简介
之前的很多方法都是用RNN的结构去构建时序上的依赖关系,但是RNN的结构的缺点是不能并行操作,且存在梯度消失的现象。所以本文就是将之前的RNN的结构改为Transfomer的形式。延续了之前TRN的整个网络的框架,也是结合了对未来帧的预测与历史帧的表示相结合来对当前的动作进行预测。
方法
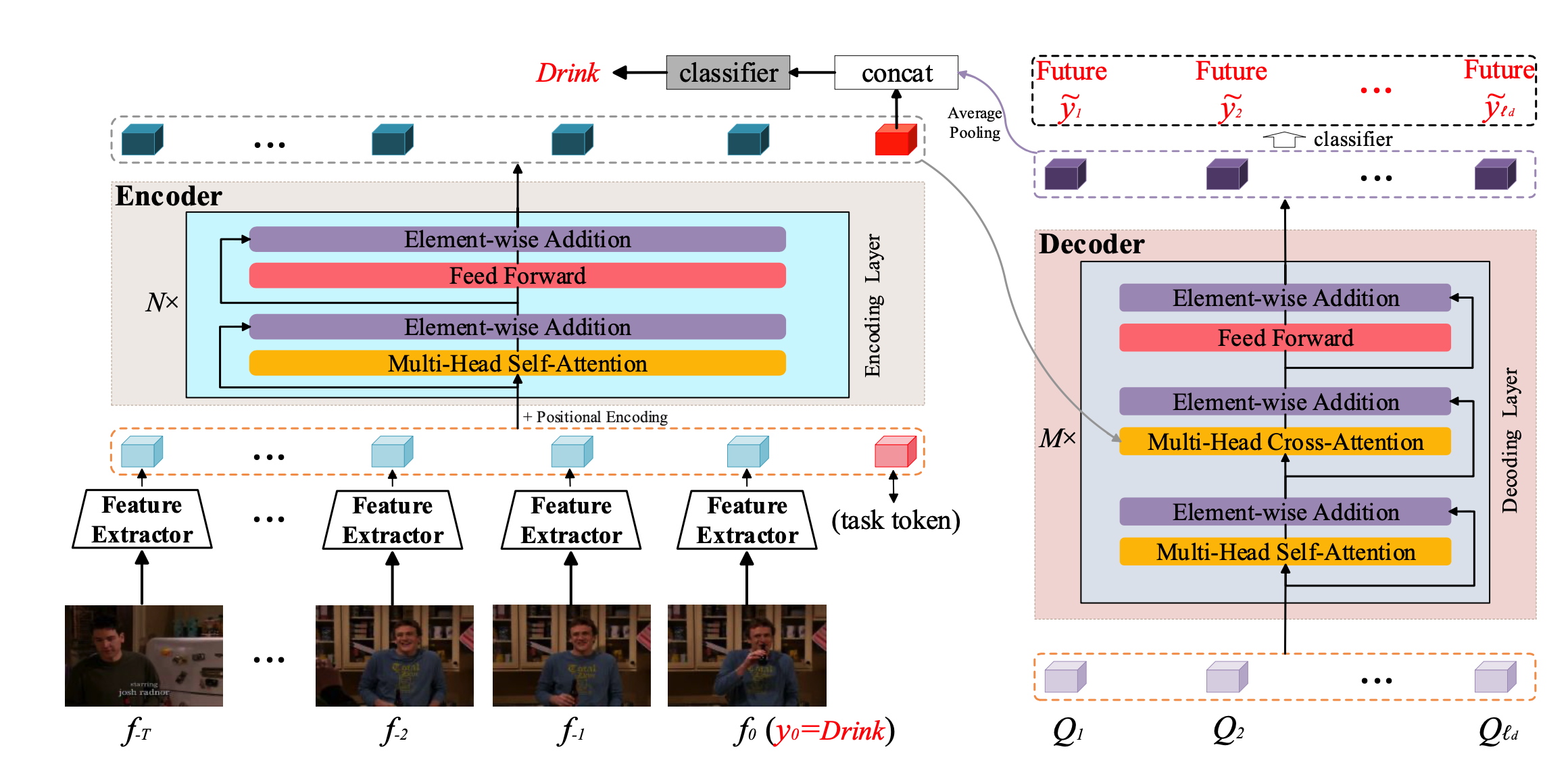
整个网络框架如上图所示,
Encoder就是利用transfomer对long-range的历史和目前帧进行特征表示,其中要说明的一个点就是,这里的特征空间包含T个历史特征,当前窗口的特征以及一个task token,这个task token的作用可以从下图看出来
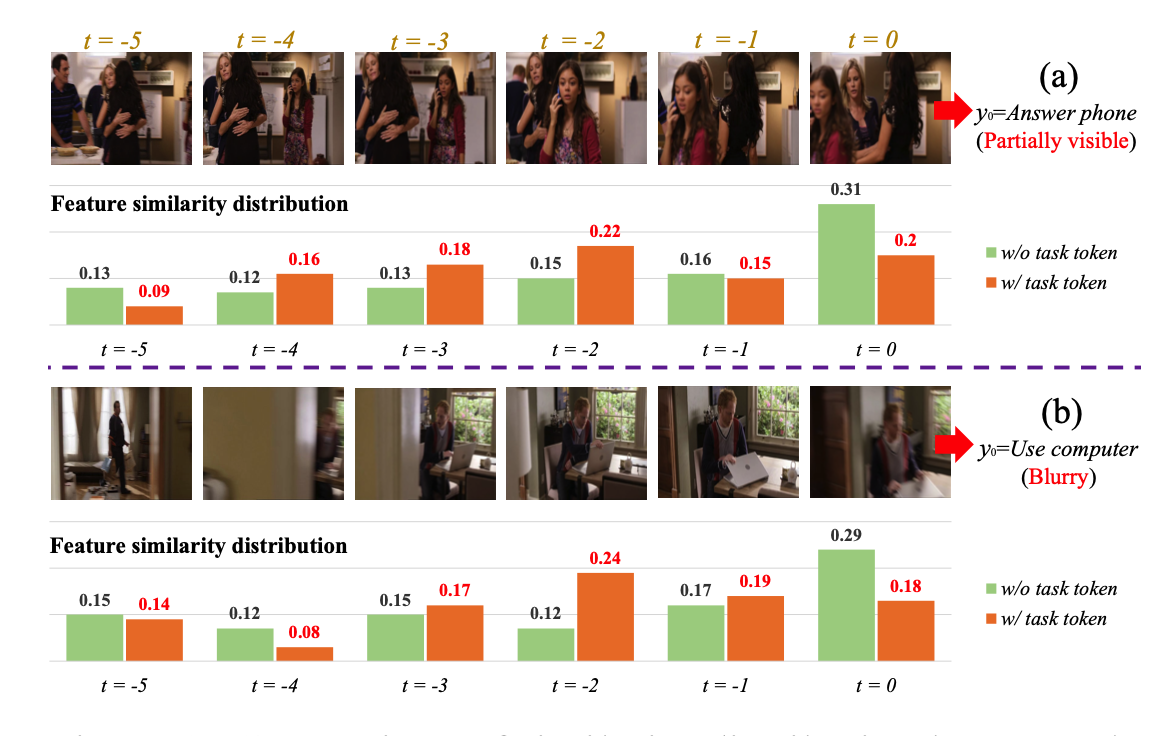
这幅图对比的是输入进classifier的特征与网络输入的特征的相似性,可以看出w/o task token 对应的是当前t=0时刻的特征,而w/ task token 对应的是历史帧中最具判别性的特征
直观上看,如果这里没有tokenclass,其他token得到的最终特征表示必然会整体偏向这个指定的token,从而不能用来表示当前动作的特征。 相比之下,tokenclass的语义embedding可以通过与encoder中的其他token自适应交互得到,更适合特征表示