Related Work:
大概过一下之前的几个重要工作(也是本文性能对比的主要几个state-of-the-art):
- TSN:视频动作/行为识别的基本框架,将视频帧下采样(分成K个Segment,各取一帧)后接2D CNN对各帧进行处理+fusion
- TRN:对视频下采样出来的 frames 的deep feature,使用 MLP 来融合,建立帧间temporal context 联系。最后将多级(不同采样率)出来的结果进行再一步融合,更好表征short-term 和 long-term 关系。
- ECO系列:
- NL I3D+GCN:使用 non-local I3D来捕获long-range时空特征,使用 space-time region graphs 来获取物体区域间的关联及时空变化。
算法框架
Intuition
为了解决上述的3D卷积运算量问题,作者提出了可嵌入到2D CNN中的 TSM 模块。作者发现:一般的卷积操作,可以分解成 位移shift + 权值叠加 multiply-accumulate 两个过程。
比如说对一个1D vector X 进行 kernel size=3 的卷积操作 可以写成:
故分解后的两个操作分别为:
- 位移(基本不消耗计算资源,常规地址偏移指针操作)
- 权值叠加
故作者认为,设计TSM模块时候,尽可能多使用位移操作(几乎0计算量),把权值叠加操作放到2D CNN本身的卷积里去做,这样就可在不加任何参数计算量基础上,实现更多功能。
TSM模块
那么问题来了,怎么在时空建模的视频理解任务里,用好这个位移操作呢?
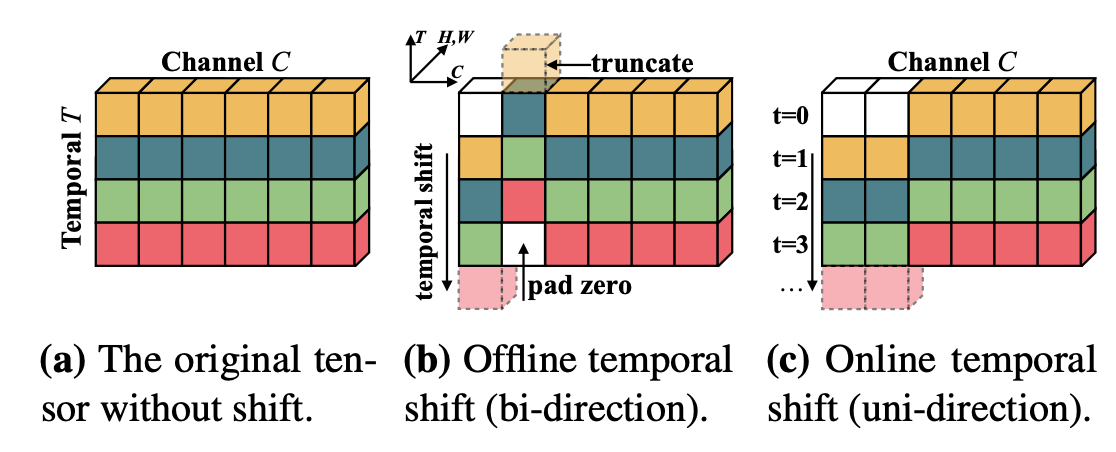
上图中最左边的二维矩阵是 时刻 tensor中 temporal和 channel维度(不需要考虑 batch 和 spatial 维度先); 中间是通过TSM模块位移后的的矩阵,可见第一个channel向前位移一步来表征的 feature maps,而第二个channel 则向后位移一步来表征 ,最后位移后的空缺 padding补零;右边的与中间的类似,不过是 online的形式,所以只考虑向前做位移。
这里就涉及一个超参:究竟多少比例的channel进行 temporal shift 才比较合适呢?
作者也考虑到了这个问题,因为如果太多channel进行时间位移,那么原始固定时刻帧的 2D CNN空间特征就会受到损害,但如果太少channel进行时间位移,那么网络又会因temporal上下文交互太少而学不到准确的temporal representation。
为了解决这个问题,作者提出了残差TSM,这样就可以整合位移前后的特征。
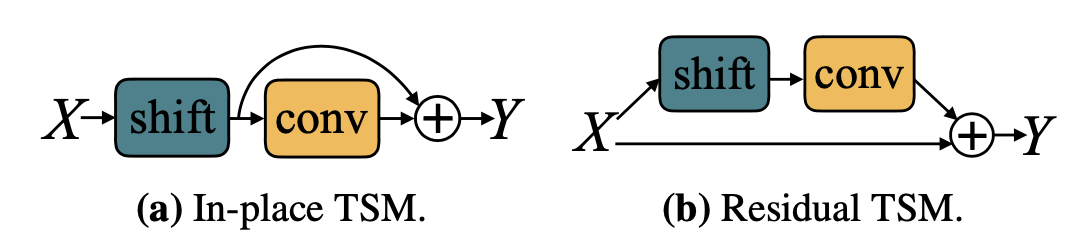
本文中的TSM是基于ResNet实现的,往ResNet里加shift,最直接的方法是在每一次卷积或者每一个residual block前做移动,我们称之为In-place TSM。以这种方式做卷积时,移动的操作是丢失了时刻上的空间信息的。因此,我们采取不同的办法,如(b)所示,将shift操作放到残差值中,另一支不动,以保留某一帧原始的空间信息,这样可以避免伤害到原来的2D CNN模型的空间特征学习能力,我们称之为Residual TSM。这里解释一下,为何每个卷积层或block都要做shift,而不是直接在开始就shift后面不再使用。这是因为,每做一次+-1的shift操作,时域上的感受野都会扩大两倍。已知ResNet本身随着网络的加深,空间感受野会越来越大,看到的信息越来越多。要在时序上也模拟这种情况,就得随着网络的加深扩大感受野,相当于让时域上看到的信息也越来越多,以模拟时序卷积的过程。
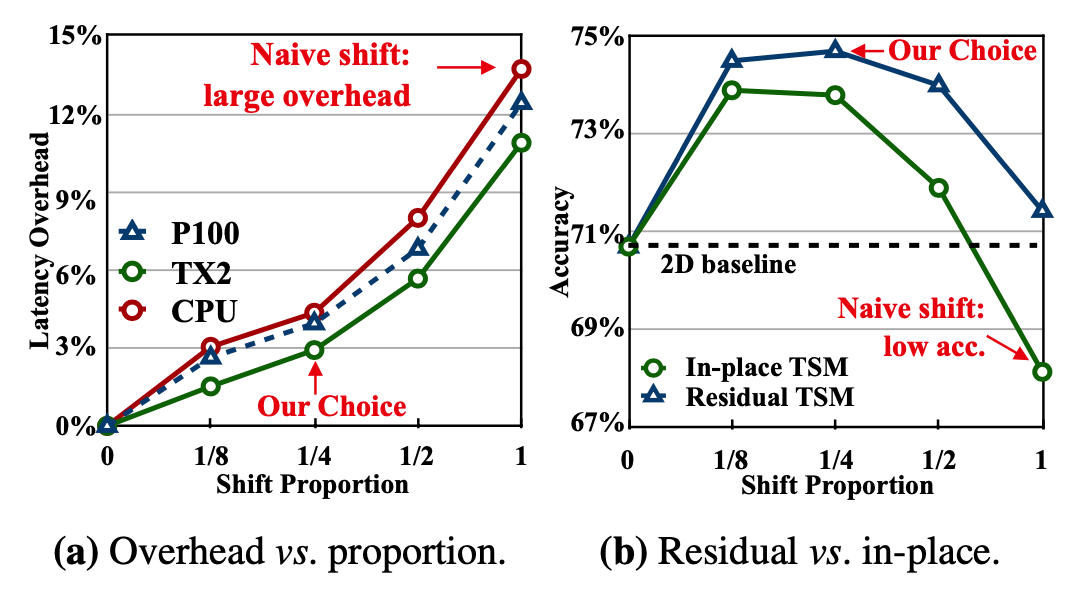
上图(b)比较了In-place TSM和Residual TSM的效果。实验显示,在所有的shift比例上,residual的方式都领先于in-place,并且,即使是做naive shift,它也能比2D baseline TSN好。利用这个实验,我们也可以结合时延实验对shift比例做选择,shift part比例在1/4的时候accuracy效果最好,而此时模型在各种设备上的时延也可以接受,因此后面的实验都是选择移动1/4的比例(1/8 for each direction)。
到这里,模型设计就介绍完了,我们串一下整个视频分类任务的流程。对于一个视频V,抽取T帧作为采样,记为。在每一帧上,我们都在处理它的2D CNN里加上TSM操作,每个帧得到一个预测的output,再把所有帧的output aggregate起来,可采用average之类的方法,从而得到预测。
shift 操作可以认为是一种特殊的1D conv

这种特殊的1D conv可以通过以下的方式进行构建:
- FC 层的 lr 和 weight decay 设置为其他layer的5倍
- HMDB-51 UCF-101 中的 BN 层除了第一层之外全部frozen
class TemporalShift(nn.Module):
def __init__(self, net, n_segment=3, n_div=8, inplace=False):
super(TemporalShift, self).__init__()
self.net = net
self.n_segment = n_segment
self.fold_div = n_div
self.inplace = inplace
if inplace:
print('=> Using in-place shift...')
print('=> Using fold div: {}'.format(self.fold_div))
def forward(self, x):
x = self.shift(x, self.n_segment, fold_div=self.fold_div, inplace=self.inplace)
return self.net(x)
@staticmethod
def shift(x, n_segment, fold_div=3, inplace=False):
nt, c, h, w = x.size()
n_batch = nt // n_segment
x = x.view(n_batch, n_segment, c, h, w)
fold = c // fold_div
if inplace:
out = InplaceShift.apply(x, fold)
else:
out = torch.zeros_like(x)
out[:, :-1, :fold] = x[:, 1:, :fold] # shift left
out[:, 1:, fold: 2 * fold] = x[:, :-1, fold: 2 * fold] # shift right
out[:, :, 2 * fold:] = x[:, :, 2 * fold:] # not shift
return out.view(nt, c, h, w)