简介
这篇ECCV2016的文章主要提出TSN(temporal segment network)结构用来做视频的动作识别。TSN可以看做是双流(two stream)系列的改进,在此基础上,文章要解决两个问题:1、是long-range视频的行为判断问题(有些视频的动作时间较长)。2、是解决数据少的问题,数据量少会使得一些深层的网络难以应用到视频数据中,因为过拟合会比较严重。
针对第一个问题,首先,为什么目前的双流结构网络难以学习到视频的长时间信息?因为其针对的主要是单帧图像或者短时间内的一堆帧图像数据,但这对于时间跨度较长的视频动作检测而言是不够的。因此采用更加密集的图像帧采样方式来获取视频的长时间信息是比较常用的方法,但是这样做会增加不少时间成本,同时作者发现视频的连续帧之间存在冗余,因此想到用稀疏采样代替密集采样,也就是说在对视频做抽帧的时候采取较为稀疏的抽帧方式,这样可以去除一些冗余信息,同时降低了计算量。
针对第二个问题,可通过常规的数据增强方式,比如随机裁剪,水平翻转等;另外还有作者提到的交叉预训练,dropout等方式来减少过拟合。这些后面会详细解释。
Temporal Segment Networks
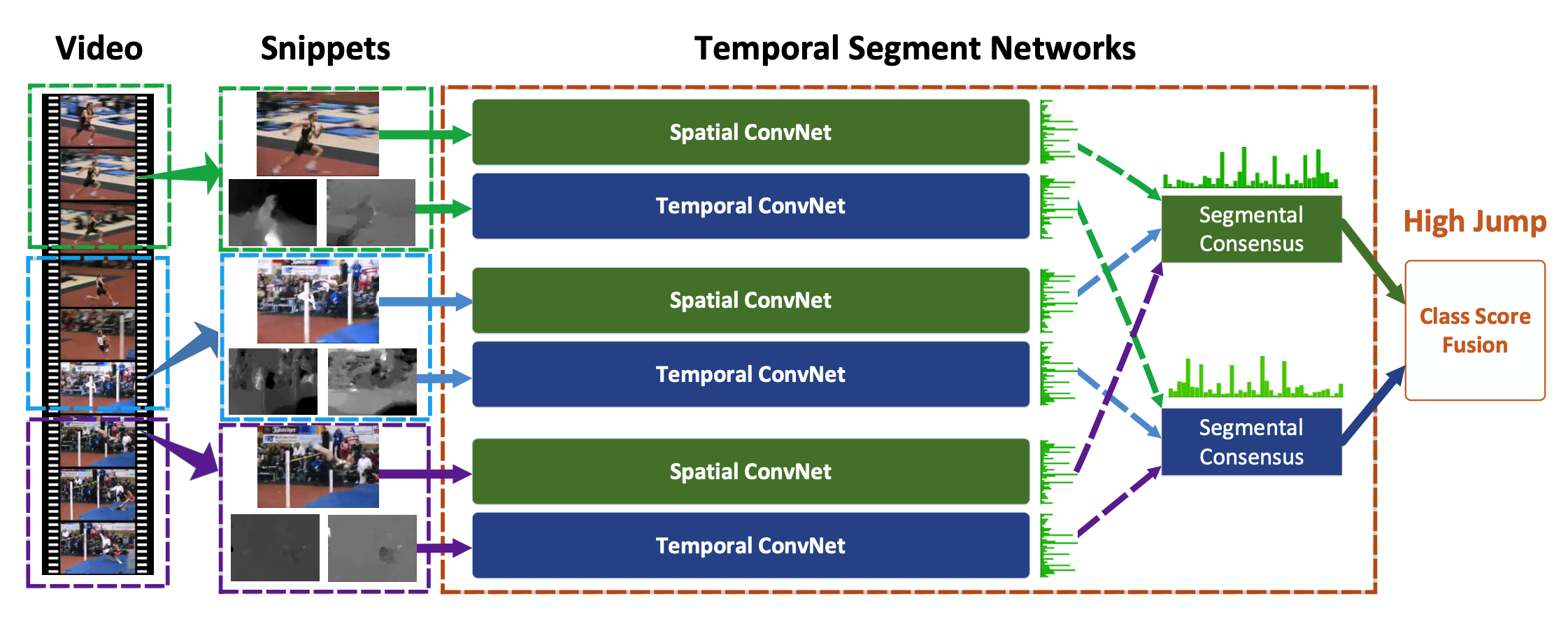
上图就是作者提出的TSN网络。网络部分是由双路CNN组成的,分别是spatial stream ConvNets和temporal stream ConvNets,这和双流网络文章中介绍的结构类似,在文中这两个网络用的都是BN-Inception(双流论文中采用的是较浅的网络:ClarifaiNet)。那么这两路CNN以什么为输入呢?spatial stream ConvNets以单帧图像作为输入,temporal stream ConvNets以一系列光流图像作为输入,换句话说两个网络的输入类型是不一样的。
当然最重要的是temporal segment network(包含多个spatial stream convnet和temporal convnet,参看Figure1)的输入不是单帧图像或短时间内的一堆图像帧,而是从视频中稀疏采样得到的一系列snippets,这就是为了获取视频的长时间信息所做的改进。
Figure1的最左边是一个Video,用 表示,将 分成 份(文中采用3),用()表示。这样TSN网络就可以用下面这个式子表示:
这里的()表示 个snippets,snippets翻译过来也是小片段,也就是说 是从 中对应的视频片段中随机采样出来的结果,是一个snippet,每个snippet包含一帧图像和两个光流特征图。这也就完成了作者说的稀疏采样。上面式子中的 就是网络的参数,因此 就是网络的输出,也就是该snippet属于每个类的得分。 函数的输出结果就是上图中spatial convnet或temporal convnet的输出结果,可以看上图中convnet图后面的绿色条形图,代表的就是socre在类别上的分布。 是一个融合函数,在文中采用的是均值函数,就是对所有snippet的属于同一类别的得分做个均值,毕竟我们最后要求的是这个video属于哪个类别,而不是这个video的某个snippet属于哪个类别。 函数的输出结果就是图中segmental consesus的输出结果。最后用 函数(文中用的softmax函数)根据得分算概率,概率最高的类别就是该video所属的类别。注意,在输入softmax之前会将两条网络的结果进行合并,默认采用加权求均值的方式进行合并,文中用的权重比例是spatial:temporal=1:1.5。另外需要强调的是:图中的 个spatial convnet 的参数是共享的,K个temporal convnet的参数也是共享的,实际用代码实现时只是不同的输入过同一个网络。
网络采用交叉熵Loss,损失函数如下(standard categorical cross-entropy),表示类别数,是标签。
其中表示:
也就是说 是一个长度为C的向量,表示一个video属于每个类别的得分。
模型训练
由于视频样本较少,训练较深的ConvNet可能会过拟合。为了解决该问题,作者提出了如下的策略:
- 跨模态预训练:RGB网络可以使用ImageNet预训练,但是光流网络没有预训练的数据集,所有作者采用ImageNet上预训练的参数来初始化光流模型参数。
- 正则化:
Batch Normalization用来解决协变量偏移的问题。在学习过程中,BN将估计每批中的激活均值和方差,并使用它们将这些激活值转换为标准高斯分布。该操作会使得模型收敛速度变快,但是同时会带来了过拟合的问题。因此,作者通过固定住除了第一层以外,其他层的BN参数(partial BN),来解决该问题。而且,作者在BN-Inception模型后面加入了dropout层,来解决过拟合的问题。
数据增强:random cropping、horizontal flipping、corner cropping、scale jittering。