在正式介绍之前,先简单回顾一下现有的两大类方法。第一大类,也是从非Deep时代,乃至CV初期就被就被广泛使用的方法叫做image pyramid。在image pyramid中,我们直接对图像进行不同尺度的缩放,然后将这些图像直接输入到detector中去进行检测。虽然这样的方法十分简单,但其效果仍然是最佳,也后续启发了SNIP这一系列的工作。单论性能而言,multi-scale training/testing仍然是一个不可缺少的组件。然而其缺点也是很明显的,测试时间大幅度提高,对于实际使用并不友好。
另外一大类方法,也是Deep方法所独有的,也就是feature pyramid。最具代表性的工作便是经典的FPN了。这一类方法的思想是直接在feature层面上来近似image pyramid。非Deep时代在检测中便有经典的channel feature这样的方法,这个想法在CNN中其实更加直接,因为本身CNN的feature便是分层次的。从开始的MS-CNN直接在不同downsample层上检测大小不同的物体,再到后续TDM和FPN加入了新的top down分支补充底层的语义信息不足,都是延续类似的想法。然而实际上,这样的近似虽然有效,但是仍然性能和image pyramid有较大差距。

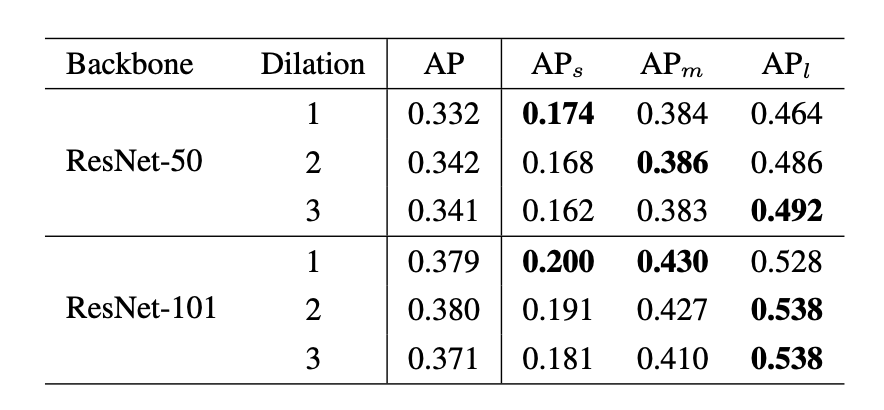
我们考虑对于一个detector本身而言,backbone有哪些因素会影响性能。总结下来,无外乎三点:network depth(structure),downsample rate和receptive field。对于前两者而言,其影响一般来说是比较明确的,即网络越深(或叫表示能力更强)结果会越好,下采样次数过多对于小物体有负面影响。但是没有工作,单独分离出receptive field,保持其他变量不变,来验证它对detector性能的影响。所以,我们做了一个验证性实验,分别使用ResNet50和ResNet101作为backbone,改变最后一个stage中每个3*3 conv的dilation rate。通过这样的方法,我们便可以固定同样的网络结构,同样的参数量以及同样的downsample rate,只改变网络的receptive field。我们很惊奇地发现,不同尺度物体的检测性能和dilation rate正相关!也就是说,更大的receptive field对于大物体性能会更好,更小的receptive field对于小物体更加友好。于是下面的问题就变成了,我们有没有办法把不同receptive field的优点结合在一起呢?
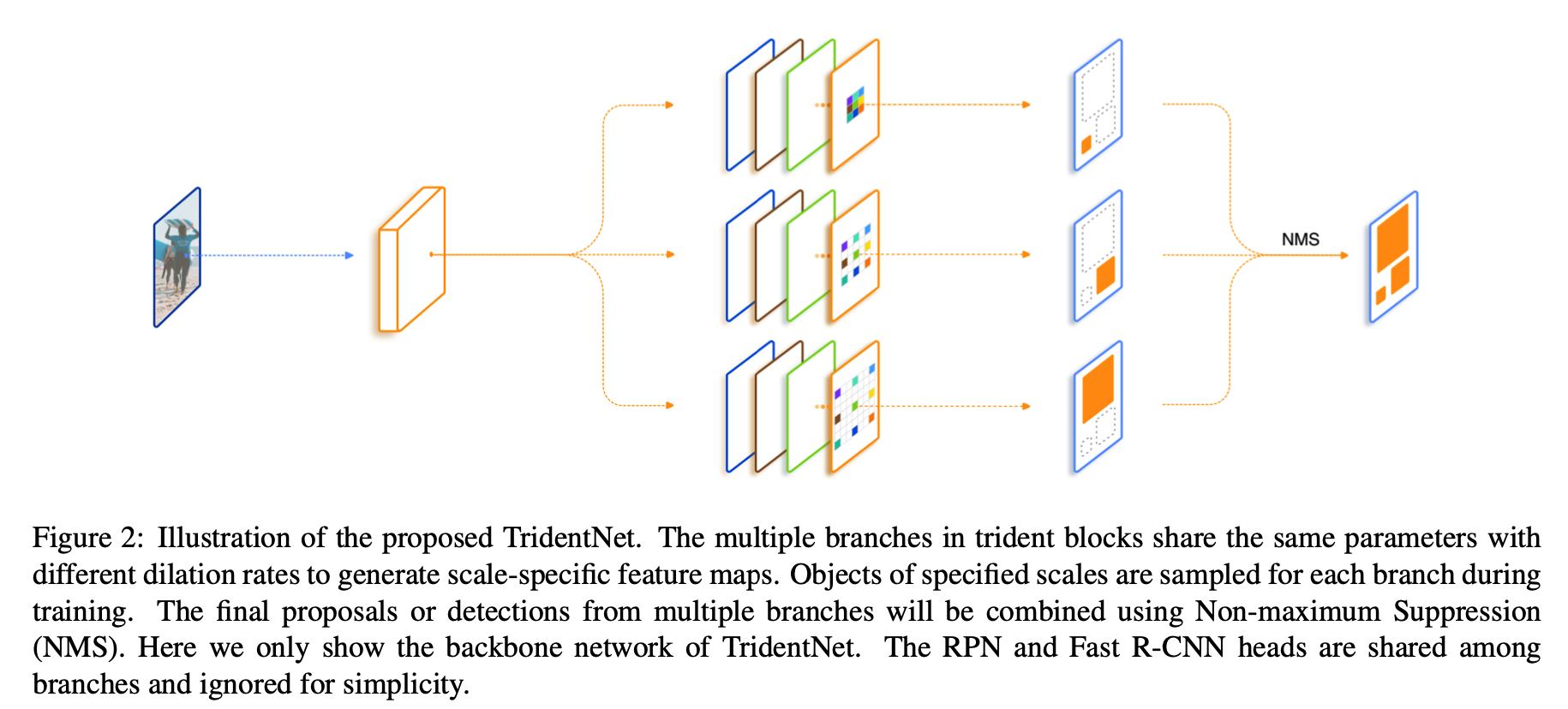
所以我们最开始的一个想法便是直接加入几支并行,但是dilation rate不同的分支,在文中我们把每一个这样的结构叫做trident block。这样一个简单的想法已经可以带来相当可观的性能提升。我们进一步考虑我们希望这三支的区别应该仅仅在于receptive field,它们要检测的物体类别,要对特征做的变换应该都是一致的。所以自然而然地想到我们对于并行的这几支可以share weight。 一方面是减少了参数量以及潜在的overfitting风险,另一方面充分利用了每个样本,同样一套参数在不同dilation rate下训练了不同scale的样本。最后一个设计则是借鉴SNIP,为了避免receptive field和scale不匹配的情况,我们对于每一个branch只训练一定范围内样本,避免极端scale的物体对于性能的影响。总结一下,我们的TridentNet在原始的backbone上做了三点变化:
- 第一点是构造了不同receptive field的parallel multi-branch,
- 第二点是对于trident block中每一个branch的weight是share的。
- 第三点是对于每个branch,训练和测试都只负责一定尺度范围内的样本,也就是所谓的scale-aware。这三点在任何一个深度学习框架中都是非常容易实现的。
在测试阶段,我们可以只保留一个branch来近似完整TridentNet的结果,后面我们做了充分的对比实验来寻找了这样single branch approximation的最佳setting,一般而言,这样的近似只会降低0.5到1点map,但是和baseline比起来不会引入任何额外的计算和参数。
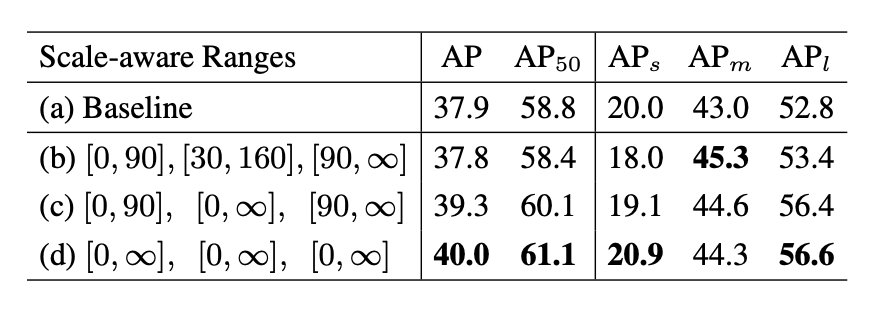
一个值得一提的ablation是,对于我们上面提出的single branch approximation,我们如何选择合适的scale-aware training参数使得近似的效果最好。其实我们发现很有趣的一点是,如果采用single branch近似的话,那么所有样本在所有branch都训练结果最好。这一点其实也符合预期,因为最后只保留一支的话那么参数最好在所有样本上所有scale上充分训练。如果和上文40.6的baseline比较,可以发现我们single branch的结果比full TridentNet只有0.6 map的下降。
这也意味着我们在不增加任何计算量和参数的情况,仍然获得2.1 map的提升。
这对于实际产品中使用的detector而言无疑是个福音。