概述
在计算机视觉领域(CV),对视觉特征的理解CNN是长期处于主导地位的。而在NLP领域,Transformer框架的巨大成功,也激发了不少研究者探索将Transformer用于计算机视觉任务。ViT(Vision Transformer)的出现标志着在CV领域Transformer架构迈出了重要的一步。尤其在当前结合LLM的多模态探索上(MM-LLM),都是以LLM大语言模型为骨干架构的模型,多种模态的信息需要先做token化处理,再输入到LLM模型。ViT天然具有序列化特征的建模能力,自然在MM-LLM探索中大放异彩~
ViT在多模态模型中的角色类似于自然语言建模中的Tokenizer组件,对图像进行视觉特征编码,产出图像的序列特征。只不过ViT的编码过程本身也是采用了Transformer的模型结构。
本文主要结合几篇paper和源码讲讲ViT和针对ViT的一些优化方法~
ViT(Vision Transformer)
ViT说起来比较简单,将图片分割成多个图像块(Patch),然后针对每个Patch通过一系列线性映射,转化成token,再将所有token拼接成序列,最终将一张图片从 \((H,W,C)\) 格式转换成 \((S,H)\) 格式的序列特征。操作过程如下图所示:
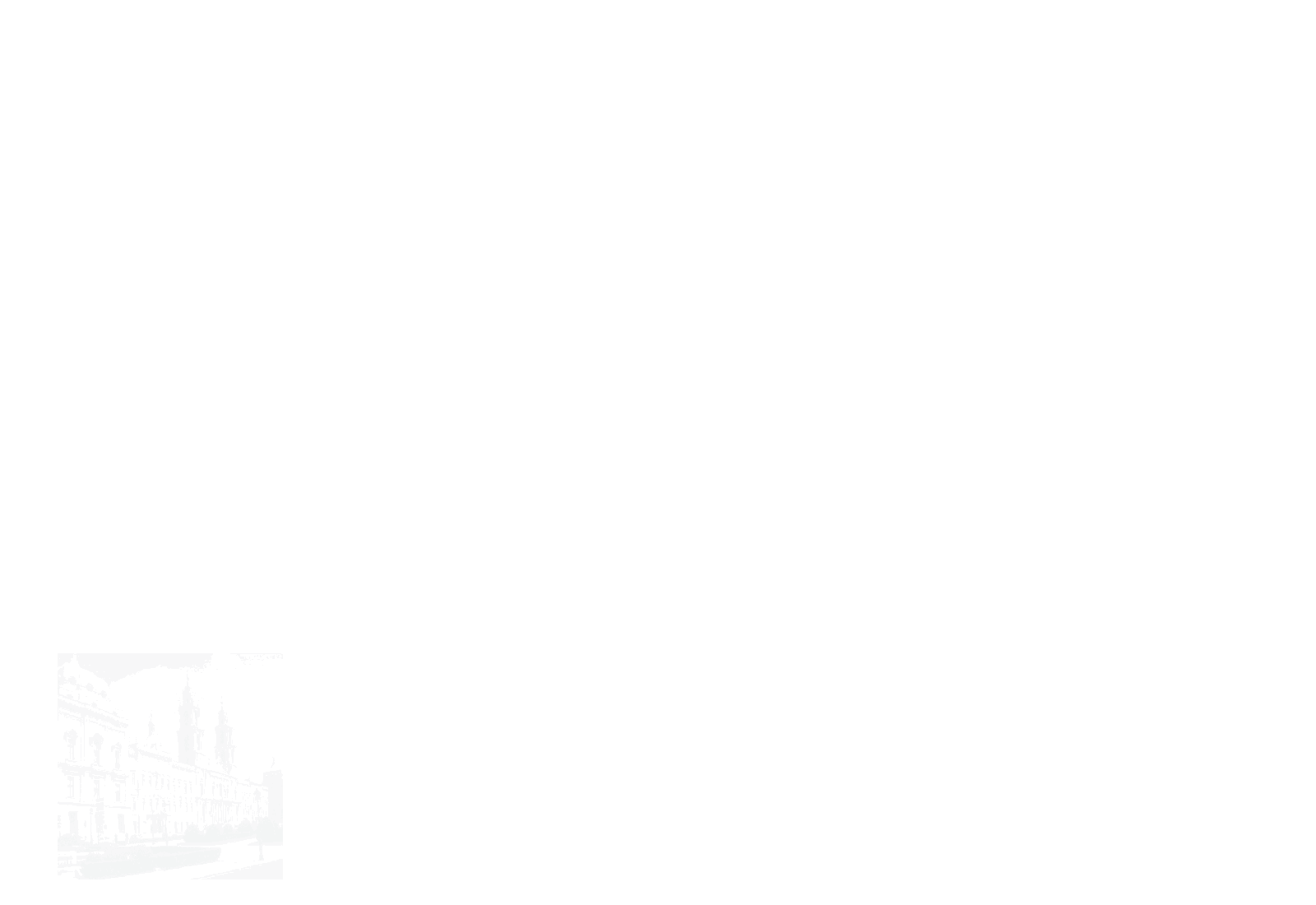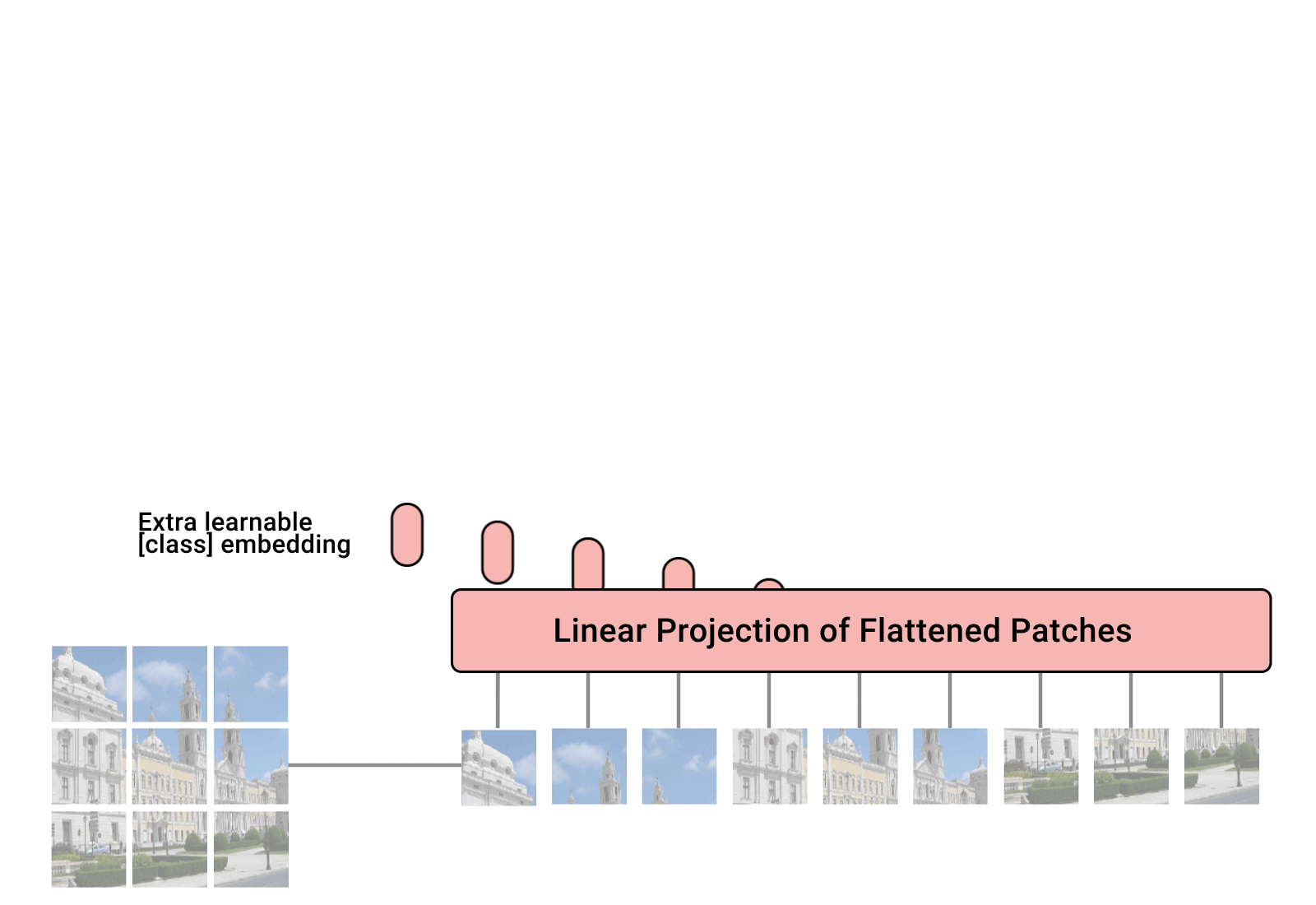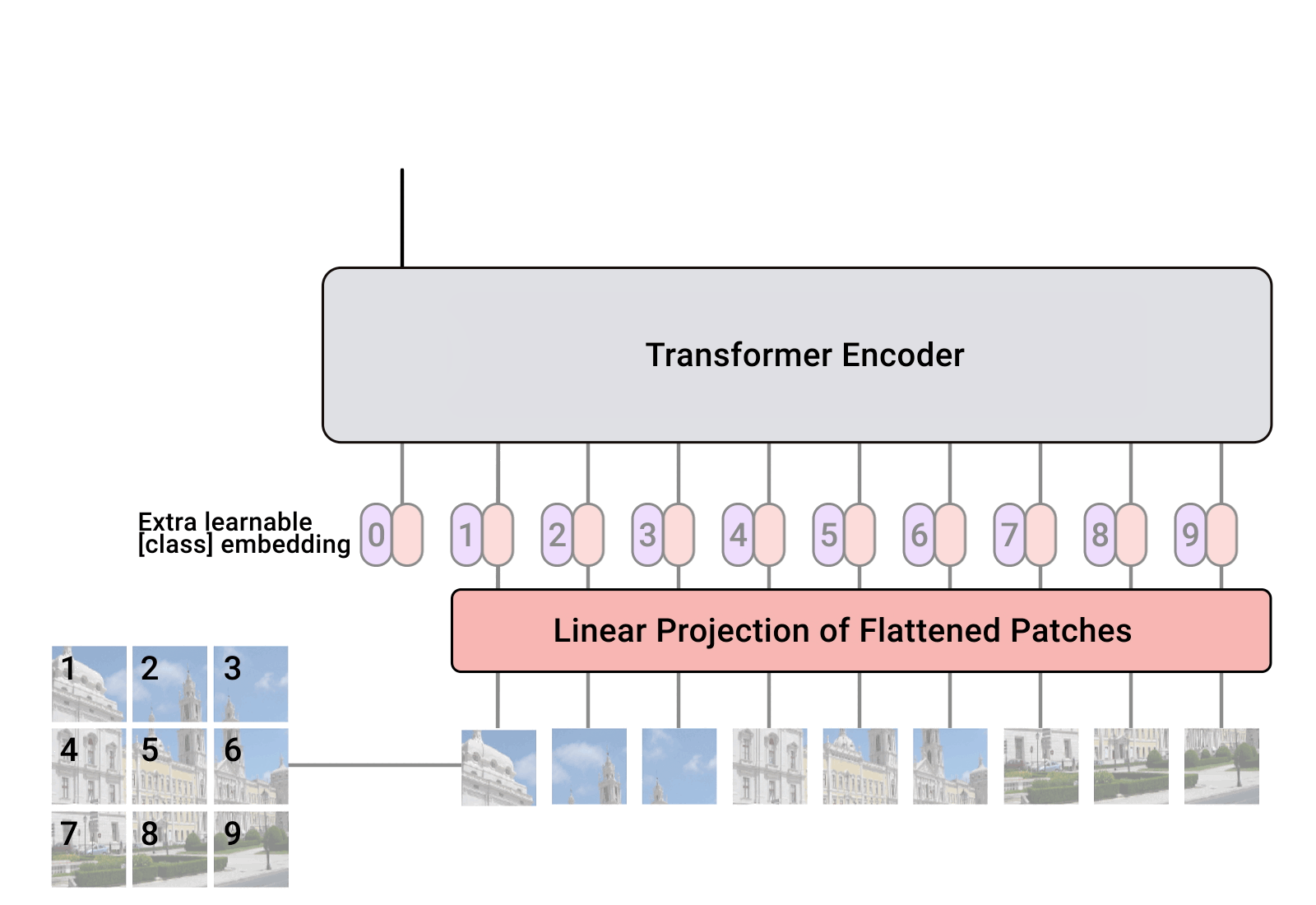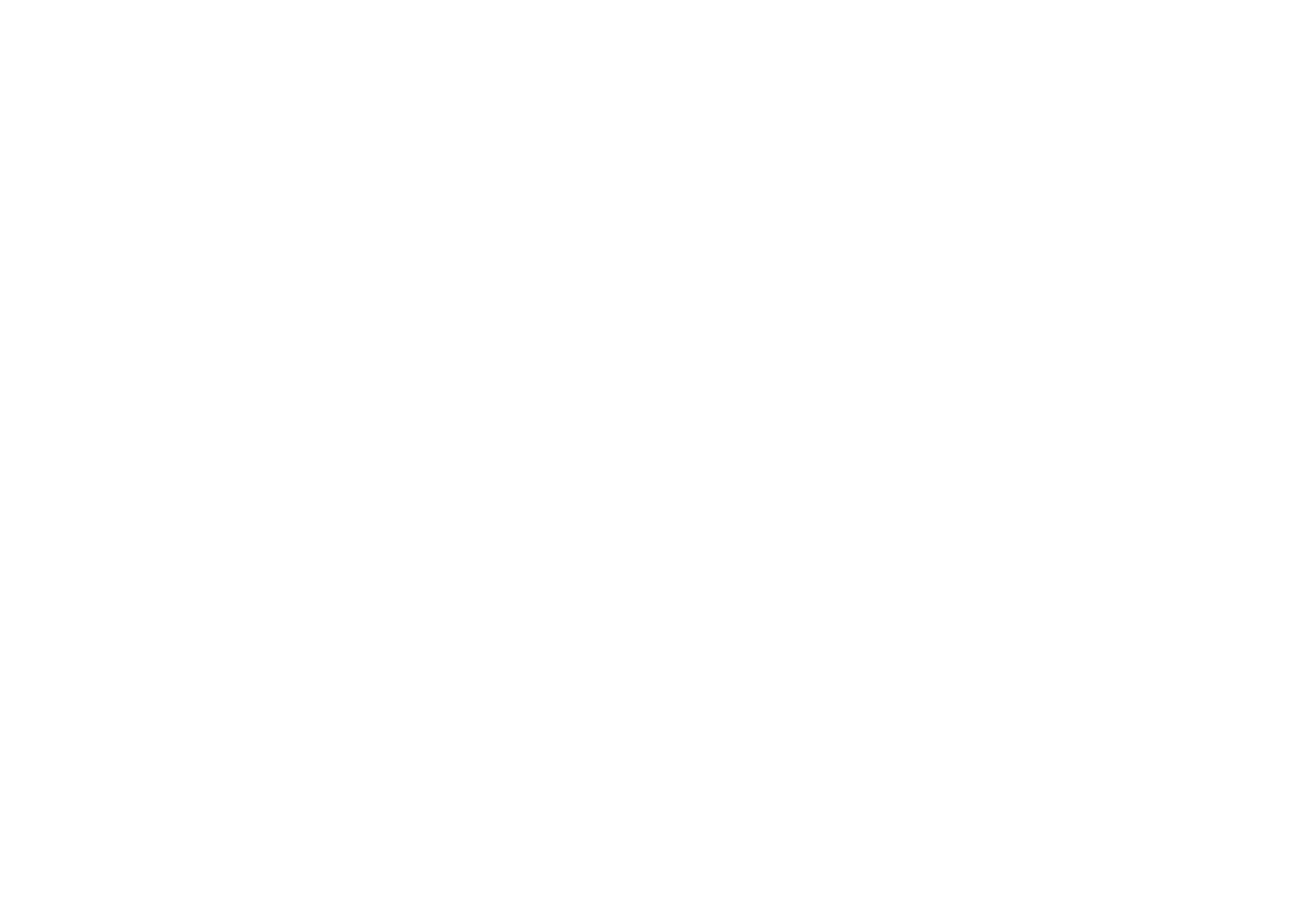
对于一个原始图片,经过4个阶段处理后输出ViT表征:
- 将图片调整为预设定的固定分辨率
- 根据预设定的Patch size,对图片做Patch分块处理
- 将分块的Patch输入一个线性变换层,映射成token embedding
- 将token embedding 拼接位置编码,输入到Transformer,最终产出图片的序列表征。
在标准的ViT实现上,输入图片会先被调整成长宽比固定的正方形,然后再按预设定的Patch size分割成固定大小的Patch块。这里需要注意,一旦设定好ViT的接收图像分辨率和Patch size,模型在后面训练、预测和迁移使用时,都要保持这个设置。
为了更好理解ViT,详见: ViT
ViT有什么缺点?
标准ViT的缺点具体表现在以下方面:
- 只能接收固定分辨率的图像输入:标准的ViT的输入必须统一处理成一致分辨率的图像,这需要提前对图像做resize处理,比如模型设置的接收图像的分辨率为: \(224×224\) ,那么如果一个图像分辨率为: \(200×800\) 的,那么需要提前将图片resize到 \(224×224\) ,这会导致图片扭曲,造成失真问题,影响模型对图片的理解。标准的ViT实现配置上是将图片处理成宽高比 1:1 ,也就是将原始图片resize成正方形。根据已有研究发现,主流的开源的图像数据集的图片分辨率分布,正方形的图片( \(h=w\) )分布通常非常稀疏,如下图所示。这也表明模型学习时,见到的大部分图片是失真的。
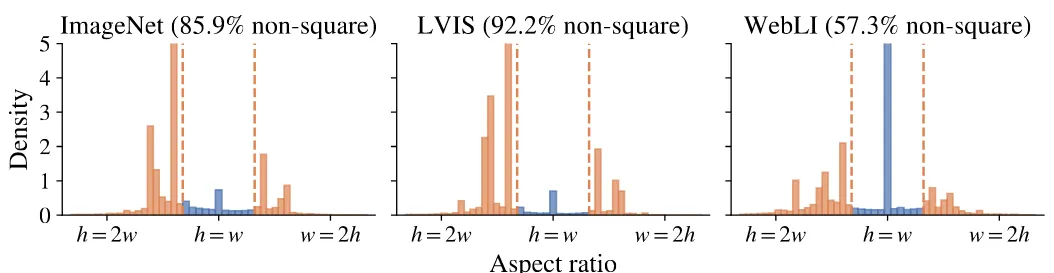
- 模型只能做单一patch size的分块处理:目前已经被验证,Patch设置越小,模型性能越好,模型运行速度越慢,而Patch设置越大,模型性能越差,模型运行速度也越快。能灵活调整Patch size的大小,对于模型灵活使用是比较重要的。然而标准的ViT实现,模型训练和预估只能设置固定大小的patch(比如: 16×16)。一旦设置好,训练和推理阶段都只能使用这个固定的patch size,如果训练和预估设置不一致,效果会大打折扣。如下图是 Flexivit 一文研究的实验结论。
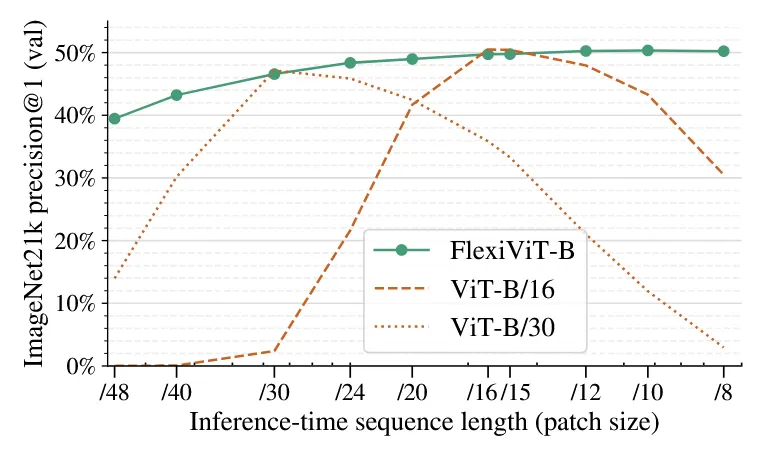
从图中我们关注两条黄色的虚线,分别是基于 Patch_Size=16 和 Patch_Size=30 训练的模型,在预估效果上,只在对应的Patch_Size表现出最佳性能,取其他Size模型效果会大幅降低。所以标准的ViT实现,是不能根据性能和准确率的需求,在预估阶段灵活选择Patch Size使用的。
一些研究也提出了ViT的其他不足,比如:
- ViT的建模方式(如:Patch内做像素平铺、特征序列按行展开)破坏了图像本身的空间结构。
这个问题,已经通过在Patch阶段增加卷积操作和在序列特征上增加2D的位置编码来提升ViT的空间建模能力,通过这些简单的优化ViT的空间建模是不逊色CNN的- ViT相比CNN训练更困难,达到相同效果,ViT需要的算力远超CNN,需要的更大的数据规模。
针对这个问题,在当前大模型时代,数据量和算力已经空前富足,ViT的模型Size一般相比LLM要小,所以在当前这并不是什么严重的问题。而相反基于Transformer的框架,在模型size和数据量上是存在Scaling Law的,所以理论上ViT模型的效果上限更高,可根据需要按性能和效率对模型灵活选择。所以总结来看,上面两点,个人觉得并不算ViT的弱势之处。
pix2struct: 避免图片失真的方法
总结一句话简单说,pix2struct主要的贡献是在标准ViT基础上,引入了可变分辨率输入的方法,保持图片原始宽高比,避免图片失真问题。
pix2struct 处理图像,始终保持跟原图像同比例的宽高进行缩放,在给定序列长度内,提取最大固定大小的Patch块。同时为了使模型能够明确感知宽高的空间分布,引入二维的可学习的绝对位置编码。
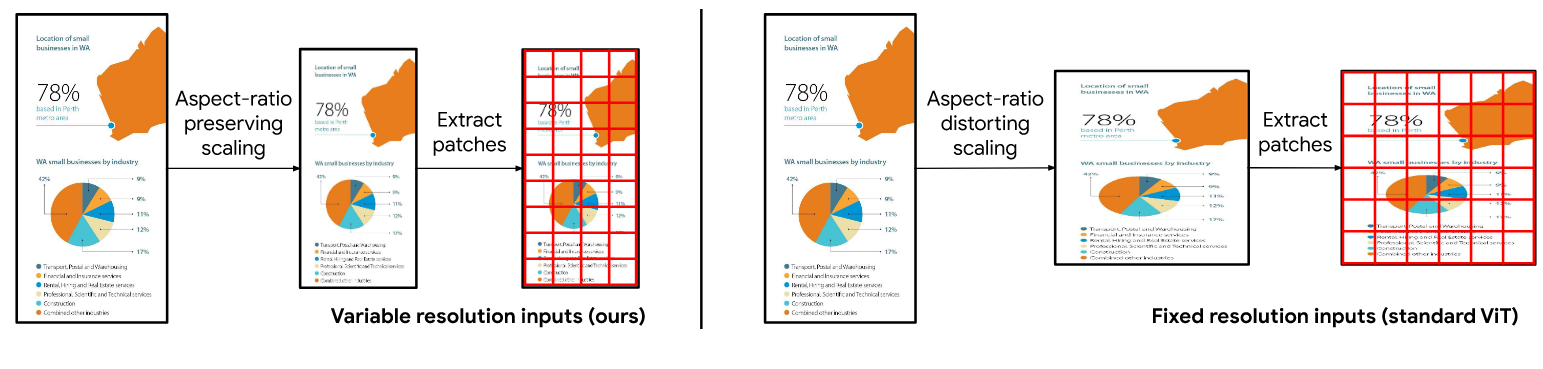
如下图所示,左图表示pix2struct的处理过程,保持原始图像的宽高比的前提下,对图像做Patch操作;右图表示传统ViT的做法,传统方法明显会带来图片失真的问题。
截取pix2struct操作的核心源码如下(详见注释):
代码片段3
#源码:https://github.com/huggingface/transformers/blob/main/src/transformers/models/pix2struct/image_processing_pix2struct.py#L260C1-L277C1
class Pix2StructImageProcessor(BaseImageProcessor):
def extract_flattened_patches(self, image, max_patches, patch_size):
...
### 3.获取patch的高、宽和图片高、宽
patch_height, patch_width = patch_size["height"], patch_size["width"]
image_height, image_width = get_image_size(image, ChannelDimension.FIRST)
### 4.根据max_patches的设置,结合图片的原始宽高,计算可resize的新的宽、高
scale = math.sqrt(max_patches * (patch_height / image_height) * (patch_width / image_width))
num_feasible_rows = max(min(math.floor(scale * image_height / patch_height), max_patches), 1)
num_feasible_cols = max(min(math.floor(scale * image_width / patch_width), max_patches), 1)
resized_height = max(num_feasible_rows * patch_height, 1)
resized_width = max(num_feasible_cols * patch_width, 1)
### 5.根据获取的新的宽,高,对图片做上采样,做双线性插值处理
image = torch.nn.functional.interpolate( image,size=(resized_height, resized_width),mode="bilinear",...)
### 6.对图片做Patch,shape: [rows * columns, patch_height * patch_width * image_channels]
patches = torch_extract_patches(image, patch_height, patch_width)
patches = patches.reshape([rows * columns, depth])
### 7.Patch的序列长度小于max_patchs,对序列做padding处理,统一补齐到max_patchs长度
result = torch.nn.functional.pad(result, [0, 0, 0, max_patches - (rows * columns)])
return result
# 图像数据处理主入口函数
def preprocess(self,..., images: ImageInput) -> ImageInput:
...
### 1. 设置好两个重要参数:max_patches是模型可处理的固定Patch长度; patch_size是分片长度
max_patches = xxx
patch_size = yyy
### 2. extract_flattened_patches对每个图片做resize的核心方法
images = [
self.extract_flattened_patches(image=image, \
max_patches=max_patches, patch_size=patch_size, ...)
for image in images
]
return images下面以一个具体例子,理解下上面的代码处理过程
示例:假设 max_patches=10, patch_size=32, image_size=100×200
代码注释3-4代码块计算过程
- 计算图片伸缩比:\(scale = \lfloor 10 \times (32/100) \times (32/200) \rfloor = 0.7155\)
- 计算缩放后的图片行列可容纳的Patch数:
\(num\_feasible\_rows = \lfloor scale \times 100 /32\rfloor = 2\)
\(num\_feasible\_cols = \lfloor scale \times 200 /32\rfloor = 4\) - 计算对Patch取整的最大resize的宽高:
\(resized\_height = num\_feasible\_rows \times 32 = 64\)
\(resized\_width = num\_feasible\_cols \times 32 = 128\)
代码注释5-7代码块处理流程图如下所示

经过上述操作后,再拼接上2D的可学习位置编码向量,后面就可以类似传统ViT的实现(做线性变换->过Transformer),最终计算得到图片的序列表征。
如上,pix2struct的工作描述完了,方法是比较简单的,主要的升级点:固定分辨率-> 可变分辨率的优化。
下面我们再看看Flexivit方法从Patch size角度对ViT做的优化。
FlexiViT: 一次训练多个patch size的模型
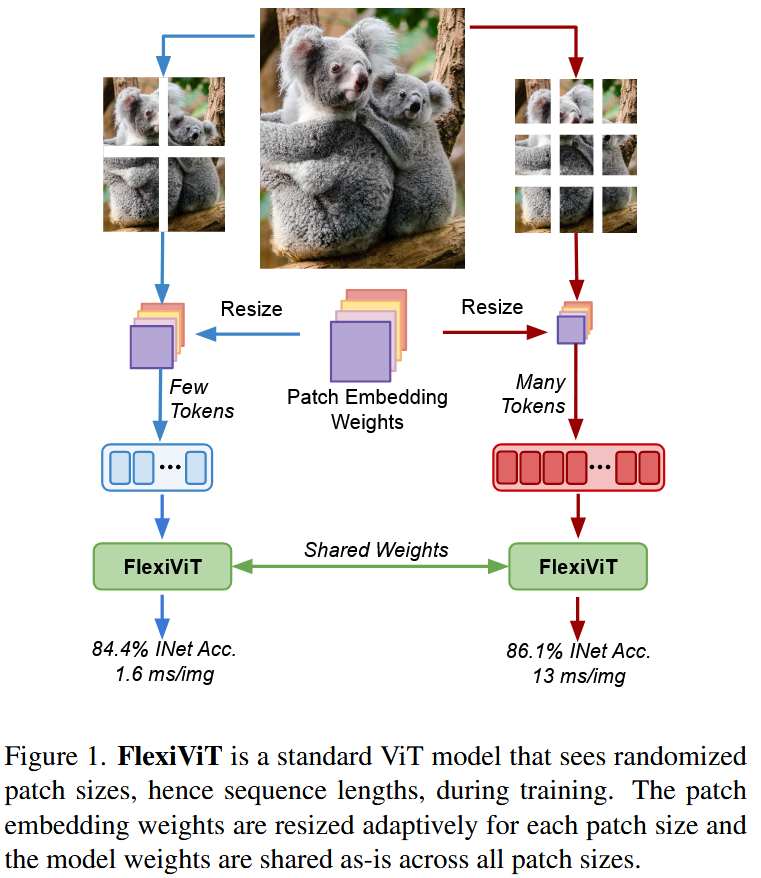
标准的ViT实现是采用固定的patch size对图像做特征抽取。这样带来的一个问题是训练好的模型只能在这个固定的patch size下能获得最好的性能。如上图的ViT-B/16和ViT-B/30效果所示(两条橙色的虚线),在固定16,30的patch size下训练的模型,在多个patch size下做评估(从8到48),最终结果表明,除了在训练的patch size下能获得较好的性能,其他patch size下,性能都折损较多。
模型使用时能灵活调整patch size,对模型落地应用是非常重要的。通常patch的大小决定了速度与准确率的权衡,patch设置越小,计算成本越高,但准确率也越高; patch越大,计算成本越低,但准确率也越低。在模型使用阶段,通常希望根据需求能动态设置patch size大小,来平衡速度和准确率。然而我们知道,对于标准的ViT实现,改变patch大小通常要对模型重新训练。
针对上面的问题,FlexiViT提出了一种自适应Patch size的模型训练方法。
简单说,FlexiViT在训练过程,每个迭代步随机一个Patch Size,对图片做Patch分块处理,由于随机选择的Patch Size会影响序列的长度,所以需要同时对Patch embedding参数和位置编码参数做resize调整,以适配Patch Size的变化。进而实现一个动态Patch size的ViT模型。
下图为FlexiViT 算法的伪代码, 作者在文中说明了这些底层可学习参数的确切形状并不重要,在所有实验中,patch都使用 \(32 × 32\) 的基础大小,对位置嵌入使用\( 7 × 7\) 的基础大小。

我们按标准ViT的形式(1.分块化处理 -> 2.计算分块embedding -> 3.增加位置编码)详细描述下FlexiViT的具体做法,也方便与标准的ViT做对比。
分块化处理(Patchification)
为了能进行各种patch size的分块,FlexiViT首先初始化一个Patch Size集合,并在每次模型训练迭代时,均匀采样一个patch size,然后对图片做Patchification。在论文中具体的设置:统一使用分辨率为 \(240 \times 240 \) 的图片,取能被240 整除的一个Patch Size集合 \(\{48,40,30,24,20,16,15,12,10,8\}\) ,每次训练迭代从集合中均匀采样一个Patch Size,对图片进行分块处理。
计算patch embedding
将一个Patch(大小为: \(p×p×c\) )映射成一个 \(d\) 维的embedding,需要 \(d\) 个与Patch同尺寸的参数矩阵与Patch做内积得到。标准的ViT,Patch Size是固定的,因此在计算Patch embedding时,只需要初始化一组参数矩阵( \(d\) 个 \(p×p×c\) 的参数)就可以正常训练模型。现在Patch Size( \(p\) )是在一组值中随机选择,假设某一次随机到的Patch Size为 \( p^∗\) ,图片会分割成 \(p^ \times p^* \times c\) 的Patch,那么如何设置映射Patch embedding的参数矩阵呢?
当Patch Size为 \(p^∗\) 时,肯定需要 \(d\) 个 \(p^* \times p^* \times c \) 的参数矩阵与Patch乘积得到Patch的embedding。
首先我们容易想到一种简单的方式:由以上步骤可知 \(p^∗\) 是可枚举的有限的集合,可以对应每个 \(p^∗\) 都初始化一组参数,但这样显然是不太可取的。
- 一方面因为不同 \(p^∗\) 的参数无法共享,使得由于数据分布问题,导致部分 \(p^∗\) 的参数得不到训练;
- 另一方面会增加模型的参数容量,设计上是非常不优雅的。
FlexiViT的做法:首先初始化一个固定大小的参数矩阵 \(W\) :\(d\) 个 \(p×p×c\)的参数(也可以看做 \(d×c\) 个 \(w\),每个 \(w\) 为 \(p×p\) 的参数,文中设置: \(p=32\) )。然后通过一个变换矩阵 \(P\) 将每个 \(w \in \mathbb R ^{p \times p}\) 参数映射成 \(\hat w \in \mathbb R^{p^* \times p^* }\),可得到了一组新的参数矩阵 \(\hat W\) : \(d\) 个 \(p^* \times p^* \times c \) 的参数,最后用新的参数与 \(p^* \times p^* \times c\)的Patch做内积,得到最终 \(d\) 维的Patch embedding。
上面提到的变换矩阵\(P\),应该如何得呢?,FlexiViT做了一个假设:对于一个Patch \(x\) 如果做信息无损变换得到 \(\hat x\),希望找到的变换矩阵 \(P\) ,使得变换后的参数 \(\hat w\) 与 \(\hat x\) 的内积和原始的 \(w\) 与 \(x\) 的内积相等。如下公式:
其中 \(\hat w = Pw\) ,\(\hat x = Bx\) 是对 \(x\) 做无损变换得到的结果, \(\langle.\rangle\) 表示内积操作, \(\hat x\) 与 \(\hat w\) 同尺寸。
显然FlexiViT这个假设是合理的,因为只要 \(x\) 信息没有折损,那么无论 \(x\) 的形式怎么变化,最终映射成的patch embedding应该是一样的,这样才能保证模型计算稳定。
论文给出的可能的解决方案
- 令牌归一化
一种方法是在嵌入后立即归一化令牌,可以显式实现或通过LayerNorm 模块实现。但这种方法有两个缺点:
- 需要更改模型架构,与现有预训练ViT模型不兼容
- 不能完全保留补丁嵌入的信息
- PI-resize 方法(伪逆调整)
作者提出了一种更原则性的方法,称为PI-resize(伪逆调整),它与现有预训练模型兼容且不需要架构更改
首先,双线性调整操作可以表示为线性变换:
其中 \(o \in \mathbb{R}^{p \times p}\) 是任意输入,\(B_{p^*}^p \in \mathbb{R}^{p^{*2} \times p^2}\) 是调整矩阵。对于多通道输入,各通道独立调整。
优化问题的形式化
我们希望找到新的patch嵌入权重 \(\hat{\omega}\) 使得调整后的补丁的令牌与原始补丁的令牌匹配。形式上,我们要解决以下优化问题:
其中\(B = B_{p^*}^p\),\(X\) 是补丁的patch分布 。
- 上采样情况的解决方案
当增加patch大小时(即 \(p^* \geq p\)),我们可以使用 \(\hat{\omega} = P\omega\),其中\(P = B(B^TB)^{-1} = (B^T)^+\) 是\(B^T\)的伪逆:
这样,我们对所有 \(x\) 都能精确匹配补丁嵌入 。
- 下采样情况的解决方案
当降低patch大小时(即 \(p^* < p\)),优化问题的解通常取决于patch分布 \(X\)。作者在附录A.2中证明,对于 \(X = \mathcal{N}(0, I)\)(标准正态分布),伪逆 \(\hat{\omega} = P\omega = (B^T)^+\omega\) 仍然是最优解。
PI-resize 的定义
综上所述,PI-resize(伪逆调整)定义为:
其中 \(P_{p^*}^p \in \mathbb{R}^{p^{*2} \times p^2}\) 是对应于PI-resize变换的矩阵。
通过双线性插值计算 \(B\) 的过程如下代码:
# 源码地址:https://github.com/google-research/big_vision/blob/main/big_vision/models/proj/flexi/vit.py#L60
def resize(x_np, new_shape):
x_tf = tf.constant(x_np)[None, ..., None]
x_upsampled = tf.image.resize(
x_tf, new_shape, method="bilinear")[0, ..., 0].numpy()
return x_upsampled
### 获取矩阵B的函数
def get_resize_mat(old_shape, new_shape):
mat = []
for i in range(np.prod(old_shape)):
basis_vec = np.zeros(old_shape)
basis_vec[np.unravel_index(i, old_shape)] = 1.
### 双线性插值
mat.append(resize(basis_vec, new_shape).reshape(-1))
return np.stack(mat).T
# https://github.com/google-research/big_vision/blob/main/big_vision/models/proj/flexi/vit.py#L69C3-L69C49
resize_mat_pinv = np.linalg.pinv(resize_mat.T)我们再总结下FlexiViT计算patch embedding的过程:
- 先初始化一组size固定的权重 \(W \in \mathbb R ^{d \times c \times p \times p}\)
- 然后根据随机的Patch size:\(p^*\) ( \(p^* \neq p\) ),获取一个 \(p\times p \to p^* \times p^*\) 的双线性插值的变换矩阵 \(B\)
- 然后获取 \(B^T \) 的伪逆矩阵 \(P\) 。
- 再用 \(P\) 对 \(W\) 做变换得到 \(\hat W \in \mathbb R^{d\times c \times p^* \times p^*}\) ,最终用 \(\hat W\) 与步骤1中的每个Patch( \(c \times p^* \times p^*\) )做内积,得到 \(d\) 维的patch embedding。
最后,我们以一个简单的例子,再来验证下,假设取一个 \(2×2\) 的 patch \(x = \begin{bmatrix} 0.1 & 0.2 \\ 0.3 & 0.4 \end{bmatrix}\) ,\(w = \begin{bmatrix} 0.5 & 0.6 \\ 0.7 & 0.8 \end{bmatrix}\)
先分别计算出 \(Bx\) 和 \(Pw\) ,如下图
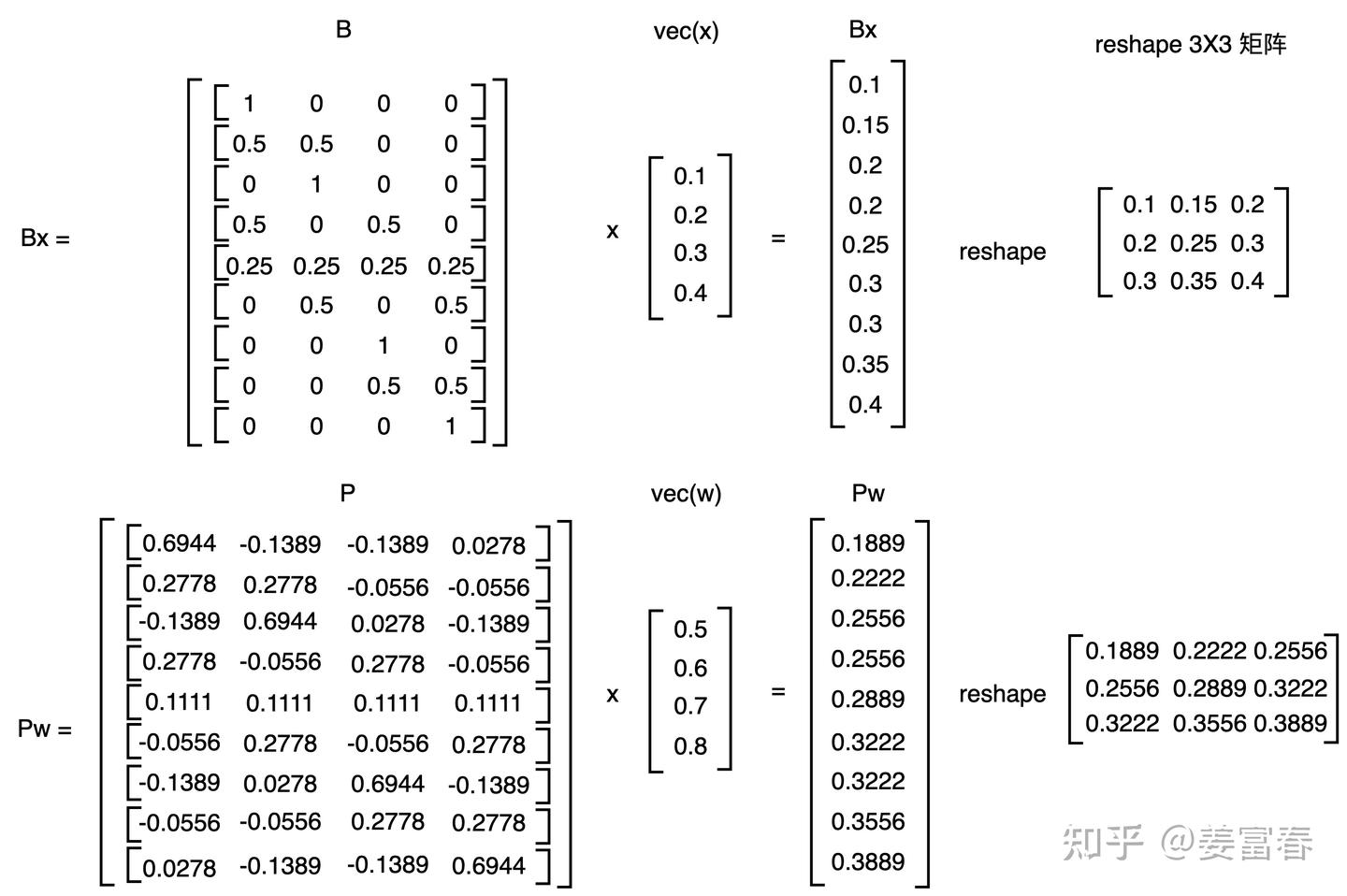
再分别计算下 \(\langle x, w\rangle\) 和 \(\langle Bx, Pw\rangle\) ,如下图所示二者是相等的。

序列表征增加位置向量
FlexiViT对位置编码也是先初始化一个长度,代码中设置 \(7×7\) ,然后通过线性插值适配到随机采样的Patch Size序列化的长度。如下代码片段:
#https://github.com/google-research/big_vision/blob/main/big_vision/models/proj/flexi/vit.py#L137C1-L142C52
....
### 按初始设置的posemb = (7,7),初始化pos_emb
pos_emb = vit.get_posemb(self, self.posemb, self.posemb_size, c, "pos_embedding", x.dtype)
### 对已经初始化的pos_emb做线性(linear)插值处理,将pos_emb插值到h*w的长度
if pos_emb.shape[1] != h * w:
pos_emb = jnp.reshape(pos_emb, (1, *self.posemb_size, c))
pos_emb = jax.image.resize(pos_emb, (1, h, w, c), "linear")
pos_emb = jnp.reshape(pos_emb, (1, h * w, c)NaViT:原生分辨率的高效率ViT
💡 NaViT的完整方案 = Factorized PE + Packing + Masking
Batch内的图像可以有不同分辨率
Image 1: 224×224 → 256 tokens
Image 2: 448×224 → 512 tokens
Image 3: 336×336 → 576 tokens
Sequence Packing: 拼接成一个长序列
[tok1_1...tok1_256 | tok2_1...tok2_512 | ...]
Attention Mask: 防止跨图像attention
│ [1 1 ... 1 0 0 ... | 0 ... 1 1 ... 1 0 | ...]│
目前我们描述的方法都是需要对图片做一定的缩放处理的,标准的ViT和FlexiViT都只接受固定分辨率的图片,pix2struct能处理不同宽高比的图片,但也需要对图片做resize操作,对较大、较小的图片要做些缩放处理,使得图片最终能处理成一个定长的序列表征,输入给模型。
那么我们有没有一种方法能够保留原始的图片的分辨率,不做任何resize处理呢?NaViT就是保留原始分辨率和宽高比的一种ViT实现
NaViT核心是借鉴了自然语言处理中序列Packing的技术,将多个图片按原始的分辨率做Patch处理后,然后拼接到一个序列中,来实现对不同分辨率图像可统一处理,论文称这种方法为Patch n' Pack。
Packing是将多图片打包到一个序列输入给模型,那么模型需要针对一个序列多example的情况做些改造处理。我们先来看看NaViT做了哪些改造。
模型的一些改造
掩码注意力和掩码池化机制(Masked self attention and masked pooling)
多example打包到一个序列后,在模型前向计算时,Transformer的每一层都会做Self-Attention计算,为了防止不同example相互attention,引入了一个额外的自注意力的掩码。此外通常CV建模任务中,需要对图像整体做表征来计算loss, 所以需要在模型顶层对每个example做表征聚合,同样需要做计算隔离,因此也需要跟Self-Attention计算一样的掩码矩阵。如下图所示,一个序列有三个example,token长度分别为:4,6,5 ,最后为了对齐Batch的多序列拼接了 2 个padding token。
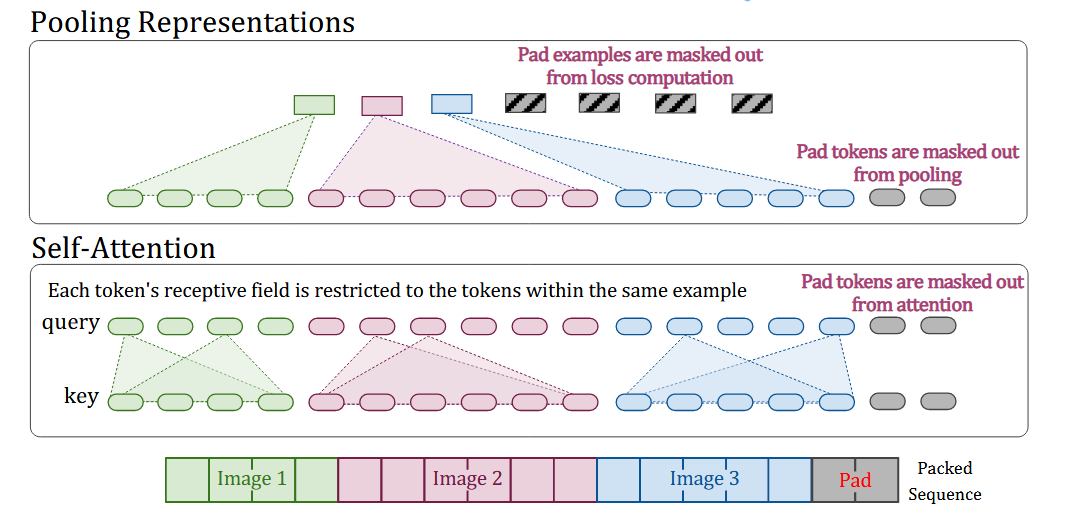
图中在计算Self-Attention和Pooling representations时,都只与每个example内的token序列进行计算。那这个隔离的Mask具体长啥样?如下图所示,其实就是一个对角分块矩阵。

引入分解式位置编码
为了处理任意分辨率和宽高比的图片数据,NaViT引入了分解式绝对位置编码加到Patch token上来表示序列中的空间信息。分解式绝对位置编码是将位置编码分解成 x 轴和 y 轴两个独立维度的位置编码向量。每个轴的位置Embedding初始化为 \(maxLen\)个 \(d\) 维向量,通过Patch的绝对位置index来映射位置向量,然后将两个轴的位置向量分别加到Patch token向量上。对比Pix2Struct引入的二维绝对位置编码,需要学习 \([maxLen,maxLen]\) 个位置嵌入,每个位置 \((x,y)\) 都要被学习过,才能获得较好的效果。
而分离式的位置编码对 x 轴和 y 轴的参数分别进行学习,一方面参数量大大减少,由 \(maxLen^2\) 减少到 \(2×maxLen\) ,另一方面分离式的位置编码,对未见过的分辨率有更好的外推性,因为虽然 \((a,b)\) 组合的分辨率没见过,但高是 \(a\) 或宽是 \(b\) 的图片模型可能分别都见过,这就能学到对应的位置表征。
在实际实现中,NAViT通常采用以下步骤:
- 对于图像中的每个patch,计算其归一化坐标 \((x/W, y/H)\),其中\(W\)和\(H\)是图像宽度和高度
- 将这些归一化坐标输入到位置嵌入函数\(\phi_x\)和\(\phi_y\)中
- 将组合后的位置嵌入与patch嵌入相加
token drop策略
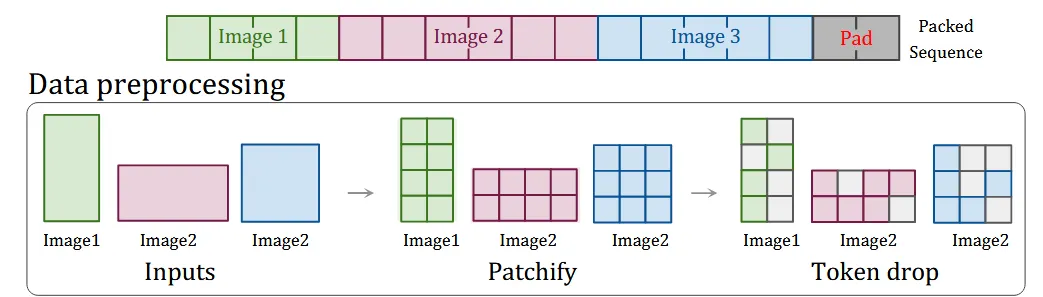
图像本身是低密度的信息载体,对于空间临近的一些像素和Patch会有较相似的信息,因此在模型训练时,可以通过适当的采样,丢弃一些Patch以提高训练吞吐和性能。对于传统的ViT方法对每个固定分辨率图片只能采用固定drop rate来采样,将每个图片处理成定长的序列以输入给模型。NaViT由于多个image被pack到一个序列里,每个图片可以有不同的drop token的策略,这为不同分辨率的图片提供了灵活的token采样方式,尤其对于一些大尺寸的图片,通过提升drop rate来压缩序列特征长度;同时为了控制Sequence的总长度,可以对最后一个图片做特化的采样策略(如:根据剩余可容纳几个token位置,来设置采样策略),来控制多image拼接后得到一个固定sequence长度,这大大简化了Batch的处理逻辑。不同图片的预处理过程下图所示,对多图片保留真实的分辨率和宽高比做Patch分块处理,然后对每个图片做不同的drop Token处理,最后拼接成一个序列。
Batch内多example对齐策略
通过Pack后的序列再组Batch,一个Batch中每个序列包含的example的数量是不同的。如上所述在CV建模任务中,最终计算loss时,通常每个example都要做pooling处理,这就导致一个Batch中每个序列有不同的pooling表征,这样是不利于一个Batch做并行化计算的。为了解决这个问题,NaViT做了Batch内example对齐处理,具体操作:对于一个Batch为 \(B\) 的序列,我们最多提取 \(B \times E_{max}\) 个pooling 后的表征,也就是每个序列都提取 \(E_{max}\) 个图像Pooling的表征。如果一个序列包括超过 Emax 的图像,超过的部分直接丢弃;如果一个序列的examples少于 Emax ,使用fake表征对序列做padding。
性能&效果讨论
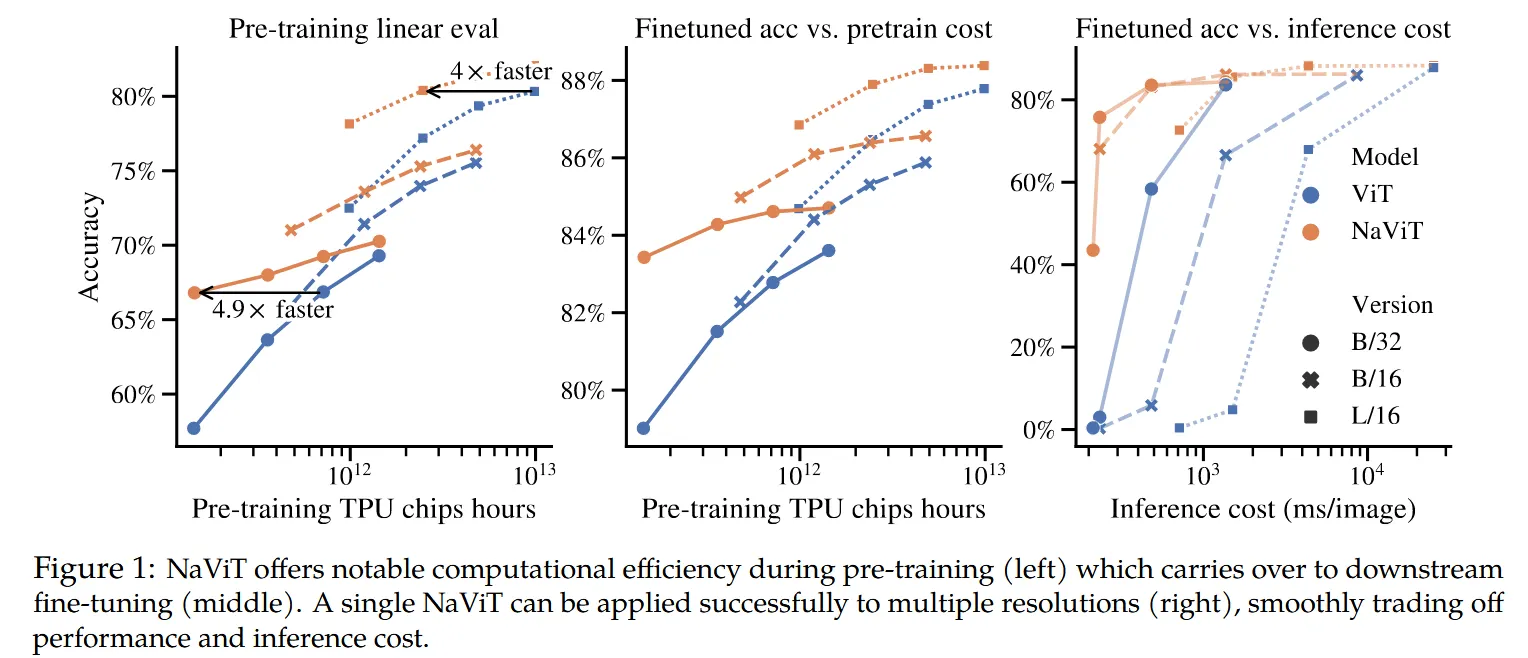
NaViT通过Packing大大提升了计算的并行性,因为相对于非Packing的计算,相同的Batch下,模型见到了更多的样本,如下图所示,与传统的ViT相对,达到传统ViT的最佳性能,只需要 1/4 的计算开销;另外如果使用相同的计算资源,NaViT的性能始终优于ViT。此外上面描述的动态token drop策略,通过灵活控制token drop率,可进一步平衡模型的吞吐和准确率。
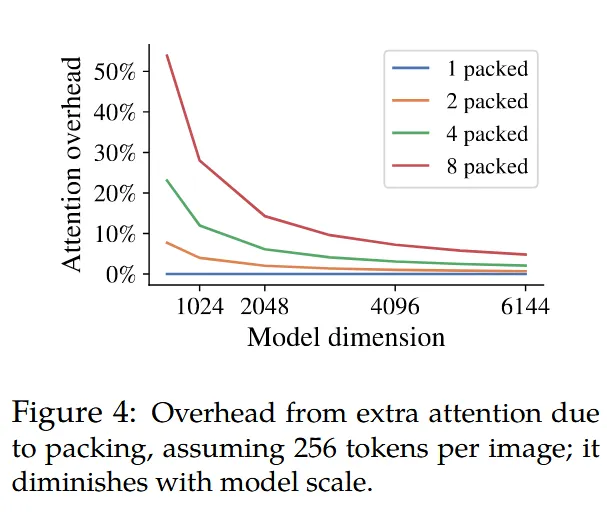
另外NaViT的Packing处理后的序列长度相对于传统的ViT要更长,我们知道计算Self-Attention是 \(O(n^2)\) 的时间复杂度,那么随着序列的长度变长,Attention计算的开销是平方级增长的。这是个影响性能的不可忽视的问题。NaViT也做了下实验,证明随着Transformer模型hidden size的维度的增加,Self-Attention成本在整体成本中所占的比例越来越小(整体成本还包括多层MLP的计算成本等)。如下图所示。随着模型逐渐增大,Packing后的序列,Attention计算的开销不足整体的10%,因此Packing更长的序列,Attention计算不会带来计算瓶颈。
小结
- ViT以简单、灵活和可Scaling的特性在CV和多模态领域越来越受欢迎,几乎成为CNN的全方位的代替品。标准的ViT操作简单,将图像分割成多个Patch,再映射成Token embedding输入给Transformer网络做表征。通常输入图像会被调整为固定的正方形宽高比,然后分割成固定数量的Patch块。
- Pix2Struct引入了一种保留图片宽高比的Token化方法;
- FlexiViT支持在一个架构内使用多种Patch Size的方法,从而可以平滑地调整序列长度和计算成本;
- NaViT通过Patch n’ Pack方法将不同图像的多个Patch打包成一个序列,这能够保留图片原生的分辨率和宽高比,同时计算性能远超ViT。Qwen-VL系列也是使用了NaViT方法来对输入的图片和视频资源做高效的建模。