简介
这篇文章主要的动机是,之前的RNN,LSTM,GRU这样的循环结构中,循环单元累计历史输入,但忽视了其与当前动作的联系,所以不能得到一个有效的判别性的表示。
Specifically, the recurrent unit accumulates the input information without explicitly considering its relevance to the current action, and thus the learned representation would be less discriminative.
所以, 这篇文章就是在探索是否可以学习一个判别性较强的表示区分相关和不相关的信息以检测当前要动作。
how RNNs can learn to explicitly discriminate relevant information from irrelevant information for detecting actions in the present.
方法
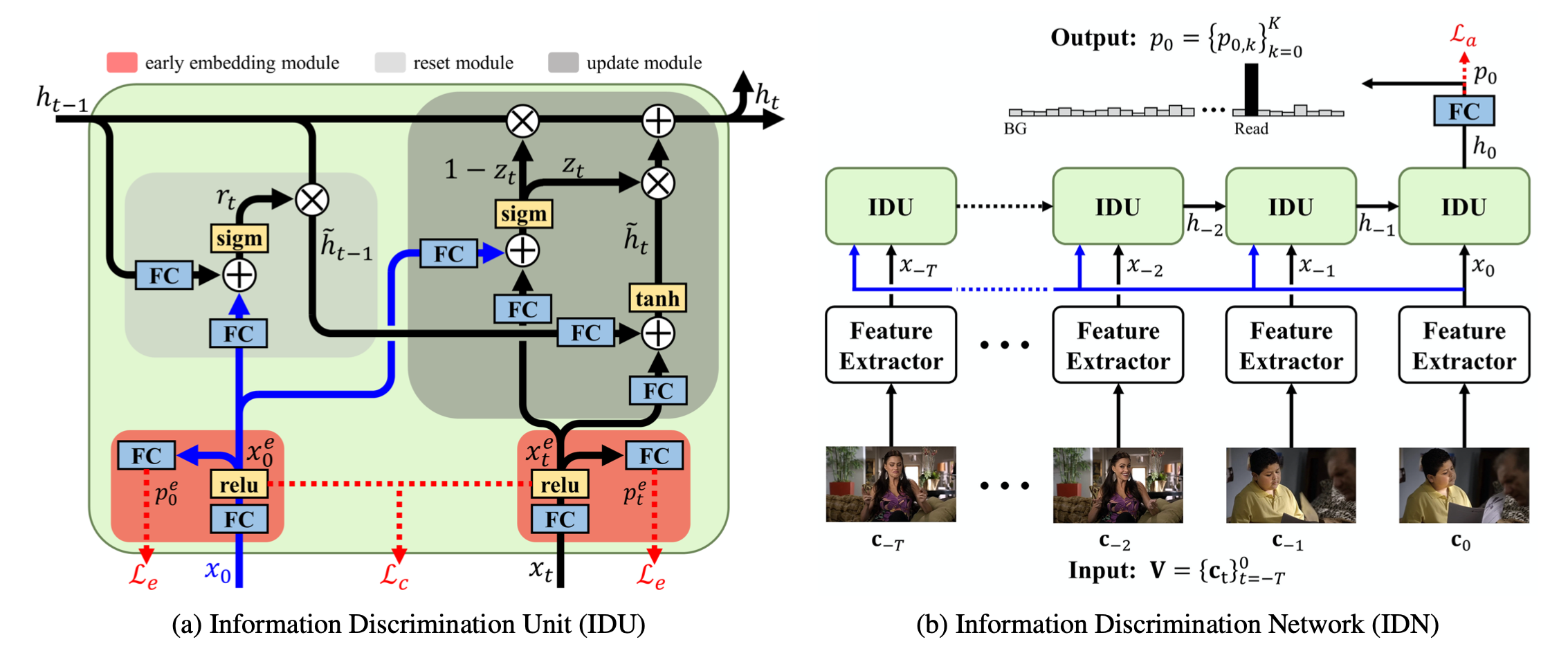
文章基于GRU提出了一个 Information Discrimination Unit (IDU)来实现上述的想法。
GRU
首先回顾一下GRU:
reset gate 决定之前的状态 是否忽略。
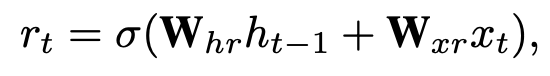
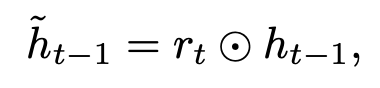
同样,update gate 决定 是否用一个新的状态函数 来更新。

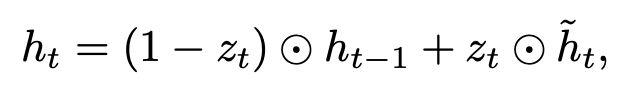
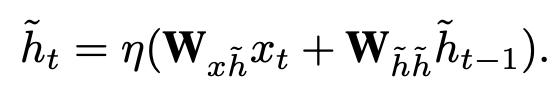
IDU
IDU在GRU的基础上增加了一个模块:**Early Embedding Module, **具体如下:
模块的输入为当前时刻特征 和所有时刻特征 ,输出为特征embedding 和
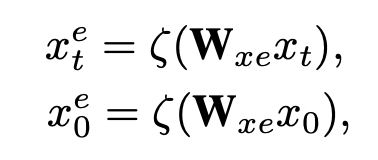
为了让特征embedding学习到相应action的表示,作者引入了两个loss去监督学习。
- 第一个为multi-class ce 进行分类
- 第二个为为了让特征更具判别性,作者加入了contrastive loss
而 reset gate 和 update gate 和GRU相似,只不过输入不同,和他们的motivation一样,reset gate是把当前时刻特征 和上一步的隐藏状态特征 作为输入,具体如下:
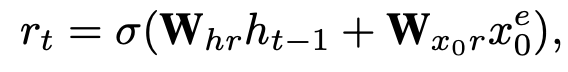

update gate是把当前时刻特征 和之前时刻特征 作为输入,具体如下:
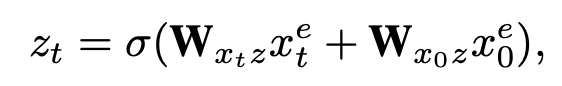

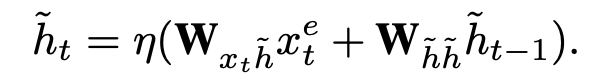
IDN
- 网络输入:当前和之前 个时刻的chunks , 。其中,每个chunk定义为 为个连续帧。
- 网络输出:当前时刻K个action的概率,$p_0 = \{p_{0,k}\}^K_{k=0}
$
- 特征提取:TSN
- 网络训练: 接FC得到action的类别概率 , 分类loss 为ce
实验
ablation study
一个有意思的实验设置是,作者设定了一个 , 代表与当前时刻action一样的历史时刻为1,否则为0,来证明IDU有效的模拟了输入信息与正在进行的动作相关性。

Performance Comparison
下面这个表,代表只看见部分action时,识别的准确率