Motivation
Motion feature 学习过程中存在的问题:
- 利用 optical flow 存储和计算的开销太大
- 现阶段的网络设计,spatio-temporal 建模 和Motion feature 建模分离
- 比如STM 直接 Add spatio temporal feature 和 motion encoding feature
- TEA 的 ME 则利用了 Motion feature 做 channeI attention
-
过去的建模都 focus 在 frame-level motion,更好的建模方式 feature-level motion
长时建模存在的问题: -
单帧过backbone,最后的feature 进行 temporal max/average pooling 做late fusion
- stack Local 3D/(2+1)D 通过网络深度增加感受野来构建时序关系——会造成优化的困难
网络结构
TEA 由 ME和MTA两个模块构成:
motion excitation (ME) module
用于建模feature level的时序变化 short-range motion
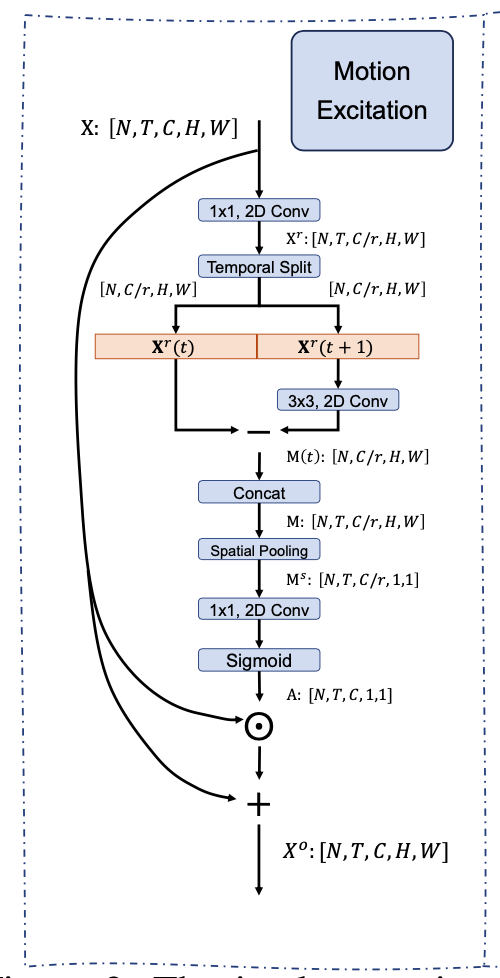
设计细节:
- 引入 reduction radio \(r=16\),利用 \(1\times 1\) 卷积降低channel数量
- 参考STM,feature在时序上进行diff(相减)建模motion信息,其中利用了一个channel-wise的 \(3\times 3\) 卷积,可以match regions of the same object from contexts ,避免直接相减造成feature的dispalce,也可以理解为一种修正或者平滑的操作。
- 利用 motion-attentive weights A 对原始feature进行channel-attention,这里使用sigmoid function 作为激活函数。
- 相比于 SENet 增加一个residual connection 增强 motion information 同时保持 scene information(背景信息)不丢失,\(\bigodot\) 表示 channel-wise multiplication.
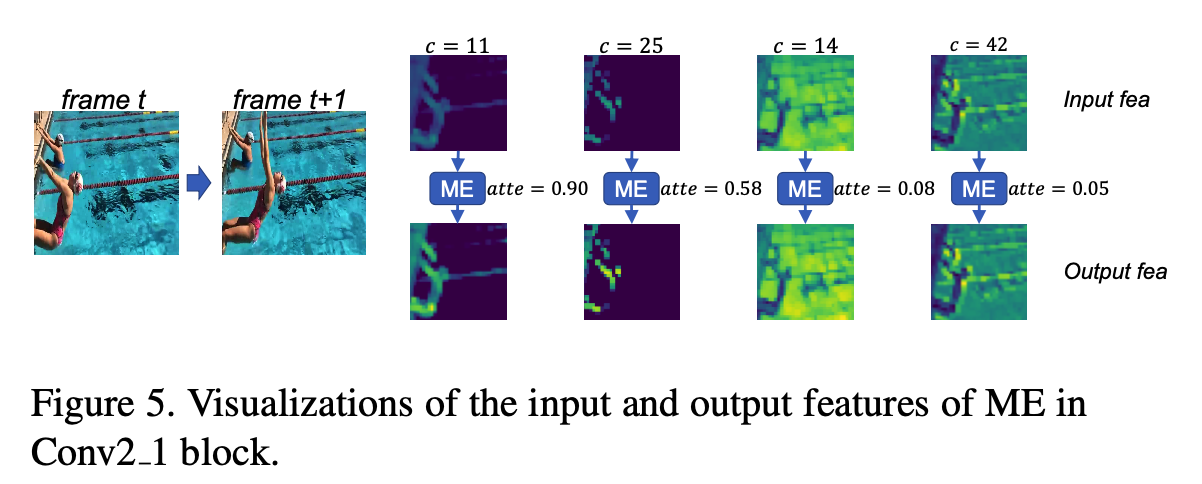
由上图可知,不同 channel的feature不同,motion-attention的操作会使用a large attention weight加强motion channel ,lower attention weight抑制background channel,
multiple temporal aggregation (MTA) module
用于进行 long-range temporal aggregation
stack Local 3D/(2+1)D 通过网络深度增加感受野来构建时序关系——会造成优化的困难
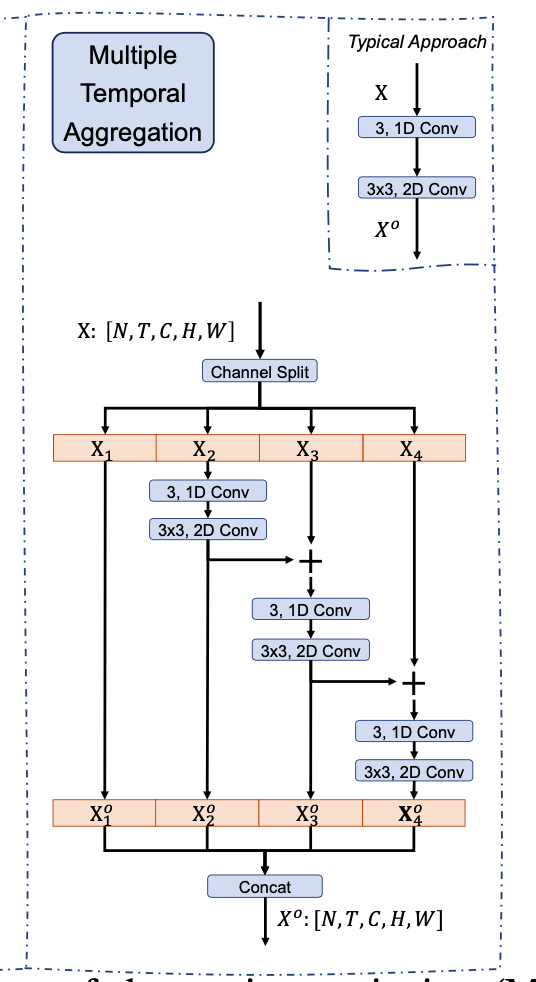
设计细节:
- 参考 Res2Net 进行设计,增加 group 、hierachical residual architecture 、cascade.
- 不增加参数、增加少量时间——来自于cascade结构,这种multiple stage的融合需要sequentially process
- 根据ablation study,纯Res2Net结构,只能对spatial的feature 进行建模,缺少temporal modeling,所以split the feature into four fragments along the channel dimension后,额外增加了一个 channel-wise 的 \(1\times 1\times 3\) 的时序卷积。注意进行 temporal convolution之前要先reshape \([N,T,C,H,W]\Rightarrow[NHW,C,T]\)
- 最后 concat feature \(X^o=[X_1^o;X_2^o;X_3^o;X_4^o],\ \ \ \ \ X^o\in\mathbb{R}^{N\times T\times C\times H\times W}\)
TEA block
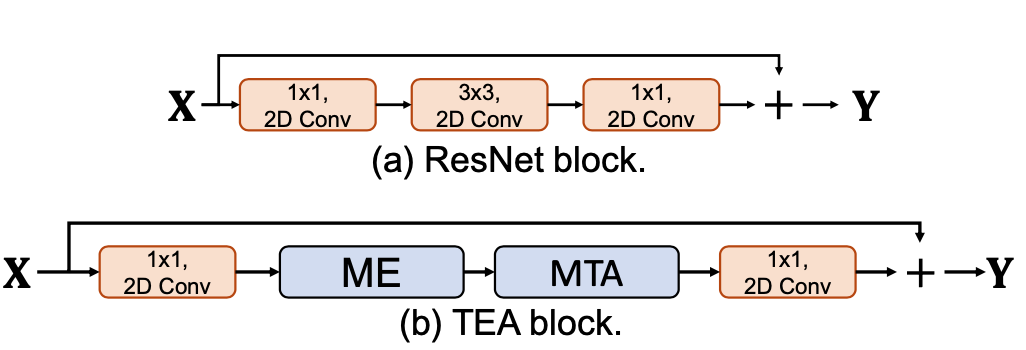
TEA block 放在 later stage 效果更好,更能有效进行long-range temporal aggregation