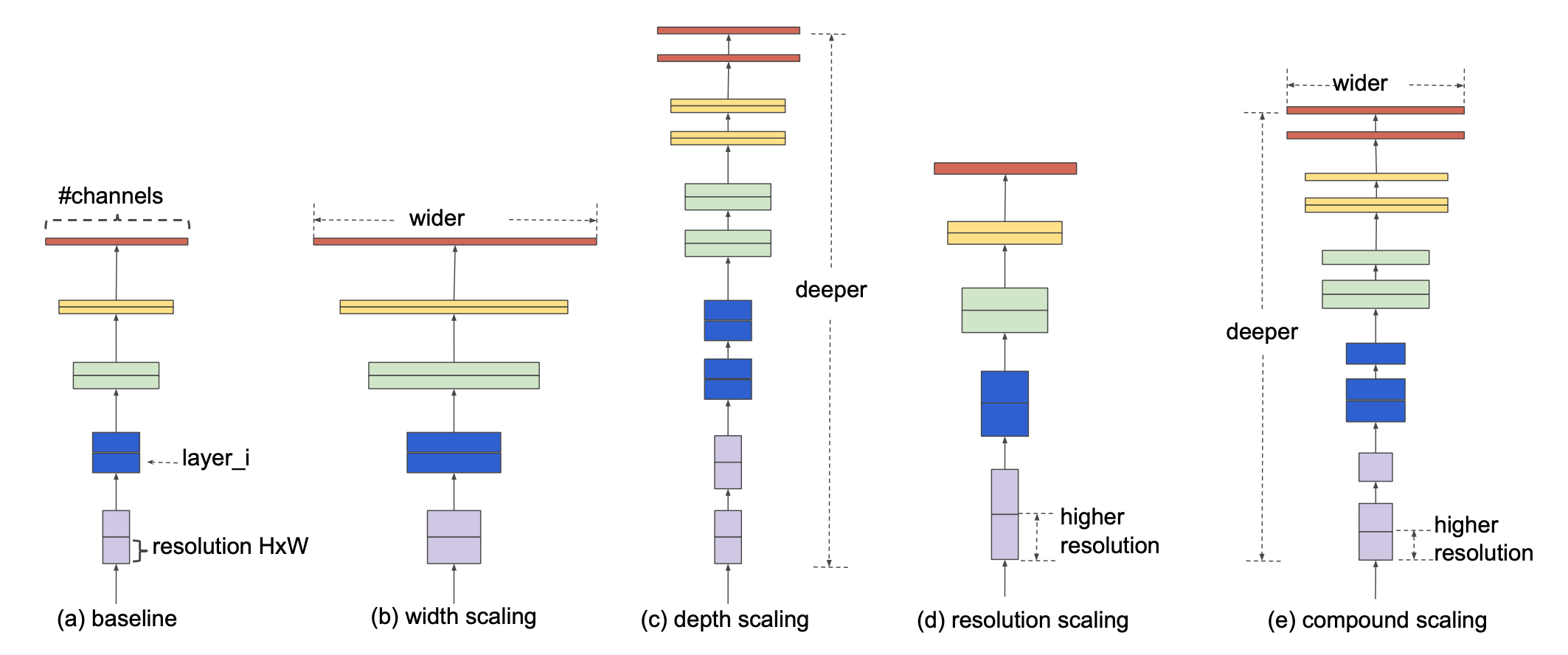
如下图所示,(a)为baseline网络,(b)、(c)、(d)为单独通过增加width,depth以及resolution使得网络变大的方式,(e)为compound scaling的方式。
EfficientNet中的base网络是和MNAS采用类似的方法(唯一区别在于目标从硬件延时改为了FLOPS),使用了compound scaling后,效果非常显著,在不同参数量和计算量都取得了多倍的提升。
网络结构
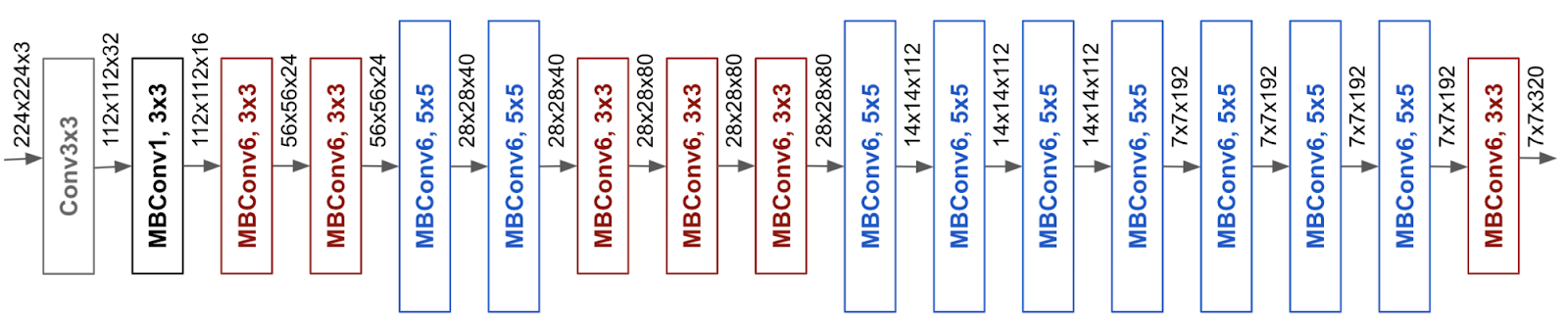
通过网络结构搜索设计了一个baseline网络,也就是EfficientNet-B0,如下图所示,网络结构利用了mobilenetV2的inverted bottleneck MBConv,比较简单以方便后续测试compound model scaling算法的效果。
在优化求解方面,作者提出2步优化,
第一步是固定,然后通过网格搜索找到满足公式3的最优,比如对于EfficientNet-B0网络而言,最佳的参数分别是α=1.2、β=1.1、γ=1.15(此时得到的也就是EfficientNet-B1);
第二步是固定第一步求得的参数,然后用不同的Φ参数得到EfficientNet-B1到EfficientNet-B7网络,最后的实验结果如Table2所示,可以看到EfficientNet系列网络在取得和其他分类网络差不多的准确率时,参数量和计算量都很减少很多。
理论上,假如EfficientNet-B0网络是全卷积,且做scale操作过程中没有小数的取整操作,那么从EfficientNet-B0到EfficientNet-B7网络的FLOPS应该是严格的关系,但从Table2来看显然没有,主要是因为scale过程中的取整操作以及EfficientNet-B0网络并非全卷积结构。
